urllib.request.Request('URL',headers = headers)
User-Agent 是爬虫和反爬虫斗争的第一步,发送请求必须带User—Agent
使用流程:
1、创建请求对象
request = urlllib.request.Request('url'......)
2、发送请求获取响应对象
response = urllib.request.urlopen(request)
3、获取响应内容
html = response.read().deconde('utf-8')
为什么要使用User—Agent呢?如果没有这个就对网页进行爬取,当爬取大量数据短时间大量访问网页那边就会知道你这边是一个程序,就可以进行屏蔽,使用User-Agent能够让那边认为你这边的爬虫是一个浏览器对其进行访问,不会拦截,当然如果就一个User-Agent短时间访问多次也是会被拦截,此时解决问题的方法是使用多个User-Agent,每次访问网页都随机选取一个User-Agent,这样就可以解决该问题。
简单的示例,使用上面的方法爬取百度首页内容:
import urllib.request url = "https://www.baidu.com/" headers = {'User-Agent': '自己找一个Uer-Agent'} #1、创建请求对象 req = urllib.request.Request(url, headers=headers) #2、获取响应对象 res = urllib.request.urlopen(req) #3|响应对象read().decode('utf-8') html = res.read().decode('utf-8') print(html)
如果要爬取一些复杂的网页,就需要对网页进行分析。
比如说对腾讯招聘进行爬取,首先腾讯招聘网页是一个动态网页,简单方式爬取不了,那我们找到这个网页的json网页如下:
https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1563246818490&countryId=&cityId=&bgIds=&productId=&categoryId=40001001,40001002,40001003,40001004,40001005,40001006&parentCategoryId=&attrId=&keyword=&pageIndex=0
&pageSize=10&language=zh-cn&area=cn
网页获得的结果是这样的:

这样看起来很难受,所以用一个插件JSON View(chrome浏览器),重新加载后格式为:
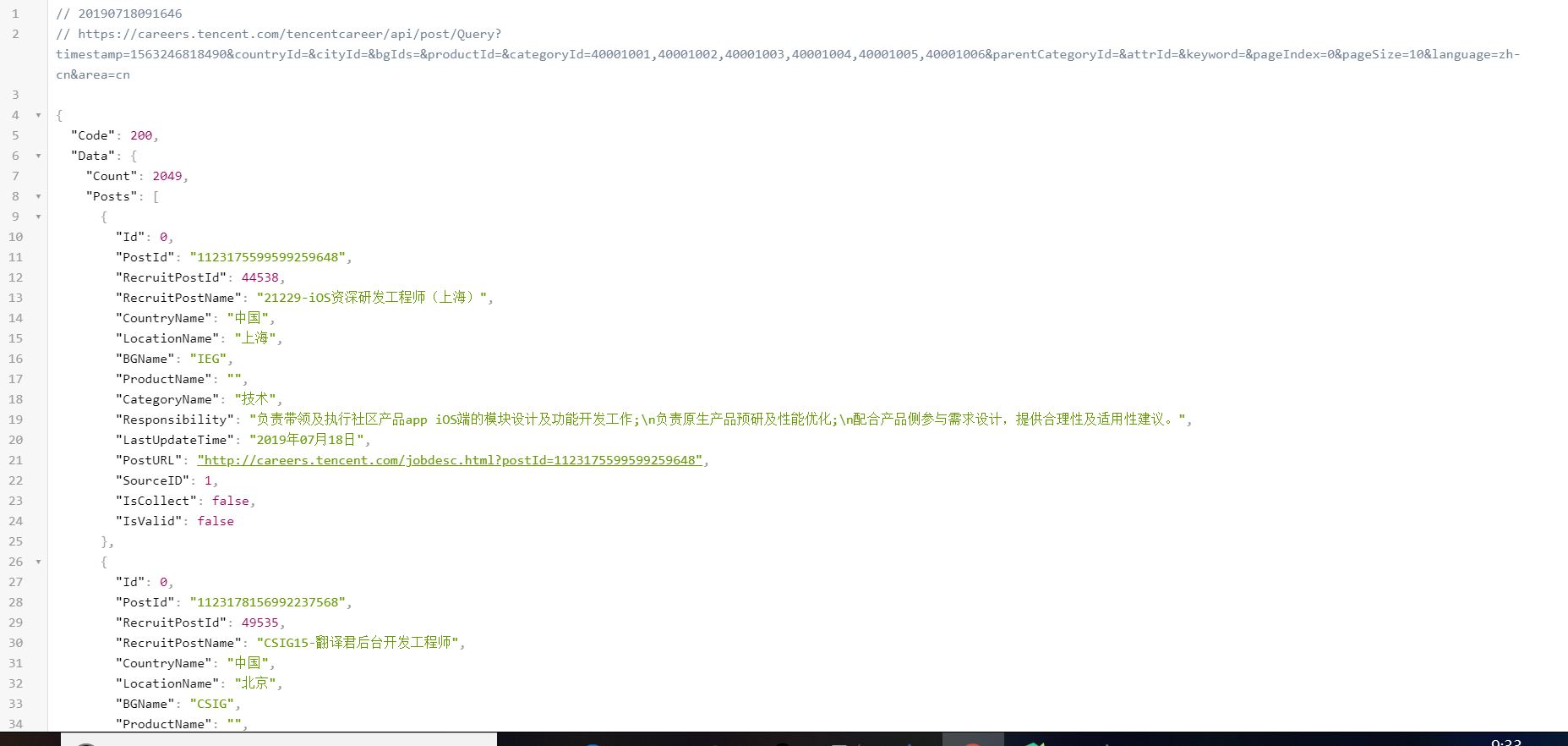
这样看起来就舒服多了,而且都是字典格式以及列表,找到我们想要的数据就更加简单了。
我们可以修改pageIndex这个锚点的值跳转到不同页面,对多个页面进行爬取。
话不多说,直接先上代码:
import urllib.request import json beginURL = 'https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1563246818490&countryId=&cityId=&bgIds=&productId=&categoryId=40001001,40001002,40001003,40001004,40001005,40001006&parentCategoryId=&attrId=&keyword=&pageIndex=' offset = 0 endURL = '&pageSize=10&language=zh-cn&area=cn' start_urls = beginURL + str(offset) + endURL headers = {'User-Agent': '自己找一个User-Agent'} while True: if offset < 2: offset += 1 else: break html = urllib.request.urlopen(start_urls, headers=headers) result = json.loads(html.read()) position = {} L = [] for i in range(len(result['Data']['Posts'])): position['职位名称'] = result['Data']['Posts'][i]['RecruitPostName'] position['最近公布时间'] = result['Data']['Posts'][i]['LastUpdateTime'] position['工作地点'] = result['Data']['Posts'][i]['CountryName'] + result['Data']['Posts'][0]['LocationName'] position['职位内容'] = result['Data']['Posts'][i]['Responsibility'] position['工作链接'] = result['Data']['Posts'][i]['PostURL'] L.append(position) print(L) with open('TencentJobs.json', 'a', encoding='utf-8') as fp: json.dump(L, fp, ensure_ascii=False)
我的思路大致是这样的:
首先从一个网页里面爬取到自己想要的数据,将第一个网页加载出来,html = urllib.request.urlopen(start_urls, headers=headers) result = json.loads(html.read()),将start-urls换成第一个网页的url就可以了,通过程序将网页得到的结果放在result里,然后从第一个网页进行分析,发现它里面的内容都是字典还有一个列表,那么通过字典和列表的索引方式找到我们想要的数据。例如,获得职位名称可以使用result['Data']['Posts'][i]['RecruitPostName'],再用一个一个position字典进行保存,后面依次类推。
将所有的字典都保存到一个列表L里面,然后再将L内数据写入到本地json文件中。对于多页面找到了锚点pageIndex,就通过一些手段每次某一页面爬取完就更改pageIndex爬取下一页。本程序通过更改offset的值,原网页应该有203个页面左右,我程序里面只爬取了两个页面,可以自行更改。
好了,如果使用了scrapy框架就会体会到python爬虫是多么的方便了。