高性能缓存数据库
数据存在内存条不在磁盘上
10万每秒
持久化保证数据不丢失
特性: 1〉速度快 2〉键值对的数据结构服务器 3〉丰富的功能: 4〉简单稳定 5〉持久化 6〉主从复制 8〉高可用和分布式转移 9〉客户端语言多
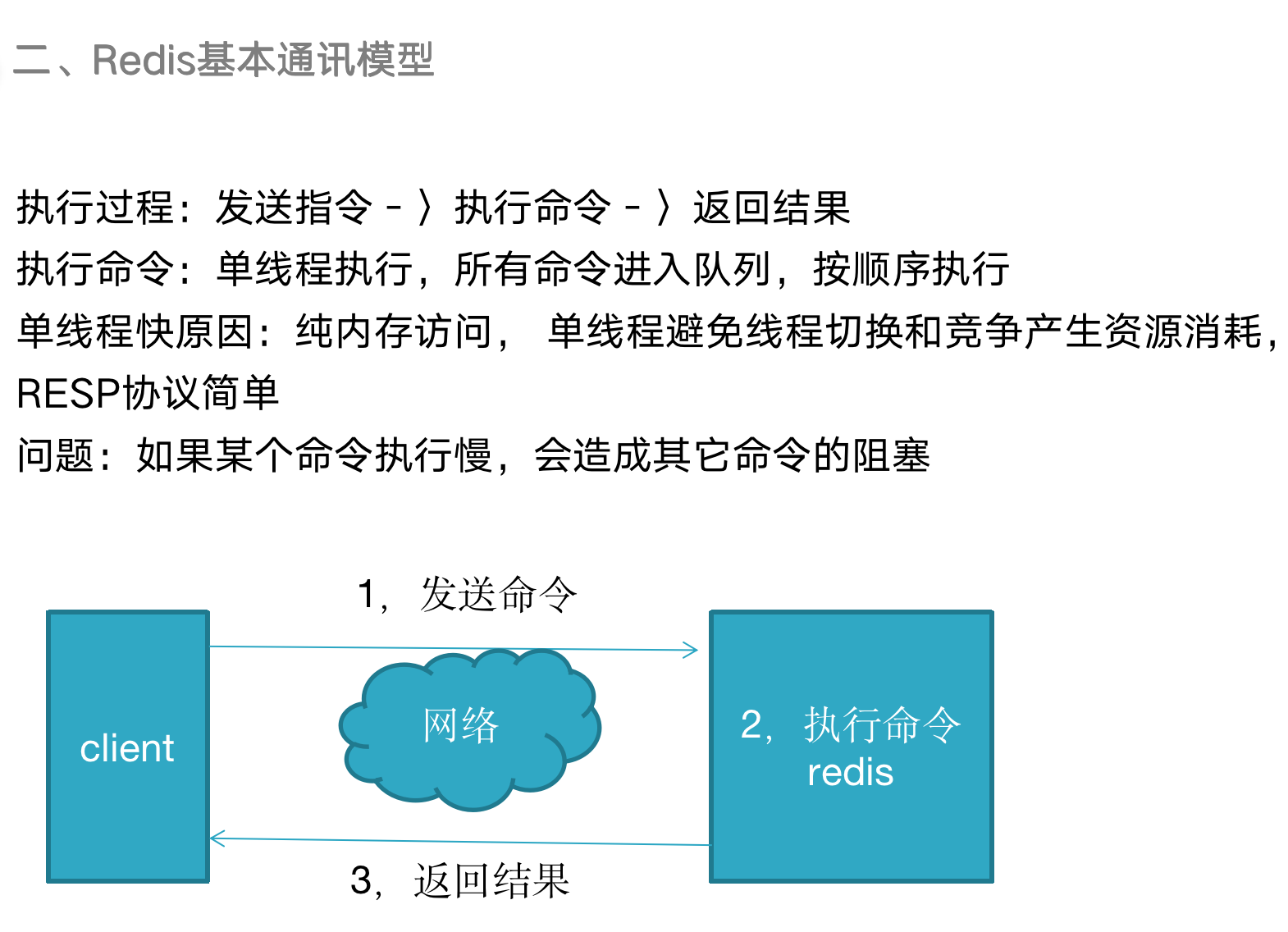
二、使用场景
1,缓存数据库: 2,排行榜 3,计数器应用 4,社交网络 5,消息队列
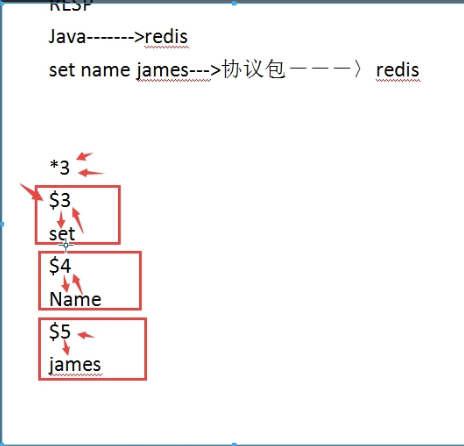
RESP协议:封装了条数 长度(tcp 报文格式 人类可读)
单线程:问题 等待 阻塞
内部: 队列
key唯一:value 五种
string
分布式锁 基于设置过期时间
flushdb 清除数据库
单个设置:效率问题. 建立连接 网络消耗时间特别多
一次性批量设置 mset
字符串的追加:append getrange
哈希表
哈希hash是一个string类型的field和value的映射表,hash特适合用于存储对象
map.put() --->不要序列化 ------ redis
用哈希

失效时间:expire user:1 10
实现用户信息存储:使用hash类型,简单直观,使用合理可减少内存空间消耗。解决了对象序列化存入redis,序列化与反序列化的开销依旧更新属性时需要把userInfo全取出来进行反序列化,更新后再序列化到redis的麻烦。但是后面(value值在一定范围内编码格式会变,超过一定的内存,512M)发现hash类型需要要控制ziplist与hashtable两种编码转换,且hashtable会消耗更多内存erialize(userInfo);

可以设置失效时间
列表<list>
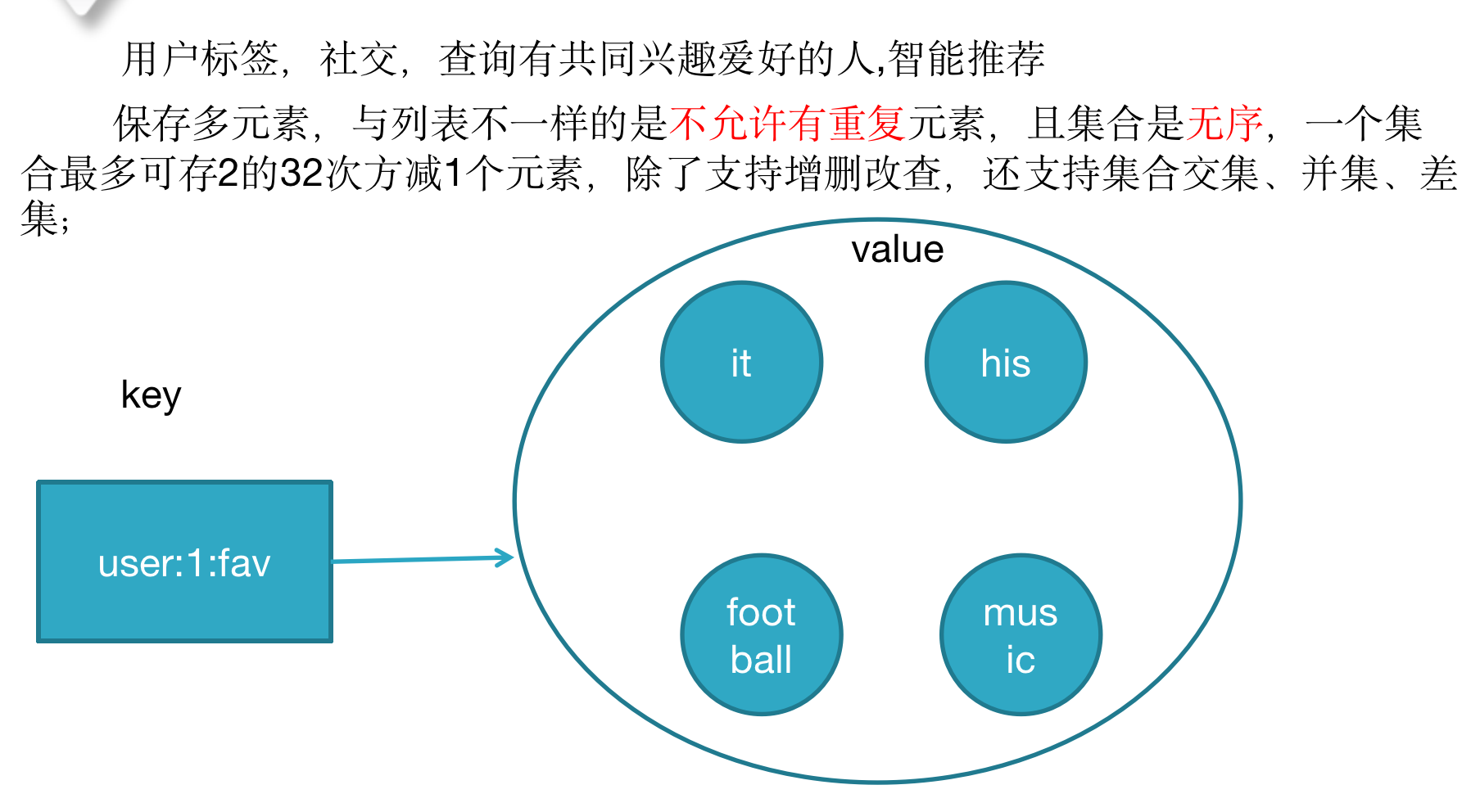
集合<set>
二维表(hash)
zset(有序集合)
时间 用时间戳
数据库慢查询
玩掏空的
order by 可以排序的值.
key ---> value. 分值

键可以匹配 *。相当于模糊查询
redis 有16个数据库 默认0
select 15
实战:

关系数据库设计: 常规设计 orderby慢查询 显然不满足需求
![]()

key的设计:内存数据库 内存昂贵 key和value都会占内存
key设计:越短越好 表达含义(闻鸡起舞)
与你的业务模块 功能模块 表
key和value优化(注意留文档,不然别人看不懂)
key并不一定是hash
order
Zadd tm.or:001(根据业务,两级就够了)

记录已投票用户,防重投
已对002文章投票过的用户,使用SET存储(无序,不能重复)
要点:并没有直接记录用户编号,而是记录用户对应的key值,先检查当前用户存不存在,存在就不让投了。
要点:order by 有时间时要转化成时间戳 (能转成整型的尽量) 提高性能
总体设计:
文章:涉及到基本信息 设计到hash
二维数据存储

缓存数据变化:
已投票用户 set集合里
key 唯一标示 雪花算法 自增uuid
操作要与唯一标示绑定
expire方法 设置失效时间
投票
查一下用户是否已经投过票
没有直接去判断而是直接往里头丢数据,不需要去查
因为当你往里头丢数据,如果你真的插入成功,会返回1,通过对1的判断
即判断了又插入了