在进行流量排序之前,先要明白排序是发生在map阶段,排序之后(排序结束后map阶段才会显示100%完成)才会到reduce阶段(事实上reduce也会排序),.此外排序之前要已经完成了手机流量的统计工作,即把第一次mr的结果作为本次排序的输入.也就是说读取的数据格式为 手机号 上行流量 下行流量 总流量
1,map阶段,读取并封装流量信息,不同的是context.write()时key必须是封装的实体类,而不再是手机号
1 /**
2 * 输入key 行号
3 * 输入value 流量信息
4 * 输出key 封装了流量信息的FlowBean
5 * 输出value 手机号
6 * @author tele
7 *
8 */
9 public class FlowSortMapper extends Mapper<LongWritable,Text,FlowBean,Text>{
10 FlowBean flow = new FlowBean();
11 Text v = new Text();
12 //读取的内容格式 手机号 上行流量 下行流量 总流量
13 @Override
14 protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, FlowBean, Text>.Context context)
15 throws IOException, InterruptedException {
16
17 //1.读取
18 String line = value.toString();
19
20 //2.切割
21 String[] split = line.split(" ");
22 String upFlow = split[1];
23 String downFlow = split[2];
24 String phoneNum = split[0];
25
26 //3.封装流量信息
27 flow.set(Long.parseLong(upFlow),Long.parseLong(downFlow));
28
29 v.set(phoneNum);
30
31 //4.写出
32 context.write(flow,v);
33
34 }
35 }
2.map之后会根据key进行排序,因此如果要实现自定义排序,必须让定义的bean实现WritableComparable接口,并重写其中的compare方法,我们只需要告诉MapReduce根据什么排序,升序还是降序就可以了
具体的排序过程由MapReduce完成
1 public class FlowBean implements WritableComparable<FlowBean>{
2 private long upFlow;
3 public long getUpFlow() {
4 return upFlow;
5 }
6 public void setUpFlow(long upFlow) {
7 this.upFlow = upFlow;
8 }
9 public long getDownFlow() {
10 return downFlow;
11 }
12 public void setDownFlow(long downFlow) {
13 this.downFlow = downFlow;
14 }
15 public long getSumFlow() {
16 return sumFlow;
17 }
18 public void setSumFlow(long sumFlow) {
19 this.sumFlow = sumFlow;
20 }
21 private long downFlow;
22 private long sumFlow;
23
24 /**
25 * 反序列化时需要通过反射调用空参构造方法.必须有空参构造
26 */
27 public FlowBean() {
28 super();
29 }
30
31 public FlowBean(long upFlow, long downFlow) {
32 super();
33 this.upFlow = upFlow;
34 this.downFlow = downFlow;
35 this.sumFlow = upFlow + downFlow;
36 }
37
38 public void set(long upFlow, long downFlow) {
39 this.upFlow = upFlow;
40 this.downFlow = downFlow;
41 this.sumFlow = upFlow + downFlow;
42 }
43
44
45 /**
46 * 序列化与反序列化顺序必须一致
47 */
48
49
50 //序列化
51 @Override
52 public void write(DataOutput output) throws IOException {
53 output.writeLong(upFlow);
54 output.writeLong(downFlow);
55 output.writeLong(sumFlow);
56
57 }
58
59
60 //反序列化
61 @Override
62 public void readFields(DataInput input) throws IOException {
63 upFlow = input.readLong();
64 downFlow = input.readLong();
65 sumFlow = input.readLong();
66 }
67
68 /**
69 * reduce context.write()会调用此方法
70 */
71 @Override
72 public String toString() {
73 return upFlow + " " + downFlow + " " + sumFlow;
74 }
75
76
77 @Override
78 public int compareTo(FlowBean o) {
79 // -1表示不交换位置,即降序,1表示交换位置,升序
80 return this.sumFlow > o.getSumFlow() ? -1:1;
81 }
82
83 }
3.reduce阶段,map阶段会对输出的value根据key进行分组,具有相同key的value会被划分到一组,这样reduce阶段执行一次reduce()读取一组,由于map阶段输出的key是定义的FlowBean,因此key是唯一的,从而
每组只有一个值,即Iterable<Text> value中只有一个值,也就是只有一个手机号
1 /**
2 * 输出的格式仍然为 手机号 上行流量 下行流量 总流量
3 * @author tele
4 *
5 */
6 public class FlowSortReducer extends Reducer<FlowBean,Text,Text,FlowBean>{
7 /**
8 * reduce阶段读入的仍然是一组排好序的数据
9 * 前面map阶段输出的结果已根据key(FlowBean)进行分组,但由于此处key的唯一
10 * 所以一组只有一个数据,即 Iterable<Text> value 中只有一个值
11 */
12 @Override
13 protected void reduce(FlowBean key, Iterable<Text> value, Reducer<FlowBean, Text, Text, FlowBean>.Context context)
14 throws IOException, InterruptedException {
15
16 //输出
17 Text phone = value.iterator().next();
18 context.write(phone,key);
19
20
21 }
22 }
下面进行debug,在map(),reduce()方法的开始与结束均打上断点,在FlowBean的compareTo()中也打上断点
map读取的内容
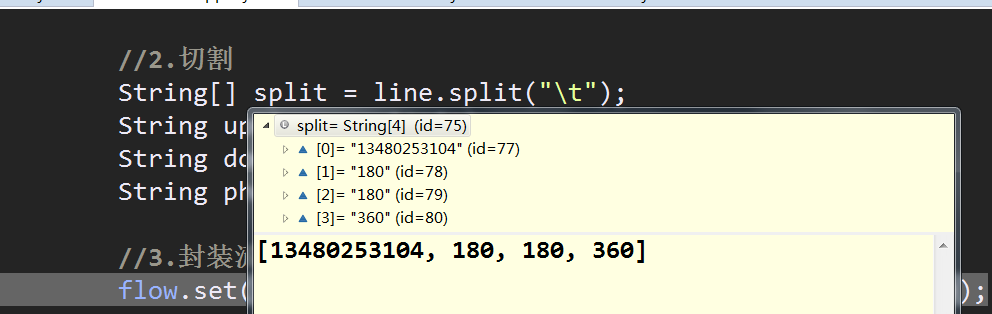
写出,注意key是FlowBean对象
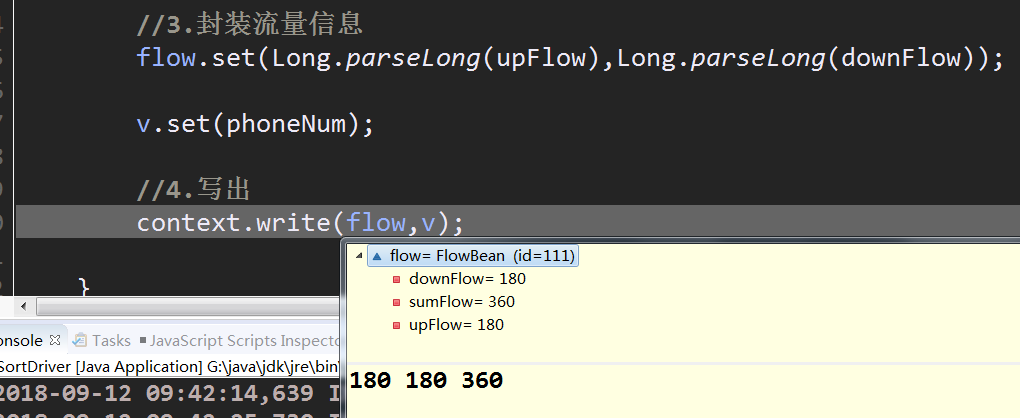
接下来是排序,可以看到排序时map仍然不是100%,也就是说map阶段进行了排序(reduce阶段也会进行排序)

排序之后进入reduce阶段,reduce时write会调用FlowBean的toString()把结果输出到磁盘上
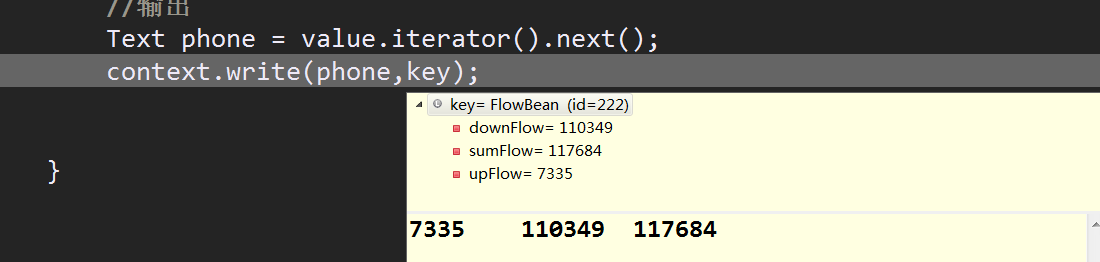

reduce除了归并排序之外,在执行write时同样会进行一次排序,执行第一组的write,(会调用FlowBean的toString()).但接下来还会去执行compareTo方法,此时在磁盘上生成的是临时目录,并且生成的part000文件是0KB,在执行完第二组的write之后才会真正把第一组数据写出到磁盘上
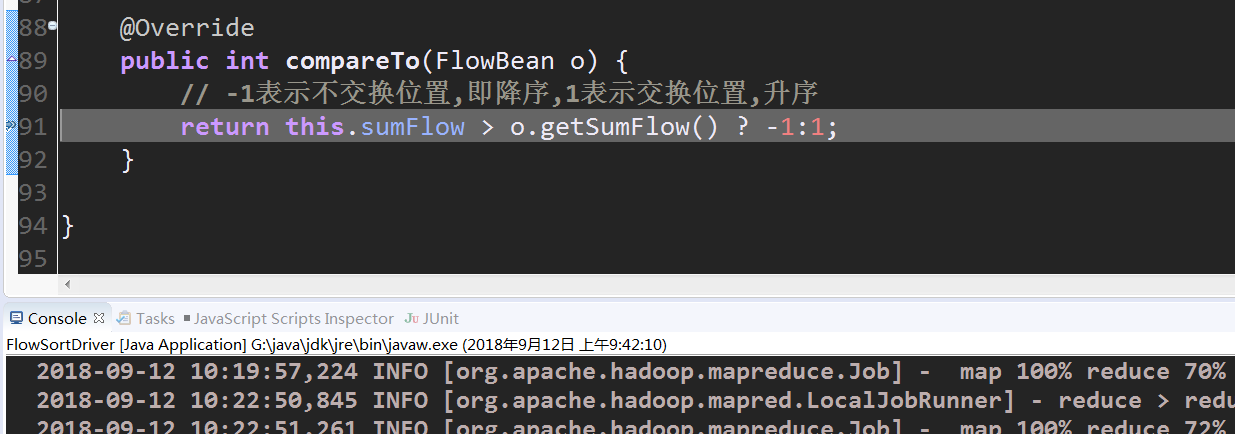


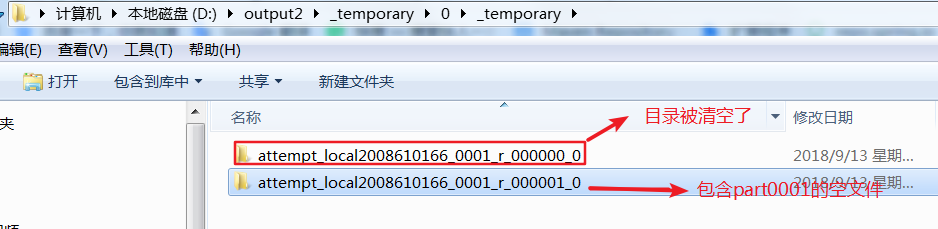
part000此时有了数据
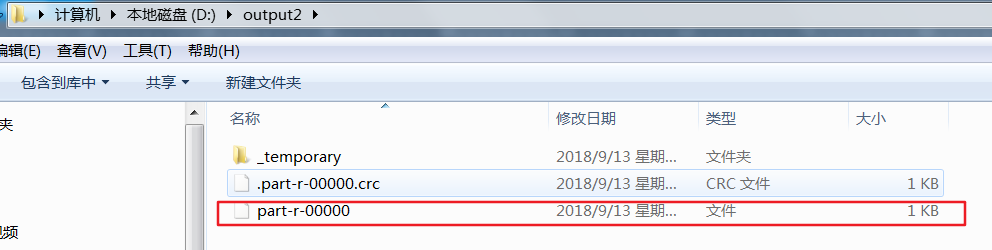
这样看来我们重写的compareTo方法无论在map阶段还是reduce阶段都被调用了