首先,放上项目github地址: https://github.com/codethereforam/java-design-patterns, 我是用java实现的
一、前言
题目中的这三个设计模式属于创建型模式,作用是为了抽象实例化过程。
我之前学过这三个设计模式,但最近发现又无法厘清这三个的区别了,为了避免下次又忘了,于是想动手记录下来。
可能有同学有疑问,提前说一下,下面所展示的类图由IDEA自带插件UML Support自动生成,而时序图由插件SequencePlugin自动生成。如果有同学对类图和时序图还不了解,请先google自学一下。
下面我结合模拟场景总结一下这三个模式,具体代码请点击本文开头的github链接。
二、简单工厂
模拟场景:一个用户管理系统,假设只有一张User表。本来用的mysql,但需求突然发生变化,现在要用Oralce,由于这两个数据库的SQL语句有些差别,需要重写数据库层面的代码,现在要求系统可以灵活切换数据库。
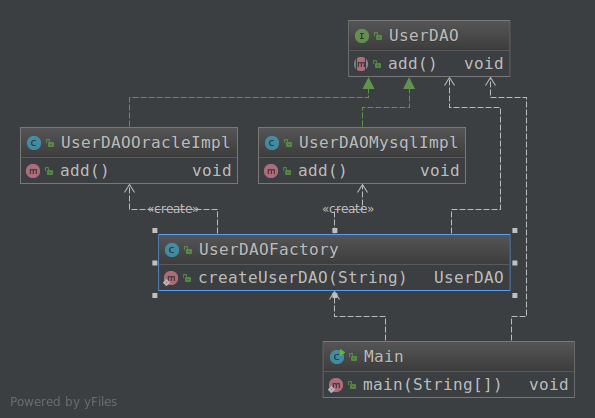
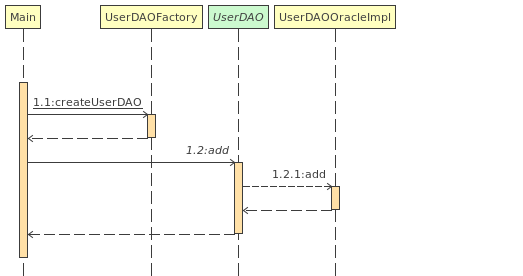
关键代码:
public class UserDAOFactory {
//静态工厂方法
public static UserDAO createUserDAO(String database) {
UserDAO userDAO = null;
switch (database) {
case "mysql":
userDAO = new UserDAOMysqlImpl();
break;
case "oracle":
userDAO = new UserDAOOracleImpl();
break;
default:
}
return userDAO;
}
}
分析:如果现在要改用SQL server数据库,需要添加一个UserDAOSqlserverImpl,然后在UserDAOFactory类的createUserDAO方法中添加一个case,这显然违背了开闭原则。
-
特点
- 工厂类包含必要的逻辑判断来选择生产具体产品
- 用于生产单个产品
-
优点
- 去除客户端与具体产品的依赖
-
缺点
- 添加产品需要修改工厂类,违背开闭原则
-
角色
- 抽象产品(UserDAO)
- 具体产品(UserDAOMysqlImpl & UserDAOOracleImpl)
- 工厂(UserDAOFactory)
三、工厂方法
模拟场景:和上述简单工厂模拟场景一样
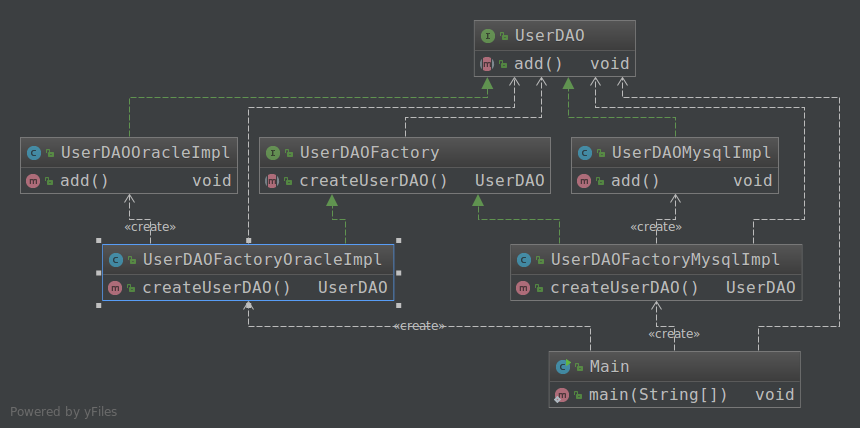
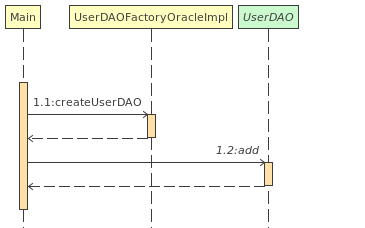
分析:如果现在要改用SQL server数据库,则需添加一个UserDAOSqlserverImpl和相应的工厂UserDAOFactorySqlserverImpl,再更改Main中的实例化代码,这满足了开闭原则,扩展很方便。但如果支持的数据库一多,那工厂就会泛滥。
-
特点
- 一个产品对应一个工厂类
- 用于生产某种类型产品
-
优点
- 方便添加新产品
- 添加新产品只需添加相应工厂类,符合开闭原则
-
缺点
- 产品多时,工厂泛滥
-
角色
- 抽象产品(UserDAO)
- 具体产品(UserDAOMysqlImpl & UserDAOOracleImpl)
- 抽象工厂(UserDAOFactory)
- 具体工厂(UserDAOFactoryMysqlImpl & UserDAOFactoryOracleImpl)
四、抽象工厂
模拟场景:在之前的场景基础上,如果系统本来还有一个日志表,是用来记录日志的。
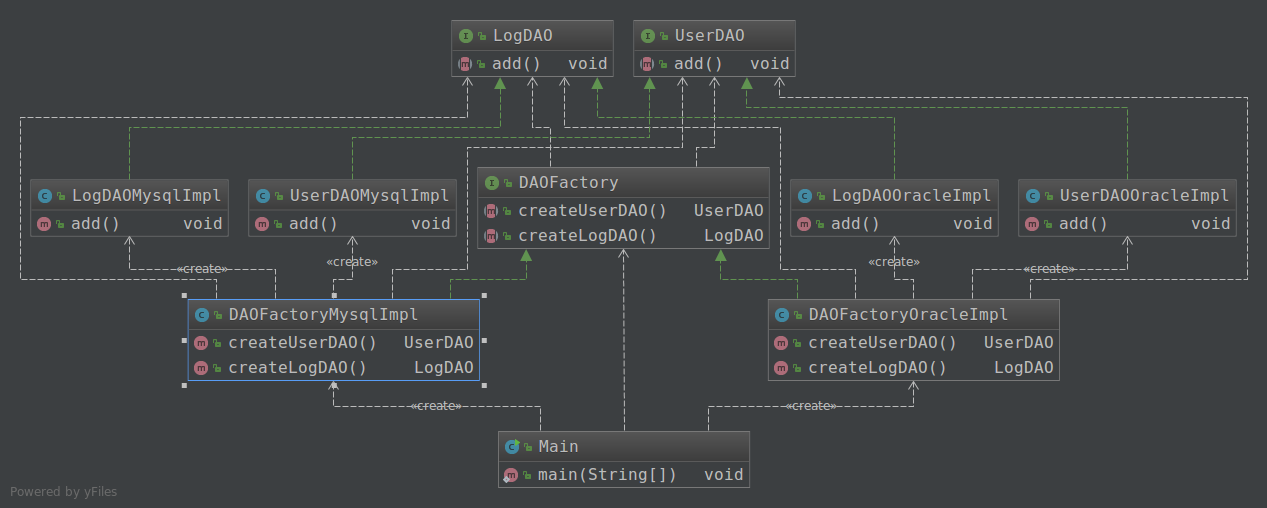

分析:如果现在要改用SQL server数据库,则需添加UserDAOSqlserverImpl、LogDAOSqlserverImpl和DAOFactorySqlserverImpl,再更改Main中的实例化代码。但如果现在要添加一个其他的表,那么就要改DAOFactory接口和接口中方法的实现,要改动的地方太多。
-
特点
- 用于生产一系列产品
-
优点
- 易于改变工厂生产行为,产生新的产品系列
- 具体创建过程与客户端分离,客户端通过接口操纵实例(factory1.createUserDAO().add())
-
缺点
- 添加新产品,要修改抽象工厂接口、具体工厂,改动太多
-
角色
- 抽象产品(UserDAO & LogDAO)
- 具体产品(UserDAOMysqlImpl & UserDAOOracleImpl & LogDAOMysqlImpl & LogDAOOracleImpl)
- 抽象工厂(DAOFactory)
- 具体工厂(DAOFactoryMysqlImpl & DAOFactoryOracleImpl)
五、用简单工厂改进抽象工厂
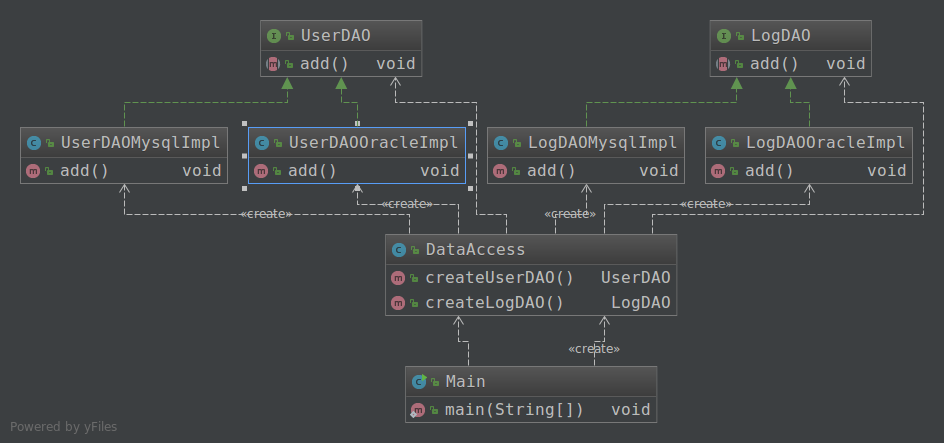
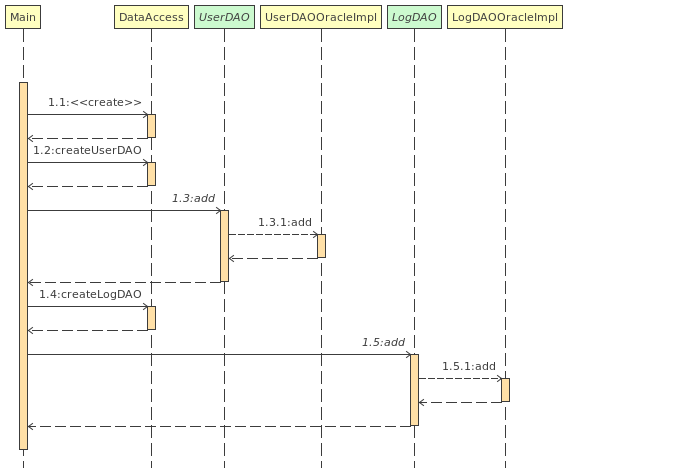
关键代码(选取DataAccess):
public UserDAO createUserDAO() {
UserDAO userDAO = null;
switch (database) {
case MYSQL:
userDAO = new UserDAOMysqlImpl();
break;
case ORACLE:
userDAO = new UserDAOOracleImpl();
break;
default:
}
return userDAO;
}
分析:与抽象工厂相比,该方法减少了三个类,添加了一个DataAccess类,类的数量减少了,系统复杂性降低。如果现在要改用SQL server数据库,则需添加UserDAOSqlserverImpl和LogDAOSqlserverImpl,然后在DataAccess类中的createUserDAO方法和createLogDAO方法分别添加一个case,这违背了开闭原则。
-
特点
- 用DataAccess取代抽象工厂和具体工厂
- DataAccess通过判断控制生产行为
-
优点
- 减少类
-
缺点
- 添加新产品系列,要改动DataAccess中的switch-case
六、用反射改进抽象工厂
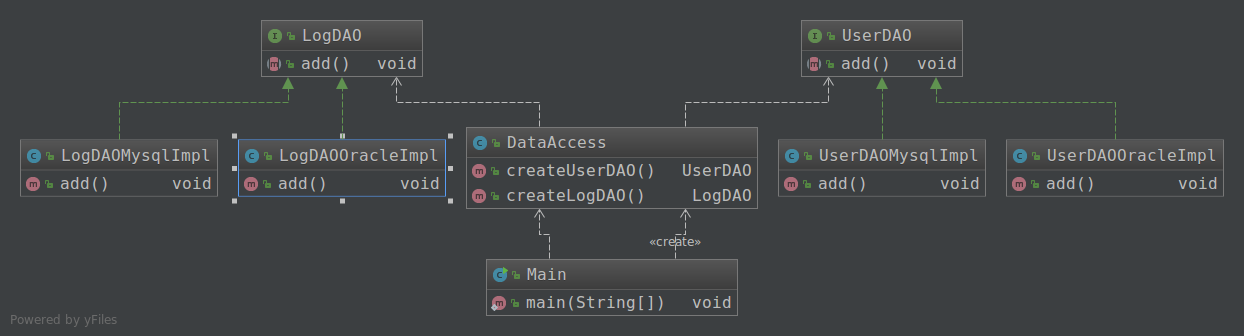
关键代码(选取DataAccess):
public static final String PACKAGE_NAME = DataAccess.class.getPackage().getName();
public UserDAO createUserDAO() throws ClassNotFoundException, IllegalAccessException, InstantiationException {
String className = PACKAGE_NAME + ".UserDAO" + database + "Impl";
return (UserDAO) Class.forName(className).newInstance();
}
分析:如果要换数据库,则无需修改DataAccess类中的代码。如果要添加表,只需要添加一个抽象产品接口和两个具体产品实现,然后在DataAccess中添加一个create**方法,扩展起来非常方便。
-
优点
- 减少类
- 解决抽象工厂添加产品改动较多的问题,方便扩展
-
可使用配置文件继续完善
七、总结
如果你仔细看到这,你可能会觉得我例子举的不恰当,哪里有系统只有一个表的呢,前面的场景直接考虑抽象工厂就行了。我承认我举的例子有问题,之前写代码时没有发现,应该是当时理解的还不够深入。
简单工厂和工厂方法的模拟场景应该改为:系统本来有一直表,但现在要添加表,而不是换数据库。而抽象工厂的模拟场景应该改为:在上述的基础上要换数据库。如果你理解了三个模式,我想这两个模拟场景你应该也知道怎么实现了。
本文的例子我参考了大话设计模式,但其他代码和文字是我自己的理解。如果有错误,望各位不吝赐教,在评论区指出。
八、参考资料
- 大话设计模式,by 程杰