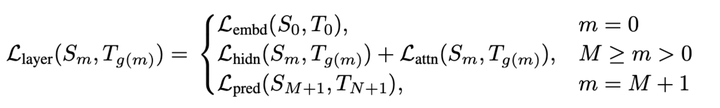TinyBERT 是华为不久前提出的一种蒸馏 BERT 的方法,模型大小不到 BERT 的 1/7,但速度能提高 9 倍。本文梳理了 TinyBERT 的模型结构,探索了其在不同业务上的表现,证明了 TinyBERT 对复杂的语义匹配任务来说是一种行之有效的压缩手段。
一、简介
在 NLP 领域,BERT 的强大毫无疑问,但由于模型过于庞大,单个样本计算一次的开销动辄上百毫秒,很难应用到实际生产中。TinyBERT 是华为、华科联合提出的一种为基于 transformer 的模型专门设计的知识蒸馏方法,模型大小不到 BERT 的 1/7,但速度提高了 9 倍,而且性能没有出现明显下降。目前,该论文已经提交机器学习顶会 ICLR 2020。本文复现了 TinyBERT 的结果,证明了 Tiny BERT 在速度提高的同时,对复杂的语义匹配任务,性能没有显著下降。
目前主流的几种蒸馏方法大概分成利用 transformer 结构蒸馏、利用其它简单的结构比如 BiLSTM 等蒸馏。由于 BiLSTM 等结构简单,且一般是用 BERT 最后一层的输出结果进行蒸馏,不能学到 transformer 中间层的信息,对于复杂的语义匹配任务,效果有点不尽人意。
基于 transformer 结构的蒸馏方法目前比较出名的有微软的 BERT-PKD (Patient Knowledge Distillation for BERT),huggingface 的 DistilBERT,以及本篇文章讲的 TinyBERT。他们的基本思路都是减少 transformer encoding 的层数和 hidden size 大小,实现细节上各有不同,主要差异体现在 loss 的设计上。
二、模型实现细节
TinyBERT 的结构如下图:
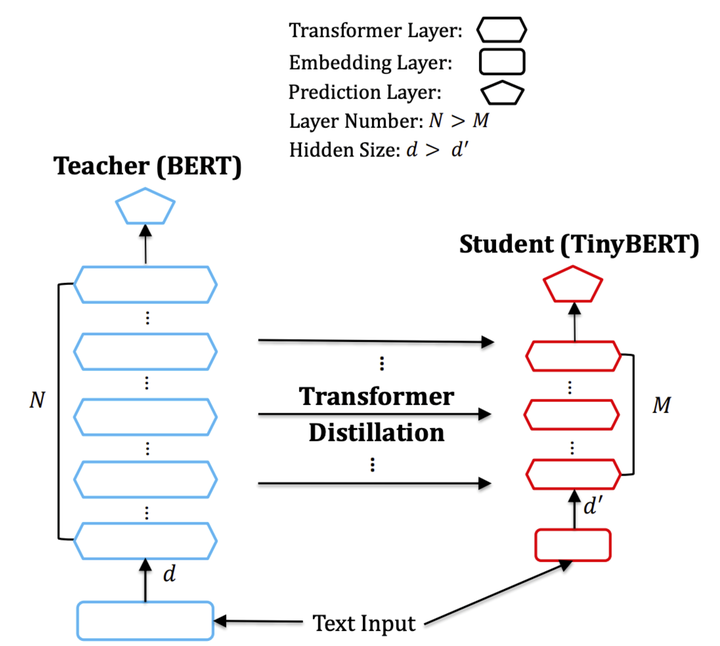
整个 TinyBERT 的 loss 设计分为三部分:
1. Embedding-layer Distillation
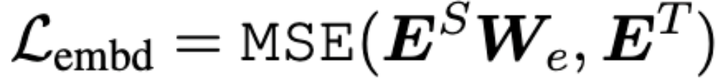
其中:
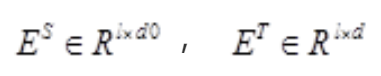
分别代表 student 网络的 embedding 和 teacher 网络的 embedding. 其中 l 代表 sequence length, d0 代表 student embedding 维度, d 代表 teacher embedding 维度。由于 student 网络的 embedding 层通常较 teacher 会变小以获得更小的模型和加速,所以 We 是一个 d 0×d 维的可训练的线性变换矩阵,把 student 的 embedding 投影到 teacher embedding 所在的空间。最后再算 MSE,得到 embedding loss.
2. Transformer-layer Distillation
TinyBERT 的 transformer 蒸馏采用隔 k 层蒸馏的方式。举个例子,teacher BERT 一共有 12 层,若是设置 student BERT 为 4 层,就是每隔 3 层计算一个 transformer loss. 映射函数为 g(m) = 3 * m, m 为 student encoder 层数。具体对应为 student 第 1 层 transformer 对应 teacher 第 3 层,第 2 层对应第 6 层,第 3 层对应第 9 层,第 4 层对应第 12 层。每一层的 transformer loss 又分为两部分组成,attention based distillation 和 hidden states based distillation.
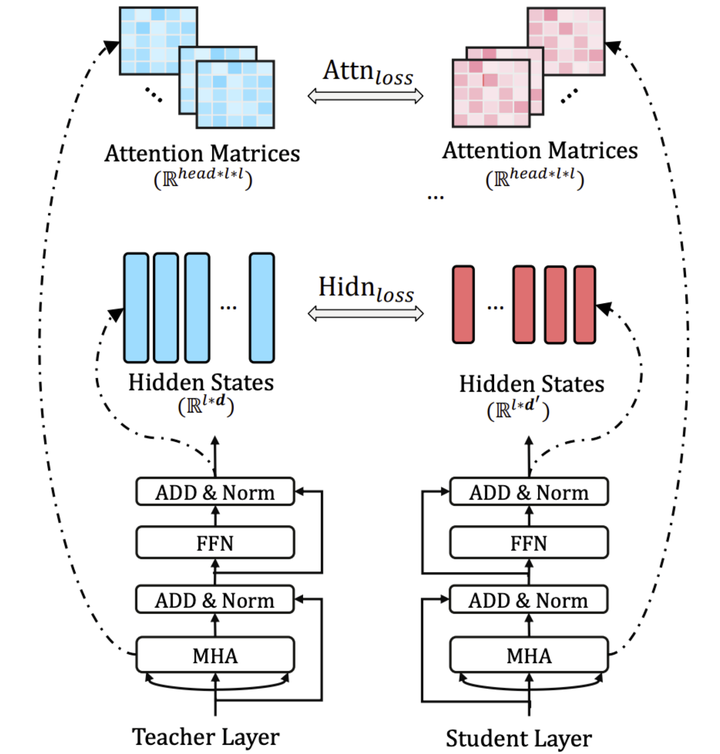
2.1 Attention based loss
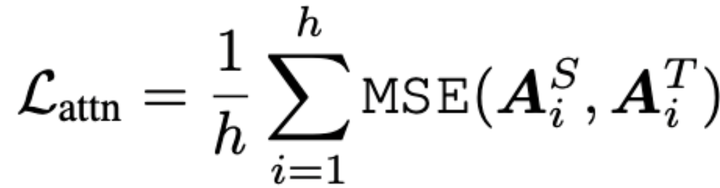
其中,
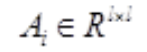
h 代表 attention 的头数,l 代表输入长度,
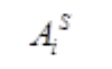
代表 student 网络第 i 个 attention 头的 attention score 矩阵,
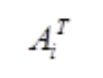
代表 teacher 网络第 i 个 attention 头的 attention score 矩阵。这个 loss 是受到斯坦福和 Facebook 联合发表的论文,What Does BERT Look At? An Analysis of BERT’s Attention 的启发。这篇论文研究了 attention 权重到底学到了什么,实验发现与语义还有语法相关的词比如第一个动词宾语,第一个介词宾语,以及[CLS], [SEP], 逗号等 token,有很高的注意力权重。为了确保这部分信息能被 student 网络学到,TinyBERT 在 loss 设计中加上了 student 和 teacher 的 attention matrix 的 MSE。这样语言知识可以很好的从 teacher BERT 转移到 student BERT.
2.2 hidden states based distillation
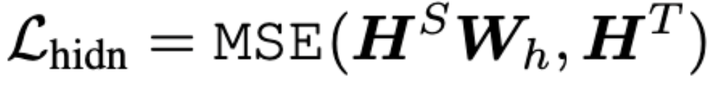
其中,

分别是 student transformer 和 teacher transformer 的隐层输出。和 embedding loss 同理,

投影到 Ht 所在的空间。
3. Prediction-Layer Distillation
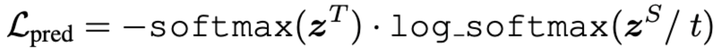
其中 t 是 temperature value,暂时设为 1.除了模仿中间层的行为外,这一层用来模拟 teacher 网络在 predict 层的表现。具体来说,这一层计算了 teacher 输出的概率分布和 student 输出的概率分布的 softmax 交叉熵。这一层的实现和具体任务相关,我们的两个实验分别采取了 BERT 原生的 masked language model loss + next sentence loss 和单任务的 classification softmax cross-entropy.
另外,值得一提的是 prediction loss 有很多变化。在 TinyBERT 中,这个 loss 是 teacher BERT 预测的概率和 student BERT 预测概率的 softmax 交叉熵,在 BERT-PKD 模型中,这个 loss 是 teacher BERT 和 student BERT 的交叉熵和 student BERT 和 hard target( one-hot)的交叉熵的加权平均。我们在业务中有试过直接用 hard target loss,效果比使用 teacher student softmax 交叉熵下降 5-6 个点。因为 softmax 比 one-hot 编码了更多概率分布的信息。并且实验中,softmax cross-entropy loss 容易发生不收敛的情况,把 softmax 交叉熵改成 MSE, 收敛效果变好,但泛化效果变差。这是因为使用 softmax cross-entropy 需要学到整个概率分布,更难收敛,因为拟合了 teacher BERT 的概率分布,有更强的泛化性。MSE 对极值敏感,收敛的更快,但泛化效果不如前者。
所以总结一下,loss 的计算公式为:
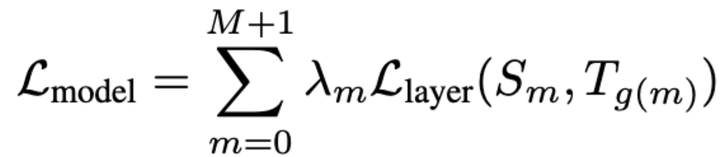
其中,