原文链接:http://tecdat.cn/?p=24141
原文出处:拓端数据部落公众号
背景
贝叶斯模型提供了变量选择技术,确保变量选择的可靠性。对社会经济因素如何影响收入和工资的研究为应用这些技术提供了充分的机会,同时也为从性别歧视到高等教育的好处等主题提供了洞察力。下面,贝叶斯信息准则(BIC)和贝叶斯模型平均法被应用于构建一个简明的收入预测模型。
这些数据是从 935 名受访者的随机样本中收集的。该数据集是计量经济学数据集系列的一部分 。
加载包
数据将首先使用该dplyr 包进行探索 ,并使用该ggplot2 包进行可视化 。稍后,实现逐步贝叶斯线性回归和贝叶斯模型平均 (BMA)。
数据
数据集网页提供了以下变量描述表:
| 变量 | 描述 |
|---|---|
wage |
每周收入(元) |
hours |
每周平均工作时间 |
IQ |
智商分数 |
kww |
对世界工作的了解得分 |
educ |
受教育年数 |
exper |
多年工作经验 |
tenure |
在现任雇主工作的年数 |
age |
年龄 |
married |
=1 如果已婚 |
black |
=1 如果是黑人 |
south |
=1 如果住在南方 |
urban |
=1 如果居住在都市 |
sibs |
兄弟姐妹的数量 |
brthord |
出生顺序 |
meduc |
母亲的教育(年) |
feduc |
父亲的教育(年) |
lwage |
工资自然对数 wage |
探索数据
与任何新数据集一样,一个好的起点是标准的探索性数据分析。汇总表是简单的第一步。
-
# 数据集中所有变量的汇总表--包括连续变量和分类变量
-
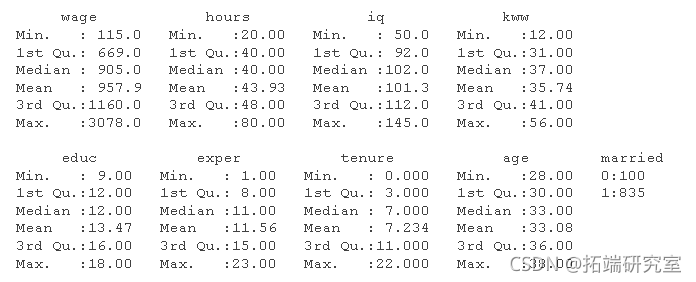
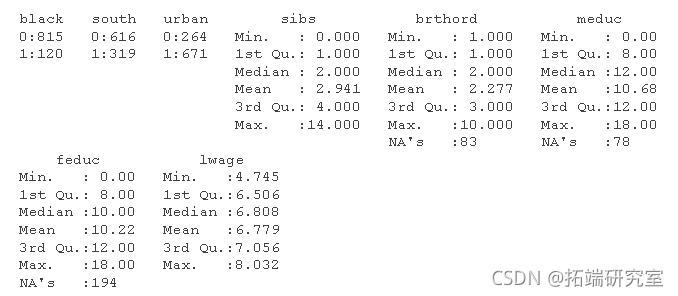
summary(wage)
因变量(工资)的直方图给出了合理预测应该是什么样子的。
-
#工资数据的简单柱状图
-
hst(wge$wae, breks = 30)
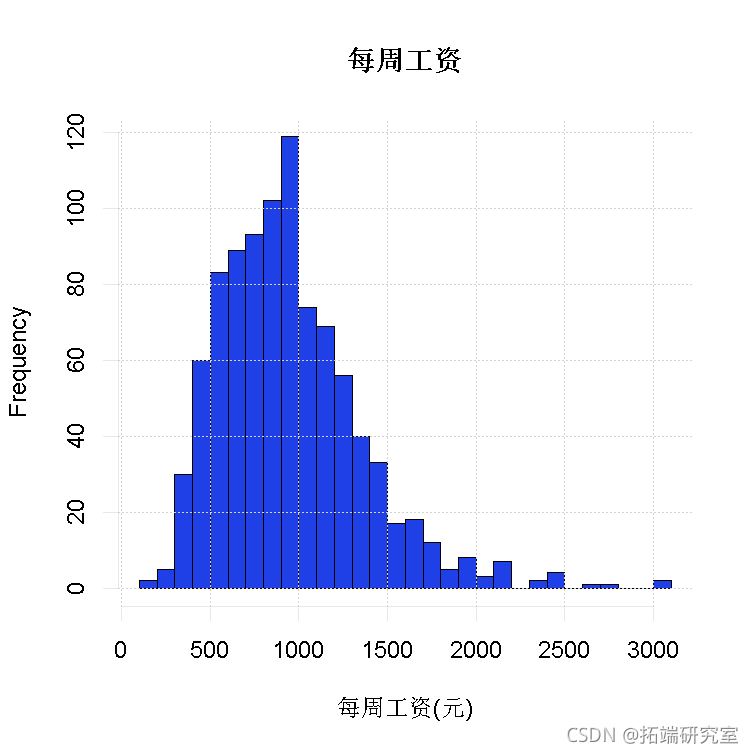
直方图还可用于大致了解哪些地方不太可能出现结果。
-
# 检查图表 "尾部 "的点的数量
-
sm(wage$ge < 300)
## [1] 6sm(wae$wge > 2000)## [1] 20简单线性回归
由于周工资('wage')是该分析中的因变量,我们想探索其他变量作为预测变量的关系。我们在数据中看到的工资变化的一种可能的、简单的解释是更聪明的人赚更多的钱。下图显示了每周工资和 IQ 分数之间的散点图。
gplot(wae, es(iq, wge)) + gom_oint() +gom_smoth() 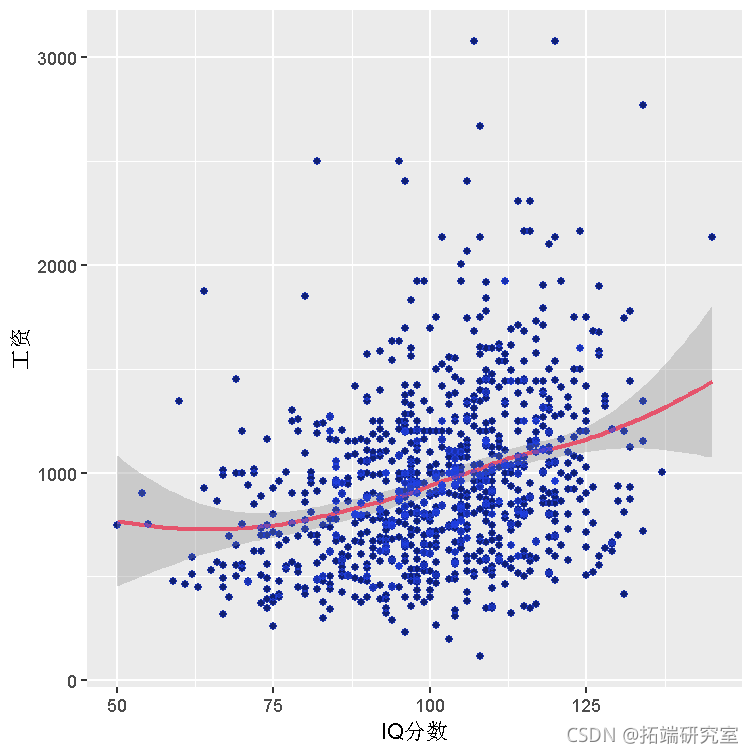
IQ 分数和工资之间似乎存在轻微的正线性关系,但仅靠 IQ 并不能可靠地预测工资。尽管如此,这种关系可以通过拟合一个简单的线性回归来量化,它给出:
工资 i = α + β⋅iqi + ϵiwagei = α + β⋅iqi + ϵi
-
m_wg_iq = lm(wge ~ iq, dta = age)
-
coefients

工资 i = 116.99 + 8.3 ⋅iqi + ϵiwagei = 116.99 + 8.3 ⋅iqi + ϵi
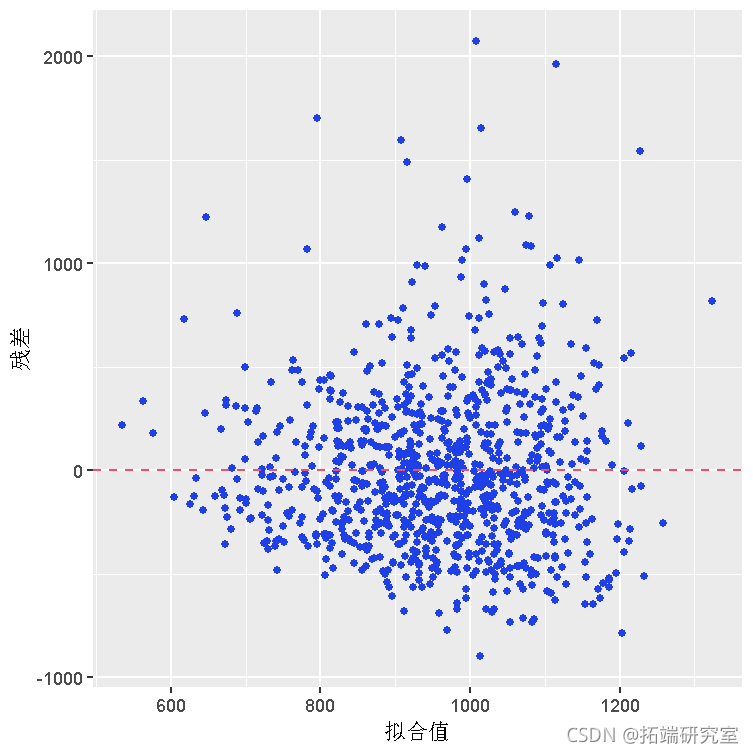
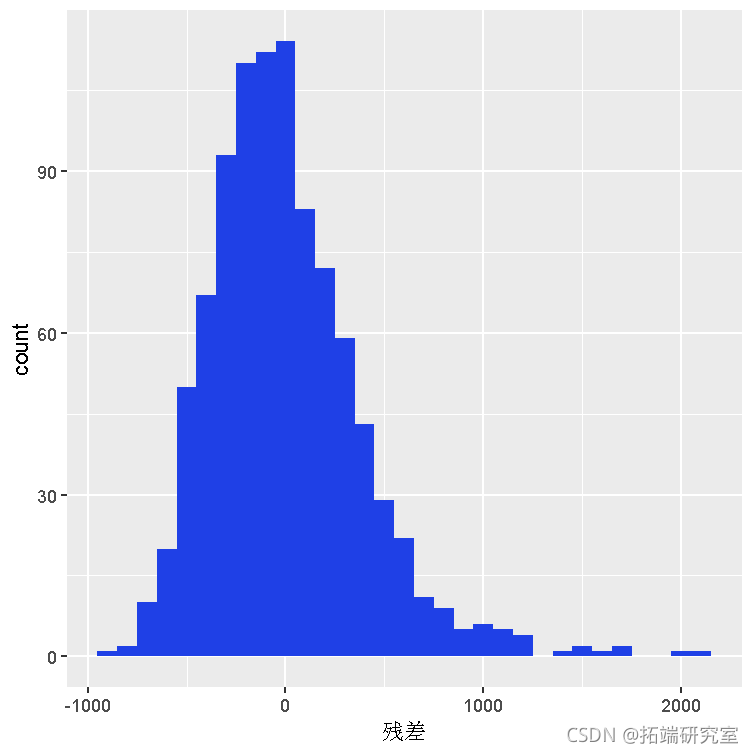
在转向贝叶斯改进这个模型之前,请注意贝叶斯建模假设误差 (ϵi) 以恒定方差正态分布。通过检查模型的残差分布来检查该假设。如果残差高度非正态或偏斜,则违反假设并且任何后续推论都无效。要检查假设,请按如下方式绘制残差:
-
# 用散点图和模型误差残差的直方图来检查正态性假设
-
-
glot(dta = mwag_q, es(x = .ite, y = .rd)) +
-
gemittr() +
-
-
plot(dta = m_g_iq, aes(x = .reid)) +
-
histgm(bnwth = 10)
-
变量变换
两个图都显示残差是右偏的。因此,IQ(因为它目前存在于数据集中)不应用作贝叶斯预测模型。但是,对 仅具有正值的偏斜因变量使用(自然)对数变换 通常可以解决问题。下面,该模型使用转换后的工资变量进行了重新拟合。
-
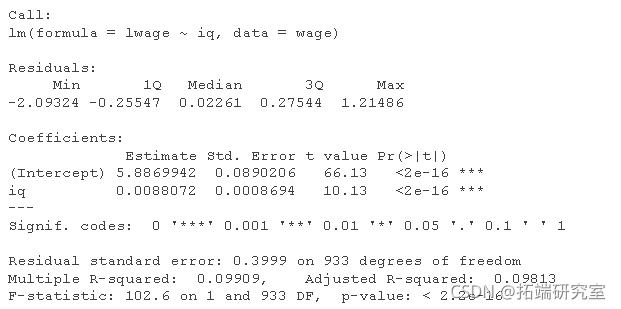
# 用IQ的自然对数拟合th模型
-
lm(lage ~ iq, data = wae)
-
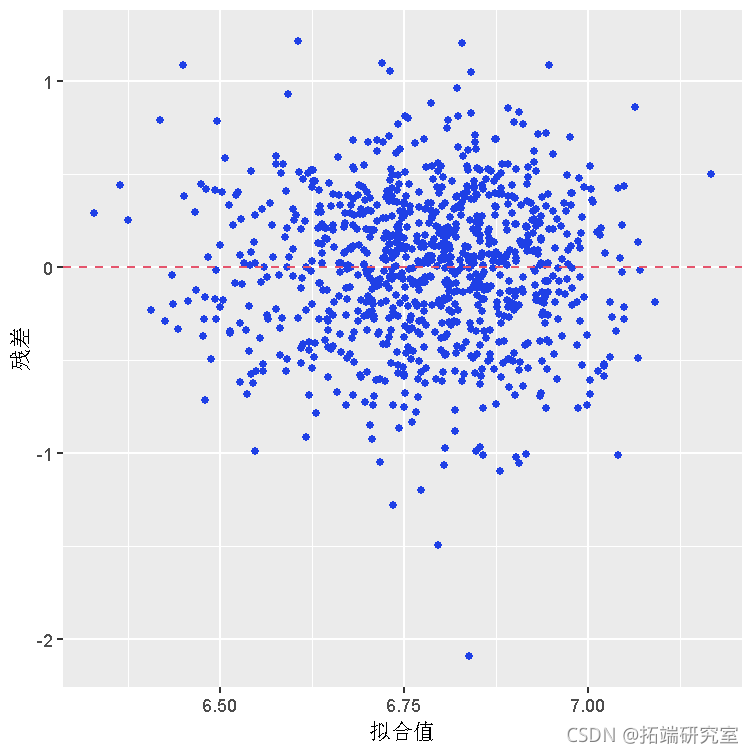
# 残差sctterplot和转换后数据的柱状图
-
plt(data = m_lag_iq, es(x = .fited, y = .reid))
-
geiter() +
-
ggpot(dta = m_lwgeiq, as(x = .resd)) +
-
gostgam(binwth = .1) +
-
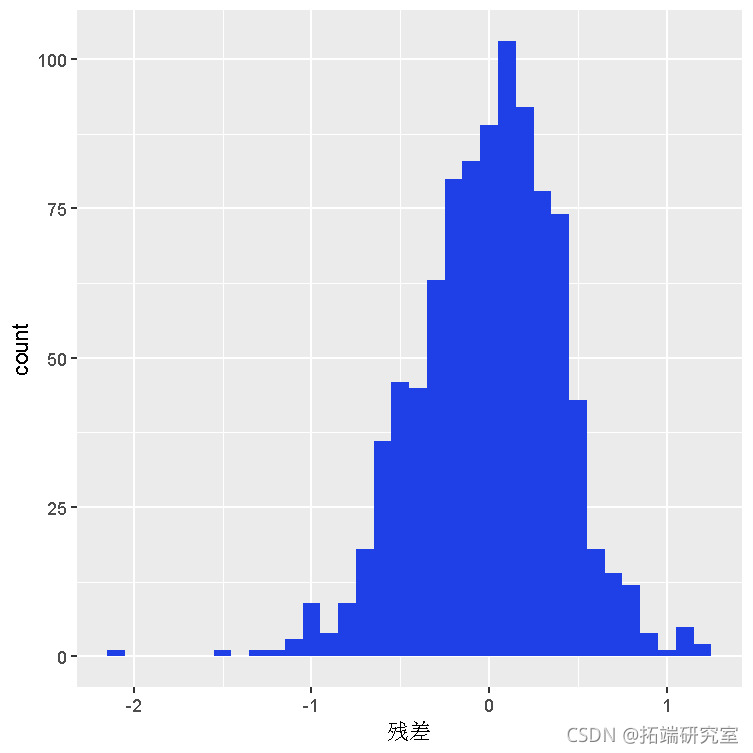
残差确实大致呈正态分布。然而,由此产生的 IQ 系数非常小(只有 0.0088),这是可以预料的,因为 IQ 分数提高 1 分几乎不会对工资产生太大影响。需要进一步细化。数据集包含更多信息。
多元线性回归和 BIC
我们可以首先在回归模型中包含所有潜在的解释变量,来粗略地尝试解释尽可能多的工资变化。
-
# 对数据集中的所有变量运行一个线性模型,使用'.'约定。
-
full = lm(lwge ~ . - wage, dta = wge)
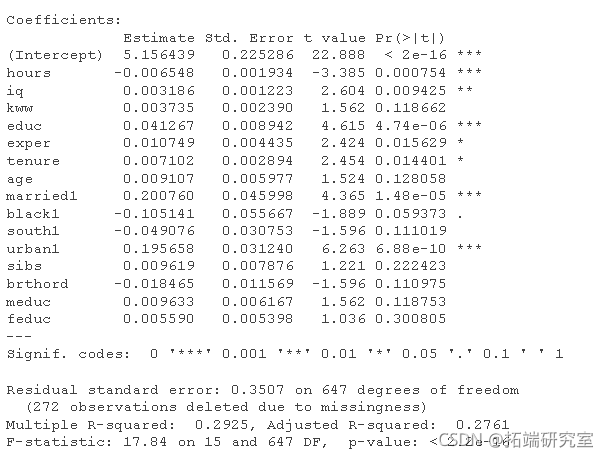
完整线性模型的上述总结表明,自变量的许多系数在统计上并不显着(请参阅第 4 个数字列中的 p 值)。选择模型变量的一种方法是使用贝叶斯信息准则 (BIC)。BIC 是模型拟合的数值评估,它也会按样本大小的比例惩罚更多的参数。这是完整线性模型的 BIC:
BIC(full)![]()
BIC 值越小表示拟合越好。因此,BIC 可以针对各种缩减模型进行计算,然后与完整模型 BIC 进行比较,以找到适合工资预测工作的最佳模型。当然,R 有一个功能可以系统地执行这些 BIC 调整。
-
# 用step计算模型
-
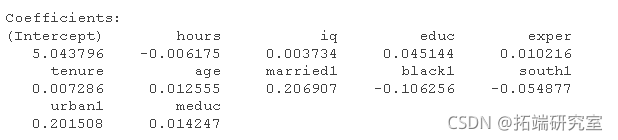
pIC(lwge ~ . - wge, dta = na.oi(wge))lg(lgth(na.mit(wge))))
-
-
# 显示逐步模型的BIC
-
BIC(se_mol)
![]()
调用 step找到产生最低 BIC 的变量组合,并提供它们的系数。很不错。
贝叶斯模型平均(BMA)
即使BIC处于最低值,我们能有多大把握确定所得到的模型是真正的 "最佳拟合"?答案很可能取决于基础数据的规模和稳定性。在这些不确定的时候,贝叶斯模型平均化(BMA)是有帮助的。BMA对多个模型进行平均化,获得系数的后验值和新数据的预测值。下面,BMA被应用于工资数据(排除NA值后)。
-
# 不包括NA
-
a_ona = na.omt(wae)
-
-
# 运行BMA,指定BIC作为判断结果模型的标准
-
BMA(wge ~ . -wge, daa= ae_o_a,
-
pror = "BIC",
-
moepor = ufom())
-
-
# 显示结果
-
summary
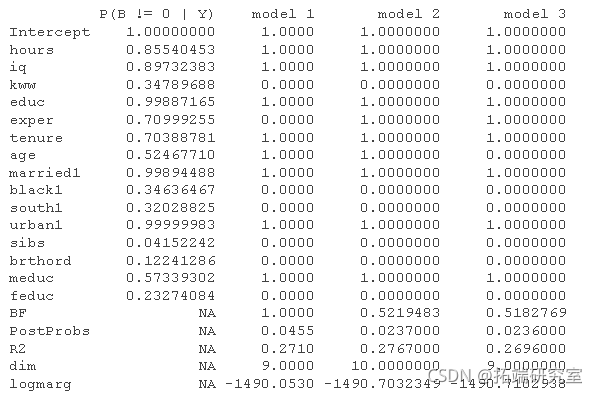
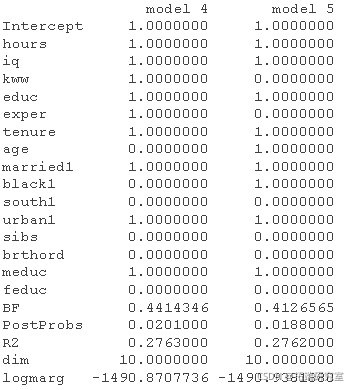
结果表显示了五个最有可能的模型,以及每个系数被包含在真实模型中的概率。我们看到,出生顺序和是否有兄弟姐妹是最不可能被包含的变量,而教育和智商变量则被锁定。BMA模型的排名也可以用图像图来显示,它清楚地显示哪些变量在所有模型中,哪些变量被排除在所有模型之外,以及那些介于两者之间的变量。
ge(b_lge, tp.oels)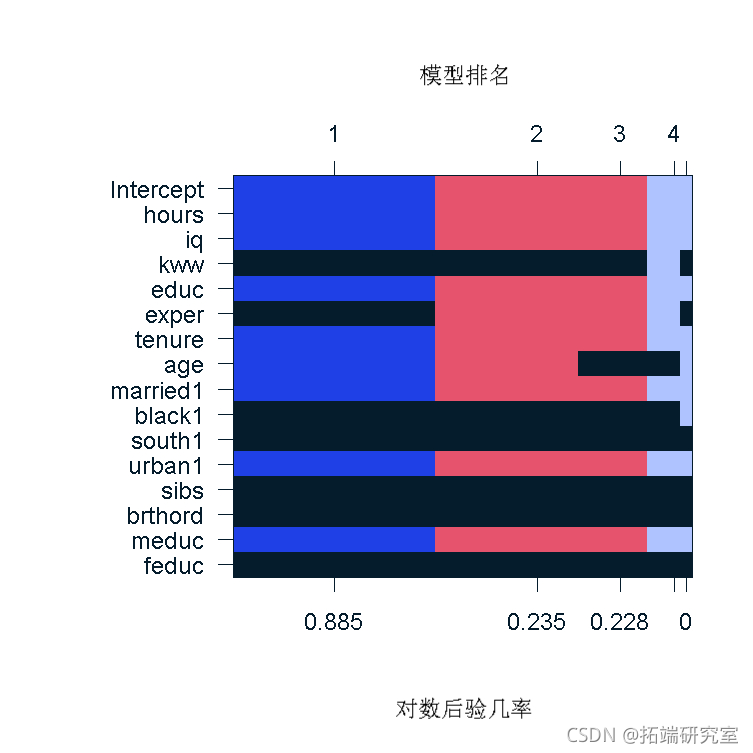
我们还可以提供模型系数的95%置信区间。下面的结果支持了关于包括或排除系数的决定。例如,在区间包含零,有大量证据支持排除该变量。
confint(ceflae)
进行预测
构建模型后,pediction 只是插入数据的问题:
-
# 用一个虚构的工人的统计资料来预测数据的例子
-
-
# 进行预测
-
redict = pedct(e_odl, newdt = wrkr,eitr = "BMA")
-
-
# 将结果转换为元
-
exp(wk_pedct)
![]()
预计这名化妆工作人员的周薪为 745 元。这到底有多准确?你得问她,但我们对我们的变量选择很有信心,并对现有的数据尽了最大努力。应用的贝叶斯技术使我们对结果有信心。

最受欢迎的见解
4.R语言中的block Gibbs吉布斯采样贝叶斯多元线性回归