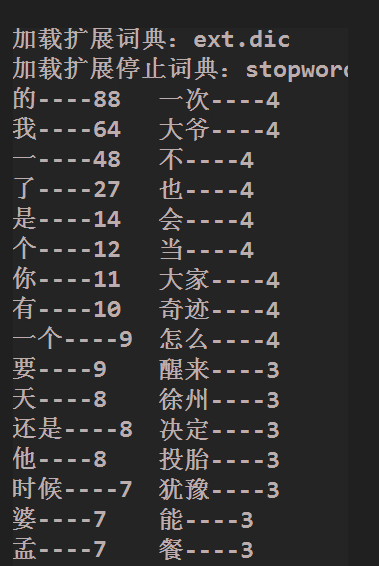
1 public class WordCount {
2 static Directory directory;
3 // 创建分词器
4 static Analyzer analyzer = new IKAnalyzer();
5 static IndexWriterConfig config = new IndexWriterConfig(analyzer);
6 static IndexWriter writer;
7 static IndexReader reader;
8 static {
9 // 指定索引存放目录以及配置参数
10 try {
11 directory = FSDirectory.open(Paths.get("F:/luceneIndex"));
12 writer = new IndexWriter(directory, config);
13 } catch (IOException e) {
14 e.printStackTrace();
15 }
16 }
17
18 public static void main(String[] args) {
19 indexCreate();
20 Map<String, Long> map = getTotalFreqMap();
21 Map<String, Long> sortMap = sortMapByValue(map);
22 Set<Entry<String, Long>> entrySet = sortMap.entrySet();
23 Iterator<Entry<String, Long>> iterator = entrySet.iterator();
24 while (iterator.hasNext()) {
25 Entry<String, Long> entry = iterator.next();
26 System.out.println(entry.getKey() + "----" + entry.getValue());
27 }
28
29 }
30
31 /**
32 * 创建索引
33 */
34 public static void indexCreate() {
35 // 文件夹检测(创建索引前要保证目录是空的)
36 File file = new File("f:/luceneIndex");
37 if (!file.exists()) {
38 file.mkdirs();
39 } else {
40 try {
41 file.delete();
42 } catch (Exception e) {
43 e.printStackTrace();
44 }
45 }
46
47 // 将采集的数据封装到Document中
48 Document doc = new Document();
49 FieldType ft = new FieldType();
50 ft.setIndexOptions(IndexOptions.DOCS_AND_FREQS);
51 ft.setStored(true);
52 ft.setStoreTermVectors(true);
53 ft.setTokenized(true);
54 // ft.setStoreTermVectorOffsets(true);
55 // ft.setStoreTermVectorPositions(true);
56
57 // 读取文件内容(小文件,readFully)
58 File content = new File("f:/qz/twitter.txt");
59 try {
60 byte[] buffer = new byte[(int) content.length()];
61 IOUtils.readFully(new FileInputStream(content), buffer);
62 doc.add(new Field("twitter", new String(buffer), ft));
63 } catch (Exception e) {
64 e.printStackTrace();
65 }
66
67 // 生成索引
68 try {
69 writer.addDocument(doc);
70 // 关闭
71 writer.close();
72
73 } catch (IOException e) {
74 e.printStackTrace();
75 }
76 }
77
78 /**
79 * 获得词频map
80 *
81 * @throws ParseException
82 */
83 public static Map<String, Long> getTotalFreqMap() {
84 Map<String, Long> map = new HashMap<String, Long>();
85 try {
86 reader = DirectoryReader.open(directory);
87 List<LeafReaderContext> leaves = reader.leaves();
88 for (LeafReaderContext leafReaderContext : leaves) {
89 LeafReader leafReader = leafReaderContext.reader();
90
91 Terms terms = leafReader.terms("twitter");
92
93 TermsEnum iterator = terms.iterator();
94
95 BytesRef term = null;
96
97 while ((term = iterator.next()) != null) {
98 String text = term.utf8ToString();
99 map.put(text, iterator.totalTermFreq());
100 }
101
102 }
103 reader.close();
104 return map;
105 } catch (IOException e) {
106 e.printStackTrace();
107 }
108 return null;
109 }
110
111 /**
112 * 使用 Map按value进行排序
113 *
114 * @param map
115 * @return
116 */
117 public static Map<String, Long> sortMapByValue(Map<String, Long> oriMap) {
118 if (oriMap == null || oriMap.isEmpty()) {
119 return null;
120 }
121 Map<String, Long> sortedMap = new LinkedHashMap<String, Long>();
122
123 List<Map.Entry<String, Long>> entryList = new ArrayList<Map.Entry<String, Long>>(oriMap.entrySet());
124 Collections.sort(entryList, new MapValueComparator());
125
126 Iterator<Map.Entry<String, Long>> iter = entryList.iterator();
127 Map.Entry<String, Long> tmpEntry = null;
128 while (iter.hasNext()) {
129 tmpEntry = iter.next();
130 sortedMap.put(tmpEntry.getKey(), tmpEntry.getValue());
131 }
132 return sortedMap;
133 }
134 }
135
136 class MapValueComparator implements Comparator<Map.Entry<String, Long>> {
137
138 @Override
139 public int compare(Entry<String, Long> me1, Entry<String, Long> me2) {
140 if (me1.getValue() == me2.getValue()) {
141 return 0;
142 }
143 return me1.getValue() > me2.getValue() ? -1 : 1;
144 // return me1.getValue().compareTo(me2.getValue());
145 }
146 }
map排序代码https://www.cnblogs.com/zhujiabin/p/6164826.html