一、
一、
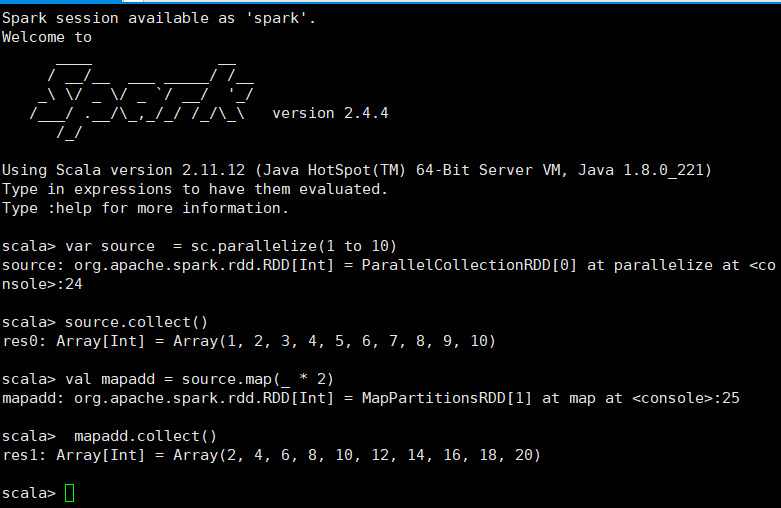
说明:返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成
scala> var source = sc.parallelize(1 to 10) source: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[8] at parallelize at <console>:24 scala> source.collect() res7: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10) scala> val mapadd = source.map(_ * 2) mapadd: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[9] at map at <console>:26 scala> mapadd.collect() res8: Array[Int] = Array(2, 4, 6, 8, 10, 12, 14, 16, 18, 20)
二、
将每一个分区形成一个数组,形成新的RDD类型时RDD[Array[T]]
scala> val rdd = sc.parallelize(1 to 16,4) rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[65] at parallelize at <console>:24 scala> rdd.glom().collect() res25: Array[Array[Int]] = Array(Array(1, 2, 3, 4), Array(5, 6, 7, 8), Array(9, 10, 11, 12), Array(13, 14, 15, 16))

三、
返回一个新的RDD,该RDD由经过func函数计算后返回值为true的输入元素组成
scala> var sourceFilter = sc.parallelize(Array("xiaoming","xiaojiang","xiaohe","dazhi"))
sourceFilter: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[10] at parallelize at <console>:24
scala> val filter = sourceFilter.filter(_.contains("xiao"))
filter: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[11] at filter at <console>:26
scala> sourceFilter.collect()
res9: Array[String] = Array(xiaoming, xiaojiang, xiaohe, dazhi)
scala> filter.collect()
res10: Array[String] = Array(xiaoming, xiaojiang, xiaohe)

四、
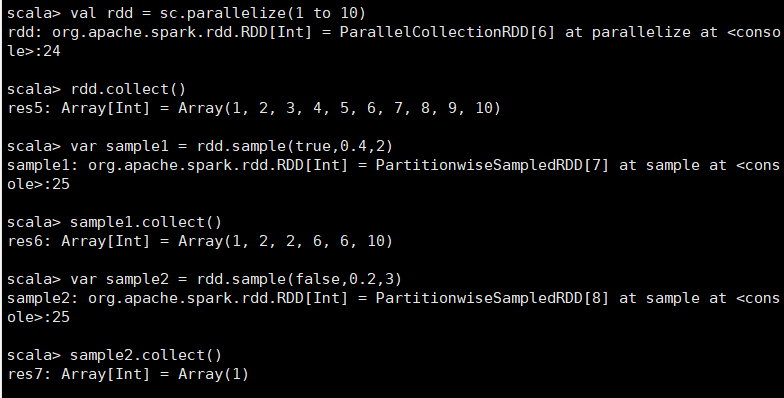
以指定的随机种子随机抽样出数量为fraction的数据,withReplacement表示是抽出的数据是否放回,true为有放回的抽样,false为无放回的抽样,
seed用于指定随机数生成器种子。例子从RDD中随机且有放回的抽出50%的数据,随机种子值为3(即可能以1 2 3的其中一个起始值)
scala> val rdd = sc.parallelize(1 to 10) rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[20] at parallelize at <console>:24 scala> rdd.collect() res15: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10) scala> var sample1 = rdd.sample(true,0.4,2) sample1: org.apache.spark.rdd.RDD[Int] = PartitionwiseSampledRDD[21] at sample at <console>:26 scala> sample1.collect() res16: Array[Int] = Array(1, 2, 2, 7, 7, 8, 9) scala> var sample2 = rdd.sample(false,0.2,3) sample2: org.apache.spark.rdd.RDD[Int] = PartitionwiseSampledRDD[22] at sample at <console>:26 scala> sample2.collect() res17: Array[Int] = Array(1, 9)
五、
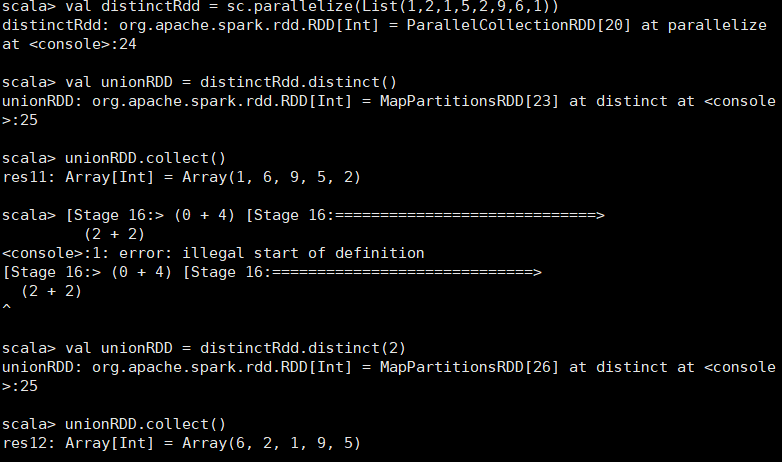
对源RDD进行去重后返回一个新的RDD. 默认情况下,只有8个并行任务来操作,但是可以传入一个可选的numTasks参数改变它。
scala> val distinctRdd = sc.parallelize(List(1,2,1,5,2,9,6,1)) distinctRdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[34] at parallelize at <console>:24 scala> val unionRDD = distinctRdd.distinct() unionRDD: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[37] at distinct at <console>:26 scala> unionRDD.collect() [Stage 16:> (0 + 4) [Stage 16:=============================> (2 + 2) res20: Array[Int] = Array(1, 9, 5, 6, 2) scala> val unionRDD = distinctRdd.distinct(2) unionRDD: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[40] at distinct at <console>:26 scala> unionRDD.collect() res21: Array[Int] = Array(6, 2, 1, 9, 5)
六、
对RDD进行分区操作,如果原有的partionRDD和现有的partionRDD是一致的话就不进行分区, 否则会生成ShuffleRDD。
scala> val rdd = sc.parallelize(Array((1,"aaa"),(2,"bbb"),(3,"ccc"),(4,"ddd")),4) rdd: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[44] at parallelize at <console>:24 scala> rdd.partitions.size res24: Int = 4 scala> var rdd2 = rdd.partitionBy(new org.apache.spark.HashPartitioner(2)) rdd2: org.apache.spark.rdd.RDD[(Int, String)] = ShuffledRDD[45] at partitionBy at <console>:26 scala> rdd2.partitions.size res25: Int = 2

七、
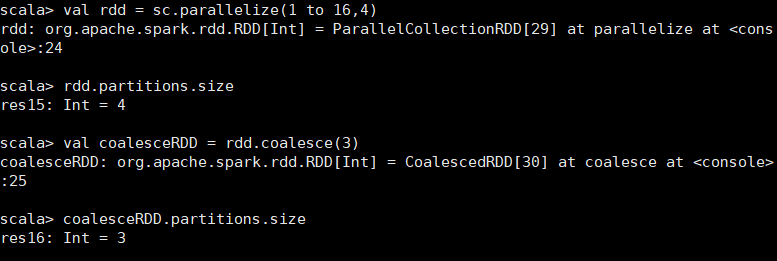
与repartition的区别: repartition(numPartitions:Int):RDD[T]和coalesce(numPartitions:Int,shuffle:Boolean=false):RDD[T] repartition只是coalesce接口中shuffle为true的实现. 缩减分区数,用于大数据集过滤后,提高小数据集的执行效率。
scala> val rdd = sc.parallelize(1 to 16,4) rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[54] at parallelize at <console>:24 scala> rdd.partitions.size res20: Int = 4 scala> val coalesceRDD = rdd.coalesce(3) coalesceRDD: org.apache.spark.rdd.RDD[Int] = CoalescedRDD[55] at coalesce at <console>:26 scala> coalesceRDD.partitions.size res21: Int = 3
八、
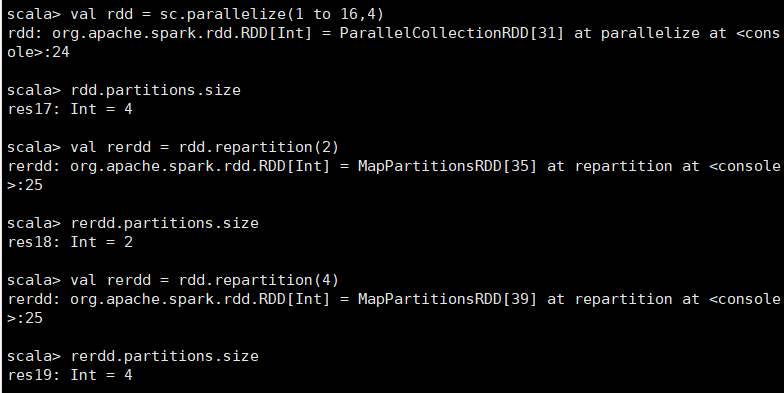
根据分区数,从新通过网络随机洗牌所有数据。 scala> val rdd = sc.parallelize(1 to 16,4) rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[56] at parallelize at <console>:24 scala> rdd.partitions.size res22: Int = 4 scala> val rerdd = rdd.repartition(2) rerdd: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[60] at repartition at <console>:26 scala> rerdd.partitions.size res23: Int = 2 scala> val rerdd = rdd.repartition(4) rerdd: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[64] at repartition at <console>:26 scala> rerdd.partitions.size res24: Int = 4
九、
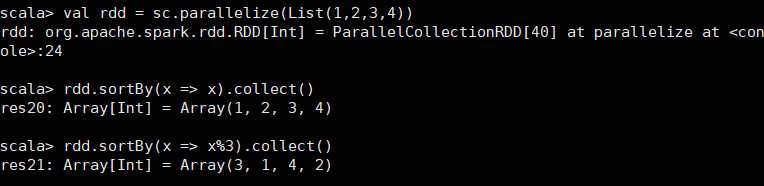
用func先对数据进行处理,按照处理后的数据比较结果排序。 scala> val rdd = sc.parallelize(List(1,2,3,4)) rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[21] at parallelize at <console>:24 scala> rdd.sortBy(x => x).collect() res11: Array[Int] = Array(1, 2, 3, 4) scala> rdd.sortBy(x => x%3).collect() res12: Array[Int] = Array(3, 4, 1, 2)
对源RDD和参数RDD求并集后返回一个新的RDD 不去重 scala> val rdd1 = sc.parallelize(1 to 5) rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[23] at parallelize at <console>:24 scala> val rdd2 = sc.parallelize(5 to 10) rdd2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[24] at parallelize at <console>:24 scala> val rdd3 = rdd1.union(rdd2) rdd3: org.apache.spark.rdd.RDD[Int] = UnionRDD[25] at union at <console>:28 scala> rdd3.collect() res18: Array[Int] = Array(1, 2, 3, 4, 5, 5, 6, 7, 8, 9, 10)

十一、
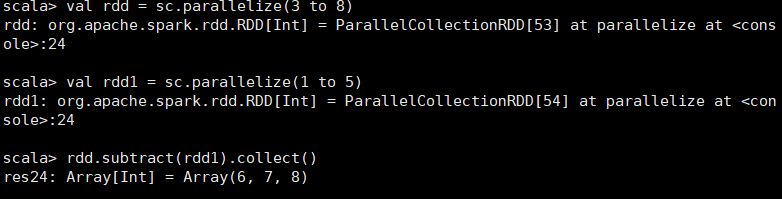
计算差的一种函数,去除两个RDD中相同的元素,不同的RDD将保留下来 scala> val rdd = sc.parallelize(3 to 8) rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[70] at parallelize at <console>:24 scala> val rdd1 = sc.parallelize(1 to 5) rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[71] at parallelize at <console>:24 scala> rdd.subtract(rdd1).collect() res27: Array[Int] = Array(8, 6, 7)
十二、
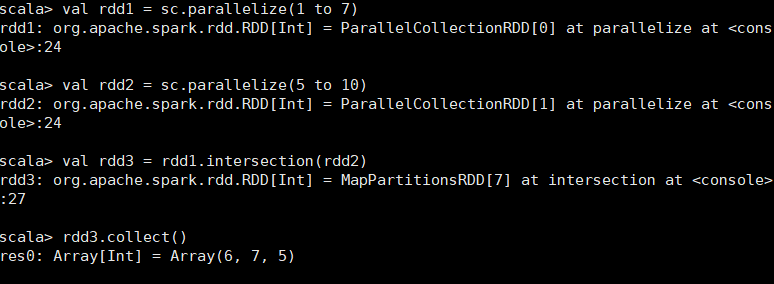
对源RDD和参数RDD求交集后返回一个新的RDD scala> val rdd1 = sc.parallelize(1 to 7) rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[26] at parallelize at <console>:24 scala> val rdd2 = sc.parallelize(5 to 10) rdd2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[27] at parallelize at <console>:24 scala> val rdd3 = rdd1.intersection(rdd2) rdd3: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[33] at intersection at <console>:28 scala> rdd3.collect() res19: Array[Int] = Array(5, 6, 7)
十三、
笛卡尔积 scala> val rdd1 = sc.parallelize(1 to 3) rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[47] at parallelize at <console>:24 scala> val rdd2 = sc.parallelize(2 to 5) rdd2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[48] at parallelize at <console>:24 scala> rdd1.cartesian(rdd2).collect() res17: Array[(Int, Int)] = Array((1,2), (1,3), (1,4), (1,5), (2,2), (2,3), (2,4), (2,5), (3,2), (3,3), (3,4), (3,5))

十四、
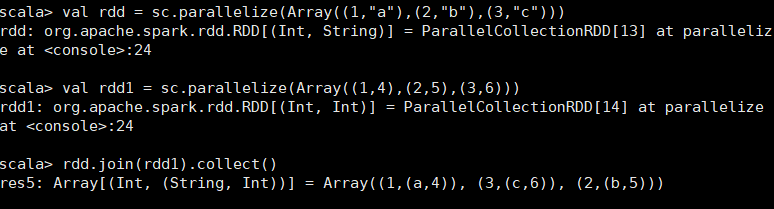
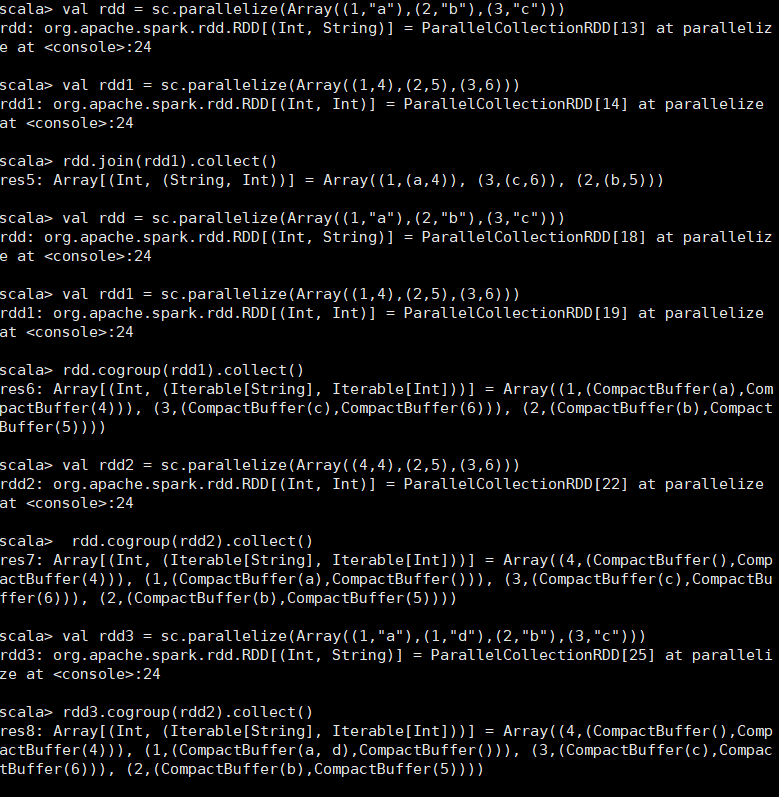
在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD scala> val rdd = sc.parallelize(Array((1,"a"),(2,"b"),(3,"c"))) rdd: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[32] at parallelize at <console>:24 scala> val rdd1 = sc.parallelize(Array((1,4),(2,5),(3,6))) rdd1: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[33] at parallelize at <console>:24 scala> rdd.join(rdd1).collect() res13: Array[(Int, (String, Int))] = Array((1,(a,4)), (2,(b,5)), (3,(c,6)))
十五、
在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable<V>,Iterable<W>))类型的RDD scala> val rdd = sc.parallelize(Array((1,"a"),(2,"b"),(3,"c"))) rdd: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[37] at parallelize at <console>:24 scala> val rdd1 = sc.parallelize(Array((1,4),(2,5),(3,6))) rdd1: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[38] at parallelize at <console>:24 scala> rdd.cogroup(rdd1).collect() res14: Array[(Int, (Iterable[String], Iterable[Int]))] = Array((1,(CompactBuffer(a),CompactBuffer(4))), (2,(CompactBuffer(b),CompactBuffer(5))), (3,(CompactBuffer(c),CompactBuffer(6)))) scala> val rdd2 = sc.parallelize(Array((4,4),(2,5),(3,6))) rdd2: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[41] at parallelize at <console>:24 scala> rdd.cogroup(rdd2).collect() res15: Array[(Int, (Iterable[String], Iterable[Int]))] = Array((4,(CompactBuffer(),CompactBuffer(4))), (1,(CompactBuffer(a),CompactBuffer())), (2,(CompactBuffer(b),CompactBuffer(5))), (3,(CompactBuffer(c),CompactBuffer(6)))) scala> val rdd3 = sc.parallelize(Array((1,"a"),(1,"d"),(2,"b"),(3,"c"))) rdd3: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[44] at parallelize at <console>:24 scala> rdd3.cogroup(rdd2).collect() [Stage 36:>(0 + 0) res16: Array[(Int, (Iterable[String], Iterable[Int]))] = Array((4,(CompactBuffer(),CompactBuffer(4))), (1,(CompactBuffer(d, a),CompactBuffer())), (2,(CompactBuffer(b),CompactBuffer(5))), (3,(CompactBuffer(c),CompactBuffer(6))))
十六、
在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,reduce任务的个数可以通过第二个可选的参数来设置。 scala> val rdd = sc.parallelize(List(("female",1),("male",5),("female",5),("male",2))) rdd: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[46] at parallelize at <console>:24 scala> val reduce = rdd.reduceByKey((x,y) => x+y) reduce: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[47] at reduceByKey at <console>:26 scala> reduce.collect() res29: Array[(String, Int)] = Array((female,6), (male,7))

十七、
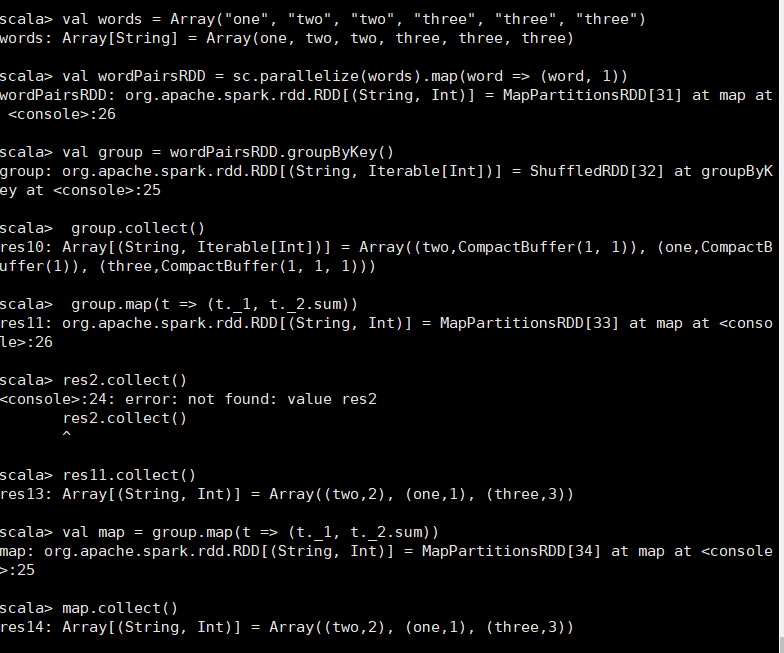
groupByKey也是对每个key进行操作,但只生成一个sequence scala> val words = Array("one", "two", "two", "three", "three", "three") words: Array[String] = Array(one, two, two, three, three, three) scala> val wordPairsRDD = sc.parallelize(words).map(word => (word, 1)) wordPairsRDD: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[4] at map at <console>:26 scala> val group = wordPairsRDD.groupByKey() group: org.apache.spark.rdd.RDD[(String, Iterable[Int])] = ShuffledRDD[5] at groupByKey at <console>:28 scala> group.collect() res1: Array[(String, Iterable[Int])] = Array((two,CompactBuffer(1, 1)), (one,CompactBuffer(1)), (three,CompactBuffer(1, 1, 1))) scala> group.map(t => (t._1, t._2.sum)) res2: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[6] at map at <console>:31 scala> res2.collect() res3: Array[(String, Int)] = Array((two,2), (one,1), (three,3)) scala> val map = group.map(t => (t._1, t._2.sum)) map: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[7] at map at <console>:30 scala> map.collect() res4: Array[(String, Int)] = Array((two,2), (one,1), (three,3))
十八、
createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C) 对相同K,把V合并成一个集合。 createCombiner: combineByKey() 会遍历分区中的所有元素,因此每个元素的键要么还没有遇到过,要么就 和之前的某个元素的键相同。如果这是一个新的元素,combineByKey()
会使用一个叫作 createCombiner() 的函数来创建那个键对应的累加器的初始值 mergeValue: 如果这是一个在处理当前分区之前已经遇到的键, 它会使用 mergeValue() 方法将该键的累加器对应的当前值与这个新的值进行合并 mergeCombiners: 由于每个分区都是独立处理的, 因此对于同一个键可以有多个累加器。如果有两个或者更多的分区都有对应同一个键的累加器, 就需要使用用户提供的 mergeCombiners()
方法将各个分区的结果进行合并。 scala> val scores = Array(("Fred", 88), ("Fred", 95), ("Fred", 91), ("Wilma", 93), ("Wilma", 95), ("Wilma", 98)) scores: Array[(String, Int)] = Array((Fred,88), (Fred,95), (Fred,91), (Wilma,93), (Wilma,95), (Wilma,98)) scala> val input = sc.parallelize(scores) input: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[52] at parallelize at <console>:26 scala> val combine = input.combineByKey( | (v)=>(v,1), | (acc:(Int,Int),v)=>(acc._1+v,acc._2+1), | (acc1:(Int,Int),acc2:(Int,Int))=>(acc1._1+acc2._1,acc1._2+acc2._2)) combine: org.apache.spark.rdd.RDD[(String, (Int, Int))] = ShuffledRDD[53] at combineByKey at <console>:28 scala> val result = combine.map{ | case (key,value) => (key,value._1/value._2.toDouble)} result: org.apache.spark.rdd.RDD[(String, Double)] = MapPartitionsRDD[54] at map at <console>:30 scala> result.collect() res33: Array[(String, Double)] = Array((Wilma,95.33333333333333), (Fred,91.33333333333333))

十九、
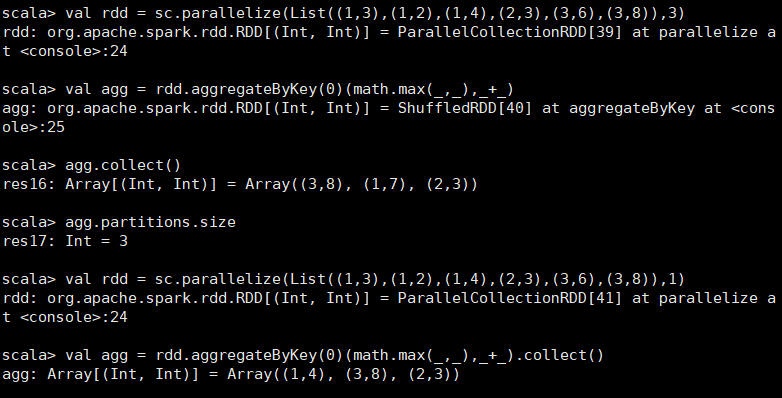
(zeroValue:U,[partitioner: Partitioner]) (seqOp: (U, V) => U,combOp: (U, U) => U) 在kv对的RDD中,,按key将value进行分组合并,合并时,将每个value和初始值作为seq函数的参数,进行计算,返回的结果作为一个新的kv对,然后再将结果按照key进行合并,最后将每个分组的value传递给combine函数进行计算(先将前两个value进行计算,将返回结果和下一个value传给combine函数,以此类推),将key与计算结果作为一个新的kv对输出。 seqOp函数用于在每一个分区中用初始值逐步迭代value,combOp函数用于合并每个分区中的结果。 scala> val rdd = sc.parallelize(List((1,3),(1,2),(1,4),(2,3),(3,6),(3,8)),3) rdd: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[12] at parallelize at <console>:24 scala> val agg = rdd.aggregateByKey(0)(math.max(_,_),_+_) agg: org.apache.spark.rdd.RDD[(Int, Int)] = ShuffledRDD[13] at aggregateByKey at <console>:26 scala> agg.collect() res7: Array[(Int, Int)] = Array((3,8), (1,7), (2,3)) scala> agg.partitions.size res8: Int = 3 scala> val rdd = sc.parallelize(List((1,3),(1,2),(1,4),(2,3),(3,6),(3,8)),1) rdd: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[10] at parallelize at <console>:24 scala> val agg = rdd.aggregateByKey(0)(math.max(_,_),_+_).collect() agg: Array[(Int, Int)] = Array((1,4), (3,8), (2,3))
二十、
(zeroValue: V)(func: (V, V) => V): RDD[(K, V)]
aggregateByKey的简化操作,seqop和combop相同 scala> val rdd = sc.parallelize(List((1,3),(1,2),(1,4),(2,3),(3,6),(3,8)),3) rdd: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[91] at parallelize at <console>:24 scala> val agg = rdd.foldByKey(0)(_+_) agg: org.apache.spark.rdd.RDD[(Int, Int)] = ShuffledRDD[92] at foldByKey at <console>:26 scala> agg.collect() res61: Array[(Int, Int)] = Array((3,14), (1,9), (2,3))

二十一、
在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD scala> val rdd = sc.parallelize(Array((3,"aa"),(6,"cc"),(2,"bb"),(1,"dd"))) rdd: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[14] at parallelize at <console>:24 scala> rdd.sortByKey(true).collect() res9: Array[(Int, String)] = Array((1,dd), (2,bb), (3,aa), (6,cc)) scala> rdd.sortByKey(false).collect() res10: Array[(Int, String)] = Array((6,cc), (3,aa), (2,bb), (1,dd))

二十二、
针对于(K,V)形式的类型只对V进行操作 scala> val rdd3 = sc.parallelize(Array((1,"a"),(1,"d"),(2,"b"),(3,"c"))) rdd3: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[67] at parallelize at <console>:24 scala> rdd3.mapValues(_+"|||").collect() res26: Array[(Int, String)] = Array((1,a|||), (1,d|||), (2,b|||), (3,c|||))

二十三、
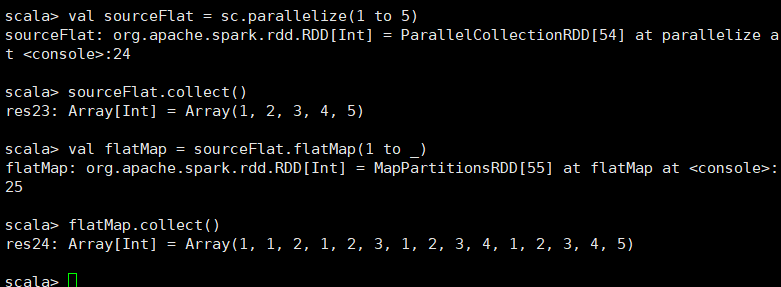
类似于map,但是每一个输入元素可以被映射为0或多个输出元素(所以func应该返回一个序列,而不是单一元素) scala> val sourceFlat = sc.parallelize(1 to 5) sourceFlat: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[12] at parallelize at <console>:24 scala> sourceFlat.collect() res11: Array[Int] = Array(1, 2, 3, 4, 5) scala> val flatMap = sourceFlat.flatMap(1 to _) flatMap: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[13] at flatMap at <console>:26 scala> flatMap.collect() res12: Array[Int] = Array(1, 1, 2, 1, 2, 3, 1, 2, 3, 4, 1, 2, 3, 4, 5)
二十四、
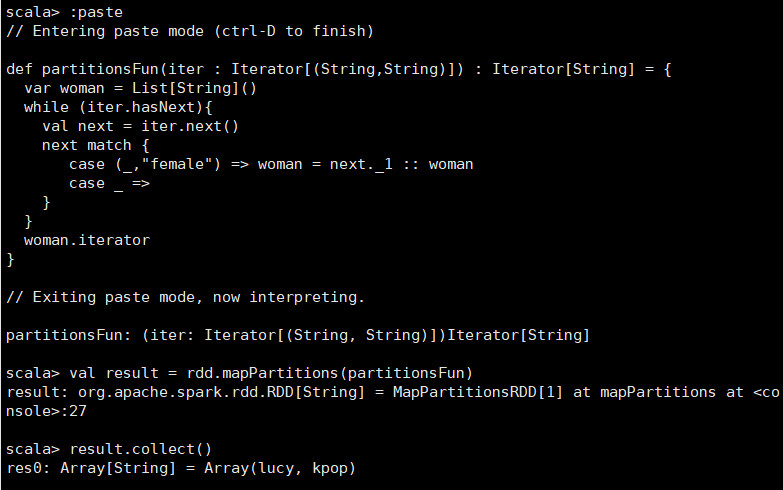
l类似于map,但独立地在RDD的每一个分片上运行,因此在类型为T的RDD上运行时,func的函数类型必须是Iterator[T] => Iterator[U]。假设有N个元素,有M个分区,那么map的函数的将被调用N次,而mapPartitions被调用M次,一个函数一次处理所有分区 scala> val rdd = sc.parallelize(List(("kpop","female"),("zorro","male"),("mobin","male"),("lucy","female"))) rdd: org.apache.spark.rdd.RDD[(String, String)] = ParallelCollectionRDD[16] at parallelize at <console>:24 scala> :paste // Entering paste mode (ctrl-D to finish) def partitionsFun(iter : Iterator[(String,String)]) : Iterator[String] = { var woman = List[String]() while (iter.hasNext){ val next = iter.next() next match { case (_,"female") => woman = next._1 :: woman case _ => } } woman.iterator } // Exiting paste mode, now interpreting. partitionsFun: (iter: Iterator[(String, String)])Iterator[String] scala> val result = rdd.mapPartitions(partitionsFun) result: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[17] at mapPartitions at <console>:28 scala> result.collect() res13: Array[String] = Array(kpop, lucy)
二十五、
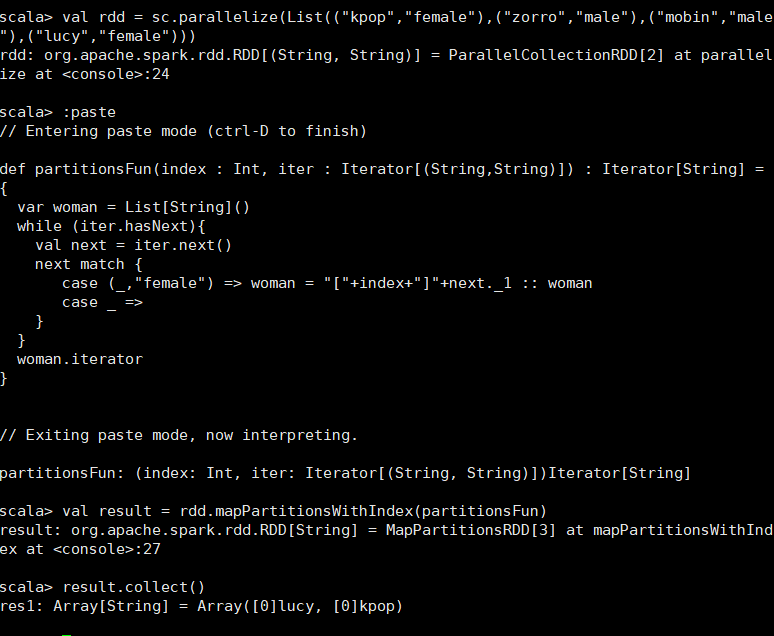
类似于mapPartitions,但func带有一个整数参数表示分片的索引值,因此在类型为T的RDD上运行时,func的函数类型必须是(Int, Interator[T]) => Iterator[U] scala> val rdd = sc.parallelize(List(("kpop","female"),("zorro","male"),("mobin","male"),("lucy","female"))) rdd: org.apache.spark.rdd.RDD[(String, String)] = ParallelCollectionRDD[18] at parallelize at <console>:24 scala> :paste // Entering paste mode (ctrl-D to finish) def partitionsFun(index : Int, iter : Iterator[(String,String)]) : Iterator[String] = { var woman = List[String]() while (iter.hasNext){ val next = iter.next() next match { case (_,"female") => woman = "["+index+"]"+next._1 :: woman case _ => } } woman.iterator } // Exiting paste mode, now interpreting. partitionsFun: (index: Int, iter: Iterator[(String, String)])Iterator[String] scala> val result = rdd.mapPartitionsWithIndex(partitionsFun) result: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[19] at mapPartitionsWithIndex at <console>:28 scala> result.collect() res14: Array[String] = Array([0]kpop, [3]lucy)
二十六、
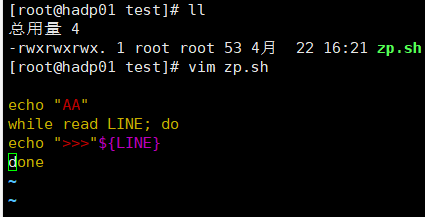
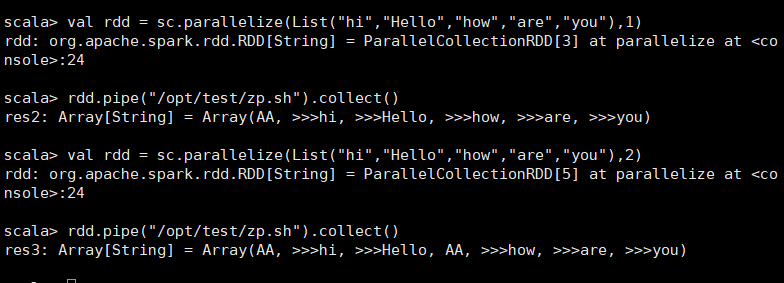
管道,对于每个分区,都执行一个perl或者shell脚本,返回输出的RDD Shell脚本 #!/bin/sh echo "AA" while read LINE; do echo ">>>"${LINE} done scala> val rdd = sc.parallelize(List("hi","Hello","how","are","you"),1) rdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[50] at parallelize at <console>:24 scala> rdd.pipe("/home/bigdata/pipe.sh").collect() res18: Array[String] = Array(AA, >>>hi, >>>Hello, >>>how, >>>are, >>>you) scala> val rdd = sc.parallelize(List("hi","Hello","how","are","you"),2) rdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[52] at parallelize at <console>:24 scala> rdd.pipe("/home/bigdata/pipe.sh").collect() res19: Array[String] = Array(AA, >>>hi, >>>Hello, AA, >>>how, >>>are, >>>you) pipe.sh: #!/bin/sh echo "AA" while read LINE; do echo ">>>"${LINE} done
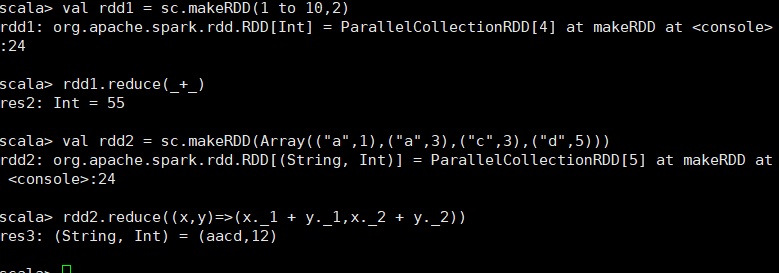
二、
通过func函数聚集RDD中的所有元素,这个功能必须是可交换且可并联的 scala> val rdd1 = sc.makeRDD(1 to 10,2) rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[85] at makeRDD at <console>:24 scala> rdd1.reduce(_+_) res50: Int = 55 scala> val rdd2 = sc.makeRDD(Array(("a",1),("a",3),("c",3),("d",5))) rdd2: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[86] at makeRDD at <console>:24 scala> rdd2.reduce((x,y)=>(x._1 + y._1,x._2 + y._2)) res51: (String, Int) = (adca,12)