数据库的存储有两种方式,一个是按行存储、一个是按列存储:
按行存储表:每行数据存储所有列、一次磁盘IO可以访问一行中所有列、适合OLTP场景。
按列存储表:每列单独存储,多个列逻辑组成一行;一次磁盘IO只包含一列数据;方便做数据压缩;适合OLAP场景。

TDSQL-A支持按列存储和按行存储两种方式来建表,同时在列表和行表之间,用户不用感知到下层的表是通过行表还是列表来建,行表和列表之间可以进行无缝的互操作——包括相互关联、相互交换数据,完全不需要感知到底下的存储逻辑。
除了操作的便利性之外,行表和列表之间混合查询还能保持完整的事务一致性,也就是说在查询运行的同时,整个事务(ACID)的能力也得到完整的保证。
TDSQL-A列存储压缩能力降低业务成本
作为OLAP场景下的产品来说,压缩是一项非常重要的能力,这里介绍TDSQL-A的列存储压缩能力。
目前我们支持两种压缩方式:
一是轻量级压缩。这是能够感知到数据内容的一种压缩方式。它可以针对用户数据的特点提供合适的压缩方式来降低用户的成本,在有规律时达到数百倍的压缩比。我们可以针对特殊的数据,比如重复率比较高的或者是有规律、有顺序的数据进行轻量级压缩。
二是透明压缩。透明压缩主要是用zstd和gzip压缩算法来提供压缩能力,可以帮用户进一步去压缩成本,提升处理效率。
** 延迟物化原理**
在分布式场景下,特别是超大规模分布式场景下,网络IO和CPU其实是非常重要的资源。如果在计算时,网络IO达到了瓶颈,或者CPU达到了瓶颈,都会从整体上影响集群的扩展性和集群的处理能力。
目前用数据库或数据仓库进行查询时,很多使用的都是提前物化。所谓的提前物化是相对于查询来说的。其在数据库里面会分解成几步:第一步需要从下面最底层的表里面把数据查询出来,再进行关联,join完成之后再进行投影,传给上层要使用的一些列。
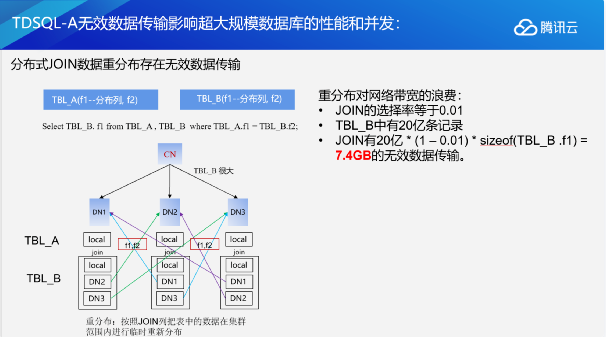
可以看到,在进行join时我们其实只关联了表b的f2这一列,但是投影时却投影了表b的f1这一列。这时对之前的数据库进行提前物化时,在传递数据给join时,我们就会把表b的f1和f2都吐出来。因为我们计算发现上层project需要f1这一列,但是join这里需要f2这一列,所以它就会把上层需要的所有列全部在这里算出来。但实际上如果在这个地方关联时过滤的比例很高的话,比如说现在有1%的满足率,其实大部分的f1是没有意义的,因为最终在这里通过join会被抛弃掉。在超大规模的分布式场景下,如果表里面有20亿条记录,选择率是0.01的话,这个时候就会有7.4GB的无效数据传输。对于十分依赖网络传播的分布式数据库来说,7.4个GB已经是非常可观的开销了。

因此我们引入了另外一种物化算法,即延迟物化。延迟物化可以简单理解为不见兔子不撒鹰。所谓的不见兔子不撒鹰,就是在投影的时候只拉去满足条件的那些数据,减少中间这7.4个GB的传输。这就要我们在进行Scan时,只看上层join节点需要的一些列,把它传递到上层节点去,join完成之后把满足条件的那些列的位置信息传递给上层的project节点。根据我们的测试,随着表变得越来越复杂,随着查询变得越来越复杂,表变得越来越大,我们优化的效果也越来越明显。
TDSQL-A全并行能力、向量化计算能力
除了上面的延迟物化外,我们还引入了系统的全并行能力。全并行能力对数据库的OLAP场景数据库来讲是一个必经之路。MPP架构让我们具备了多节点并行的架构优势,同时我们还通过优化做到了节点内部的多进程进程间的进行,并在内部使用了CPU的特殊指令做到指令级并行,因此TDSQL-A可以做到三级并行,依次是:节点级并行,进程级并行以及指令级并行。这种全并行的能力能够进一步提升我们整体的处理效率。
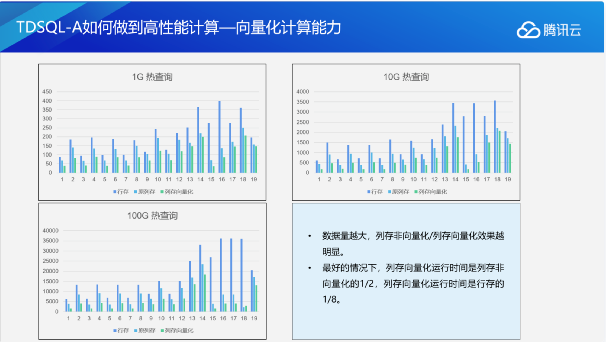
向量化计算能力在OLAP上也是一个必须探讨的课题。TDSQL-A也进行了一些新的尝试,并实现了向量化计算能力:数据量越大,列存非向量化和列存向量化效果越明显,在最好的情况下,列存向量化运行时间是列村非向量化的1/2,列存向量化运行时间是行村的1/8。列存储的向量化执行能够达到行存储执行1/8左右。向量化计算能力对整个OLAP性能的提升是非常明显的。
TDSQL-A的多平面能力提供一致的读扩展性
在整体架构上,TDSQL-A也提供了比较好的一致性的读扩展能力。
一致性的读扩展能力是跟随业务场景的催生的技术特性。有一些客户反映过这种的情况,就是在数据库CPU,内存已经用满的情况下,还有更多的业务请求要加进来。为了满足这种读的扩展性需要,我们就研发出了能够提供读取能力的多平面特性,简单理解就是在读写平面的基础上,通过内部复制的方式来创建出一个只读平面,去处理只读的请求。相比之前新建数据库集群的方式,这种做法在降低了业务成本和系统复杂度的同时,也帮助客户解决了很多现实的问题。
TDSQL-A整体技术架构小结
TDSQL-A整体的技术架构可以总结成六点:
通过集中式的网络架构、网络融合通信技术以及后面在执行级层面引入的能力,可以进一步去拓展分布式MPP数据仓库的存储规模的上限,达到数千台的规模;
通过向量化技术,底层整个执行级的逻辑优化,做到极速OLAP的响应;
在存储层面通过多种高效的数据压缩方式,提供极高的压缩比,帮助业务去节省经营成本;
在接口层面完整兼容了SQL2003,同时对ORALE语法兼容性达到95%,包括存储过程、触发器等一系列内容;
支持行列混合存储及行列混合操作的能力;
借助特有能力去访问外部数据源,包括分布式对象存储,HDFS存储等,能够实现存储与计算分离。
TDSQL-A后续规划
TDSQL-A的后续规划分为两部分:
一方面是陆续将目前基于PG10的版本,merge到PG11、PG12、PG13等更高版本,持续地跟进社区版本丰富的特性,来提升用户的体验,为客户创造更多价值。
另一方面,随着硬件技术的不断发展,包括GPU、FGA以及APE这些新硬件的发展,给我们创造了为客户创造更高价值可能性,TDSQL-A也希望通过引入新硬件,来提升产品竞争力,为客户提供更好的服务。