ReLeQ:一种自动强化学习的神经网络深度量化方法
ReLeQ:一种自动强化学习的神经网络深度量化方法
ReLeQ: An Automatic Reinforcement Learning Approach for Deep Quantization of Neural Networks
量化作为压缩的一种重要手段被广泛应用,而位宽和准确率的矛盾也始终存在。目前解决的方法有如CLIP-Q中的贝叶斯优化器,确定位宽。另一个问题是量化值的选取,在LQ-Net中采取了交替训练的方式。
如果将量化位宽的不同看作不同的决策,那么就可以利用强化学习的思路进行选择,ReLeQ就是其中的一种实现框架。不同层可能重要性不同,对准确率也有不同的敏感度。ReLeQ可以学习最终分类精度相对于每个层权重的量化级别的敏感度,从而确定每个层的位宽,同时保持分类精度。


方法论:用于量化的强化学习
每一层的位宽(bitqbq_bqb)属于集合{1,2,3,4,5}{1,2,3,4,5}{1,2,3,4,5}中,通过确定位宽来训练ReLeQ代理(agent),同时考虑先前层在每个步骤的量化。确定DNN层的准确率敏感度需要了解先前层(previous layers’ )的位宽,层索引,层大小和关于权重分布的统计(如,标准差),即Figure 2中Layer Specific的Static内容。因此,使用LSTM网络来考虑层之间的这种依赖关系。Figure 2a显示了ReLeQ代理的状态空间,分类如下:(i)每层唯一的层特定参数与特定于网络的参数,这些参数在代理在训练过程中表征整个网络。(ii)在训练过程中不会改变的静态参数。在训练过程中更改的动态参数取决于代理在搜索空间时所采取的操作。最后,除了层的属性之外,状态参数反映了关于量化和精度状态的一些指示,其定义如下:
动作空间
论文提供一组离散的量化位宽,ReLeQ代理从中选择以获得奖励反馈。 如Figure 2(b)所示,用于实现的一组位宽是1,2,3,4,5,但是也可以根据需要更改。
奖励函数
文章将奖励函数(Reward formulation)定义为两个状态的函数,分别是准确率状态与量化状态。 以下公式显示了ReLeQ奖励的制定,Figure 2c显示了公式的可视化。

在上述函数中,a和b是超参数,th是精度状态阈值。 当代理接近最佳量化组合时,以这种方式制定奖励产生平滑的奖励梯度。 此外,不同的二维梯度可加快代理的收敛时间。 通过设置阈值以防止不必要或不期望的搜索,进一步减少任务完成。 阈值还使代理能够探索设计空间内更多相关区域。
学习过程
如Figure 1所示,代理逐个遍历所有层,确定每一步的层的量化级别。 在针对给定步骤的每个动作之后,我们执行简短的重训练过程,并使用所得到的验证准确率来计算奖励。为了鼓励较低的比特宽度量化并因此降低成本,代理将所有层的平均量化与上述重新训练的准确度相结合地计入奖励。准确率奖励由相对于全精度准确度的改进或维持的验证准确度确定,而如果代理减少层的位宽,则量化奖励为正。 准确度奖励和量化奖励之间的相互作用使代理能够以最小的准确度损失对网络进行深度量化。
策略和价值网络
代理由两个网络组成,策略网络和价值网络。 所有状态嵌入都作为输入提供给LSTM层,这作为策略和价值网络的第一个隐藏层。 根据论文的评估,LSTM使ReLeQ代理的收敛速度比没有LSTM的情况下快几倍。 除了LSTM之外,策略网络还有两个完全连接的隐藏层,每个隐藏层有128个神经元,最终输出层中的神经元数量等于代理可以选择的可用位宽数量。 而Value网络有两个完全连接的隐藏层,每层隐藏128个和64个神经元。 使用近端策略优化(PPO),用于更新策略和价值网络。
评估
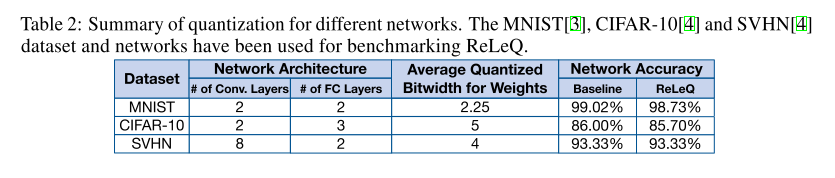
论文测试了MNIST,CIFAR10,SVHN数据集,分别将这些网络量化为平均位宽分别为2.25,5和4,在所有情况下精度损失小于0.3%。

测试的网络都比较简单,准确率损失的也不大。更多的结果在论文中有详细的说明。
状态嵌入
论文也进行了实验来评估使用状态嵌入的有效性。在每次迭代中,重复相同的实验,同时省略一次嵌入状态并保留其余部分。观察到层的尺寸/尺寸是最重要的收敛嵌入。层的标准差是第二重要参数。Figure 5a显示了LeNet的收敛行为,其中权重方差作为状态嵌入的一部分(基线结果),Figure 5b显示了权重方差从状态嵌入中排除时的行为。其余的状态嵌入有助于加速收敛过程。

加速微调
损失函数增加的自定义目标是为了增加泛化性能或对权重值施加一些偏好。以下小节中讨论正则化的使用方式。
Quantization friendly regularization
正则化是增强神经网络泛化性能的常用技术之一。 正则化通过向目标函数添加术语(正则化器)来有效地约束权重参数,该目标函数以软方式捕获期望的约束。 这是通过在优化过程中对权重更新施加某种偏好来实现的。最常用的正则化技术称为权重衰减,其目的是通过限制权重的增长来降低网络复杂性。 通过在目标函数中添加一个惩罚大权重值的术语来实现: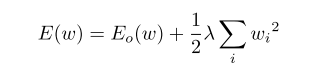
论文提出了一种对量化有利的新型正则化。通过在原始目标函数中添加周期函数(正则化器)来实现所提出的正则化,如Figure 6a。周期性正则化器具有对应于期望量化级别的周期性最小模式。通过基于给定层的特定比特数将周期与量化步长匹配来实现这种对应。其中EoE_oEo是原始损失度量,而λqlambda_qλq是一个控制权重量化误差有多强的参数。 www是包含网络的所有参数的向量。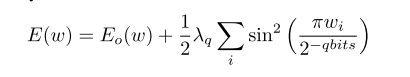
为了简单和清楚起见,Figure 6b和6c描绘了假设损耗表面(要最小化的原始目标函数)和2-D重量空间中的额外正则化项的几何草图。 对于重量衰减正则化,在图6b中,褪色的圆形轮廓表明,当我们接近原点时,正则化损失最小化,但这种方式并不在量化点处于小值。而提出的量化友好正则化能在不同量化点处均有较低的正则化值,从而降低损失,加快收敛。
在Figure 7上可以看出加上这一项起到的作用。
总结
整体来看强化学习在量化中仅仅进行了选择量化位宽的作用,而实际量化方式并没有明确说明。所以感觉只是把原来的自动求位宽和剪枝率的方法变了。正则化这一项倒是很新颖,不过不能满足非均匀量化。