什么是模块:
模块实质上就是一个python文件,它是用来组织代码的,意思就是说把python代码写到里面,文件名就是模块的名称,test.py:test就是模块名称
安装模块:连网时直接用pip方法一,没连网需要下载对应模块包进行安装方法二,三。
方法一:cmd下使用 pip install xlwt (xlwt 这个是模块名称)
如提示pip不是内部命令说明环境变量没有配对,把查看“Scripts”文件下是否有pip3把这个文件配置到环境变量内。
查看pip已经安装的模块 cmd pip list
或者python -m pip install --upgrade pip -i https://pypi.douban.com/simple
pip升级时界面有时会出现连接超时可以用以下方法:使用timeout参数增加时间 python -m pip install --upgrade pip --timeout 6000,下载其他模块超时时也可以后面跟时间如:pip install xxx --timeout 6000(后面时间随便写)
方法二:模块以.whl结尾的直接在 当pip 下载模块时不能下载过超时了可以直接在网上搜索当前模块名称 如:下载pymysql模块
搜网上索到 以pypl结尾的,点击进去进行下载然后直接进行安装
以pypl结尾的,点击进去进行下载然后直接进行安装
pip install c:/user/xxxg/desktop/xxx.whl#后面跟对应文件路径和下载包名称
方法三:模块以.tar.gz结尾的 (1.先解压,2.解压之后在命令行里面进入到这个目录下,3.执行python setup.py install)
模块的更新: pip install -U 模块名称
标准模块:python自带的模块,不需要再下载的模块例如:os,time,random,hashlib 等等
模块导入查询:import导入文件时先从当前目录下寻找,在从环境变量文件下面进行查找。
查找当前安装模块并导出来: pip freeze > e:pip_list.txt
安装文件内的模块: pip install -r e:pip_list.txt
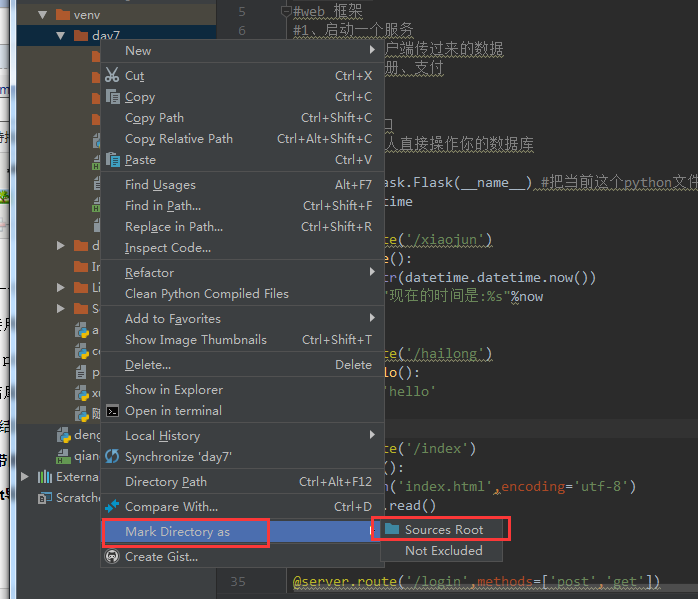
使用pycharm开发时需要引用其他文件内的模块有两种方法:
1.直接选择对应模块右键mark directory as--sources root(sources root 主要是把当前的目录变成跟目录便于配置内的数据操作)
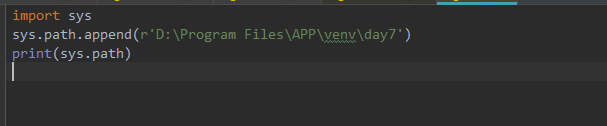
2.使用path路径方法进行添加
1.excel模块
写excel


import xlwt #写excel 只写不读 book = xlwt.Workbook() sheet = book.add_sheet('chahca')#任意写一个参数 #sheet.write(0,0,'id')# 单个写 行,列,内容 stus = [ [1,'njf','1234','xiaoxiao','wangming'], [2,'xiaojun','1234','xiaoxiao'], [3,'hailong','1234','xiaoxiao'], [4,'xiaohei','1234','xiaoxiao'], [4,'xiaohei','1234','xiaoxiao'], [4,'xiaohei','1234','xiaoxiao'], [4,'xiaohei','1234','xiaoxiao'], [4,'xiaohei','1234','xiaoxiao'], [4,'xiaohei','1234','xiaoxiao'], ] line = 0 # 控制行数 for stu in stus: col = 0 # 定义 列 for s in stu: sheet.write(line,col,s) #指定行,列以及内容 col += 1 #循环一次加一次列 line += 1 #没循环一次加一次 book.save('sht.xls')#保存到文件内
读取excel
import xlrd #xlrd:读取execl, wenben =xlrd.open_workbook("jinniug.xls")#这个文件名称必须的在这个目录下 #没有就要写这个文件的绝对路径 wenjian = xlrd.open_workbook("C:\UsersAdministratorDesktopFTP账号.xlsx") sheet = wenjian.sheet_by_index(0)#获取当前文件多少页 print(sheet.nrows) #excel里面有多少行 print(sheet.ncols) #excel里面有多少列 day = sheet.cell(1,1).value#获取那一列,那一行的数据,如果没有对应的会报错 print(day) for i in range(sheet.nrows):#循环获取每行的内容 print(sheet.row_values(i)[1:2]) #'[1:2]' 获取这一行内那一列到那一列的数据 print(sheet.row_values(1))#获取到整行的内容
修改excel
import xlrd import xlutils #修改excel表格 from xlutils import copy book = xlrd.open_workbook('stu.xls') #先用xlrd打开一个Excel new_book = copy.copy(book) #然后用xlutils里面的copy功能,复制一个Excel sheet = new_book.get_sheet(0)#获取sheet页 sheet.write(0,1,'xiaomming') sheet.write(1,1,'xiaojun')
练习题:获取表格内某几列数据

import xlrd def read_excel(): all_case = [] book = xlrd.open_workbook("C:\UsersAdministratorDesktop接口测试模板.xls") sheet = book.sheet_by_index(0) for i in range(1,sheet.nrows): row_data =sheet.row_values(i)[4:8] all_case.append(row_data) return all_case print(read_excel())
import hashlib password = '123456789' m = hashlib.md5(password.encode())#字符串不能直接加密,需要转成二级制后才能加密 print(m.hexdigest())#返回密文 #加盐就是随机在原有的密码上在加上一串字符 #加盐操作 def my_md5(s:str,salt=None): #salt是盐值 s = str(s) if salt: s = s+salt m = hashlib.md5(s.encode()) #转换为二进制在加盐 return m.hexdigest()
3.拼音模块
import xpinyin s = xpinyin.Pinyin() p = xpinyin.Pinyin() #实例化 res = p.get_pinyin('烘干') #默认不传后面的话,两个拼音之间会有- 链接 print(res) print(s.get_pinyin('王明',''))#如果需要去掉空格后面以空来连接
4.操作数据库
数据库建立或查询(1.链接数据库:账号、密码、ip、端口号、数据库;2.建立游标;3.执行sql(执行insert、delete、update语句时,必须得commit)4.获取结果;5.关闭游标;6.连接关闭;)
import pymysql host='1.1.1.'#数据库地址例如:192.168.1.1 user='jxz' #账号 password='123456' #密码只能是字符串 db='jxz' #数据库 port=3306#端口号只能写int类型 charset='utf8'#只能写utf8,不能写utf-8 import pymysql conn = pymysql.connect(host=host,password=password, user=user,db=db,port=port, charset=charset,autocommit=True )#建立连接数据库方法 connect,加了autcommit=True后就不需要commit了 cur = conn.cursor()#建立游标,(需要数据库管理员进行那东西或放东西) cur.execute('select * from app_myuser limit 5;')#只帮你执行sql语句 cur.commit()#执行sql语句时除了查询不commit,其他都需要,不然不能提交 #print(cur.fetchall())#获取数据库所有结果 print(cur.fetchone())#只获取一条数据 print(cur.description)#获取表里所有字段信息 cur.close()#关闭游标 conn.close()#关闭数据库
import hashlib, pymysql, datetime def my_db(sql): import pymysql coon = pymysql.connect( host='118.24.3.40', user='jxz', passwd='123456', port=3306, db='jxz', charset='utf8') cur = coon.cursor() # 建立游标 cur.execute(sql) # 执行sql if sql.strip()[:6].upper() == 'SELECT': res = cur.fetchall() else: coon.commit() res = 'ok' cur.close() coon.close() return res def my_md5(str): import hashlib new_str = str.encode() # 吧字符串转成bytes类型 m = hashlib.md5() # 实例化md5对象 m.update(new_str) # 加密 return m.hexdigest() # 获取返回结果 def reg(): username = input("username:").strip() pwd = input("pwd:").strip() cpwd = input('cpwd:').strip() if username and pwd and cpwd: sql = 'select * from nhy where name = "%s";' % username res = my_db(sql) if res: print("该用户已经存在!") else: if pwd == cpwd: md5_pwd = my_md5(pwd) insert_sql = 'insert into nhy (name,pwd) values ("%s","%s");' % (username, md5_pwd) my_db(insert_sql) print("注册成功!") else: print('两次输入的密码不一致!') else: print('必填项不能为空!') def login(): username = input('username:').strip() pwd = input('pwd:').strip() if username and pwd: md5_pwd = my_md5(pwd) sql = 'select * from nhy where name = "%s" and pwd = "%s";' % (username, md5_pwd) res = my_db(sql) if res: print("欢迎,登陆成功!今天是%s" % datetime.date.today()) else: print('账号或密码错误') else: print("必填项不能为空!") # login() reg()
5.时间模块
1.time模块提供各种时间相关的功能,与时间相关的模块有:time,datetime,calendar等。
2.时间有三种表示方式,一种是时间戳、格式化时间、时间元组。时间戳和格式化时间相互转化,都需要先转化为时间元祖,时间戳单位最适于做日期运算。
import datetime,time ticks = time.time() print('当前时间戳:',ticks)#当前的时间戳 a = time.strftime('%Y-%m-%d %H:%M:%S') #当前时间表示 print(a) time.sleep(30)#等待30秒 time1 = time.strptime('2038-08-29 19:23:59','%Y-%m-%d %H:%M:%S')#时间格式 b = time.mktime(time1)#时间元祖转换为时间戳 start=1535731200#利用time包的函数localtime将其转换为日期。 start_trans=time.localtime(start) print(start_trans) #时间戳转格式日期需要的格式。如(%Y-%m-%d %H:%M:%S) start_trans_2=time.strftime('%Y-%m-%d %H:%M:%S',start_trans) print(start_trans_2) start_trans_3=time.strftime('%Y-%m-%d',start_trans) print(start_trans_3) #把时间格式转换为员组 now = '2019-09-11 00:00:00' now = time.strptime(now,"%Y-%m-%d %H:%M:%S") #将标准时间格式转换为时间戳 now_a = time.mktime(now) print(now) print(now_a)
5.glob 模块
import glob '''glob 模块是查找文件路径的模块,支持*?[]这三种通配符,返回的数据类型是list. * 代表0个或多个字符 ? 代表一个字符 []匹配指定范围内的字符,如[0 - 9]匹配数字, 也可以使用!代表不匹配的''' glob1 = glob.glob(r"/Users/my_python/*.py") # 过滤,只搜索以py结尾的文件。 print(glob1) glob2 = glob.glob(r"/Users/my_python/0?.py") print(glob2) glob3 = glob.glob(r"/Users/my_python/0[0,1,2].py") print(glob3) glob4 = glob.glob(r"/Users/my_python/0[0-3].py") print(glob4) glob5 = glob.glob(r"/Users/my_python/0[a-z].py") print(glob5)
6.OS模块
os模块:负责程序与操作系统的交互,提供了访问操作系统底层的接口;
BAE_PATH = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) #获取当前文件夹的路径
import os os.remove('filename')# 删除文件 os.rename(oldname, newname) #重命名文件 os.walk() #生成目录树下的所有文件名 os.chdir('dirname')# 改变目录 os.mkdir/makedirs('dirname')#创建目录/多层目录 os.rmdir/removedirs('dirname')# 删除目录/多层目录 os.listdir('dirname') #列出指定目录下的所有文件 os.getcwd() #取得当前工作目录 os.chmod() #改变目录权限 os.path.basename('path/filename') #去掉目录路径,返回文件名 os.path.dirname('path/filename') #去掉文件名,返回目录路径 os.path.join(path1[,path2[,...]]) #将分离的各部分组合成一个路径名 os.path.split('path')# 返回( dirname(), basename())元组 os.path.splitext() #返回 (filename, extension) 元组 os.path.getatime#ctimemtime 分别返回最近访问、创建、修改时间 os.path.getsize() #返回文件大小 os.path.exists() #是否存在 os.path.isabs() #是否为绝对路径 os.path.isdir() #是否为目录 os.path.isfile() #是否为文件
7.sys模块
负责程序与python解释器的交互,提供了一系列的函数和变量,用于操控python的运行时环境。
sys.path.insert(0,BAE_PATH)#把对应路径添加到环境变量中
import sys sys.argv #命令行参数List,第一个元素是程序本身路径 sys.modules.keys() #返回所有已经导入的模块列表 sys.exc_info()# 获取当前正在处理的异常类,exc_type、exc_value、exc_traceback当前处理的异常详细信息 sys.exit(n)# 退出程序,正常退出时exit(0) sys.hexversion #获取Python解释程序的版本值,16进制格式如:0x020403F0 sys.version #获取Python解释程序的版本信息 sys.maxint #最大的Int值 sys.maxunicode #最大的Unicode值 sys.modules #返回系统导入的模块字段,key是模块名,value是模块 sys.path #返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform #返回操作系统平台名称 sys.stdout #标准输出 sys.stdin 3标准输入 sys.stderr #错误输出 sys.exc_clear() #用来清除当前线程所出现的当前的或最近的错误信息 sys.exec_prefix #返回平台独立的python文件安装的位置 sys.byteorder #本地字节规则的指示器,big-endian平台的值是'big',little-endian平台的值是'little' sys.copyright #记录python版权相关的东西 sys.api_version# 解释器的C的API版本
8.发送邮件模块 yagmil
import yagmail user='xxx@163.com' password='xxxxxxxxxx' m = yagmail.SMTP(host='smtp.163.com',user=user,password=password,) #smtp.qq.com,smtp_ssl=True 如果是qq邮箱的话加这个参数 m.send(to=['xxxxxx@qq.com'], #多个用户发送可以直接在后面加邮箱地址"ddd@aa.com",也可以用list列表 subject='明天不上课',contents='明天不上课,在家好好休息。。。', ) #to 表示接收的邮箱号,subject表示:标题, contents 表示:内容,
9.打印日志模块 nnlog
import nnlog log = nnlog.Logger(file_name='my.log', level='debug', when='D', backCount=5, interval=1) # file_name是日志文件名 # level是日志级别,如果不传的话默认是debug级别:(error错误,waing警告,info打印提示信息,debug调试信息) # when是日志文件多久生成一个,默认是按天,S 秒、M 分、 H 小时、 D 天、 W 每星期 # backCount是备份几个日志文件,默认保留5天的 # interval是间隔多久生成一个日志文件,默认是1天 log.debug('默认日志级别是debug') log.info('info级别') log.warning('waring级别') log.error('error级别') #error级别是最高的其他就不显示了, log2 = nnlog.Logger(file_name='nn.log') # 直接传入文件名也是ok的,其他的就取默认值了 log2.debug('test')
10.random随机模块
import random, string print(random.random()) # 随机浮点数,默认取0-1,不能指定范围 print(random.randint(1, 20)) # 随机整数 print(random.randrange(1, 20)) # 随机产生一个range print(random.choice('x23serw4')) # 随机取一个元素 print(random.sample('hello', 2)) # 从序列中随机取几个元素 print(random.uniform(1, 9)) # 随机取浮点数,可以指定范围 x = [1, 2, 3, 4, 6, 7] random.shuffle(x) # 洗牌,打乱顺序,会改变原list的值 print(x) print(string.ascii_letters + string.digits) # 所有的数字和字母
11. requests模块
requests模块是python的一个第三方模块,它是基于python自带的urllib模块封装的,用来发送http请求和获取返回的结果,操作很简单。需要自己安装 pip install requests
import requests req = requests.get('http://www.baidu.cn',data={'username':'xxx'},cookies={'k':'v'}, headers={'User-Agent':'Chrome'},verify=False,timeout=3) #发送get请求,data是请求数据, # cookies是要发送的cookies,headers是请求头信息,verify=False是https请求的时候要加上,要不然会报错。 #timeout参数是超时时间,超过几秒钟的话,就不再去请求它了,会返回timeout异常 req3 = requests.put('http://www.baidu.cn') #put方式请求 req4 = requests.patch('http://www.baidu.cn')#patch方式请求 req5 = requests.delete('http://www.baidu.cn')#delete方式请求 req6 = requests.options('http://www.baidu.cn')#options方式请求,用法和上面的get、post都一样 r = requests.get("https://www.baidu.com/")# get 请求获取状态码 rl = requests.get(url='https://www.baidu.com/', params={'wd':'python'}) #带参数的请求 url = 'http://www.baidu.com' print(r.status_code) #获取返回状态码,如果不是200,可以使用r.raise_for_status() 抛出异常 print(r.recontent)#获取返回的内容,二进制格式,一般下载图片、视频用这个 print(r.text) #获取返回的内容,字符串格式 print(r.json())#获取返回的内容,json格式,这个必须是返回的是json才可以使用,否则会报错 print(r.headers)#获取响应头 print(r.cookies)#获取返回的cookie print(r.encoding)#获取返回的字符集 print(r.url) #直接打印请求 print(r.content) #以字节流形式打印
练习题:下载音乐,先去查找音乐的url
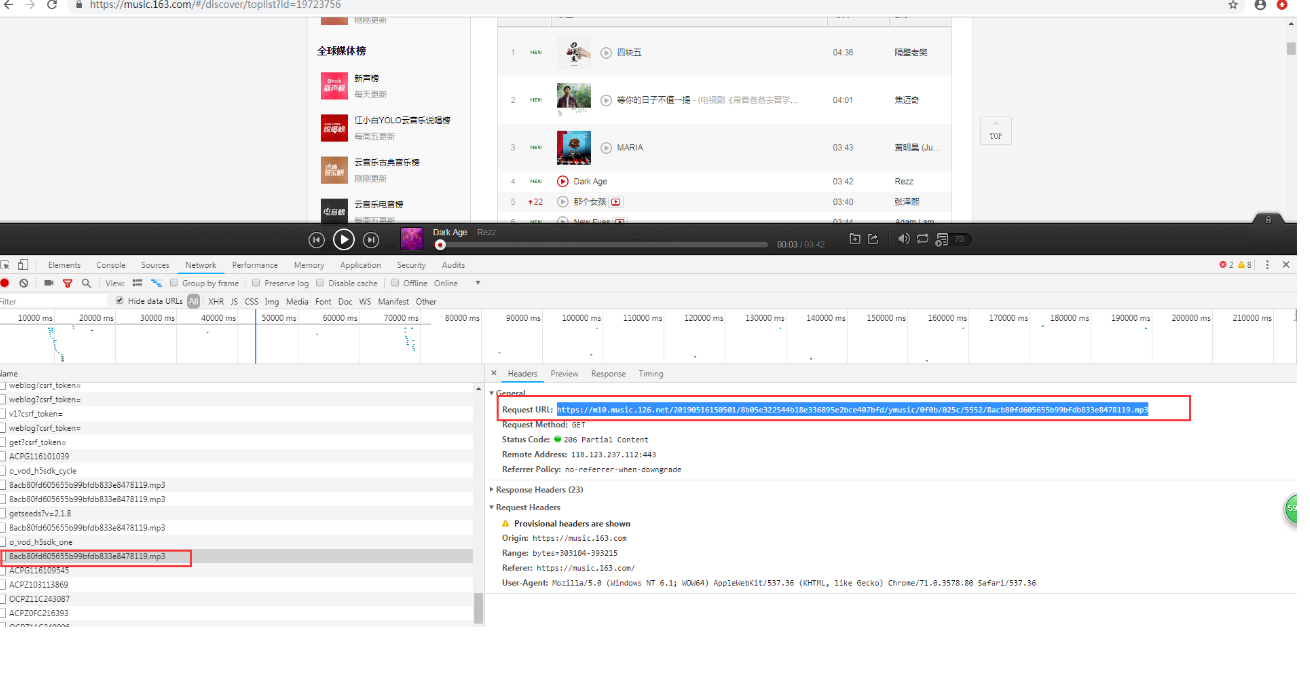
import requests MP3_url='https://m10.music.126.net/20190516150501/8b05e322544b18e336895e2bce407bfd/ymusic/0f0b/025c/5552/8acb80fd605655b99bfdb833e8478119.mp3' res = requests.get(MP3_url) mp3 = res.content #返回的二进制内容 f = open('d12.mp3','wb') f.write(mp3) f.close()