Robot Framework 介绍
RobotFramework是一款基于python的开源自动化测试框架,遵守Apache License 2.0协议,在此协议下所有人都可以免费开发和使用。因为Robot Framework 是灵活和可扩展的,所以它很合适用于测试具有多种接口的复杂软件:用户接口,命令行,web service,编程接口等。RF提供很多的扩展库供使用。Robot的测试用例和配置使用HTML,TXT等格式文件进行编辑,html是比较常用的一种格式。
关键字驱动
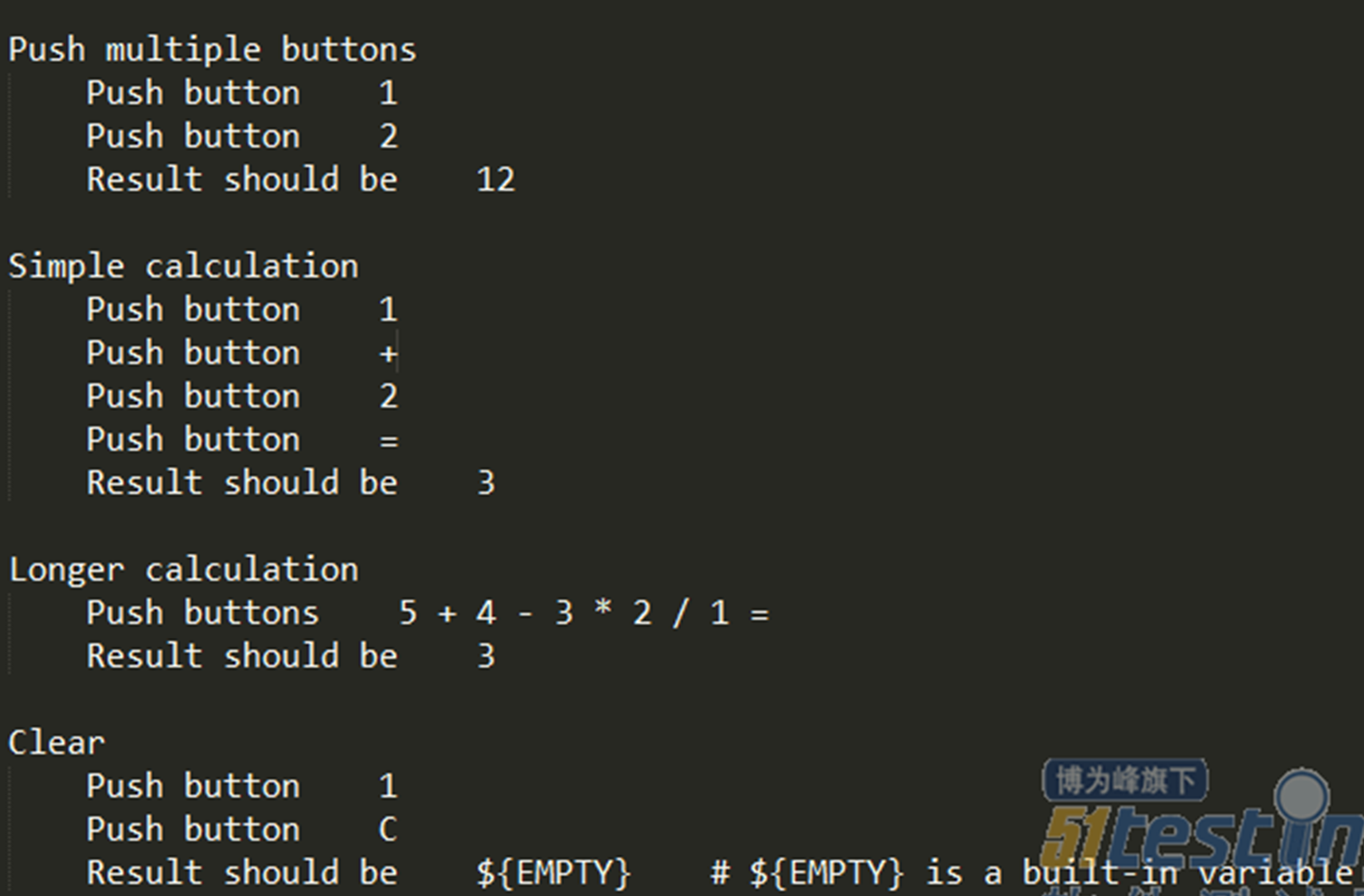
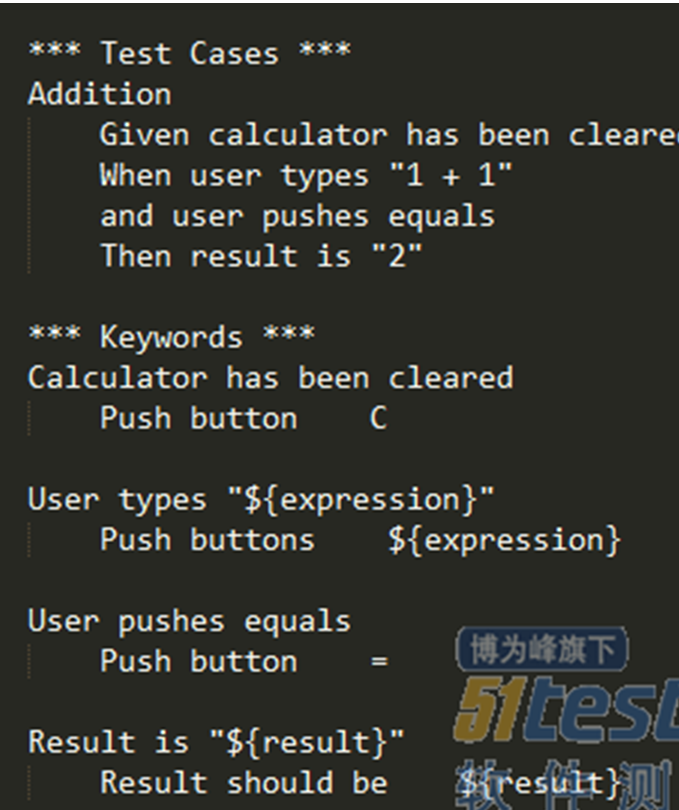
关键字驱动使得我们的自动化用例具备非常高的可读性,只要由测试开发人员封装好关键词库,即使是业务测试人员也可以很方便地编写自动化用例;其次,可以在基本关键词的基础上构造高级关键词,这使得我们的自动化有了无限扩展的可能;例如以测试计算器功能为例:这边其实包括了4个测试用例,及连续输入、简单加、复杂运算、复位功能,“Push Button”、“Result should be”都是我们在关键词库中预先定义好的关键词,实现了简单的操作及断言功能;
数据驱动
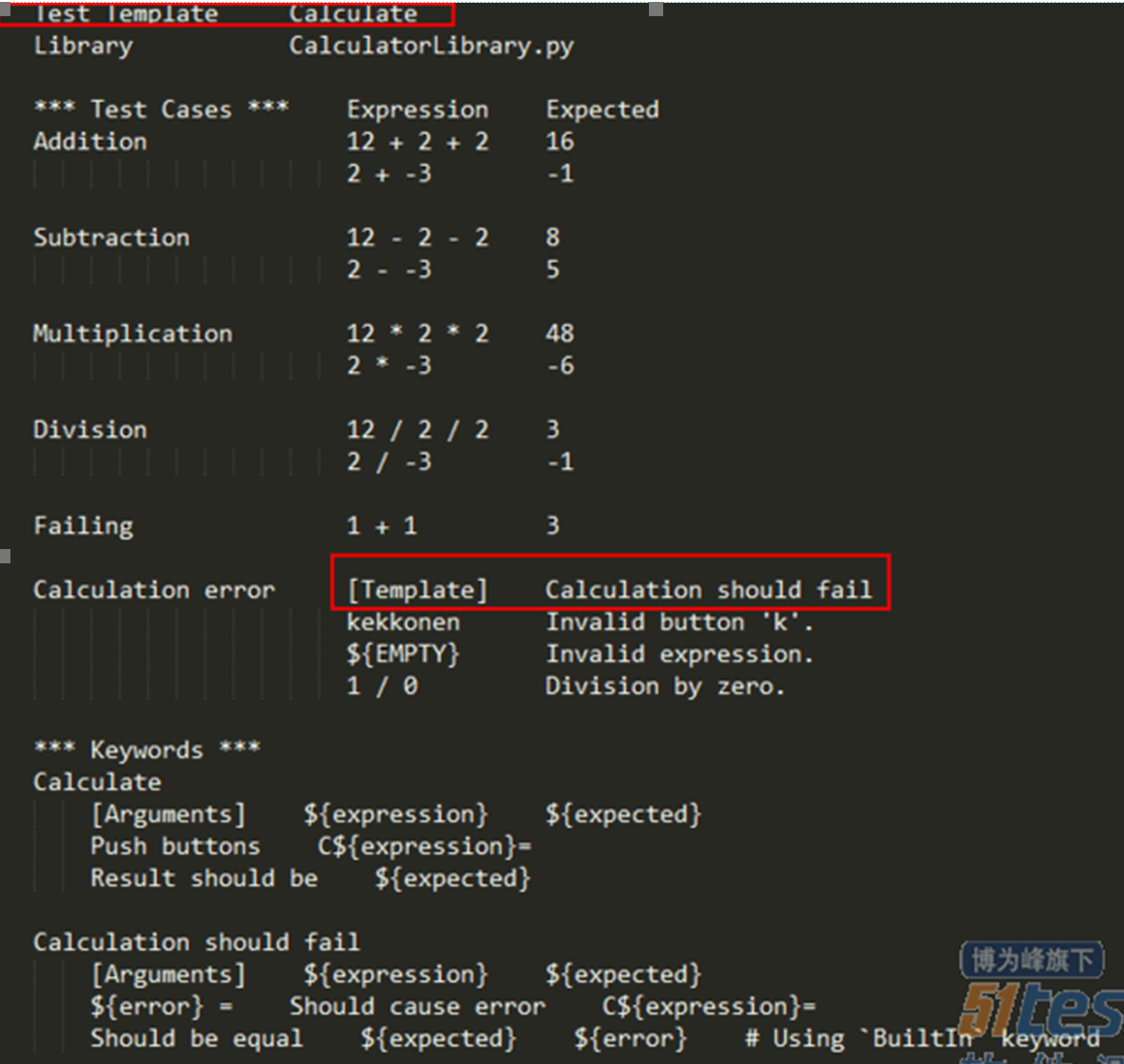
数据驱动引入了一个非常有效的“模板”概念,在很多测试场景下,测试人员输入的操作是有一定重复性的,区别只在于输入的数据,还是以登陆为例,除了包含正常的测试用例,还需要有其他的异常用例覆盖才能保证登陆接口的正确性。基于横向构造不同的测试数据输入来判断不同的测试结果,即为数据驱动。行为可以封装成模板。
该用例定义了两个模板,一个是Calculate计算模板,一个是错误模板。然后直接根据测试数据执行即可。
行为驱动
行为驱动是一种在关键词驱动之上更加抽象更加高级的自动化测试手段;通常结构是“Given-When-and-Then”,即在一个什么样的前置条件下,当用户触发了什么操作,产生了一个什么样的结果,结果该是怎么样。还是以测试及计算器为例。
一、RF转义字符
Rf的测试数据转义字符是反斜杠 ( )

二、Robot Framework文件类型
1.RF文件
Robot Framework测试数据以表格形式进行定义,可以使用的格式包括超文本标记语言(HTML),制表符分隔值(TSV),纯文本或者新结构化文本(reST)。Robot Framework根据文件的扩展名来为这些以不同格式存储的测试数据选择解析器。扩展名不区分大小写,可识别的扩展名包括HTML的.html,.htm和.xhtml,TSV的.tsv,纯文本的.txt和新结构化文本的.rest。针对HTML和TSV格式有不同的测试数据模板,使你轻易就可以开始动手编写用例。在HTML文件中,测试数据通过分隔的表格进行定义。Robot Framework基于首个单元格里的文本来识别这些测试数据表。所有可识别表格之外的参数都自动忽略。你可以使用任何你喜欢的编辑器来编辑HTML文件中的测试数据,但是推荐使用可以实实在在看到表格的图形化编辑器。
RF文件通常以.robot为后缀名,并且提供了很多的编辑工具,方便的进行robot文件的编辑。官方的RIDE是很好的选择,纯图形化界面,方便团队没有开发经验的人参与其中。一个RF文件通常包括三个节点(也称为表):
|
表格名称 |
作用 |
别名 |
|
Setting表 |
1、 加载测试库文件、资源文件和变量文件; 2、 为测试文件和测试用例定义中间变量; |
Setting, Settings, Metadata |
|
Variable表 |
变量定义,这些变量能在整个测试数据中使用。 |
Setting, Settings, Metadata |
|
Test Case表 |
利用存在的关键字创建测试用例; |
Test Case, Test Cases |
|
Keywords 表 |
利用已存在的低级关键字创建用户级关键字; keyword可以理解为一个公用的方法,供test case使用 |
Keyword, Keywords, User Keyword, User Keywords |
2.Resource资源文件的结构
其实resource文件与普通robot文件没多大区别,只不过它是被导入的库文件,通常用来定义一些公用的变量和keywords:
三、变量
变量是RF的完整特征,它们能在测试数据的大多数地方被使用。最常见的是在测试用例表和关键字表中被用于关键字的参数。一个普通的关键字名称不能使用变量来指定,但使用内建关键字Run Keyword 可以。RF的变量无需特定声明,只要有初始化赋值即可使用。不区分大小写、空格和下划线
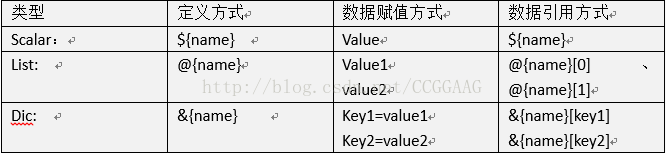
•标量变量:${scalar}。当在测试数据中使用标量变量时,他们将被分配的值所代替。
•列表变量:@{LIST}。列表变量是复合变量,可以分配多个值给它。
•字典变量:& {DICT}。
•数字变量:可以用来创建一个全是整型和浮点型的数字:整形80、浮点型80、浮点型{3.14}
•Boolean变量:${true/false}
•Null/None变量: ${null/None}
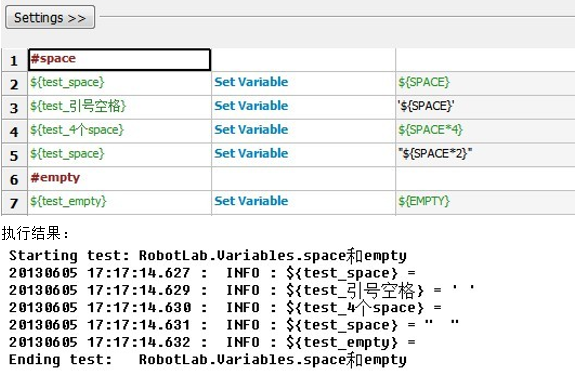
•空格SPACE和空SPACE和空{EMPTY}变量
•操作系统变量
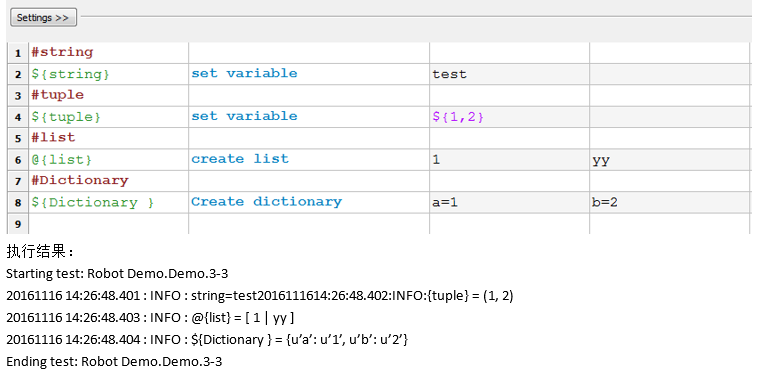
1、标量变量、列表变量、元组变量、字典变量
访问单个列表项
可以访问一个特定值的变量列表的语法 @ {名称}(指数) ,在那里 指数 是选择的索引值。 指数 从0开始,负指标可以用来访问项目的结束, 和试图访问一个值太大索引会导致一个错误。 指数会自动转换为整数,还可以 使用变量指标。 可以使用列表项以这种方式访问 同样作为标量变量。
*** Test Cases ***
List Variable Item
Login @{USER}
Title Should Be Welcome @{USER}[0]!
Negative Index
Log @{LIST}[-1]
Index As Variable
Log @{LIST}[${INDEX}]
标量变量、列表变量、字典变量创建和引用有何区别:
实际案例展示
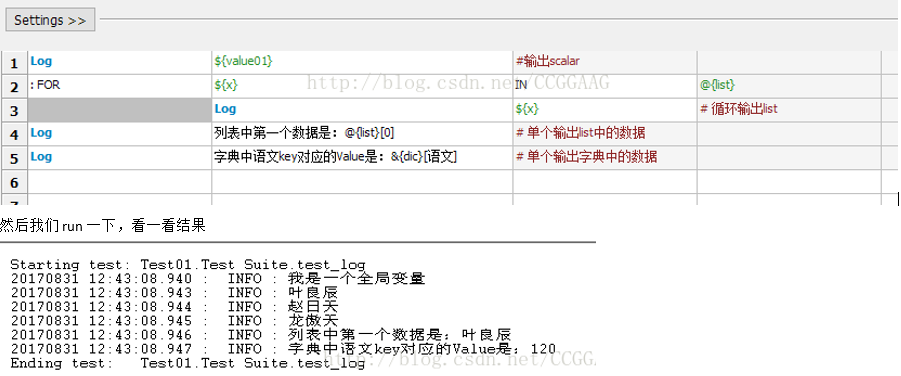
这里我们直接创建了这三种数据,

然后,我们新建一个case,来验证一下我们能否引用这些数据类型
1行为单个数据scalar,2、3、4行是list,5行是dic
我们中间在2、3行使用了一个循环语法,来循环的输出列表中的内容
2、数字变量

3、布尔变量和None/null
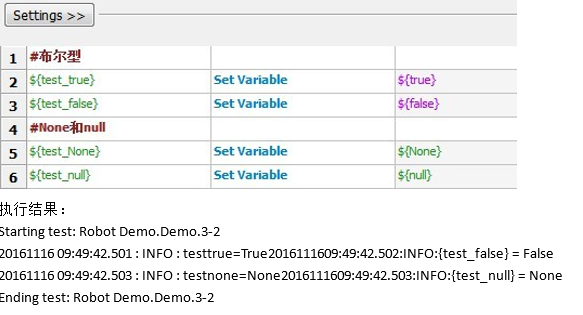
4、space和empty
5、操作系统变量
|
变量 |
解释 |
|
$ { CURDIR } |
目录的绝对路径,测试数据文件所在的位置。 这个变量是区分大小写的。 |
|
$ { TEMPDIR } |
系统临时目录的绝对路径。 在类unix系统通常 / tmp ,在窗户 c:Documents and Settings <用户> Temp 本地设置。 |
|
$ { EXECDIR } |
目录的绝对路径测试执行 从开始的。 |
|
$ { / } |
系统目录路径分隔符。 / 在类unix 系统和 在Windows。 |
|
$ {:} |
系统路径元素分隔符。 : 在类unix 系统和 ; 在Windows。 |
|
$ { n } |
系统行分隔符。 n 在类unix系统和 r n 在Windows。 2.7.5新版本。 |
*** Test Cases ***
Example
Create Binary File CURDIRCURDIR{/}input.data Some text here${ }on two lines
Set Environment Variable CLASSPATH TEMPDIRTEMPDIR{:}CURDIRCURDIR{/}foo.jar
四、RF库
1、标准库
Robot Framework可以直接导入使用的库,包括:
•Builtin:包含经常需要的关键字。自动导入无需import,因此总是可用的
•Dialogs:提供了暂停测试执行和从用户的输入方式。
•Collections:提供一组关键词处理Python列表和字典。
•OperatingSystem:允许执行各种操作系统相关的任务。允许执行各种操作系统相关的任务,使各种操作系统相关的任务在robotframework正在运行的系统中执行。
•Remote:远程库接口的一部分。没有自己的任何关键字,作为robotframework和测试库之间的代理的特殊库。实际测试库可以在不同的机器上运行,可以使用任何编程语言支持XML-RPC协议的实现。
•Screenshot:提供关键字来捕获和存储桌面的截图。
•String:用于处理字符串并验证它们的内容的库,用于生成、修改和验证字符串
•Telnet:支持连接到Telnet服务器上打开的连接执行命令。
•XML:用于生成、修改和验证XML文件的库。
•Process:系统中运行过程的库。
•DateTime:日期和时间转换的库,支持创建和验证日期和时间值以及它们之间的计算
2、扩展库
Robot Framework需要下载安装后才能使用的库,包括:
•Android library:所有android自动化需要的测试库,内部使用的是Calabash Android
•iOS library:所有iOS自动化需要的测试库,内部使用Calabash iOS服务
•appiumlibrary:Android和iOS测试库,内部使用的是appium
•HTTP library (livetest):内部使用LiveTest工具的HTTP测试的库。
•HTTP library (Requests):内部使用request工具的HTTP测试的库。
•MongoDB library:使用pymongo和MongoDB交互的库。(MongoDB是一个基于分布式文件存储的数据库)
•Database Library (Java):基于Java的数据库测试库。也可使用Jython和Maven central.
•Database Library (Python):基于Python数据库测试库。支持任何Python解释器,包括Jython。
•watir-robot:使用Watir的工具的Web测试库。
•seleniumlibrary:Web测试库,内部使用比较流行的selenium工具。利用早期的selenium1.0和本身已经过时。
•selenium2library:使用selenium2的Web测试库。替换了大部分老的seleniumlibrary。
•selenium2library java:selenium2library的java接口
•Django Library:为Django的库,一个Python Web框架。
•sudslibrary:一种基于泡沫基于SOAP的Web服务的功能测试库,动态的SOAP 1.1的客户端。
•Archive library:处理.zip和.tar压缩包的库。
•Diff Library:比较两个文件的库。
•FTP library:Robot Framework上测试和使用FTP服务的库。
•SSHLibrary:通过SSH连接的在远程机器上执行命令。还支持使用SFTP进行文件传输
•rammbock:通用的网络协议测试库;提供简单的方法来指定网络数据包,并检查发送和接收数据包的结果。
•imagehorizonlibrary:跨平台、基于图像识别的GUI自动化纯Python库。
•autoitlibrary:Windows的GUI测试库,使用AutoIt的免费工具作为驱动。
•Eclipse Library:使用SWT窗口小部件测试Eclipse RCP应用程序的库。
•robotframework-faker:一个服务faker的库,faker的测试数据生成器。
•swinglibrary:用Swing GUI测试java应用程序库
•remoteswinglibrary:使用swinglibrary库测试和连接一个java进程,尤其是java web
start的应用。(Java Web Start 是基于 Java 技术的应用程序的一种部署解决方案,它是连接计算机和 Internet
的便捷通道,允许用户在完全脱离 Web 的情况下运行和管理应用程序)
•MQTT library:测试MQTT brokers和应用的库。
3、用户自定义的Test Library库
在实际的工作中,肯定会发现有些功能RF自身的Library,或者第三方的Library都无法实现,这个时候我们就得自己写library来实现它了。
1)编写Library
假设你有3个方法,你需要写成自己的library
1:公式:(a+b)的a次方,a,b是正整数
2:有一网址(字符串),http://www.example.com?ip=192.187.111.198&code=12345&name=cat,想得到ip内容,即192.187.111.198
3:(用户名+10位随机数+一个key)进行md5加密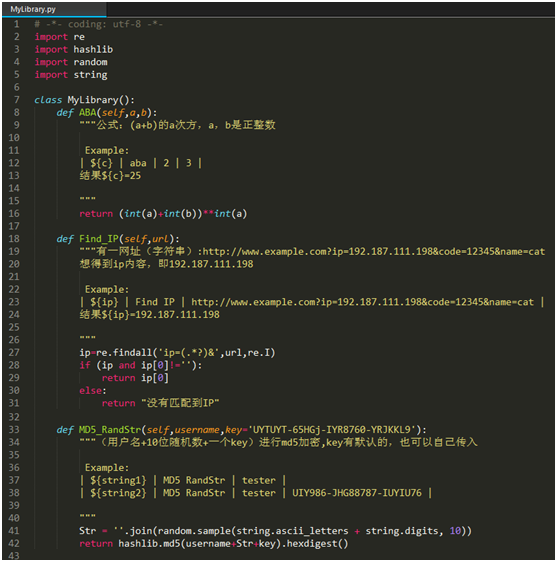
比如我这样子已经写好了,编译调试一下,确保自己没有错误哦。若是有错误,导入RF会失败。然后,将这个文件保存的文件名要和这个class的类名一样,所以我把他保存成MyLibrary.py
2)放置位置及导入
最后,我们把这个文件放在了RF项目的同一目录下,即可。如果你放在其他地方,也是可以的,但是导入的时候,地址要写对哦
来到RF中,我们导入它(记得写.py)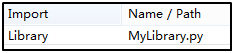
3)确认导入成功
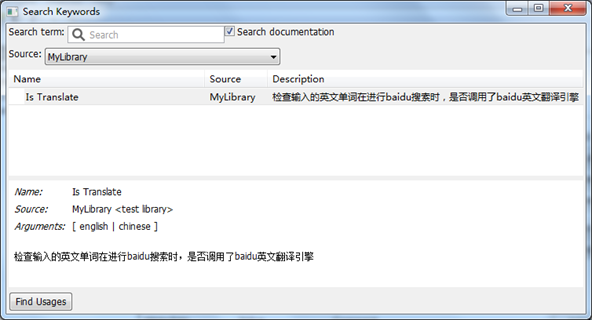
按F5,是不是看到自己写的那些关键字了?而且还有自己的中文注解哦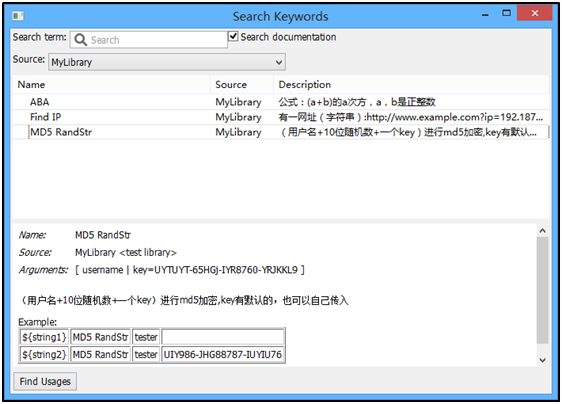
4)使用library
使用这3个关键字,我们跑一下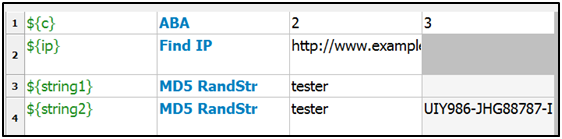
5)查看结果
运行结果

4、Robot Framework自定义Library
RobotFrame Work为我们提供了包括OS、Android、XML、FTP、HTTP、DataBase、Appium、AutoIt、Selenium、 Watir等大量的库。在使用过程中,除这些库之外,对于某些我们自己特定的应用逻辑,我们还需要开发自己的Library,以便于进行自动化测试。本篇我们以baidu搜索英文时的自动翻译为例,介绍一下如何开发自己的Library。
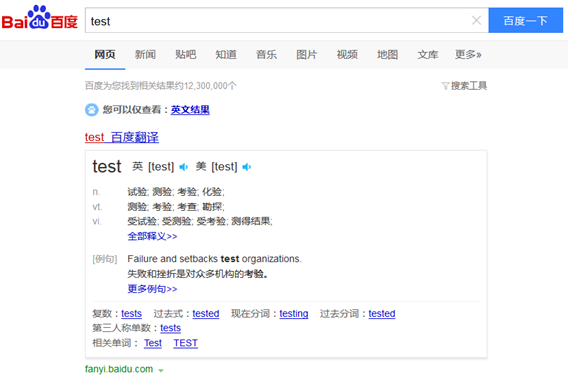
我们这次使用的示例的业务逻辑如下,打开baidu,搜索英文单词“Test”,查看页面中是否含有Test的自动翻译结果(我们以翻译结果“检验”做验证),手动执行效果如图
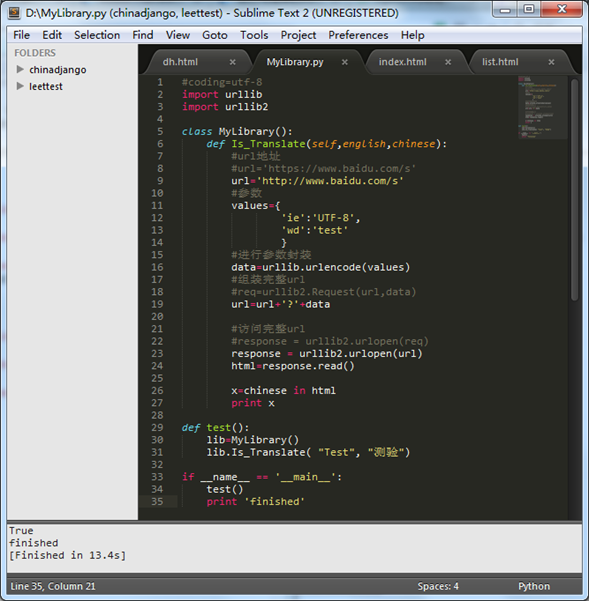
1.编写脚本
我们使用Python的urllib编写测试脚本,并保存到当前RobotFrame Work的测试项目目录下,文件名为MyLibrary.py 。
# -*- coding=utf-8 -*-
import urllib
import urllib2
class MyLibrary():
def Is_Translate(self,english,chinese):
u'''
检查输入的英文单词在进行baidu搜索时,是否调用了baidu英文翻译引擎
'''
#url地址
#url='https://www.baidu.com/s'
url='http://www.baidu.com/s'
#参数
values={
'ie':'UTF-8',
'wd':'test'
}
#进行参数封装
data=urllib.urlencode(values)
#组装完整url
#req=urllib2.Request(url,data)
url=url+'?'+data
#访问完整url
#response = urllib2.urlopen(req)
response = urllib2.urlopen(url)
html=response.read()
x=chinese in html
print x
def test():
lib=MyLibrary()
lib.Is_Translate( "Test", "测验")
if __name__ == '__main__':
test()
print 'finished'
在本地运行脚本,检验脚本的正确性。
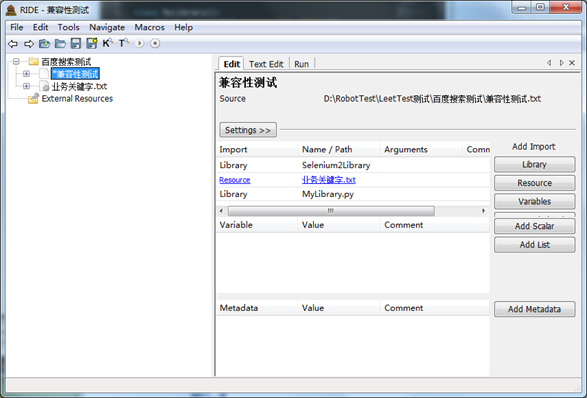
2.引用自定义Library
在TestSuit节点上进行编辑,添加Library,Library名称为我们的脚本文件名MyLibrary.py 。
按F5键,查看刚刚引入的Library
3.添加测试用例
新建一个测试用例,命名为“百度翻译”。添加测试步骤“Is Translate”
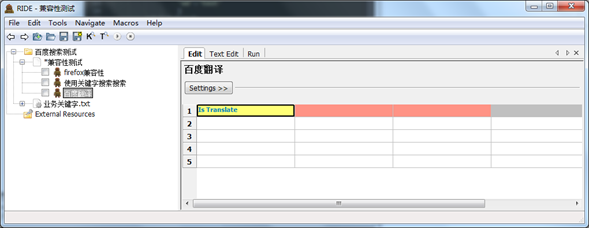
此时看到所编辑行的两个单元格变为了红色,表示该关键字需要两个必填变量,对应我们的脚本中的两个参数。
添加变量,英文输入“Test”,对应检验结果为“测验”
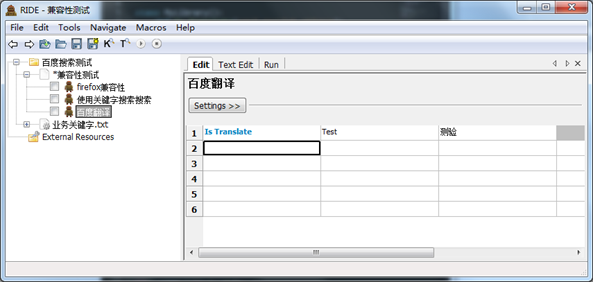
4.运行测试
运行测试,此时,测试不通过
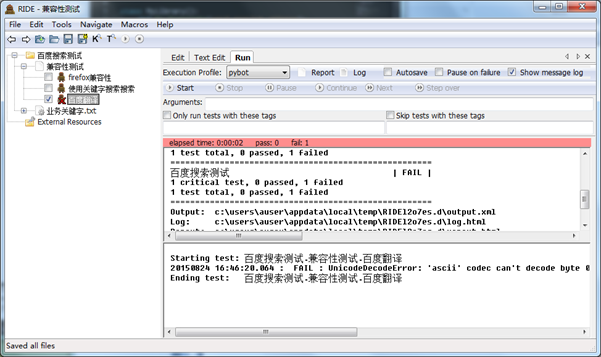
检查错误信息,错误信息为
Starting test: 百度搜索测试.兼容性测试.百度翻译
20150824 16:59:37.014 : FAIL : UnicodeDecodeError: 'ascii' codec can't decode byte 0xe7 in position 490: ordinal not in range(128)
Ending test: 百度搜索测试.兼容性测试.百度翻译
表示是我们的TestCase中的中文字符编码格式错误,此时需要调整以下RobotFrame Work在调用脚本进行运行时的系统编码格式。
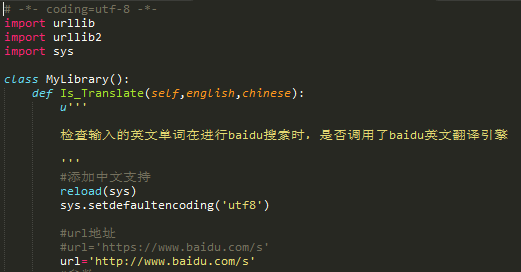
5.增加中文支持
向脚本中添加代码,设置系统默认编码为utf8
#添加中文支持
reload(sys)
sys.setdefaultencoding('utf8')
6.再次执行
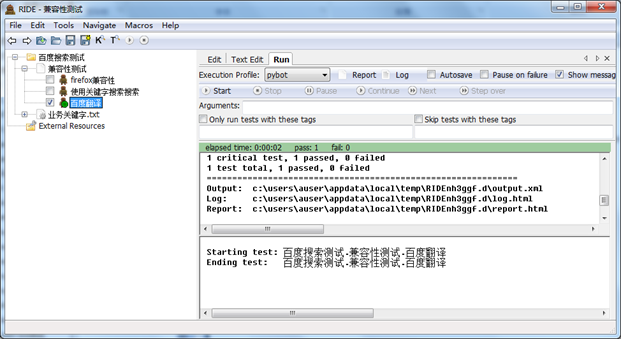
再次执行测试,测试通过,结果为Pass,表示被打开的页面中出现了我们所需要的“测验”字符。(作为简单示例,此时暂不考虑其它搜索结果中的输出问题,如 果要进行严格的测试,应该对搜索后返回的html做解析,先定位到baidu翻译引擎的div位置,再对位置中的翻译结果做检查。)
5、Robot Framework开发系统关键字
对于特定的需求,工具没提供相关的Library和关键字的时候,就只能放弃了。还好robot framework提供了 Evaluate 关键字,对于Evaluate 关键字的使用等有时间再讲。当robot framework 不能解决需求,我是直接写个.py 程序,通过Evaluate 关键字调用。然后,就受到了批评,不能这么玩,动不动就这么干的话其实robot framework 就成了鸡肋,所以,规范的做法是去封装系统关键字。
其实我的需求也非常简单,接收一个目录路径,自动遍历目录下以及子目录下的所有批处理(.bat)文件并执行。
首先在..Python27Libsite-packages目录下创建CustomLibrary目录,用于放自定义的library库。在其下面创建runbat.py 文件:
#-*- coding:utf-8 -*-
from robot.api import logger
import os
class Runbat(object):
def run_all_bat(self,path):
u'''接收一个目录的路径,并执行目录下的所有bat文件.例
| run all bat | filepath |
'''
for root,dirs,files in os.walk(path):
for f in files:
if os.path.splitext(f)[1] == '.bat':
os.chdir(root)
#print root,f
os.system(f)
def __execute_sql(self, path):
logger.debug("Executing : %s" % path)
print path
def decode(self,customerstr):
return customerstr.decode('utf-8')
if __name__ == "__main__":
path = u'D:\test_boject'
run = Runbat()
run.run_all_bat(path)
注意在run_all_bat()方法下面加上清晰的注释,最好给个实例。这样在robot framework 的帮助中能看到这些信息,便于使用者理解这个关键字的使用。
对于创建普通的模块来说这样已经ok了。但要想在robot framework启动后加载这个关键字,还需要在CustomLibrary目录下创建__init__.py文件,并且它不是空的。
from runbat import Runbat
class CustomLibrary(Runbat):
"""
这里也可以装x的写上我们创建的CustomLibrary如何如何。
"""
ROBOT_LIBRARY_SCOPE = 'GLOBAL'
这个文件中其实有用的信息就三行,但必不可少。robot framwork 在启动时会加载这个文件,因为在这个文件里指明了有个runbat文件下面有个Runbat类。从而加载类里的方法(run_all_bat())。
下面,启动robot framework RIDE,按F5:
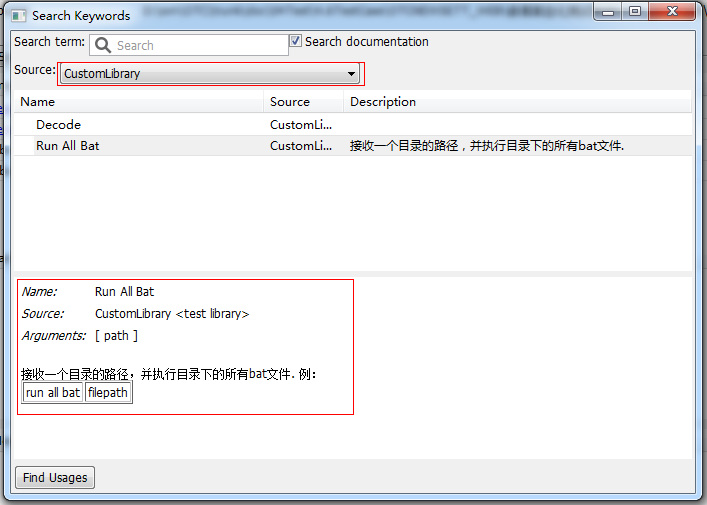
找到了我们创建的关键字,下面就是在具体的项目或测试套件中引用CustomLibrary
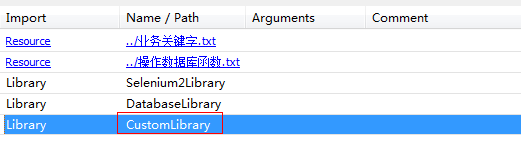
然后,在具体的测试用例中使用“run all bat” 关键字。
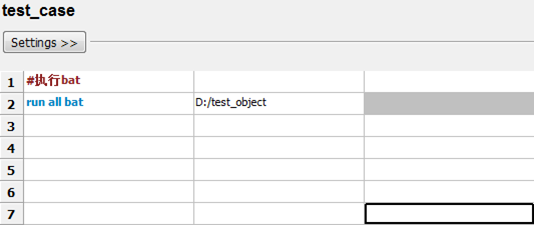
6、Robot Framework 连接Oracel数据库
Robot Framework 提供了多种Library。其中Database Library可用来连接操作数据库。
1.安装Database Library
打开Robot Framework官网,找到Database Library,选择Python版的。地址:http://franz-see.github.io/Robotframework-Database-Library/
Database Library的运行需求包括:
Python环境
Robotframework
Database API Specification 2.0 Python Module
其中的Python与Robot Framework我们已经安装过,现在需要安装一个Database API Specification 2.0 Python Module,也就是用于连接数据库的Python模块。这里的逻辑是这个样子的,Database Library实际上是一个处在Robot Framework和Database Interfaces 中间的代理模块,Robot Framework 通过Database Library 所提供的接口,间接的调用各数据库的Database Interfaces,从而实现操作数据库的目的。
打开Database Interfaces页面,找到Oracle的API驱动及下载地址,找到你对目前python环境对应版本的安装文件,下载安装http://sourceforge.net/projects/cx-oracle/files/
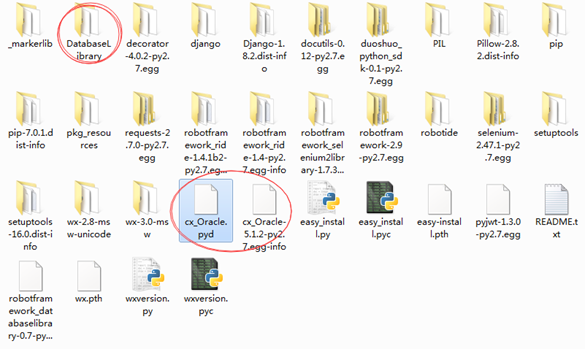
之后,下载安装DatabaseLibrary。安装完成后,在你的 Python27Libsite-packages目录下,可以看到Database Library文件夹和cx_Oracle.pyd文件
2.编写测试脚本
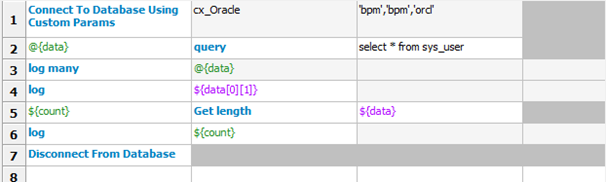
我们编写一个数据库查询的测试用例,脚本如下:
Connect To Database Using Custom Params cx_Oracle 'bpm','bpm','orcl'
@{data} query select * from sys_user
log many @{data}
log ${data[0][1]}
countGetlengthcountGetlength{data}
log ${count}
Disconnect From Database
运行脚本,结果如下
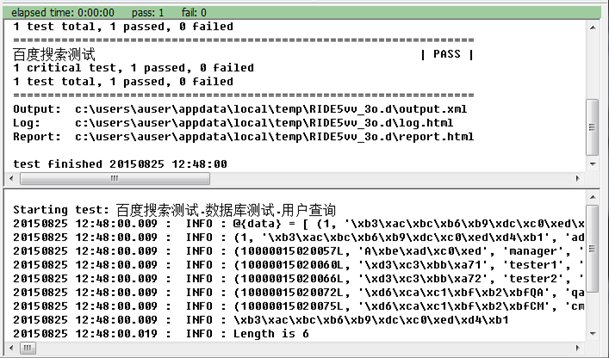
运行后查看Log,表中的中文全部变成了乱码。cx_Oracle的默认编码不是Utf-8,需要人工转换一下。DataBaseLibrary自身没有提供转换函数,为了解决这个问题,我们需要对DataBaseLibrary进行扩展。
3.解决Database Library中文乱码问题
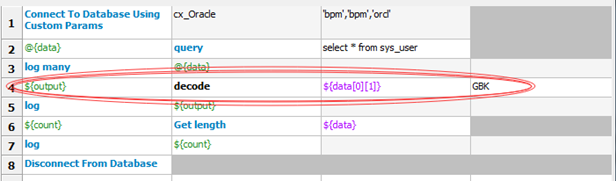
打开安装目录下的 query.py文件,添加一个decode函数,用于对字符串进行解码
def decode(self,customstr,mode):
return customstr.decode(mode)
更改测试脚本,增加转码过程
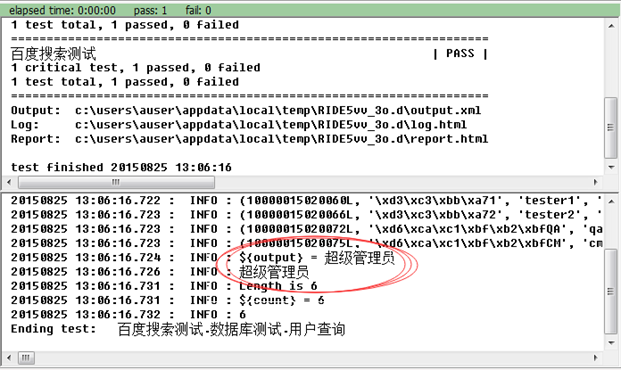
再次运行,得到系统输出,测试通过
7、Robot Framework 使用条件表达式
主要对如何在Robot Framework中使用条件表达式做过程控制作说明。按照Robot Framework的官方文档介绍,Robot Framework并不建议在TestCase或Keyword的编写中使用条件表达式,应为这样做会使TestCase变得难以理解。它提倡的是将逻辑过程写在自定义的Test Library中,之后再执行Test Library中的方法,并获取其执行结果。尽管如此,RobotFramework还是提供了一些Keyword可以用于条件判断。
1. Run Keyword
Run Keyword可以将一个关键字作为一个参数,并执行该关键字,同时,该关键字可以是从之前的内容中动态获取的变量。举例来说。
我们在自定义的MyLibrary.py库中,增加一个方法,用于进行条件判断,并返回结果。
def get_result(self,arg):
if int(arg) > 0:
return 'LOG'
else:
return 'FAIL'
建立TestSuite“IF测试”,建立TestCase“Run_Keyword”,引用MyLibrary.py,编写脚本。
1)编写输入数据>0的脚本
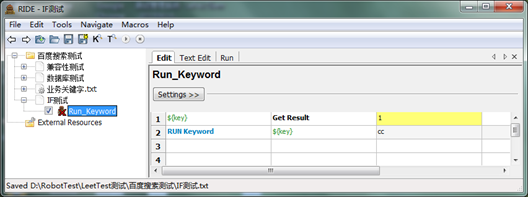
运行,并查看测试结果,此时,“Log”作为“Get Result”的返回结果,赋值给了${key},并在Run Keyword时被执行
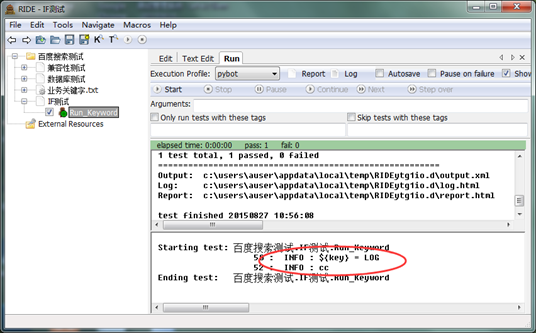
2)编写输入数据=0的脚本

运行,并查看测试结果,此时,“Fail”作为“Get Result”的返回结果,赋值给了${key},并在Run Keyword时被执行
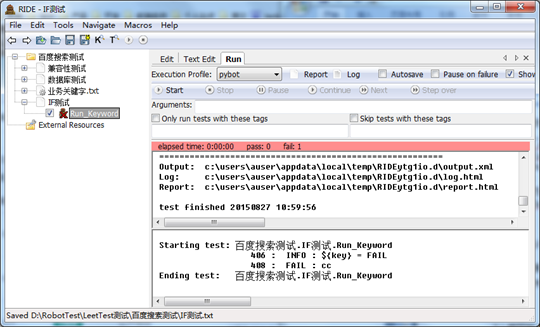
2. Run Keyword If / Run Keyword Unless
Run Keyword If 和 Run Keyword Unless 当满足条件表达式要求时,执行指定关键字。可以用于简单的IF/ELSE 逻辑。例如。我们编写脚本如下:

其中 … 用于语句分段。运行测试用例,执行结果为:
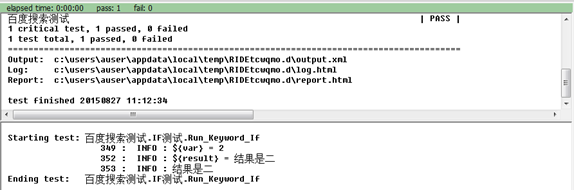
对应的Run Keyword Unless的用例及执行结果为:
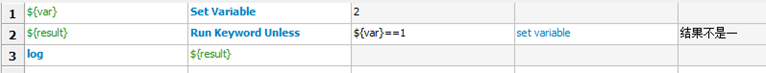
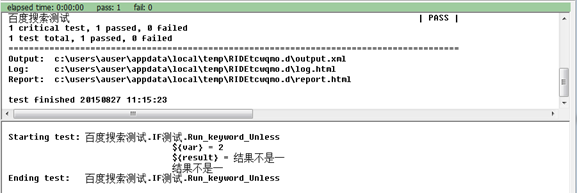
3. Set Variable If
Set Variable If用于根据表达式,动态的设置变量值。我们编写脚本如下:

执行测试用例,执行结果为:
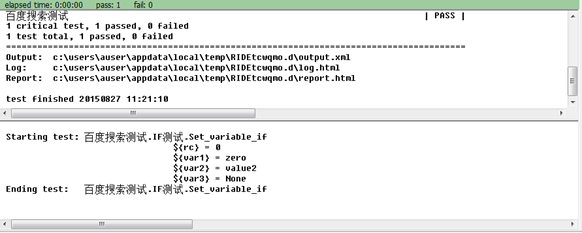
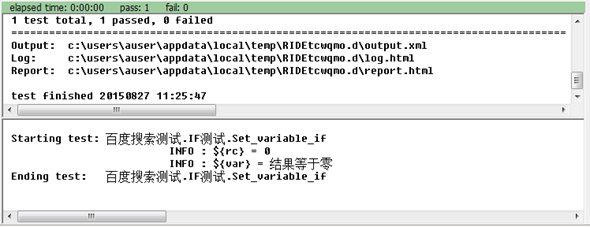
以上的方法可以用于做if/else简单分支的逻辑处理,对于存在else if等情况时,可以采用如下方法:

对应的执行结果为:
8、Robot Framework使用For循环
在自动化测试过程中,使用For循环来对某个动作进行重复操作是很普遍的行为。在Robot Framework中,各种测试库中均提供了多种方式的For循环结构,在其中覆盖了大部分类型的循环类型。而Robot Framework自身也包含了多种的For循环语法结构,可用于独立编写带循环结构的测试脚本。
For循环可以在TestCase中进行使用,也可以在KeyWrod中进行使用。除了特别简单的测试用例外,一般建议在Keyword中进行使用,以便于将For循环的复杂性隐藏起来,保持测试用例结构上尽可能的简单。
1.普通的For循环
在一个普通的For循环中,循环开始的关键字是 :FOR ,其中的:用于与一般关键字做区分,对于循环结构体内的每一行,使用 作为改行的行首关键字。对于循环中的变量,可以在 IN 关键字后给出所有变量,也可以从一个列表中进行赋值,每次循环从列表中取出一个值。例如:
1)给出所有变量

2)从列表中进行赋值

执行测试用例,输出结果为:

2.嵌套循环
Robot Framework本身并不支持直接使用嵌套循环,但是可以通过在一个循环结构中使用另一个包含有循环结构的关键字来实现。例如
*** Keywords ***
Handle Row
[Arguments] @{row}
: FOR ${cell} IN @{row}
log ${cell}
Handle Table
[Arguments] @{table}
: FOR @{row} IN @{table}
Handle Row @{row}
在使用时,调用Handle Table,Handle Table再调用内层循环Handle Row,从而实现嵌套循环的目的。
3.For-in-range循环
除了针对序列的循环之外,有些时候还需要能够进行特定迭代次数的循环。Robot Framework中通过FOR index IN RANGE limit来实现,其语法与Python中的使用方式相似。
1)只使用数据上限
只使用数据上限时,数据从0开始,每次+1,数据从0直到指定数据,但不包含该数据。例如:

输出结果为0、1、2、3、4、5、6、7、8、9,数据从0开始至9结束,输出结果不包含10.
2)使用开始和结束数据
使用开始和技术数据时,数据从“开始数据”开始,每次+1,至“结束数据”结束,但不包含结束数据。例如:

输出结果为2、3、4、5、6、7、8、9、10,数据从2开始至10结束,输出结果不包含11.
3)使用开始、结束、步长
使用 开始、结束、步长 时,数据从“开始数据”开始,每次+“步长数据”,至“结束数据”结束,但不包含结束数据。例如:

输出结果为2、5、8,数据从2开始至11结束,每次累加3,输出结果不包含11.
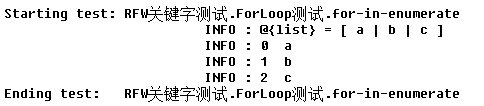
4.For-in-enumerate循环
有些时候需要知道当前循环中的循环位置的index编号,此时可以使用FOR index ... IN ENUMERATE ...关键字。在取index编号时,固定使用 ${index} 作为变量名,例如

运行结果为
5.多变量循环
与Python中的for循环类似的是,当列表中的变量数量可以被一定数量整除时,可以直接使用等于该数量的变量做循环。例如

6.For-in-zip 循环
对于有些测试来说,可能会用到多个列表的数据,在循环中需要对这些数据进行组合使用。Robot Framework提供了一个叫做For-in-zip的关键字,该关键字来自于python内置的zip函数,可用于对列表进行组合。例如

这里注意,我们在定义一个列表变量时,可以使用列表名,也可以使用@列表名,而在for−in−zip循环中使用该关键字时,只能使用列表名,也可以使用@列表名,而在for−in−zip循环中使用该关键字时,只能使用{列表名}。执行测试用例,结果如下:

7.跳出循环
一般来说一个循环结构的用例需要遍历完所有数据后再退出。某些情况下,需要提前终止并跳出循环时,可以使用Exit For Loop 或者 Exit For Loop If。例如
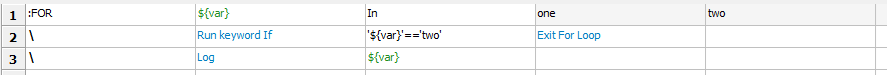
或是使用

执行测试用例,输出结果为:

8.在循环中使用continue
有些时候,需要在循环中使用continue来跳过循环结构体中的某些过程。在Robot Framework中,可以使用Continue For Loop 或者 Continue For Loop If。具体用法与跳出循环时的Exit用法一致,这里不再做演示。
9.重复执行单一关键字
某些情况下,循环结构可能只需要对一个关键字做执行次数的循环。Robot Framework提供了一个关键字Repeat Keyword,只需指明循环次数和循环中的关键字即可。而在描述循环次数时,有时为了让测试用例易于理解,可以在次数后面添加一个times 或 x 例如:

五、Robot Framework分层思想
谈到Robot Framework 分层的思想,就不得不提“关键字驱动”。在程序设计的讲究设计模式,设计模式其实就是根据需求使用抽象与封装,其实就是分层思想。把一个实现过程分成不同多层。提高的灵活性,从而达到可扩展性和可维护性。再回到自动化的话题上,我们可以把操作步骤封装一个一个的方法(关键字),通过调用关键字来实现测试用例。
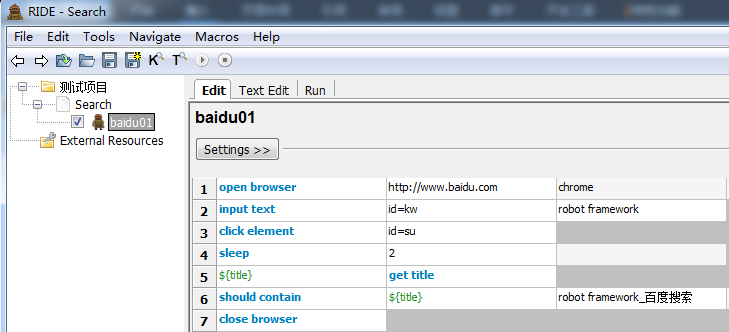
我现在要写5条百度搜索的用例:
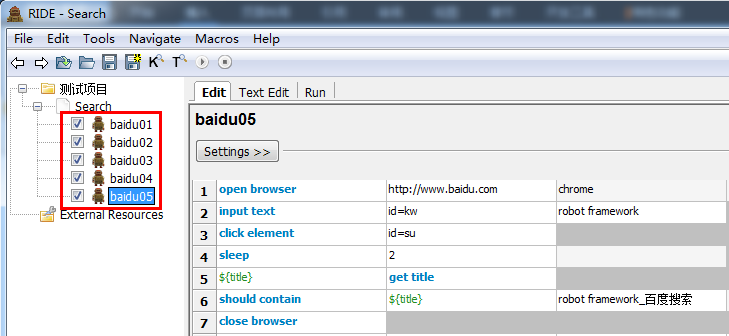
可以在Search测试套件下创建5条测试用例。其实对于每一条测试用例来说,只是搜索的内容不同,脚本步骤是完全一样的。这样做无疑增加的脚本的冗余,而且不便于维护。假如,百度输入框的定位方式变了,我不得不打开每一条用例进行修改。
我们可以过创建关键字的方式,从而实现分层的思想来解决这个问题。
Robot Framework 关键字
1、创建资源
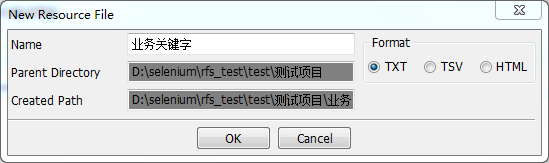
右键“测试项目”选择“new resource”创建资源。
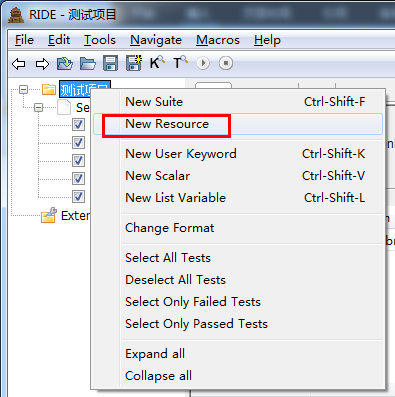
输入资源名称:
2、创建关键字
右键“业务关键字”选择“new User Keyword” 来创建用户关键字。
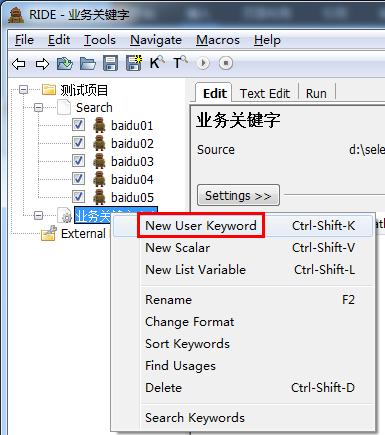
输入关键字的名称:
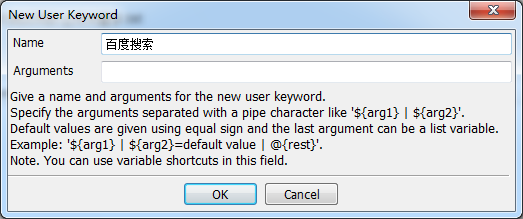
3、编辑关键字
分析:
对于一个测试用例来说,用户关心的是输入什么内容,得到什么结果。
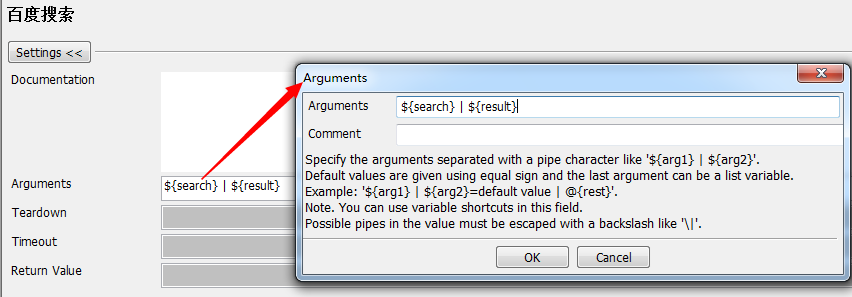
所以,对于“百度搜索”关键字来说,需要创建两个接口变量search和search和{result} 两个变量,用于接收输入内容和预期结果。
点击Arguments输入框,定义变量,多个变量从用“|”隔开。
在百度用户中使用参数化变量。
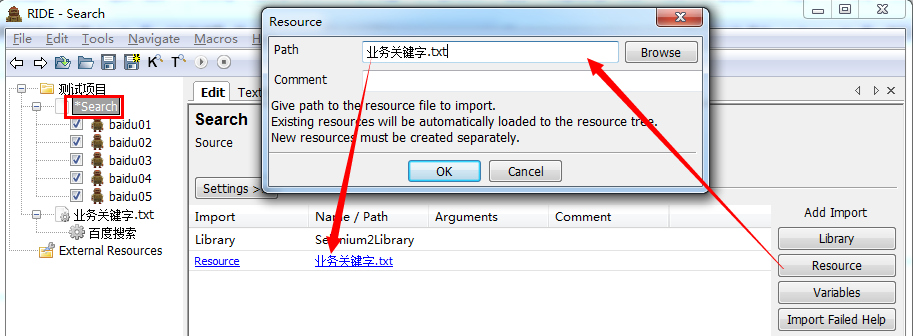
4、添加创建的资源
切换到测试套件(Search)页面,添加资源(业务关键字.txt)
5、调用关键字
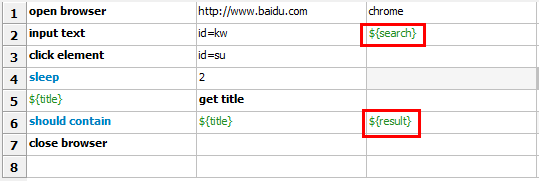
现在就可以在测试用例中使用创建的关键字了(百度搜索)。
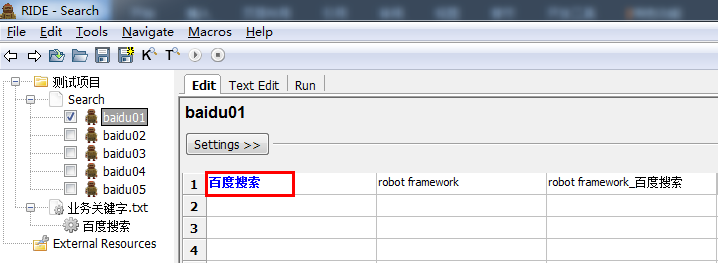
对于每一条用例来说,调用“百度搜索”关键字,输入搜索内容,输入预期结果即可。不同关心用例是如何执行的。如果百度输入框的定位发生了变化,只用去修改“百度搜索”关键字即可,不用对每一条用例做任何修改。大大提高的用例的维护性和扩展性。
继续分层的设计:
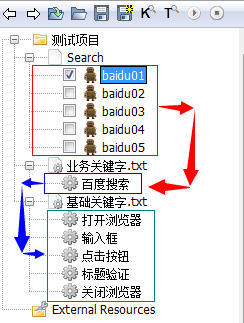
到此,Robot Framework +selenium 自动化测试粗犷的讲完了。当然还有更多API 的使用,和细枝末节的设置没有介绍。但我们已经可以拿它来开展自动化工作了。
流程与数据分离
将搜索测试中的内容继续分层,还是要把一些底层的代码级关键字继续拆分出来
下面对res1.txt进行操作
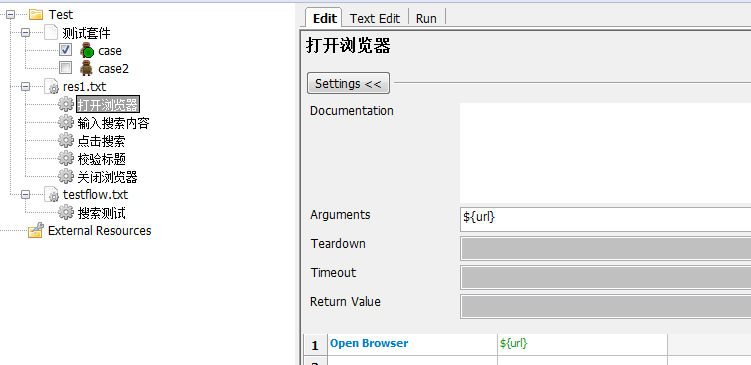
1.打开浏览器
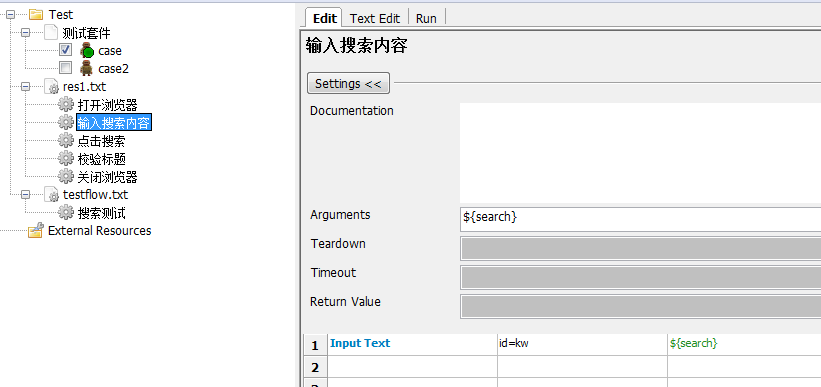
2.输入搜索内容
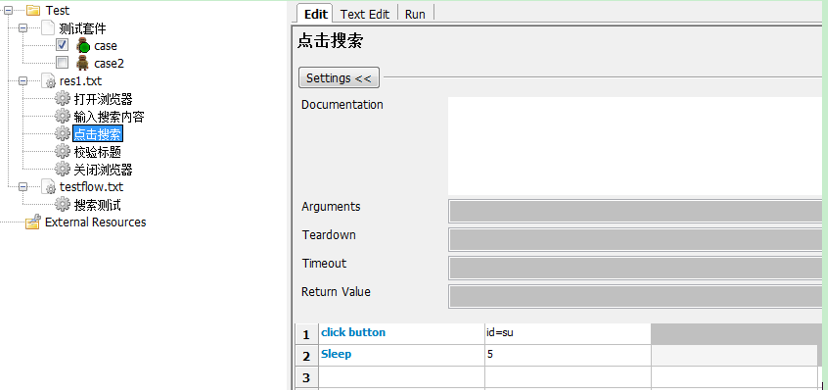
3.点击搜索
4.校验标题
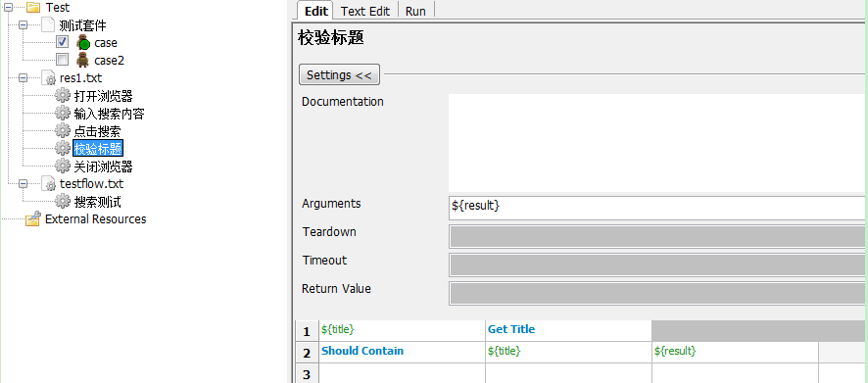
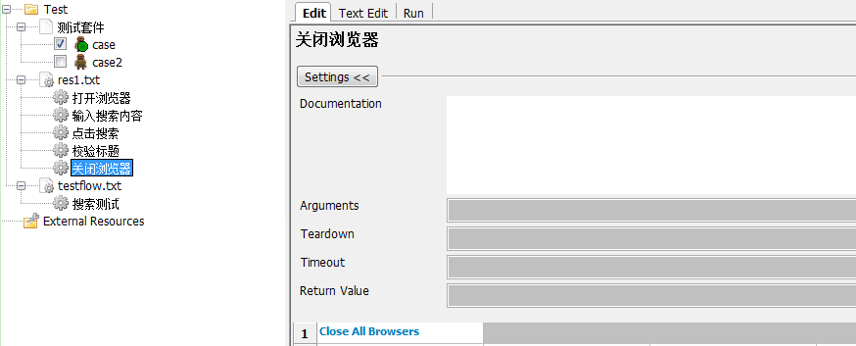
5.关闭浏览器
接着我们把对应的搜索测试中的代码都换成相应的关键字,记得添加参数${url}
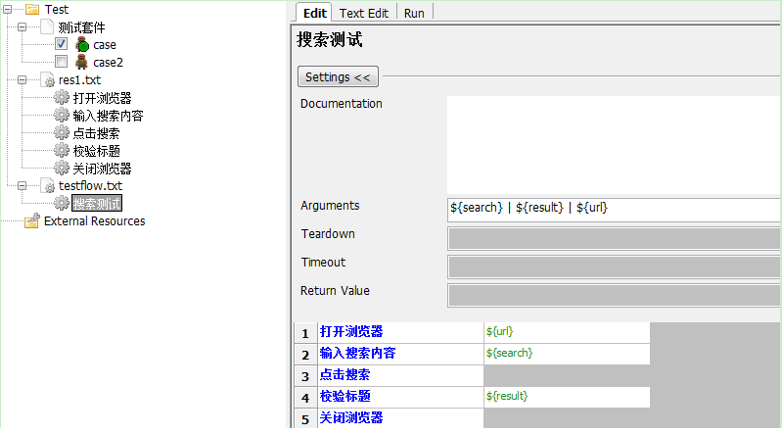
最后该运行了
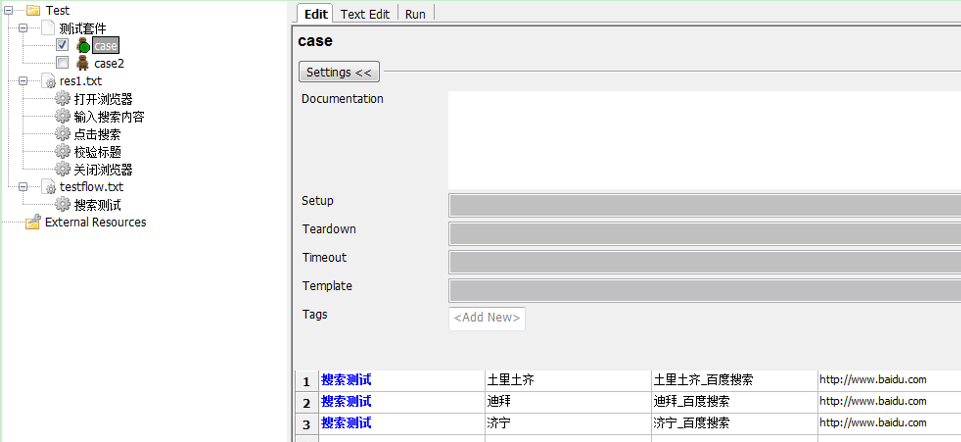
至此,我们这个案例就已经完成分层了,因为案例比较简单,所以只分了3层,分别是案例层,流程层,元素层。他们的调用关系也是逐层深入的
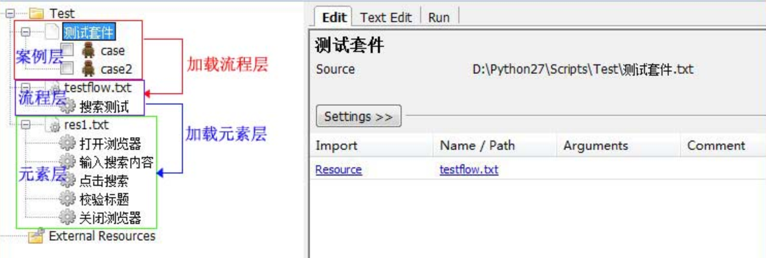
流程与数据分离的好处不单是为了以后维护方便,也使得案例的架构层级清晰。越是靠近上层的部分,脚本越贴近自然语言,或者说很像我们的测试案例;越靠近下层的部分,越是接近页面元素的代码级部分。这样以后如果发生维护的时候,根据需要维护的内容,只需要在很少的地方进行调整即可。比如一个元素的id变了,那我只要在elements里面更新就行了。比如测试的流程调整了,以前是ABC的页面顺序,现在是ACB的页面顺序,那么只要在testflow层进行调整即可。实际上目前我们的流程都集中在testflow以及下面的部分,而数据一般都是在案例层去给流程层传递,这就是我们的流程与数据分离了。当然,我们还可以再进一步的分离,把数据放到外面,脱离我们的案例,在运行的时候才传递进行,也是可以实现的。后面我会做个简单的例子给大家看。
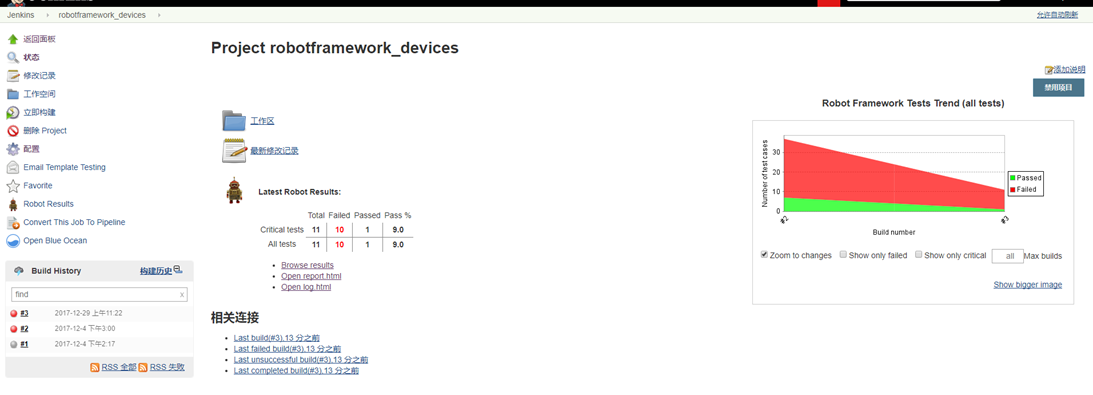
Robotframework+jenkins配置
假设我们完成了一个模块的用例设计,可是想晚上9点或凌晨运行,这时候该怎么实现呢?jenkins可以很好解决我们的疑难。
Jenkins安装
这里简单说下安装,建议下载war包在tomacat中启动或是直接在cmd中使用命令启动jenkins(如果已经使用.msi安装成windows服务了,下面会提到解决方法)。
配置
- 基本信息
在jenkins主页中,新建 一个自由风格的项目,配置项目的名称等基本信息如图
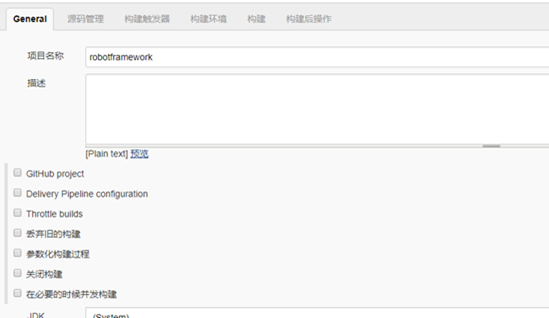
因为这里没有使用svn或git,文件直接保存在本地,所以没有使用源码管理,如果使用了源码管理的可以根据实际情况配置源码管理的配置信息。
- 构建触发器
这里选择使用Build periodically,进行定时构建,如图

这里设置的是每天凌晨2点进行构建。
这里注意选择的是build Periodically,选择的是定时构建,不管代码是否有更新;而另外一个构建方式Poll SCM,则是svn或git代码有更新才会再制定的时间内进行构建
- 构建
接下来就是构建过程,这里是windows环境,所以使用的是Execute Windows batch command
使用命令执行要运行的用例如pybot.bat -d F:outputdir F: estcswx,这里-d是将执行结果保存在F:outputdir目录下,而F: estcswx是需要执行用例的文件夹

- 构建后操作
这里提前需要安装一个插件Public Robot Framework test result
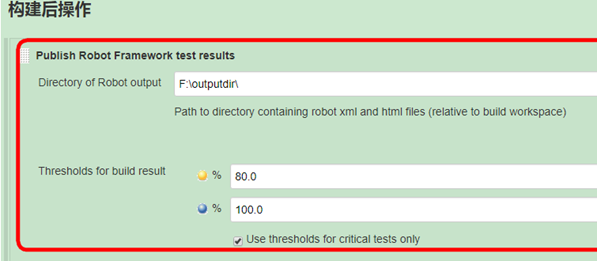
如果构建的时候,使用的是默认的输出目录,那么这里的Directory of Robot output 默认为空。
- 添加接收邮箱
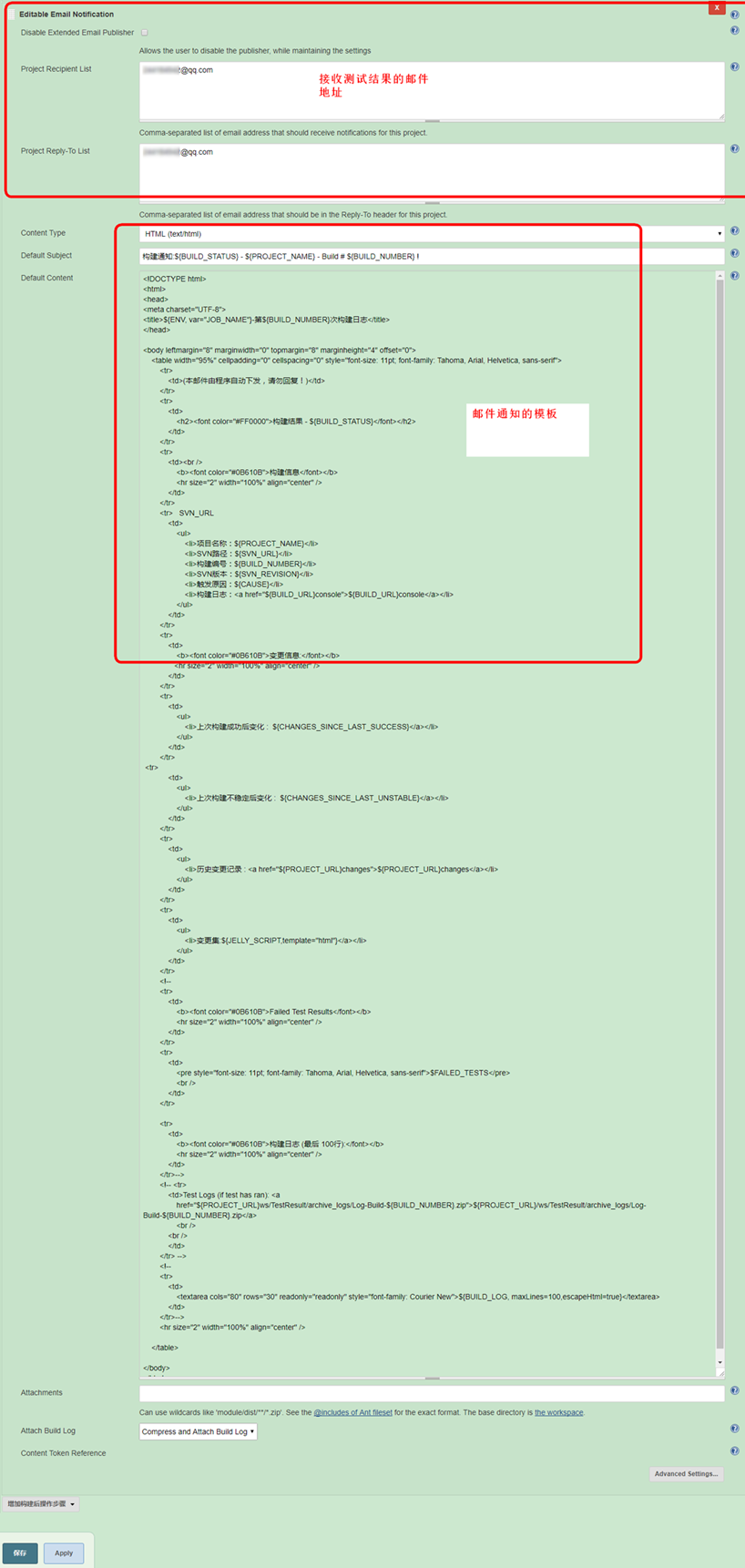
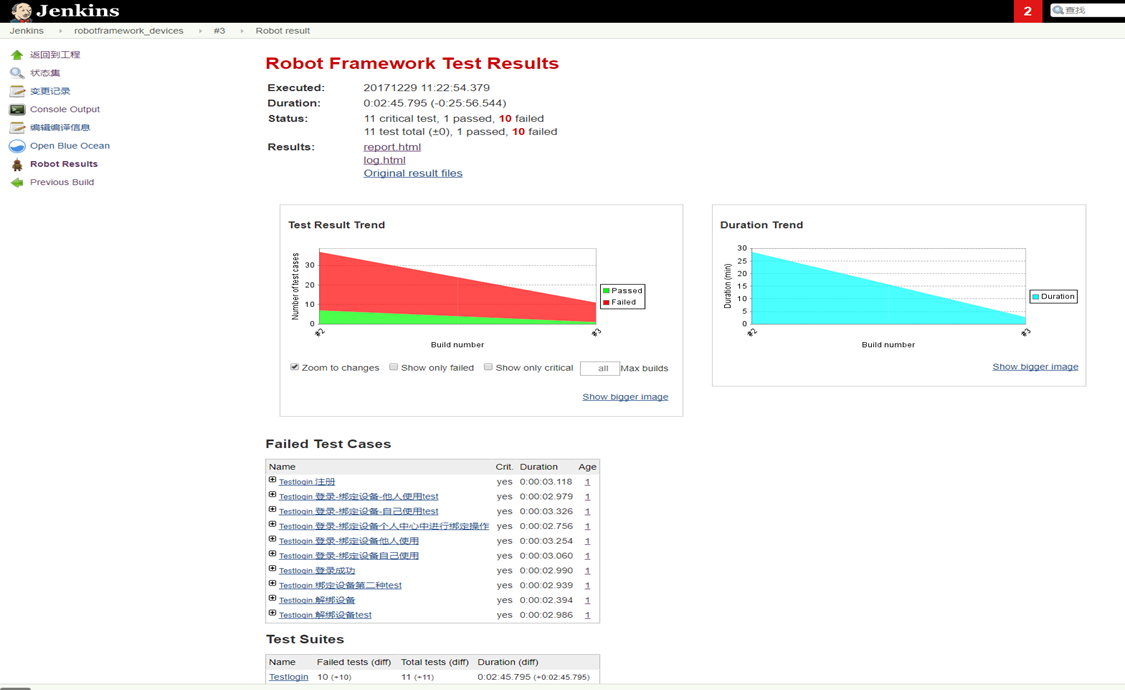
- 执行结果
构建之后查看结果如图