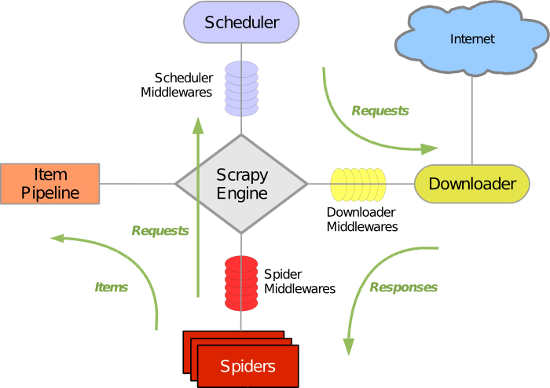
1,spider打开某网页,获取到一个或者多个request,经由scrapy engine传送给调度器scheduler
request特别多并且速度特别快会在scheduler形成请求队列queue,由scheduler安排执行
2,schelduler会按照一定的次序取出请求,经由引擎, 下载器中间键,发送给下载器dowmloader
这里的下载器中间键是设定在请求执行前,因此可以设定代理,请求头,cookie等
3,下载下来的网页数据再次经过下载器中间键,经过引擎,经过爬虫中间键传送给爬虫spiders
这里的下载器中间键是设定在请求执行后,因此可以修改请求的结果
这里的爬虫中间键是设定在数据或者请求到达爬虫之前,与下载器中间键有类似的功能
4,由爬虫spider对下载下来的数据进行解析,按照item设定的数据结构经由爬虫中间键,引擎发送给项目管道itempipeline
这里的项目管道itempipeline可以对数据进行进一步的清洗,存储等操作
这里爬虫极有可能从数据中解析到进一步的请求request,它会把请求经由引擎重新发送给调度器shelduler,调度器循环执行上述操作
5,项目管道itempipeline管理着最后的输出