pandas简介
1.pandas是一个强大的Python数据分析的工具包,它是基于Numpy构建的,正因pandas的出现,让Python语言也成为使用最广泛而且强大的数据分析环境之一。
2.
安装方法:
pip install pandas
引用方法:
import pandas as pd
Series
1.简介:
Series是一种类似于一维数组的对象,由一组数据和一组与之相关的数据标签(索引)组成。
2.创建的几种方法
前提:

第一种方式:
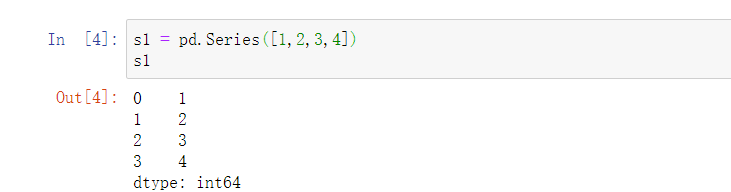
将数组索引以及数组的值打印出来,索引在左,值在右,由于没有为数据指定索引,于是会自动创建一个0到N-1(N为数据的长度)的整数型索引,取值的时候可以通过索引取
第二种方式:

自定义索引,index是一个索引列表,里面包含的是字符串,依然可以通过默认索引取值。
第三种方式:
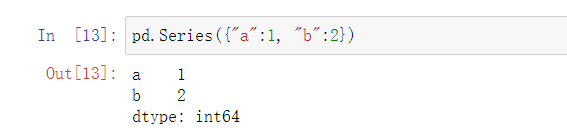
指定索引
第四种方式:
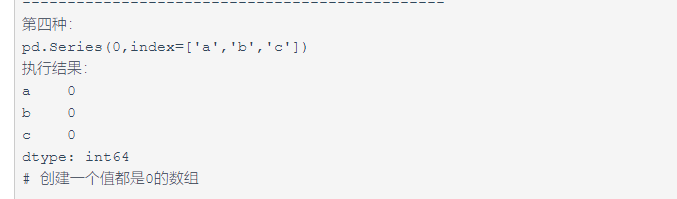
补充:以上方式可通过索引取值

3.缺失数据处理

示例和数据:

因为rocky没有出现在st的键中,所以返回的是缺失值
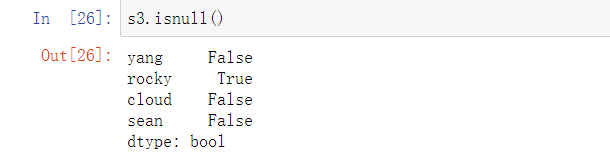
1.isnull():判断是否有缺失值,是缺失值返回Ture
2.dropna() # 过滤掉值为NaN的行

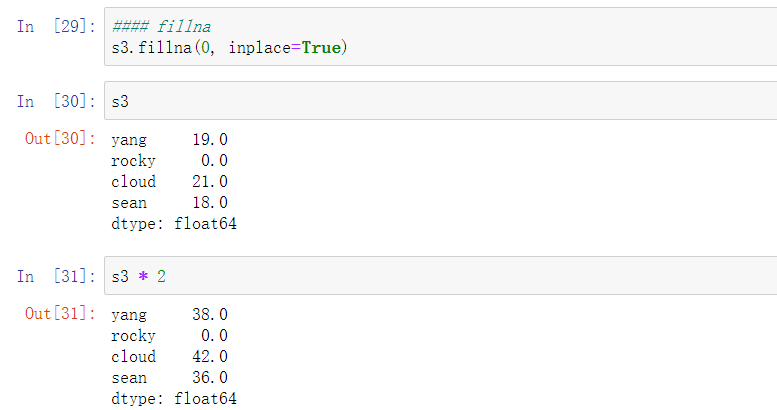
3.fillna() # 填充缺失数据
4.Series特性

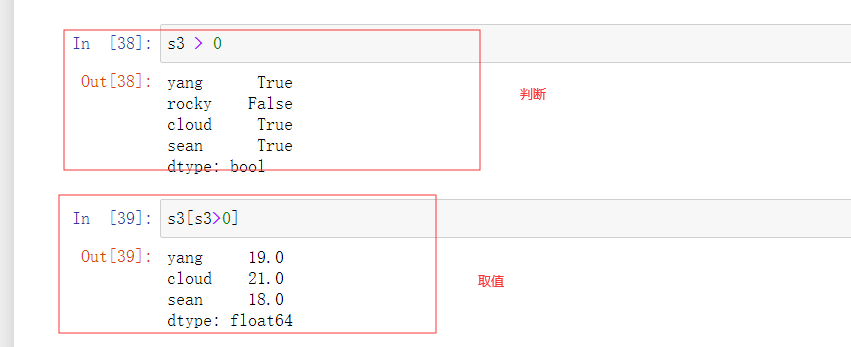
#1.加减乘除运算

#2.布尔值过滤:sr[sr>0]
5.支持字典的特性

#1.取值

6.整数索引

示例:

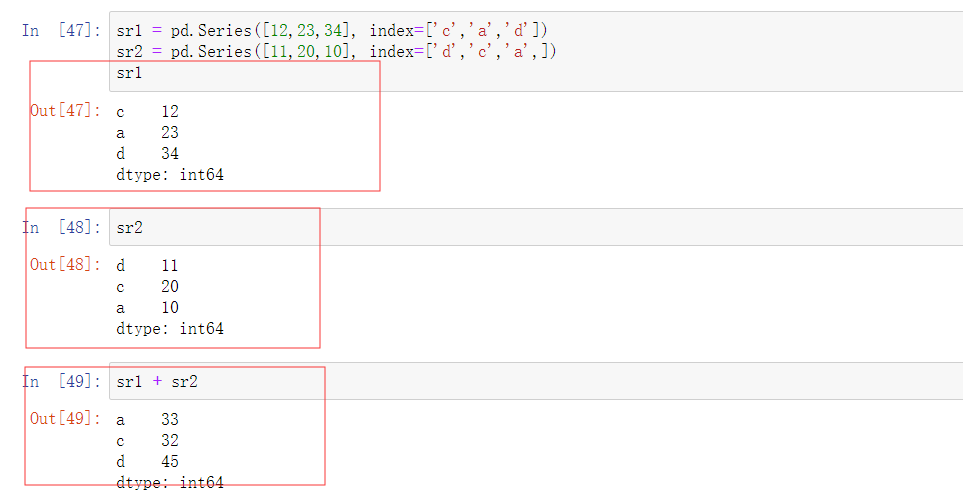
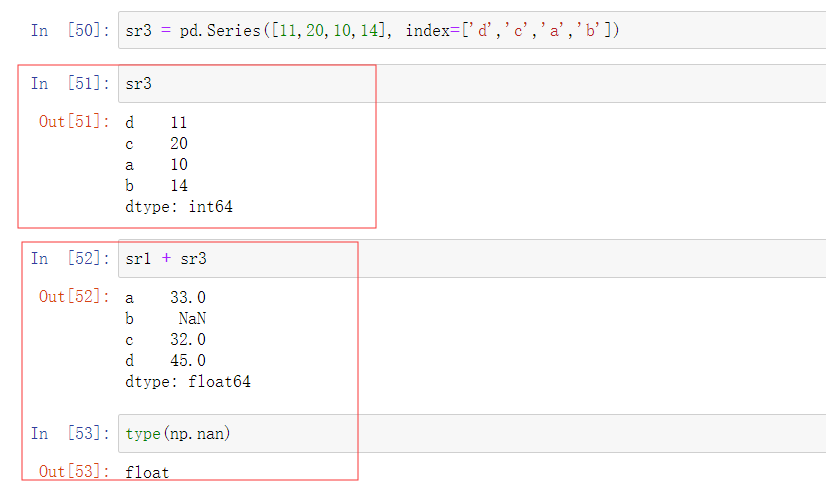
7.数据对齐
示例1:
示例2:
DataFrame
1.简介
DataFrame是一个表格型的数据结构,相当于是一个二维数组,含有一组有序的列。他可以被看做是由Series组成的字典,并且共用一个索引。
2.创建的几种方式
第一种: pd.DataFrame({'one':[1,2,3,4],'two':[4,3,2,1]}) # 产生的DataFrame会自动为Series分配所索引,并且列会按照排序的顺序排列 运行结果: one two 0 1 4 1 2 3 2 3 2 3 4 1 > 指定列 可以通过columns参数指定顺序排列 data = pd.DataFrame({'one':[1,2,3,4],'two':[4,3,2,1]}) pd.DataFrame(data,columns=['one','two']) # 打印结果会按照columns参数指定顺序 第二种: pd.DataFrame({'one':pd.Series([1,2,3],index=['a','b','c']),'two':pd.Series([1,2,3],index=['b','a','c'])}) 运行结果: one two a 1 2 b 2 1 c 3 3
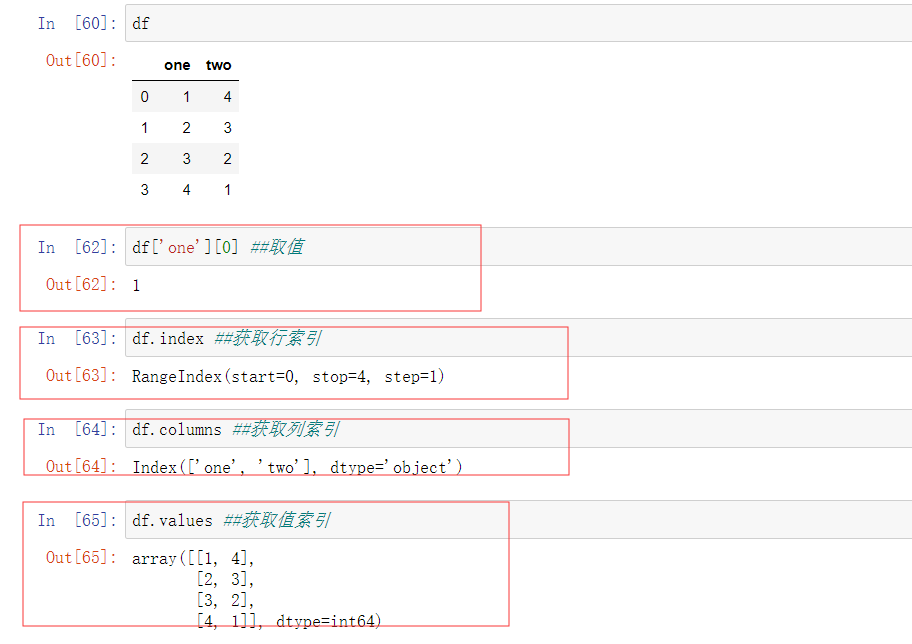
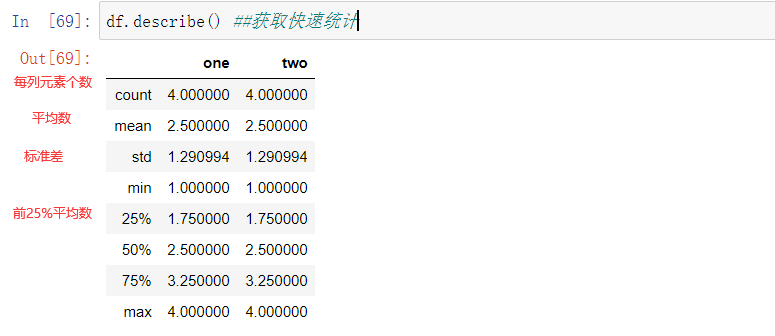
3.常用属性

示例:
4.常见获取数据方式
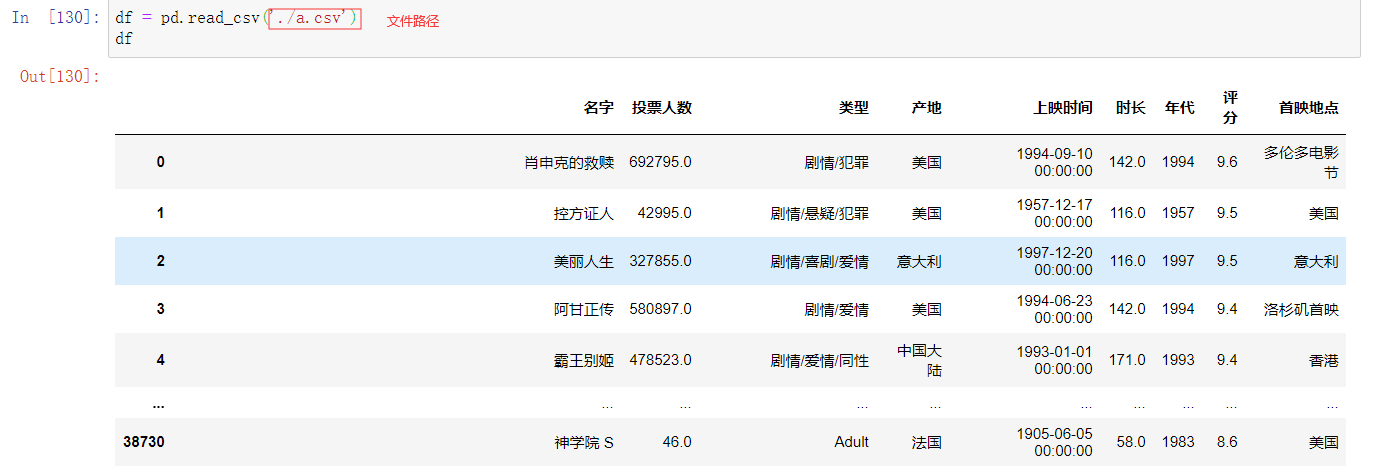
示例1:读取文件
示例2读取后规定展示数量
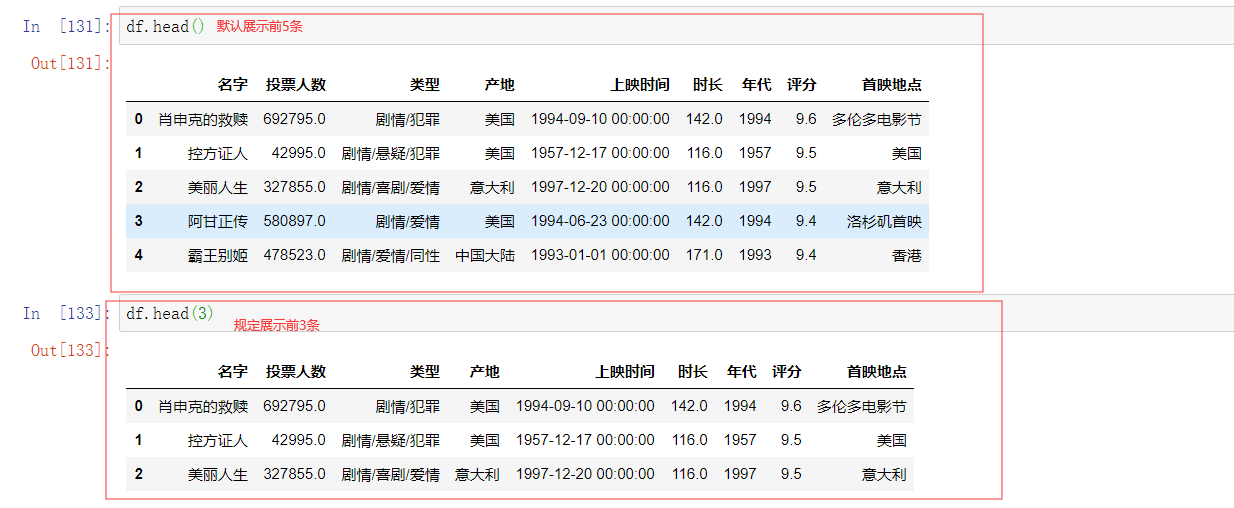
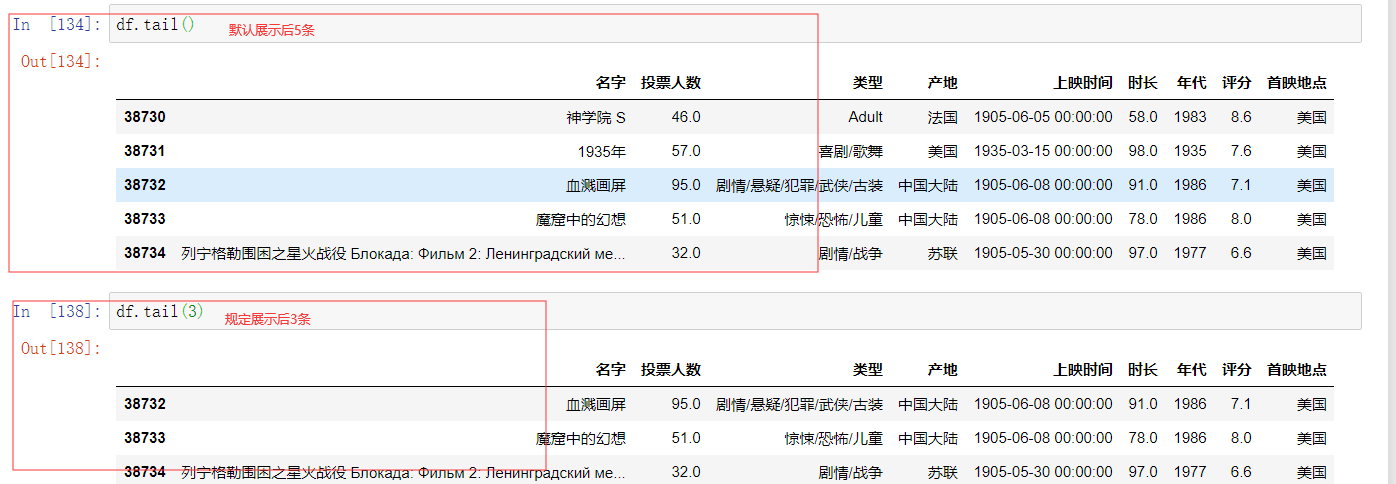
示例3另存为

5.分组
#1.read_html
示例1:
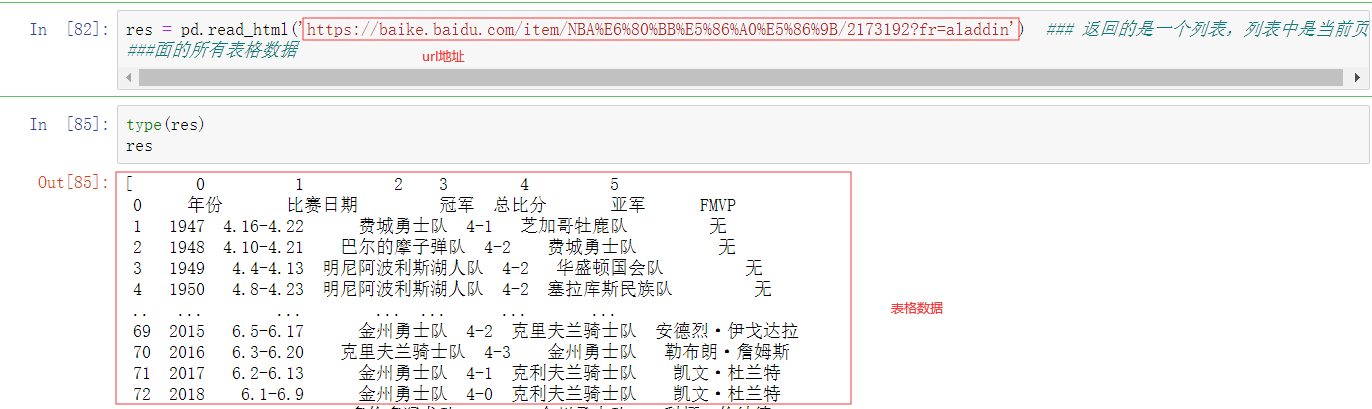
取值示例:

优化示例:
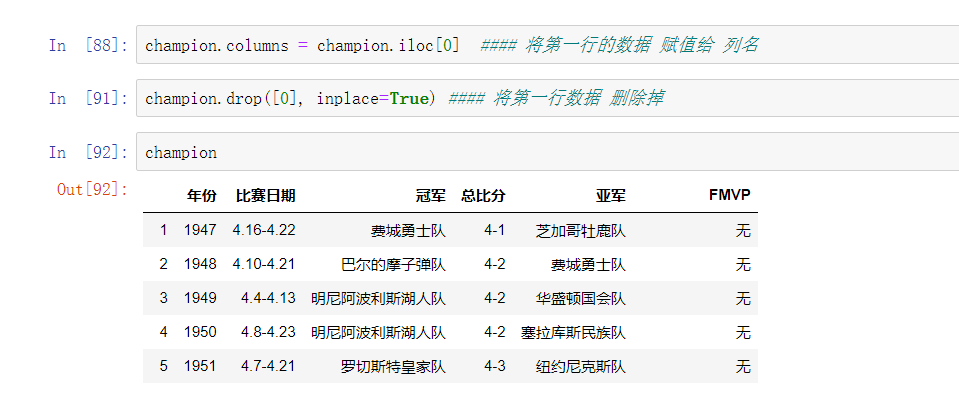
分组示例:

分组排序示例:
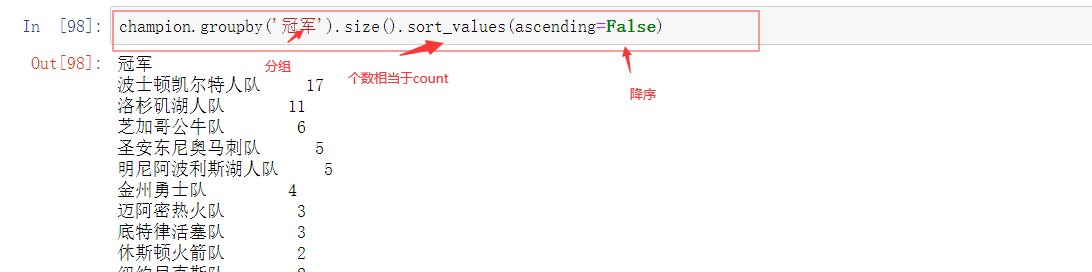
2个列字段分组

6.时间处理
1.时间转换

2.时间格式转换

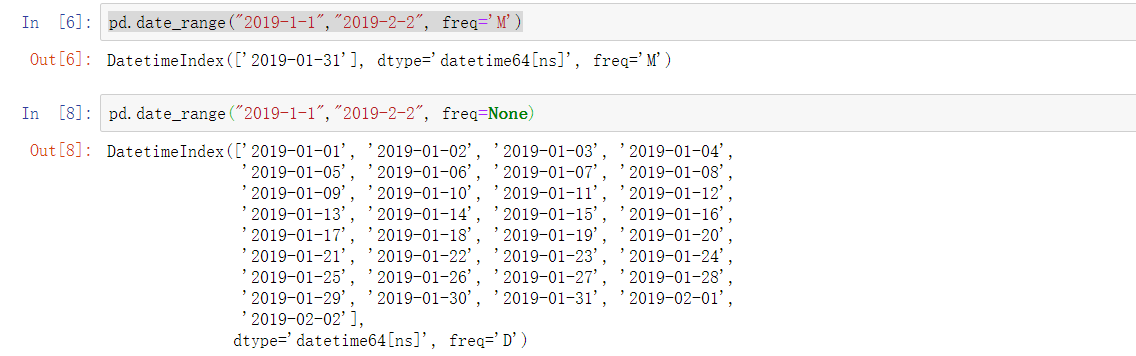
3.data_range

示例: