当数据量比较小时,可以使用 7 :3 训练数据和测试数据,或者 6:2 : 2 训练数据,验证数据和测试数据。
(西瓜书中描述常见的做法是将大约 2/3 ~ 4/5 的样本数据用于训练,剩余样本用于测试)
当数据量非常大时,可以使用 98 : 1 : 1 训练数据,验证数据和测试数据。
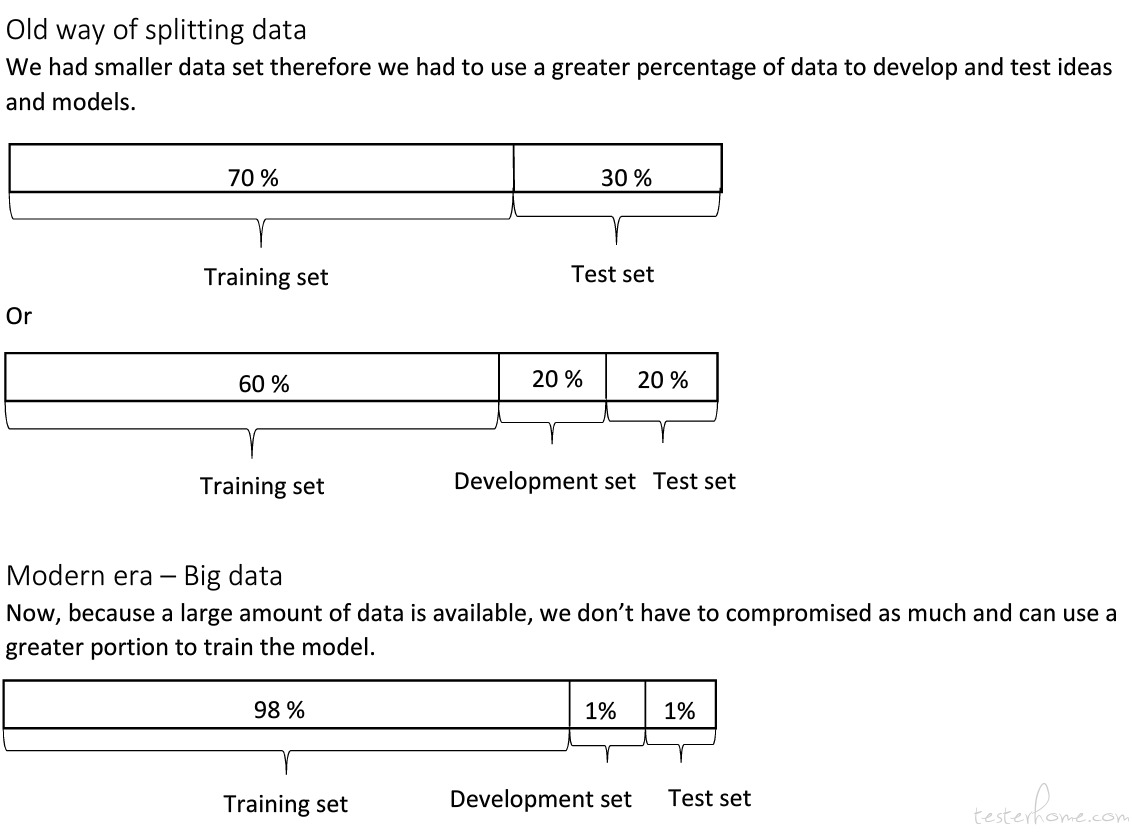
传统机器学习阶段(数据集在万这个数量级),一般分配比例为6:2:2。
而大数据时代,这个比例就不太适用了。因为百万级的数据集,即使拿1%的数据做test也有一万之多,已经足够了。可以那更多的数据做训练。因此常见的比例可以达到98:1:1 ,甚至可以达到99.5:0.3:0.2等。