其实前面几个月看过人脸检测测论文,就是我写MTCNN那阵,看过了10篇?其实主要还是看的别人的专栏和总结,自己没怎么深入看。因为感觉和目标检测用的方法很像。还没决定做哪个方向之前,还是在增强基本功比较好。
人脸检测和通用目标检测的区别
1. 要求速度快,能做到实时。毕竟用在安防这种地方,讲究的就是实时监测
2. 要求效率高,因为人脸比较小,所以需要对小物体准确率比较高。
所以需要在通用目标检测框架基础上做一些见得修改。参照别人的专栏,自己写一下吧。
https://zhuanlan.zhihu.com/p/32702868
https://zhuanlan.zhihu.com/p/38512246
https://zhuanlan.zhihu.com/p/36621308
1.级联系列
https://zhuanlan.zhihu.com/p/38340206
主要参考这个人的文章,写的很详细。
Cascade CNN
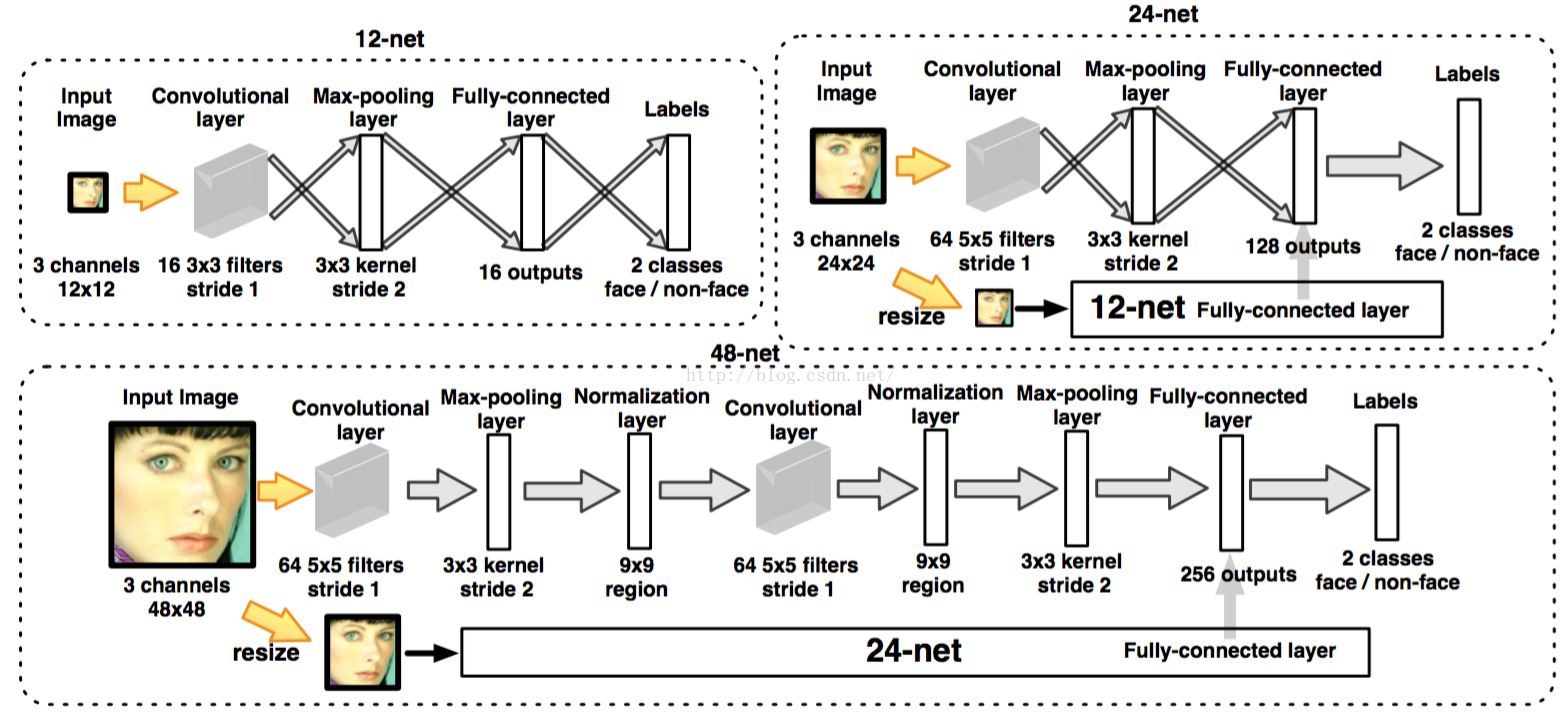
这篇为级联网络结构和CNN结合的第一论文?之后MTCNN就是在他的基础上做得修改。结构如下,3个特征提取网络,分析是否属于人脸,3个回归框调整网络,对回归框位置进行调整:

先是3个特征提取网络,12net,24net和48net,代表属于输入的图片格式大小。即使用12*12的滑动窗口进行滑动,提取图片输入网络中。12net的作用是先大量粗晒不符合的图片,为下一步准备分类减少负担。注意24net和48net都有一个分支,这个分支也会提取特征,然后与24net或48net的全连接层组合,一起判断是否属于人脸。
回归框调整网络,完全是利用先验知识做得调整。注意最后labels是48个评分,即对48种调整分别做了评分。如下:
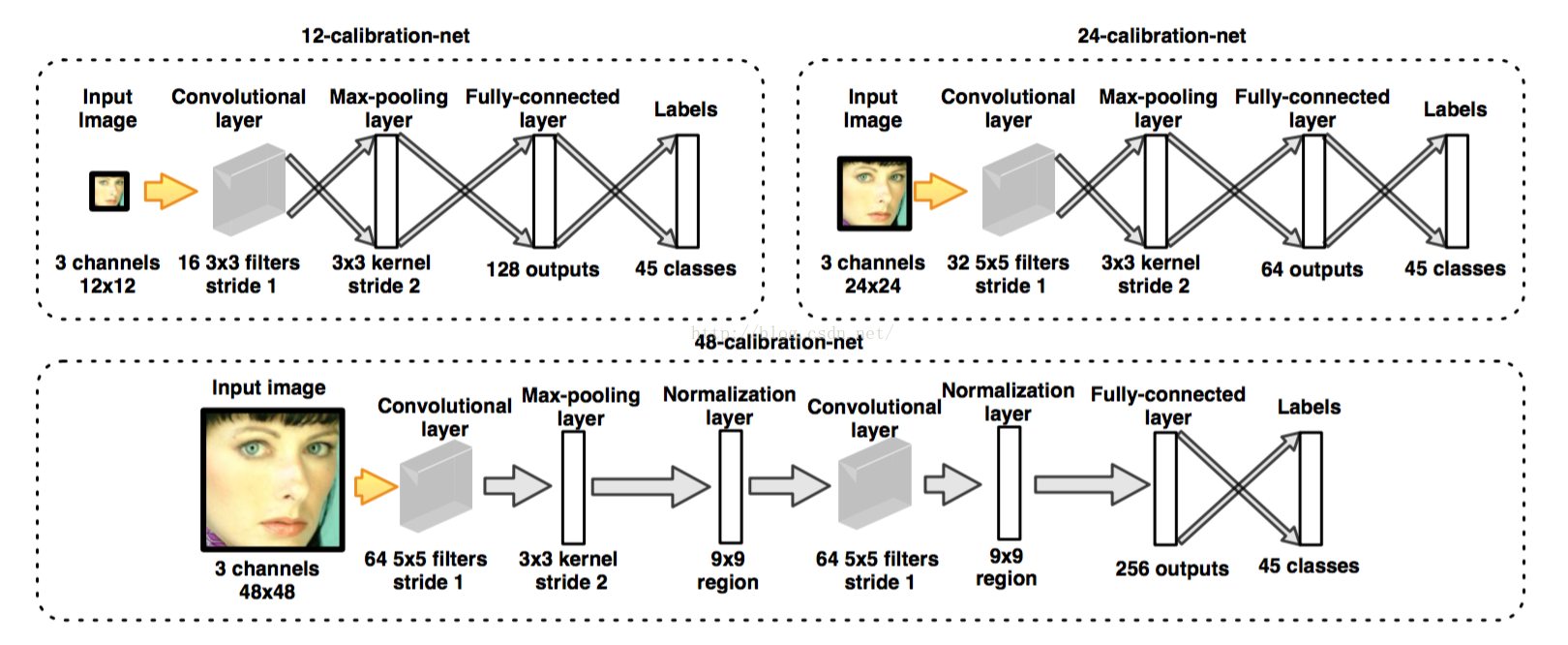
如何进行的45种调整呢?5*3*3如下:
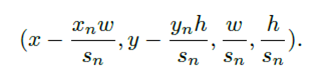
Sn:(0.83,0.91,1.0,1.10,1.21)
Xn:(-0.17,0,0.17)
Yn:(-0.17,0,0.17)
MTCNN
MTCNN是在原来Cascade CNN上做得一种调整。
第一步是先形成图像金字塔,取不同大小的图像,之后在整幅图上做全卷积,注意第一次P-net无全连接网络,因为输入的图片大小不一样。之后筛选之后将第一次的预测图像resize成24*24,然后输入到R-net中,然后进行预测。第三次resize成48*48,然后输入到O-net中,再进行预测。流程如下图:
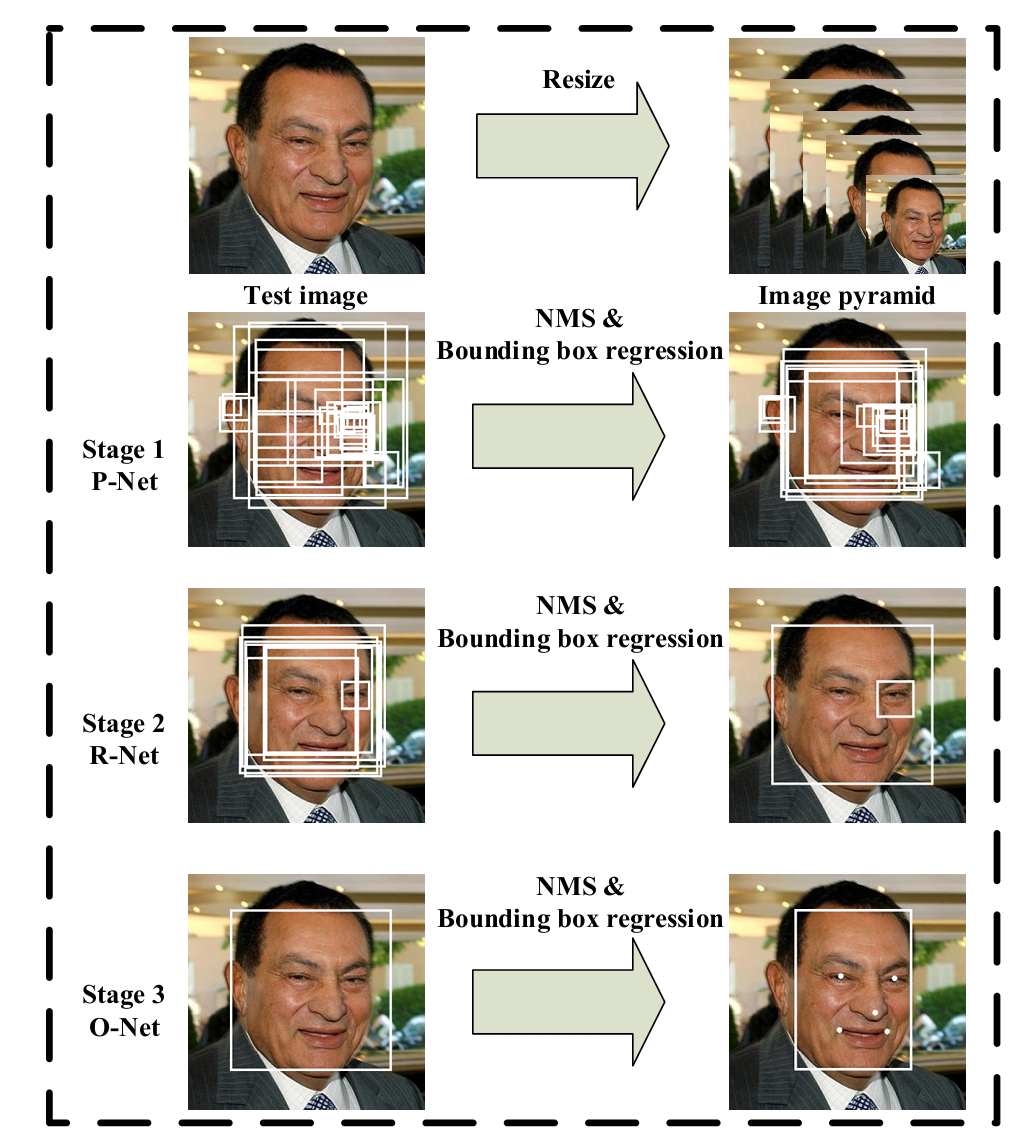
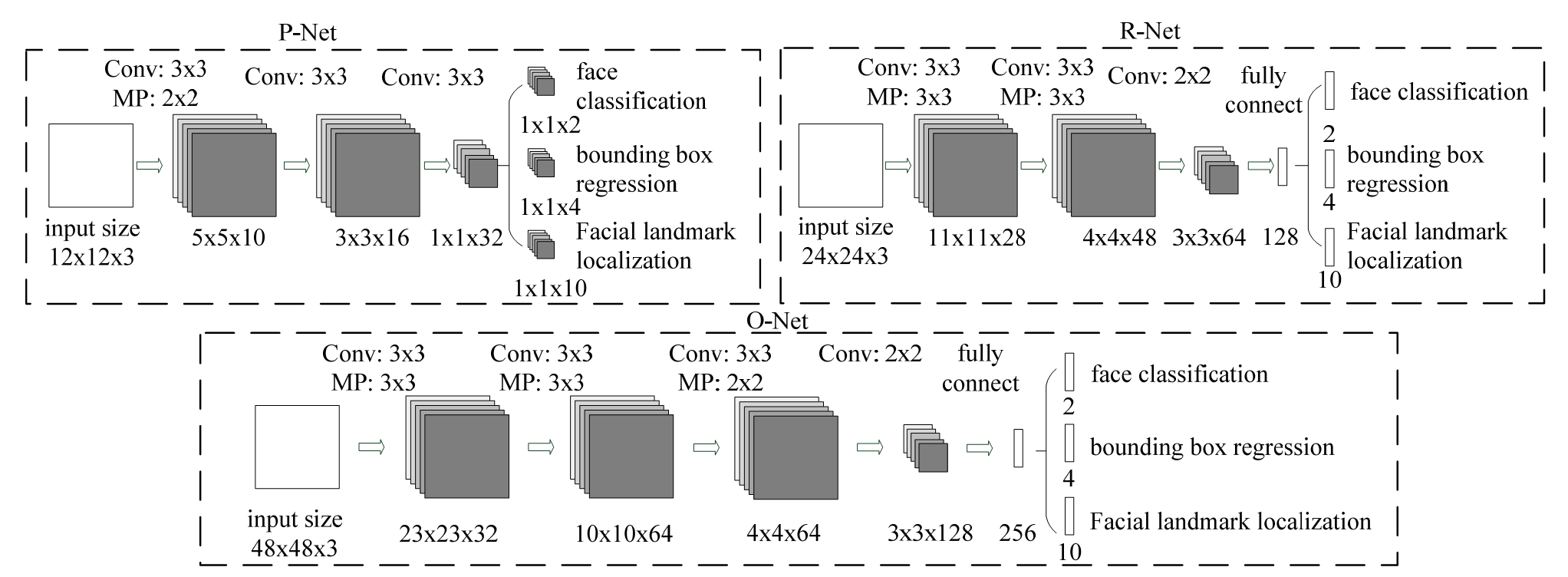
精细的网络结构如下图。可以看到和Cascade还是很像的,都是级联网络,加入了关键点检测,同时第一层12*12网络也去掉了全连接层:
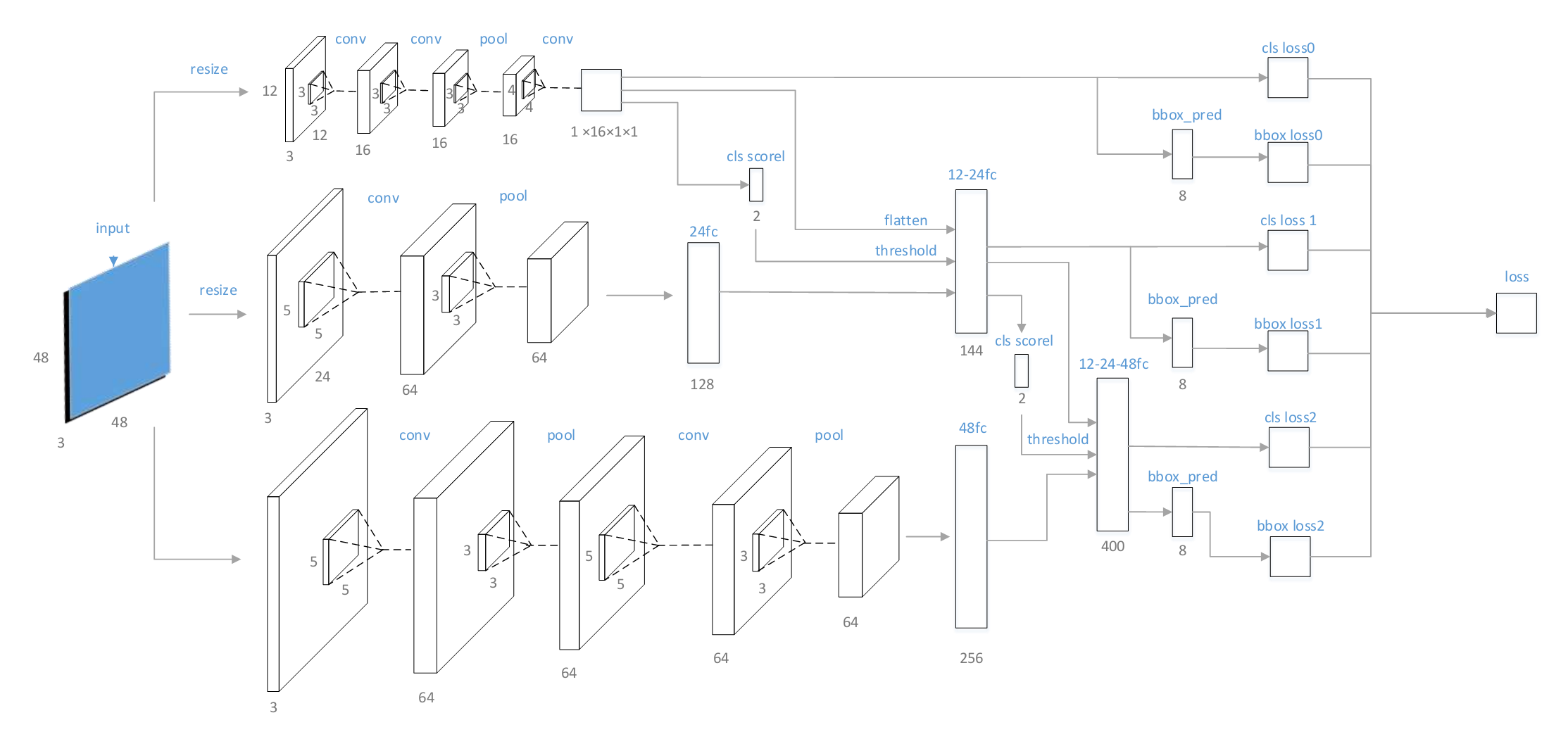
Facecraft
级联网络的进一步优化,做到了end2end训练,但是貌似效果不如MTCNN不过端到端训练应该是个趋势,毕竟速度快。.整体框架如图,很明白的图,就是分三支路,之后分别预测同时和下一支路特征进行融合。还提到了和Fastrcnn进行联合训练?没仔细看是如何提出的。。。
loss部分
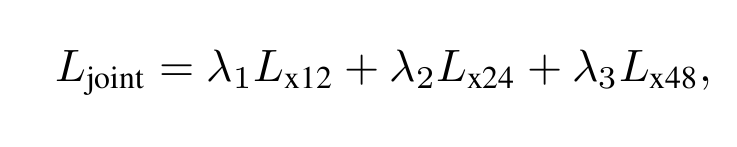
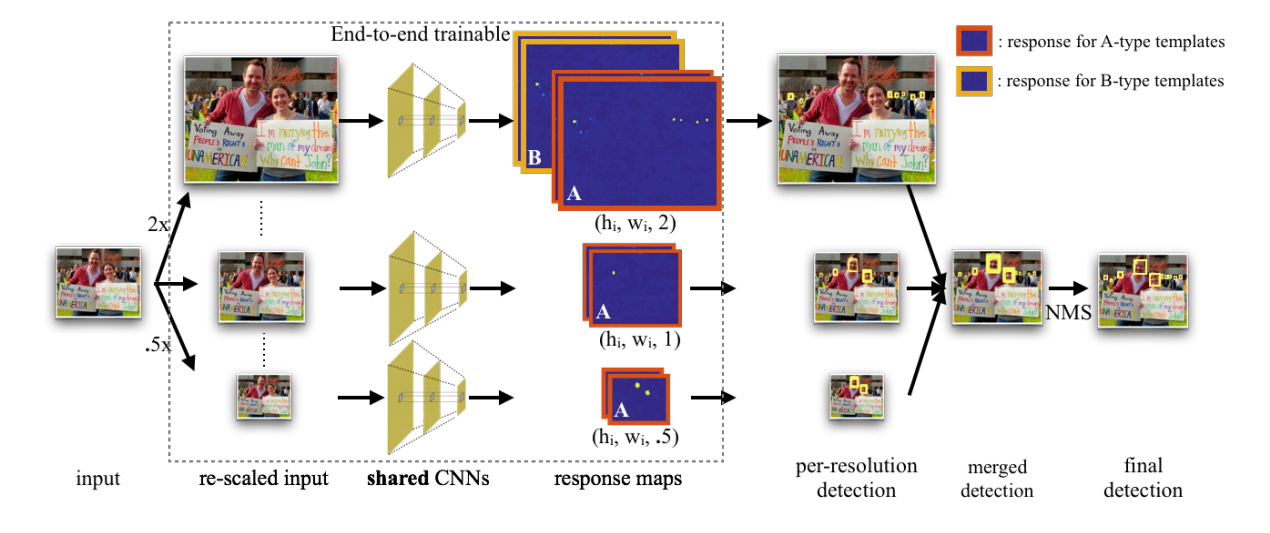
Finding tiny face
这个不是级联网络,更像目标检测中One-Stage方法做得一种优化,明显针对小目标的。如图,有几种训练方式,可以直接看翻译。
1. 模板固定,即人脸大小固定,输入不同resize后的图像。
2. 图像固定,输入不同大小的人脸
3.前两种的结合,改变人脸和图像
因为同一副图像中多个不同人脸,大小也不一样,resize的意义在于检测多尺度信息,尤其是小目标。这个模板是如何取得?不是特别清楚。模板就很像目标检测的anchor结构了。估计也是通过聚类来得到的一种先验统计
4,5. 在3的基础上增加一些上下文信息,有助于分类识别。文中叫context.

下图为网络架构不同大小,不同大小图片和不同size的人脸模板
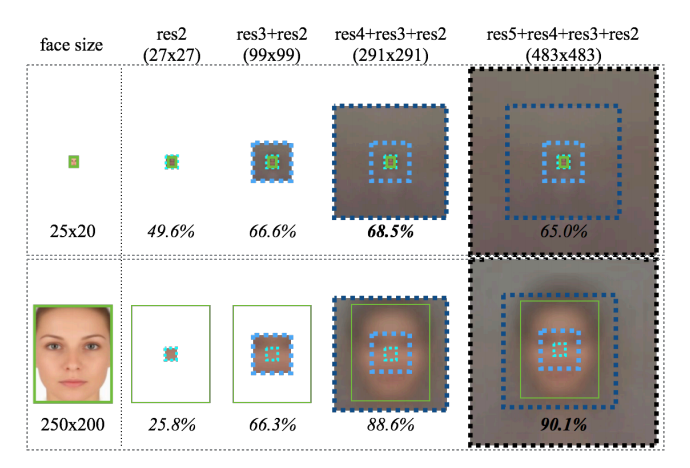
还对比了一组加入上下文信息后的结果,融入不同层feature map有助于小人脸的识别:
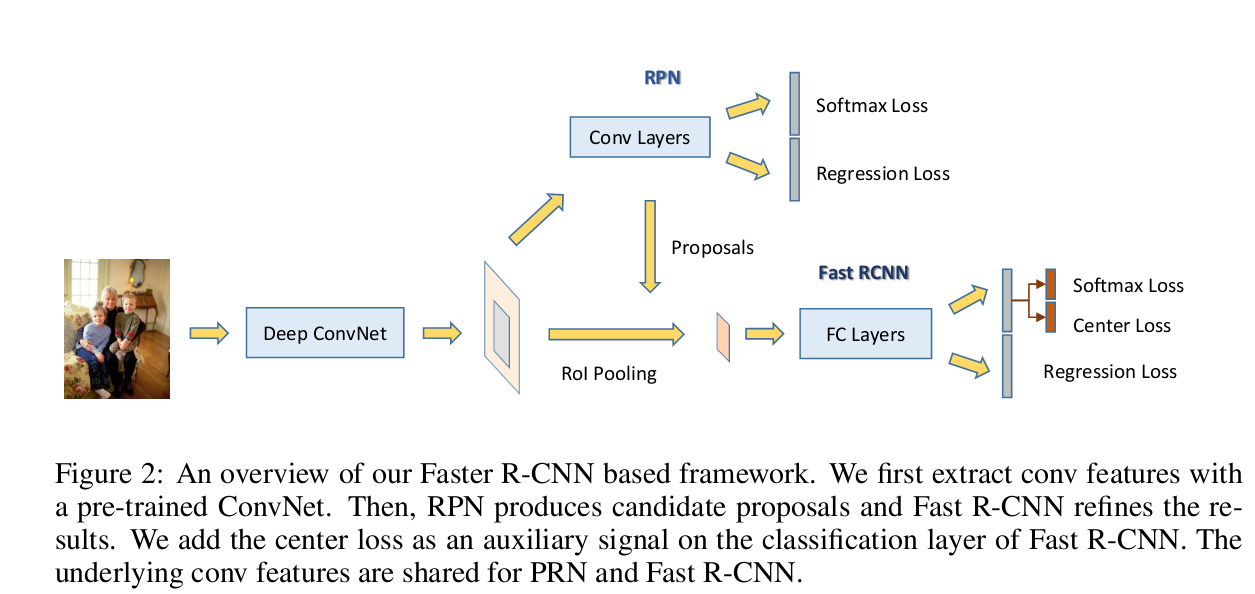
Face-RCNN
对Faster-RCNN做得一个优化,加入center loss,多尺度训练,还有对正负样本的限制。。没仔细看,因为一看到和Frcnn像就没看下去了。。
central loss更多用于人脸识别。就是不同人脸通过网络形成向量,对比不同向量间差异能更好识别人脸。
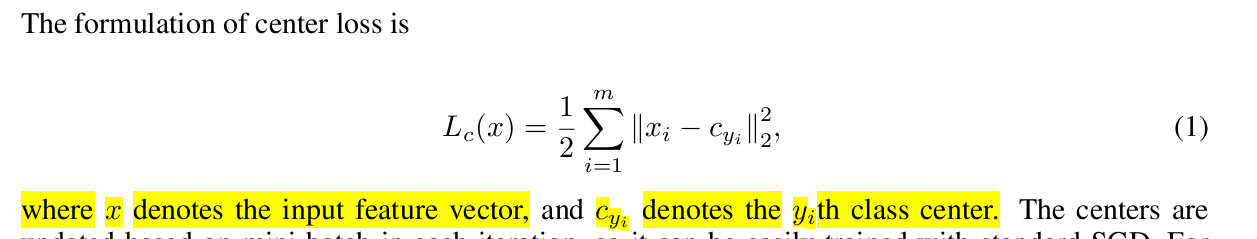
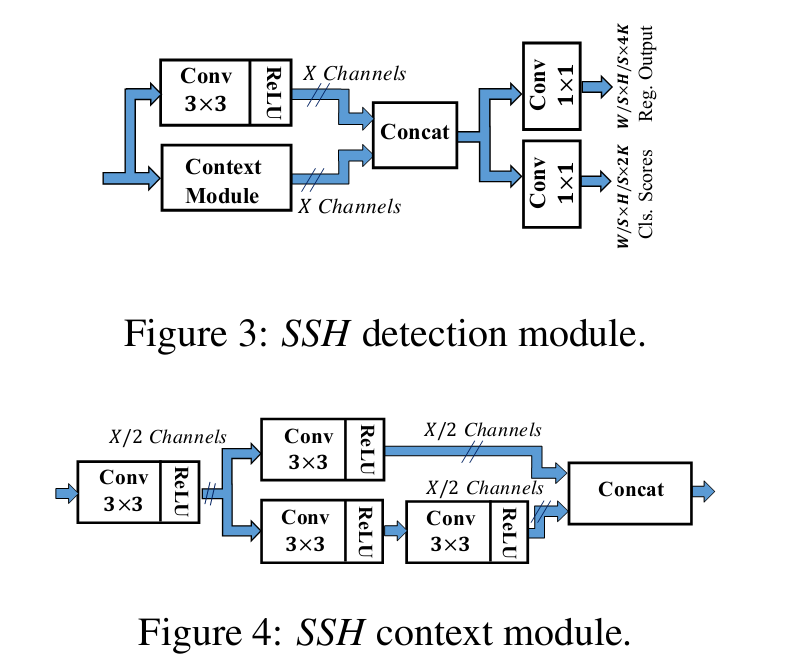
SSH
基于SSD的,对传统的人脸检测改进就是不再resize输入图片,而是由不同的卷积,造成不同的感受野,以此区分大,中,小脸。还要产生K个anchor结构
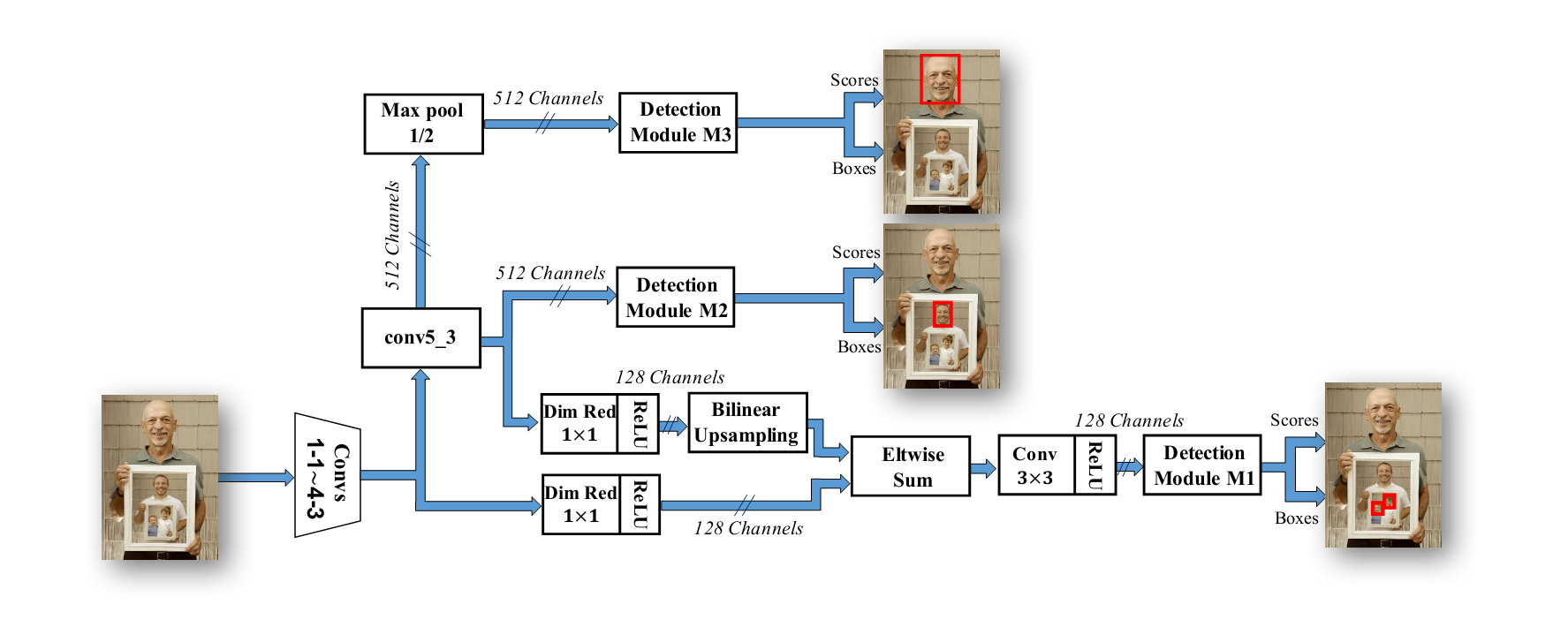
其中MA,M2,M3模块就是不同的感受野模块,通过不同大小的卷积形成的。