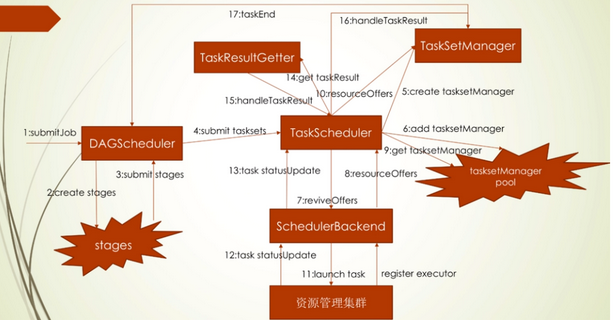
在使用spark-submit提交一个Spark应用之后,Driver程序会向集群申请一定的资源来启动东若干个Executors用来计算,当这些Executors启动后,它们会向Driver端的SchedulerBackend进行注册,告诉Driver端整个每一个Executor的资源情况。 那么在一个Spark Application中的一旦一个RDD触发了Action API后,就会触发一个job的提交,job的提交步骤如下:
1、DAGScheduler根据RDD的依赖来划分并创建Stage,划分Stage的原则是碰到宽依赖就进行Stage的划分,划分好的所有Stage之间也有父子关系。调度Stage的时候先调度没有父亲的Stage
2、将没有父亲的Stage转成Taskset提交给TaskScheduler进行调度,每一个Stage对应着一个Taskset,一个Taskset包含了若干个Task,如果RDD有几个分区,那么这个Taskset中就有几个Task
3、TaskScheduler接收到Taskset之后,先创建一个TasksetManager,用于调度和管理这个Taskset中所有Task,然后将这个TasksetManager放到TasksetManager Pool中(这个Pool的功能就是使得我们可以使用不同的策略来调度TasksetManager)。
4、这个时候TaskScheduler就向SchedulerBackend申请足够的资源来调度执行某一个TasksetManager中的Task了,如果SchedulerBackend资源充足的话,则将可以用的资源情况告诉TaskScheduler,TaskScheduler将资源情况告诉TasksetManager,然后TasksetManager根据资源情况来调度需要执行的Task(这里包含了延迟调度、Task黑名单机制等)
5、从TasksetManager中调度的Task直接发往相对应的Executor进行执行,这个时候SchedulerBackend的记录的集群的资源情况信息会被更新,因为有Task占用资源了
6、当Executor上执行的Task结束了后,会将Task的状态发往给SchedulerBackend,SchedulerBackend将Task的状态告诉TaskScheduler,TaskScheduler委托TaskResultGetter来解析返回的Task的状态,得到Task执行完之后的结果,然后将Task执行完的结果数据告诉TasksetManager,TasksetManager根据Task的执行结果来更新该Task的状态信息(比如Task是失败、成功还是重跑等),更新完TasksetManager中对应的Task的结果后,再去更新DAGScheduler中Task所在的Stage的状态,比如,如果Task是成功的,该Task所在的Stage的所有Task都跑完了,那么DAGScheduler就可以调度该Stage的子Stage了