通过info memory 观察到某个实例内存占用很高。
redis-cli --bigkeys 可以找到最大的key
找一个redis比较空闲的时间执行
redis-cli --bigkeys
影响比较大 可以 redis-cli --bigkeys -i 0.1 。 0.1为每100个key休息0.1秒
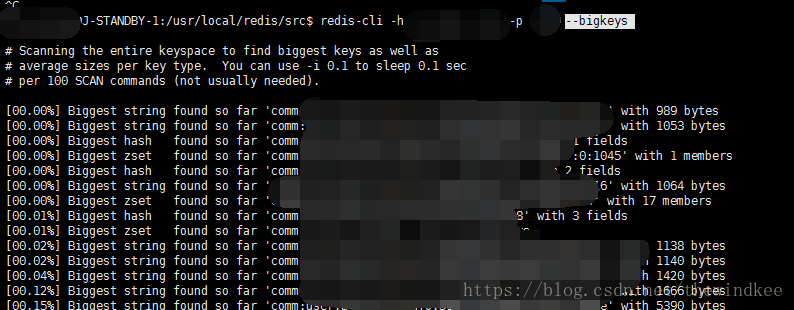
可以发现这个键包含的元素很多。
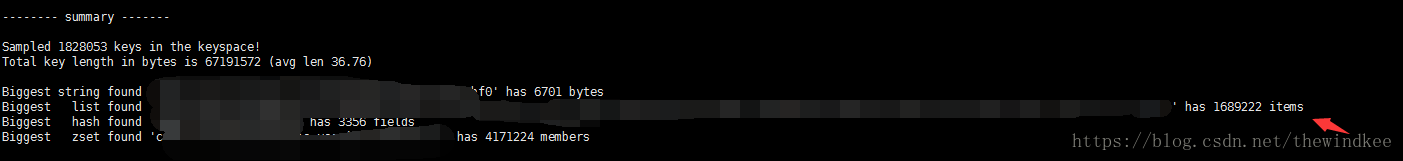
使用debug object 查看它的大小(不是实际大小。这个操作很耗时)
这里看到大概有1G

也可以单独查看空闲时间(get、ttl等操作会重置空闲时间)

分析这个1G的键是否应该存在,或者拆分成多个键,分布到不同实例。
一个扫描大键的脚本 , 利用debug object , 很耗时。脚本来自:https://gist.github.com/epicserve/5699837
#!/usr/bin/env bash
human_size() {
awk -v sum="$1" ' BEGIN {hum[1024^3]="Gb"; hum[1024^2]="Mb"; hum[1024]="Kb"; for (x=1024^3; x>=1024; x/=1024) { if (sum>=x) { printf "%.2f %s
",sum/x,hum[x]; break; } } if (sum<1024) printf "%sbyte",sum; } '
}
redis_cmd='redis-cli -h 192.168.0.190 -p 6390'
# get keys and sizes
for k in `$redis_cmd keys "*"`; do key_size_bytes=`$redis_cmd debug object $k | perl -wpe 's/^.+serializedlength:([d]+).+$/$1/g'`; size_key_list="$size_key_list$key_size_bytes $k
"; done
# sort the list
sorted_key_list=`echo -e "$size_key_list" | sort -n`
# print out the list with human readable sizes
echo -e "$sorted_key_list" | while read l; do
if [[ -n "$l" ]]; then
size=`echo $l | perl -wpe 's/^(d+).+/$1/g'`; hsize=`human_size "$size"`; key=`echo $l | perl -wpe 's/^d+(.+)/$1/g'`; printf "%-10s%s
" "$hsize" "$key";
fi
done