【LevelDB Cache机制】
对于levelDb来说,读取操作如果没有在内存的memtable中找到记录,要多次进行磁盘访问操作。假设最优情况,即第一次就在level 0中最新的文件中找到了这个key,那么也需要读取2次磁盘,一次是将SSTable的文件中的index部分读入内存,这样根据这个index可以确定key是在哪个block中存储;第二次是读入这个block的内容,然后在内存中查找key对应的value。
levelDb中引入了两个不同的Cache:Table Cache和Block Cache。其中Block Cache是配置可选的,即在配置文件中指定是否打开这个功能。
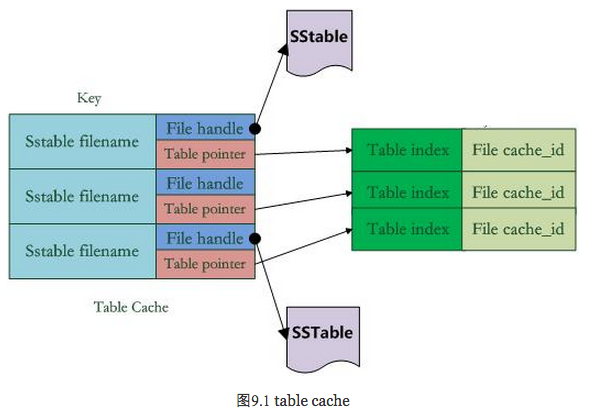
图9.1是table cache的结构。在Cache中,key值是SSTable的文件名称,Value部分包含两部分,一个是指向磁盘打开的SSTable文件的文件指针,这是为了方便读取内容;另外一个是指向内存中这个SSTable文件对应的Table结构指针,table结构在内存中,保存了SSTable的index内容以及用来指示block cache用的cache_id ,当然除此外还有其它一些内容。
比如在get(key)读取操作中,如果levelDb确定了key在某个level下某个文件A的key range范围内,那么需要判断是不是文件A真的包含这个KV。此时,levelDb会首先查找Table Cache,看这个文件是否在缓存里,如果找到了,那么根据index部分就可以查找是哪个block包含这个key。如果没有在缓存中找到文件,那么打开SSTable文件,将其index部分读入内存,然后插入Cache里面,去index里面定位哪个block包含这个Key 。如果确定了文件哪个block包含这个key,那么需要读入block内容,这是第二次读取。
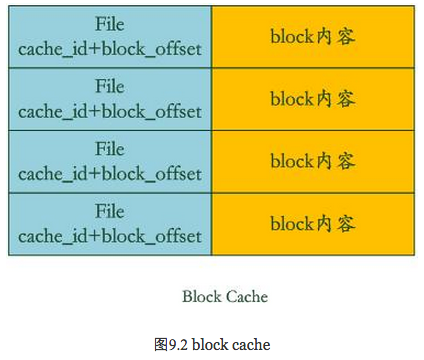
Block Cache是为了加快这个过程的,图9.2是其结构示意图。其中的key是文件的cache_id加上这个block在文件中的起始位置block_offset。而value则是这个Block的内容。
如果levelDb发现这个block在block cache中,那么可以避免读取数据,直接在cache里的block内容里面查找key的value就行,如果没找到呢?那么读入block内容并把它插入block cache中。levelDb就是这样通过两个cache来加快读取速度的。从这里可以看出,如果读取的数据局部性比较好,也就是说要读的数据大部分在cache里面都能读到,那么读取效率应该还是很高的,而如果是对key进行顺序读取效率也应该不错,因为一次读入后可以多次被复用。但是如果是随机读取,您可以推断下其效率如何。
参考:http://www.cnblogs.com/haippy/archive/2011/12/04/2276064.html