JVM的启动
绝大部分的大数据技术都是建立在Java的JVM之上的。所以,我们对JVM的启动的了解是非常有必要的,当然,我们也不用非常深入的去了解这个,我们只需要把握两个非常关键的点即可:
- 我们只能通过java命令来启动一个JVM,比如:当执行java com.twq.HelloWorld就会启动一个JVM,然后在这个JVM上执行com.twq.HelloWorld中main方法中的程序代码
- 当启动的一个JVM需要参数的时候,我们可以通过java命令的参数设置来提供参数。比如,我们可以通过-Xmx300M来设置启动的JVM的堆内存大小、我们可以通过-cp参数来设置启动的JVM需要依赖的额外的Java字节码文件、我们还可以通过-D的方式来设置我们的程序需要的一些参数
java -cp C:\bigdata-course\workspace\hdfs-course\target\hdfs-course-1.0-SNAPSHOT.jar -Dname=yellow -DsleepDuration=5 -Xmx300m com.twq.basic.launcher.JvmLauncherTest
当使用java命令启动了一个JVM之后,执行的是我们指定的主类中的main方法中的程序代码,这个方法里面的程序可以简单到只打印Hello World,当然,也可以复杂到任何其他复杂的程序,这个就取决于业务场景了。
RPC
启动的JVM可以做任何复杂的程序业务,当一个JVM之上的程序业务满足不了需求的时候,我们可能再需要启动一个JVM程序或者再启动多个JVM程序,这些JVM程序之间是需要相互通讯,然后协调的完成业务需求,这个时候就会涉及到了JVM与JVM之间的通讯技术了,就是我们常用的RPC技术
RPC是英文单词Remote Procedure Call的缩写,翻译成中文就是远程过程调用的意思,其实就是远程程序的调用执行的意思,RPC是和程序语言没关系的,绝大部分程序语言都可以支持RPC。如果用在Java语言中,那么RPC的意思就是JVM与JVM之间的通讯了。
RPC技术的基础是Socket网络编程,Java语言也是支持Socket编程的,一个服务端程序和一个客户端程序,这两个程序是分别不同的两个JVM中运行的,客户端所在的JVM可以通过Socket技术向服务端所在的JVM上发送消息,服务端接收消息后就可以处理消息,然后还可以选择是否将结果返回给客户端,这个就是一个典型的JVM之间的通讯的场景。
在JVM之间通过Socket进行通讯的时候,当然需要指定协议,客户端肯定不能发送服务端不能处理的消息吧。客户端也不能接收不能处理的消息吧。所以基于RPC的技术,服务端金额客户端之间肯定是会有协议的
当然,在真实的实现RPC的时候,我们不会使用原生的Socket编程,我们会使用对Socket进行了封装的并且成熟了的工业级RPC框架,比如netty等
分布式存储原理
分布式存储解决的就是大量数据存储的问题了。这个量一般是TB、PB级别
1PB = 1024TB;1TB = 1024GB;1GB = 1024M
如果一个文件的数据量比较小,那么一台机器就可以存储的下,当这个文件的数据量越来越大的时候,等大到一台机器存储不下的时候,这个时候就需要分布式的存储。
比如,我们现在有一个大文件,它的数据量是5PB。这个时候一台机器肯定是存储不下的。那我们可以将这5PB的数据文件划分成若干个小块,假设每一个块的大小是256M,那么5PB的数据文件就被划分成20971520个数据块了,我们可以将这么多的数据块分布式的存储在1000台机器上(假设每台机器的磁盘容量是10TB),大约每一台机器存储2万多一点的数据块。
数据分块,分布式的存储在多态机器上,这就是分布式存储的第一个特点。
假设上面1000台机器中有一台机器挂掉了,那么存在于这台机器上的数据块都不能对外提供服务了,这样的话5PB的文件的数据就不完整了。那么为了解决这个问题,我们可以将每一个数据块再备份一个,然后两个相同的数据块分别存储在不同的机器上,这样的话一个数据块所在的机器挂了,那么另一个机器上的相同的数据块还可以对外提供服务。这样做就可以容错了,提高了数据块的高可用性
数据块冗余存储在多台机器以提高数据块的高可用性,这就是分布式存储的第二个特点
现在问题又来了,这么多的机器节点以及存储在机器节点上的这么多数据块该怎么管理呢?我们可以在另外的一台服务器上启动一个JVM进程,这个JVM进程就是负责管理所有存储数据的机器节点以及存储在这些机器节点上的所有数据块,如下图:
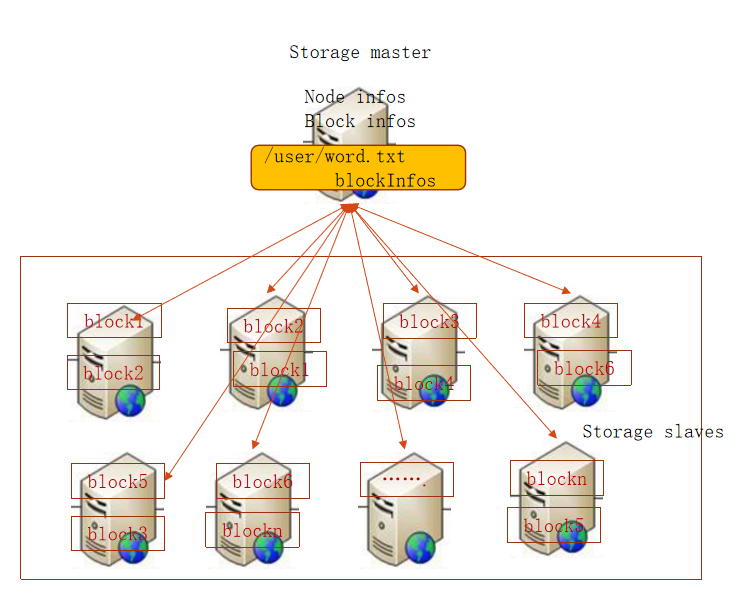
上图中的Storage master就是负责管理所有的存储数据的机器以及所有的数据块,所以在Storage master中会存在:机器节点的信息(Node Info) 以及 数据块信息(Block Info)
上图中的Storage slaves就是负责数据块的存储,当Storage slaves中的每一个机器启动了后都会将自己所含有的磁盘容量等信息告诉Storage master机器,当每一个数据块存储在某个Storage slave上时都会把自己的信息告诉Storage master机器。
所以分布式存储的第三个特点就是:遵从主/从(master/slave)结构的分布式存储集群
这里一定要明白的三点是:
- 在Storage master和Storage slave上都是会启动一个JVM进程,在Storage master机器上,这个JVM进程负责机器节点和数据块的管理;在Storage slave上的JVM进程负责数据块的存储服务
- Storage master上的JVM进程和Storage slave上的JVM进程之间的通讯是通过RPC完成的。当然两个不同Storage slave机器上的JVM进程也是有可能通过RPC进行通讯的(需要将一个数据块备份,然后将这个备份的数据块通过RPC传输到另一个slave机器中)
- 所以说,分布式存储的基础就是我们前面讲到的两点:JVM的启动 以及 RPC。当然我们以后碰到的大数据技术的基础基本也都是JVM的启动 以及 RPC
总结分布式存储的特点
- 数据分块,分布式的存储在多台机器上
- 数据块冗余存储在多台机器以提高数据块的高可用性
- 遵从主/从(master/slave)结构的分布式存储集群
分布式存储中的文件
在遵从主/从(master/slave)结构的分布式存储集群中,其实存在两种类型的文件:
- 真实存放数据的文件,这类文件都是存储在slave上的文件,我们称之为物理文件
- 相对于存储在slave上的文件,那么在master上其实也有一个文件的概念,这个文件不是存储数据的文件,它是一个逻辑文件,就是用一个文件全路径名表示,这个文件全路径名对应着数据块的存储信息(数据块的存储位置等信息)
- 如果这里还没有理解分布式存储系统中的物理文件 和 逻辑文件的话,没有关系,我们在讲HDFS的时候会再次提到