BIO带来的挑战
BIO 就是我们常说的阻塞I/O , 不论磁盘I/O 还是网络/O ,数据在写入OutputStream 或者从 InutStream 读取数据时都有可能会阻塞,一旦有了阻塞,线程就会失去CPU 的使用权,这在大规模访问量和有性能要求的情况下是不能被接受的,虽然网络I/O 有一些解决办法(比如一个客户端对应一个线程,线程池等),但是在一些使用场景下任然是无法解决的,比如需要大量HTTP 长连接的情况,像淘宝的Web旺旺,服务端就需要保持几百万甚至更多的HTTP 连接,但又并不是每时每刻连接都在传输数据,这种情况下不可能同时创建这么多的线程来保持连接。就算能创建这么多的线程,如果我们想给某些客户端更高的服务优先级,就很难通过设计线程的优先级来完成。如果每个客户端的请求在服务端需要访问一些竞争资源,客户端如果都在不同的线程中,就需要同步,要实现这种大量的同步操作,远远比单线程复杂的多,所以,就有了新的I/O 操作方式。
NIO的工作机制
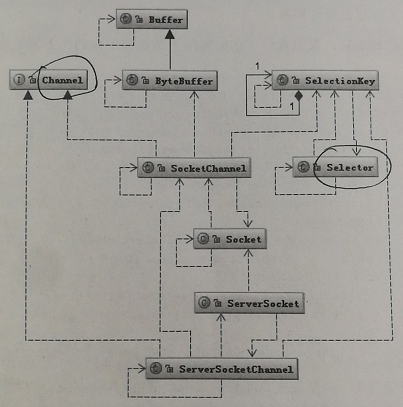
NIO的相关类图
Channel 和Selector 是两个关键类。也是NIO的两个核心概念。这里的Channel 要比Socket 更加具体,Selector 作为整个的调度系统,负责监控Channel的状态,即可以轮询每个Channel的状态。
Buffer类, 也比Stream 更具体,如果说Channel 是汽车的话,那Buffer就是汽车上的座位,是相对Channel 更具体的概念,如果说Stream只能代表一个座位,至于是什么车,什么座位,都不清楚,只能自己想像。在上车之前,自己并不清楚车上是否还有座位,也不知道是什么车。因为我们自己不能选择, 所有信息都封装在了Socket 里面。对自己是透明的。
NIO 通过引入Channel ,Buffe和Selector 就是把这些信息具体化,让我们自己能够控制。比如在调用Writ() 往SendQ()中 写数据时,当一次性写入的数据超过SendQ()的长度,这就是需要按照SendQ() 的长度进行分割。这个过程中需要将用户空间数据和内核地址空间进行切换。这个切换不是我们能够控制的, 但是可以在Buffer中,我们可以控制Buffer的容量,是否扩容,以及如何扩容。
public void selector() throws IOExcepton{
ByteBuffer buffer = ByteBuffer.allocate(1024);
Selector selector = Selector.open();
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.configureBlocking(false);// 设置为非阻塞方式。
ssc.socket().bind(new InetSocketAddress(8080));
ssc.register(selector,SelectionKey.OP_ACCEPT);//注册监听的事件
while(true){
Set seletedKeys = selector.selectedKeys();// 取得所有的Key集合
Iterator it = selectedKeys.iterator();
while(it.hasNext()){
SelectionKey key = (SelectionKey)it.next();
if(key.readyOps()&SelectionKey.OP_ACCEPT) == SelectionKey.OP_ACCEPT{
ServerSocketChannel ssChannel = (ServerSocketChannel)key.channel();
SocketChannel sc = ssChannel.accpet();//接受到服务端的请求
sc.configureBlocking(false);
sc.register(selector,SelectionKey.OP_READ);
it.remove();
}
else if ((key.readyOps() & SelectionKye.OP_READ) == SelectionKey.OP_READ){
SocketChannel sc = (SocketChannel) key.channel();
while(true) {
buffer.clear();
int n = sc.read(buffer);// 读取数据
if (n<= 0 ){
break;
}
buffer.filp();
}
it.remove();
}
}
}
}
上面这段代码实现了, 调用Selector的静态工厂创建一个选择器,创建一个服务端的Channel, 绑定到一个Socket对象,并把这个通信信道注册到选择器上。把这个通信信道设置为非阻塞模式,然后就可以调用Selector 的selectedKeys 方法来检查已经注册在这个选择器上的所有通信信道是否有需要的事件发生,如果有的话,就会返回所有的SelectionKey , 通过这个对象的Channle 方法就可以取得这个通信信道对象,从而读取通信的数据,这里读取的数据是Buffer ,这个Buffer 就是我们可以控制的缓冲器。
上面将Server端的监听连接请求的事件和处理请求的事件放在一个线程中,但是在事件的应用中,我们通常将他们放在两个线程中去:
一个线程专门负责监听客户端的连接请求。而且是以阻塞的方式进行的.
另外一个线程专门负责处理请求。这个专门处理请求的线程才会真正采用NIO 的方式,比如Web服务器Tomcat 和Jetty 都是使用这种方式。
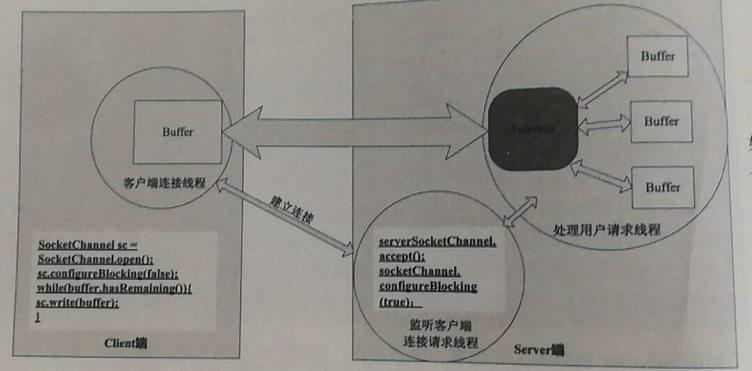
基于NIO 的Socket请求的处理过程
Selector 可以同时监听一组通信信道(Channel) 上的I/O 状态,前提是这个Selector 已经注册到这些通信信道中了。选择器Selector 可以调用select ()方法检查已经注册的通信信道上的I/O 是否已经准备好,如果没有至少一个信道I/O 状态有变化,那么select 方法会阻塞等待或在超时时间后返回0。如果有多个信道有数据,那么将会把这些数据分配到对应的Buffer 中。 关键在于: 有一个线程来处理所有连接的数据交互,每个连接的数据交互都不是阻塞方式,所以可以同时处理大量的连接请求。
Buffer的工作方式
Selector检测到通信信道I/O 有数据传输时,通过select() 取得SelectChannel,将数据读取或写入到Buffer缓冲区,那么如何接受和写出数据呢?
可以简单的把Buffer理解为一组基本数据类型元素列表,通过几个变量来保存这个数据的当前位置状态。 也就是4个索引。
| 索引 | 说明 |
| capacity | 缓冲区数组的长度 |
| position | 下一个要操作数据元素元素的位置 |
| limit | 缓冲区数组中不可操作的下一个元素的位置,limit<=capacity |
| mark | 用于记录当前position的前一个位置或者默认是 0 |
实际操作时又是这样的:
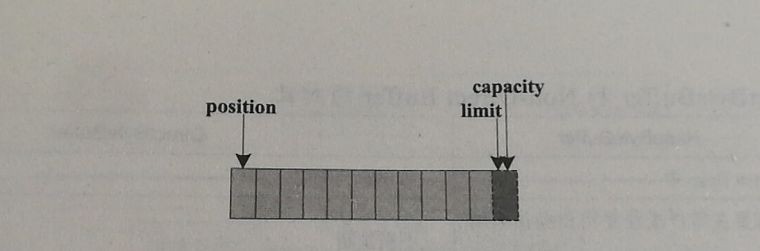
关系图
通过ByteBuffer.allocate(11) 方法创建一个11B的数组缓冲区,初始状态如上图,position 位置为0 ,capacity 和limit 默认都是数组长度,当写入5个字节时,变化如下:
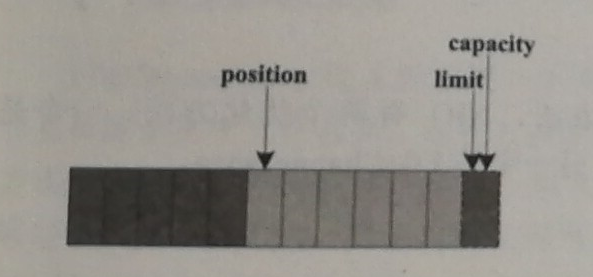
位置变化图
这个时候需要将缓冲区的5个字节,写入到Channel 信道,所以调用byteBuffer.flip()方法,数组的状态变化如下:
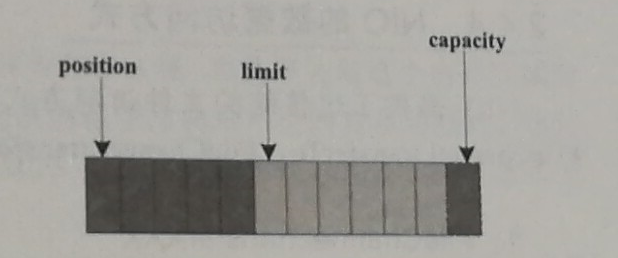
状态变化图
此时底层操作系统就而可以从缓冲区中正确读取这五个字节数据并发出去了。在下一次写数据之前,我们再调一下clear()方法,缓冲区的索引状态就会又回到初始位置。 当调用mark() 方法时,它将记录当前position的前一个位置,当我们调用reset时,position将恢复mark记录下来的值。
通过Channel 获取的I/O 数据首先要经过操作系统的Socket 缓冲区,再将数据复制到Buffer 中,这个操作系统缓冲区就是底层TCP所关联的RecvQ 或者SendQ 队列,从操作系统缓冲区到用户缓冲区复制数据比较消耗性能,所以Buffer 提供了另外一种直接操作操作系统缓冲区的方式,即,ByteBuffer.allocateDirector(size), 这个方法返回的DirectByteBuffer 就是与底层存储空间关联的缓冲区,它通过Native 代码操作非JVM 堆的内存空间,每次创建或者释放的时候都要调用一次System.gc()。 有一点需要注意, 在使用DirectByteBuffer 的时候可能会引起JVM 内存泄露的问题。
DirecByteBuffer 和Non-Direct Buffer(HeapByteBuffer) 的对比:
| HeapByteBuffer |
DirectByteBuffer |
|
| 存储位置 | Java Heap 中 | Native 内存中 |
| I/O | 需要在用户地址空间和操作系统内核地址空间复制数据 | 不需要复制 |
| 内存管理 | Java GC 回收,创建和回收开销少 |
通过调用System.gc() 要释放掉Java 对象引用的DirectByteBuffer 内存 空间,如果Java 对象时间持有引用可能会导致Native内存泄露,创建和回收开销大 |
| 适用场景 | 并发连接数 少于1000, I/O 操作较少时比较合适 | 数据量比较大,生命周期比较长的时候合适 |
NIO的数据访方式
NIO 有两个优化方法 :
- FileChannel.transferTO, FileChannel.transferFrom
- FileChannel.map
FileChannel.transferXXX
相比传统的文件访问方式,这种方式可以减少数据从内核到用户空间的复制,数据直接在内核空间中移动,在Liunx 中使用sendfile系统调用。
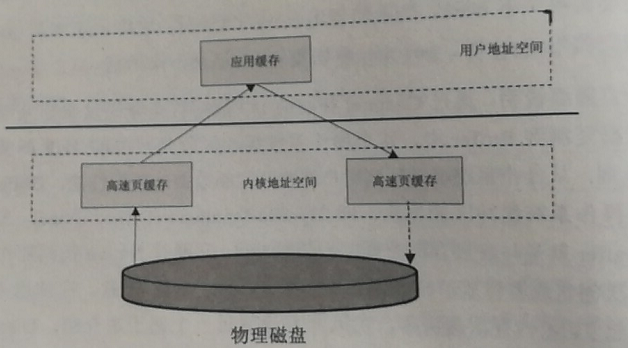
传统的数据访问方式
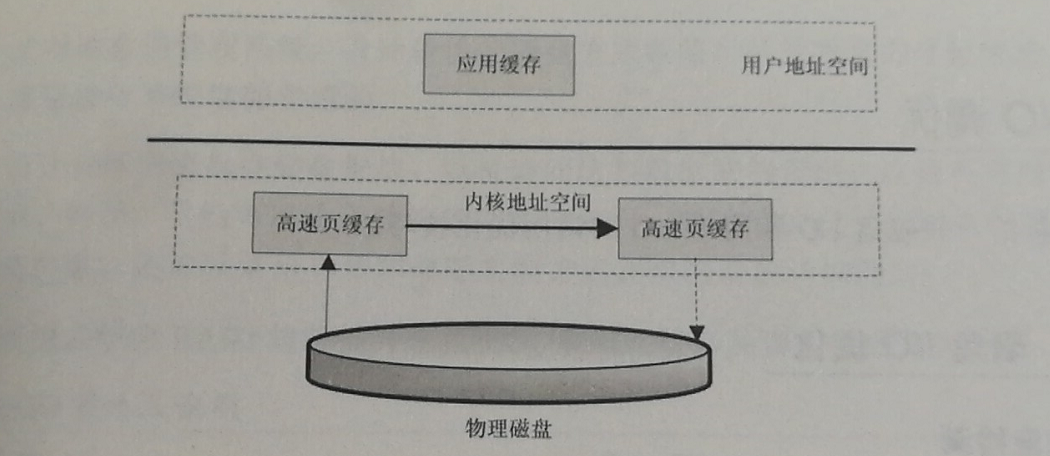
FileChannel.transferXXX 的访问方式
FileChannel.map
这种方式将文件按照一定大小块映射为内存区域,当程序访问这个内存区域时,将直接操作这个文件数据,这种方式省去了数据从内核空间向用户空间复制的损耗。这种方式适合对大文件的只读性操作,如大文件的MD5校验,但是这种方式是和操作系统相关的底层I/O 实现相关的。
public static void map (String[] args){
int BUFFER_SIZE = 1024 ;
String filename = "test .db"
long fileLength = new File(filename).length();
int bufferCount = 1 + (int)(fileLength/BUFFER_SIZE);
MappedByteBuffer[] buffers = new MappedByteBuffer[ bufferCount ];
long remaining = fileLength;
for (int i = 0 ;i<bufferCount ;i++){
RandomAccessFile file;
try{
file = new RandomAccessFile (filename,"r ");
buffers[i] = file.getChannel().map(fileChannel.MapMode.READ_ONLY,i * BUFFER_SIZE, (int)Math.min(remaining,BUFFER_SIZE));
} catch(Exception e){
e.prinStackTrace();
}
remaining -=BUFFER_SIZE;
}
}