总体来说大概有以下2个大的步骤
1.连接集群(yarnrunner或者是localjobrunner)
2.submitter.submitJobInternal()在该方法中会创建提交路径,计算切片(writesplits),生成job.xml在路径下,提交job等
下面用windows下执行mr程序的过程进行源码分析,先把你的hadoop所在的盘符下的tmp文件清空.我的是d:/tmp
1.debug执行driver,进入waitForCompletion,然后进入conect(),可以看到该方法创建了一个新的集群对象
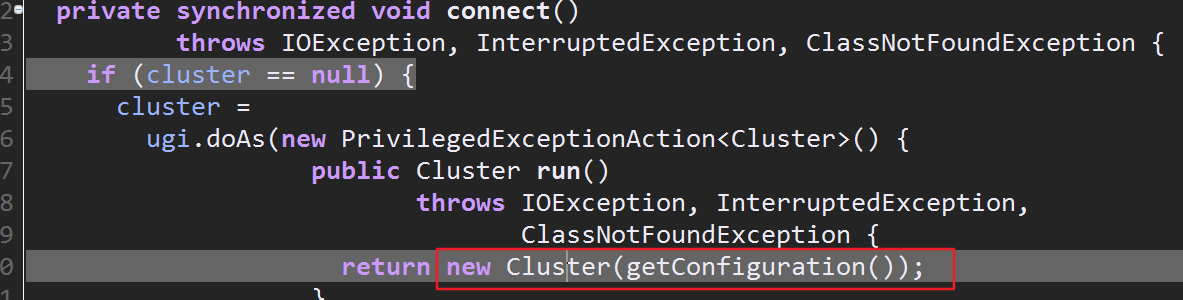
进入之后,来到Cluster类的构造方法里的initialize(),这个方法内部先初始化了包含着ClientProtocolProvider的list集合,然后遍历该集合,ClientProtocolProvider根据传入的conf来生成我们需要的ClientProtocol,这个对象用于客户端通信,该类的getClient()会返回创建完成的ClientProtocol实例

到这可以确定,connect方法的作用就是连接集群,本地的话就是localJobRunner,yarn上的话就是yarnrunner
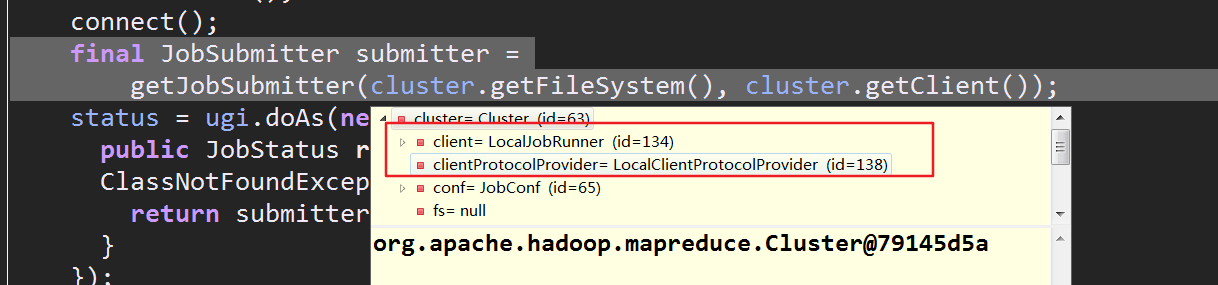
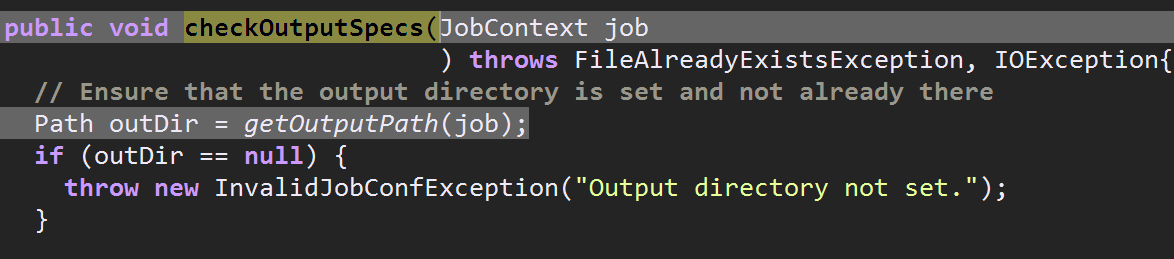
生成的submitter是真正用于提交job的对象,接下来进入关键的submitter.submitJobInternal(Job.this, cluster),其内部第一行代码执行了checkSpecs(),该方法中用checkOutputSpecs()检查输出路径,
回到submitJobInternal(),getStagingDir()初始化提交数据的路径,还有一些权限管理的东西

这行代码执行完毕后,来到d:/tmp,发现果然创建了路径,当然目前还创建jobId,切片,所以目录是空的

接着向下执行完getNewJobId,生成了一个jobId,这个jobId将会赋给submitJobDir用于创建路径


接着向下执行,进入copyAndConfigureFiles(),该方法会创建路径并做一些上传的工作,包括各种配置文件,如果连接的yarn还会上传jar包
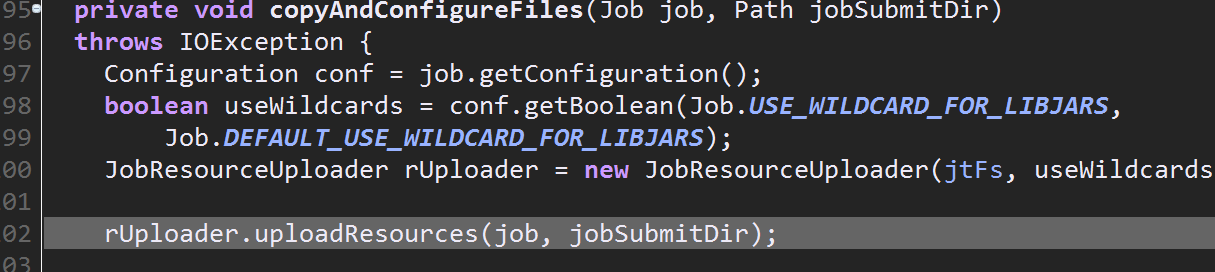
依次进入uploadResource()--------->uploadResourcesInternal
在uploadResourceInternal中执行完mkdirs,发现生成了jobId的目录,当然该目录仍然是空的
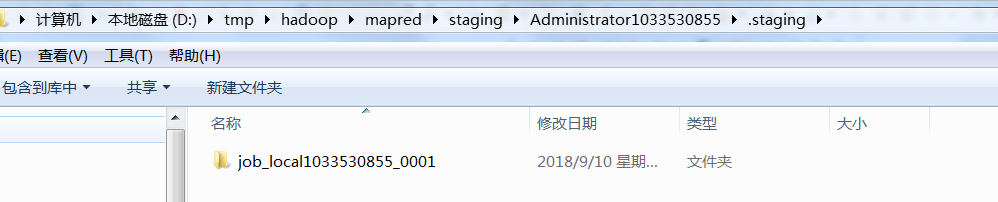
好了,接下来仍然回到submitJobInternal(),配置文件名为job.xml(此时并没有真正生成文件在磁盘目录下)

仅接着进入wirteSplits(),切片从这里开始

进入writeSplits()后再进入writeNewSplits(),进入input.getSplits(job)中,切片过程都在这个方法里了,

先分析long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));求最大值,getFormatMinSplitSize()的返回值是1,getMinSplitSize(job)返回的是你在mapred-site.xml中配置的
mapreduce.input.fileinputformat.split.minsize的value值,默认是0,所以long minsize=1

而 long maxSize = getMaxSplitSize(job);中getMaxSplitSize返回的是Long的最大值所以maxSize=9223372036854775807

接着向下执行,可以看到此时的blocksize是32MB(因为是本地模式),

进入computeSplitSize()这是切片中我感觉最诡异的地方,上面我们说了minSize=1,maxSIze=Long.MaxValue>blockSize=32*1024*1024

所以返回值是blockSize,这也是为什么默认的切片大小等同于blockSize,接着向下就是切几片的问题,可以看到只有当字节数除以切片大小大于1.1时才会增加一片,否则整体作为一个切片
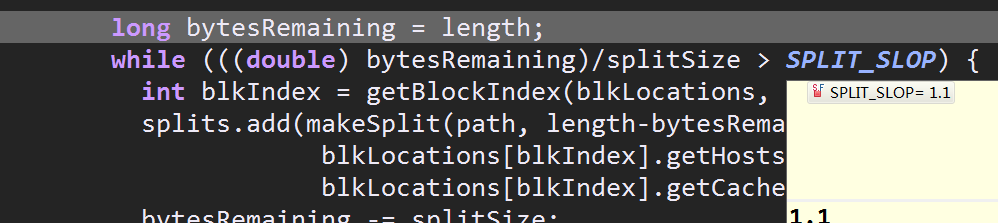
所以当剩余的大小除以切片数小于1.1时,这些剩余的字节将会整体作为一个切片加入切片的list中
回到submitJobInternal()执行完writesplite后,发现目录下多了些切片的规划文件,这些文件将会用来计算开启的maptask个数
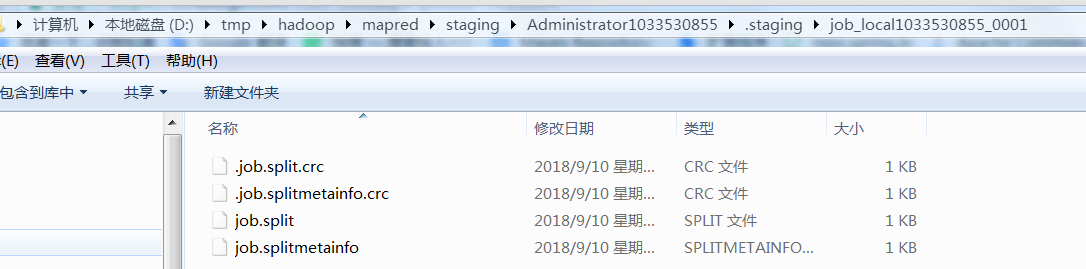
接着向下执行完writeConf会把job.xml写入到目录下

现在这些文件马上要消失了,因为接下来要执行submitJob(),提交后文件会被清除
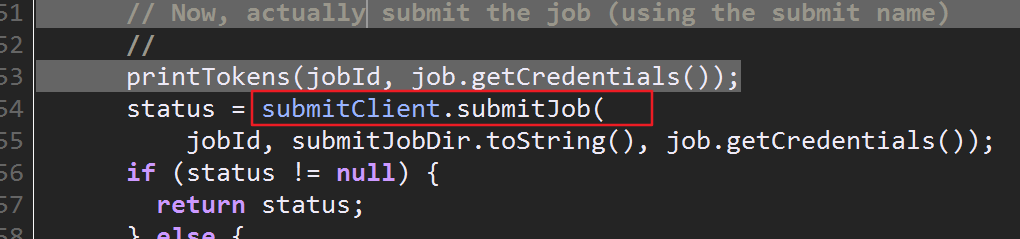
提交后会生成一个hadoop-用户的目录,查看了下这个目录也是空的,大概是用来记录连接记录之类的吧

到这提交过程基本就完成了,等待执行MapReduce程序即可