DDL(Data Definition Language,数据定义语言)
DDL就是我们在创建表的时候用到的一些语句,比如说CREATE、ALTER、DROP等。DDL主要是用在定义或改变表的结构、数据类型、表之间的链接或约束等初始化工作上。
DCL(Data Control Language,数据库控制语言)
DCL是用来设置或更改数据库用户或角色权限的语句,包括GRANT、DENY、REVOKE等语句,这个层面应该主要是DBA做的事情了,但是如果是在小公司可能你还是要干,像部署数据库的时候你不会怎么行,特别是ORACLE这种用户驱动的数据库。
grant、roll back 、commit等
一、常见的数据库对象
表、视图,存储过程、函数,索引,触发器、序列
表的命名规则:
1.必须字母开头
2.长度为1-30个字符
3.A-Z,a-z,0-9, _ , $, #
DML--DDL-DCL倒的,
一、DML insert、delete、update ,select
(1).insert的时候可以直接写insert语句
insert into table_a (column1,column2,column3) values('a','b','c'); --白手起家
insert into table_a (column1,column2,column3) select column4,column5,column6 from table_b; --投机取巧 --不用写as
(2)DELETE --只删除表数据,不影响表结构
(3)UPDATE
题目:两个表 A与B,A与B的关联通过aid与bid,然后用bname字段更新aname字段,
update A set aname =(select bname from B where A.aid=B.bid)
update操作的时候会产生排他锁,举个例子现在是a用户对表C进行update操作了,并没有commit,然后b用户此时对表C进行update操作是不可以的,除非等到a用户执行commit后,b用户可以对更新后的表C进行操作。
Select操作 也是开启事物,也会排他,insert,delete,update,select都会开启事务
DML可以rollback
写完update后执行commit命令,然后rollback后无效果
savepoint --设置保存点
savepoint A;是设置保存点的语句
约束constraint -- 创建并修改约束
not null
unique --是可以插入null的
一个字段的约束设置的是unique,该字段为null是可以的,并且可以存在多条null,这是unique与primary的区别
primary key是要求非空的,unique是可以null的
primary key
foreign key
外键的作用:
保持数据一致性,完整性,主要目的是控制存储在外键表中的数据。 使两张表形成关联,外键只能引用外表中的列的值!
子表,父表的定义: 拥有外键的表是子表。主键被其它表引用的表是父表。
换句话说:因为父表的标识被很多个子表中的记录引用,所以叫父表。
拥有外键关系,并且可以随便删除数据,不影响其它表的数据的那个表叫子表。
外键 (FK) 是用于建立和加强两个表数据之间的链接的一列或多列。通过将保存表中主键值的一列或多列添加到另一个表中,可创建两个表之间的链接。这个列就成为第二个表的外键。
外键是用来控制数据库中数据的数据完整性的,就是当你对一个表的数据进行操作,他有关联的一个或更多表的数据能够同时发生改变
这就是外键的作用
病人信息表(子表)--科室信息表(父表)
超女选秀活动有两个数据表:
1)赛区参数表
赛区代码,赛区名称,……。
2)超女基本信息表
赛区代码、超女编号、姓名、颜值、身材、身高、体重、……。
录入超女基本信息的时候要选择赛区,为了保证数据的有效,要求录入赛区代码时,必须保证赛区参数表中有这个赛区代码,否则数据是不一致的,为了保证数据的完整性,必须在程序中判断数据的合法性。针对这种情况,在表结构设计中采用外键来约束这两个表的赛区代码字段。
对赛区参数表来说,赛区代码是该表的主键。
对超女基本信息表来说,赛区代码是该表的外键。
赛区参数表也称为主表,超女基本信息表也称为从表。
3、外键约束
1)当对从表进行操作时,数据库会:
a)向从表插入新记录时,如果外键值在主表中不存在,阻止插入。
b)修改从表的记录时,如果外键的值在主表中不存在,阻止修改。
2)当对主表进行修改操作时,数据库会:
a)主表修改主键值时,旧值在从表里存在便阻止修改。
3)当对主表进行删除操作时,数据库会(三选一):
a)主表删除行时,其主键值在从表里存在便阻止删除。
b)主表删除行时,连带从表的相关行一起删除。
c)主表删除行时,把从表相关行的外键字段置为null。
6、示例脚本
/* 创建赛区参数表。 */
create table T_AREACODE
(
areaid number(2) not null, -- 赛区代码,非空。
areaname varchar(20) not null, -- 赛区名称,非空。
memo varchar(300), -- 备注
primary key(areaid) -- 创建主健。
);
/* 创建超女基本信息表。 */
create table T_GIRL
(
id char(4) not null, -- 编号
name varchar2(30) null, -- 姓名
areaid number(2) null, -- 赛区代码
yz varchar2(20) null, -- 颜值
sc varchar2(20) null, -- 身材
memo varchar2(1000) null, -- 备注
primary key(id) -- 创建主健。
);
/* 以下三种创建外键的方式只能三选一 */
/* 为T_GIRL创建外键,无on delete选项。 */
alter table T_GIRL
add constraint FK_GIRL_AREACODE foreign key(areaid)
references T_AREACODE(areaid);
/* 为T_GIRL创建外键,采用on delete cascade选项。 */-- 级联删除--当父表中的列删除时,子表的相关数据也被删除
alter table T_GIRL
add constraint FK_GIRL_AREACODE foreign key(areaid)
references T_AREACODE(areaid)
on delete cascade;
/* 为T_GIRL创建外键,采用on delete set null选项。 */-- 级联置空--当父表中的列删除时,子表的相关数据被置空alter table T_GIRL add constraint FK_GIRL_AREACODE foreign key(areaid) references T_AREACODE(areaid) on delete set null;
参考:https://www.cnblogs.com/wucongzhou/p/12496127.html#5、删除外键
事件触发限制: on delete和on update , 可设参数cascade(跟随外键改动), restrict(限制外表中的外键改动),set Null(设空值),set Default(设默认值),[默认]no action
子表,父表的定义: 拥有外键的表是子表。主键被其它表引用的表是父表。
换句话说:因为父表的标识被很多个子表中的记录引用,所以叫父表。
拥有外键关系,并且可以随便删除数据,不影响其它表的数据的那个表叫子表。
使用的时候谁做为谁的外键,主要从以下两点考虑:
1/,删除是如何相互影响的,删除记录受约束的那个是父表,不受约束的那个是子表;
2/,记录必须先存在的是父表;两种用途:
1/, 最常用的一种: 减少重复数据.表A中拥有外键,表B的数据基本是不允许删除的.这时选择对 INSERT 和 UPDATE 强制关系即可.
2/,其次,是增加一个从属表. 如果表A删除一条记录时,表B中也随着删除一条相关联的记录,那么外键关系中,表A的主键是表B的外键。这种关系,实际上表B是表A的从属表(即表A是父表),选择对 INSERT 和 UPDATE 强制关系时,如果向表B中插入数据,表A中必须已经存在对应的记录。选择级联删除相关的字段时,删除表A中的一条记录,就会删除对应的表B中的一条记录。
外键的作用:
外键 (FK) 是用于建立和加强两个表数据之间的链接的一列或多列。通过将保存表中主键值的一列或多列添加到另一个表中,可创建两个表之间的链接。这个列就成为第二个表的外键。
FOREIGN KEY 约束的主要目的是控制存储在外键表中的数据,但它还可以控制对主键表中数据的修改。例如,如果在 publishers 表中删除一个出版商,而这个出版商的 ID 在 titles 表中记录书的信息时使用了,则这两个表之间关联的完整性将被破坏,titles 表中该出版商的书籍因为与 publishers 表中的数据没有链接而变得孤立了。FOREIGN KEY 约束防止这种情况的发生。如果主键表中数据的更改使之与外键表中数据的链接失效,则这种更改是不能实现的,从而确保了引用完整性。如果试图删除主键表中的行或更改主键值,而该主键值与另一个表的 FOREIGN KEY 约束值相关,则该操作不可实现。若要成功更改或删除 FOREIGN KEY 约束的行,可以先在外键表中删除外键数据或更改外键数据,然后将外键链接到不同的主键数据上去。
check
目标
实例讲解在Oracle中如何使用CHECK约束(创建、启用、禁用和删除)
2. 什么是Check约束?
CHECK约束指在表的列中增加额外的限制条件。
注:
CHECK约束不能在VIEW中定义。
CHECK约束只能定义的列必须包含在所指定的表中。
CHECK约束不能包含子查询。
3. 创建表时定义CHECK约束
3.1 语法:
CREATE TABLE table_name
(
column1 datatype null/not null,
column2 datatype null/not null,
...
CONSTRAINT constraint_name CHECK (column_name condition) [DISABLE]
);
其中,DISABLE关键之是可选项。如果使用了DISABLE关键字,当CHECK约束被创建后,CHECK约束的限制条件不会生效。
3.2 示例1:数值范围验证
create table tb_supplier
(
supplier_id number,
supplier_name varchar2(50),
contact_name varchar2(60),
/*定义CHECK约束,该约束在字段supplier_id被插入或者更新时验证,当条件不满足时触发。*/
CONSTRAINT check_tb_supplier_id CHECK (supplier_id BETWEEN 100 and 9999)
);
验证:
在表中插入supplier_id满足条件和不满足条件两种情况:
--supplier_id满足check约束条件,此条记录能够成功插入
insert into tb_supplier values(200, 'dlt','stk');
--supplier_id不满足check约束条件,此条记录能够插入失败,并提示相关错误如下
insert into tb_supplier values(1, 'david louis tian','stk');
不满足条件的错误提示:
Error report -
SQL Error: ORA-02290: check constraint (502351838.CHECK_TB_SUPPLIER_ID) violated
02290. 00000 - "check constraint (%s.%s) violated"
*Cause: The values being inserted do not satisfy the named check
3.3 示例2:强制插入列的字母为大写
create table tb_products
(
product_id number not null,
product_name varchar2(100) not null,
supplier_id number not null,
/*定义CHECK约束check_tb_products,用途是限制插入的产品名称必须为大写字母*/
CONSTRAINT check_tb_products
CHECK (product_name = UPPER(product_name))
);
验证:
在表中插入product_name满足条件和不满足条件两种情况:
--product_name满足check约束条件,此条记录能够成功插入
insert into tb_products values(2, 'LENOVO','2');
--product_name不满足check约束条件,此条记录能够插入失败,并提示相关错误如下
insert into tb_products values(1, 'iPhone','1');
不满足条件的错误提示:
SQL Error: ORA-02290: check constraint (502351838.CHECK_TB_PRODUCTS) violated
02290. 00000 - "check constraint (%s.%s) violated"
*Cause: The values being inserted do not satisfy the named check
4. ALTER TABLE定义CHECK约束
4.1 语法
ALTER TABLE table_name
ADD CONSTRAINT constraint_name CHECK (column_name condition) [DISABLE];
其中,DISABLE关键之是可选项。如果使用了DISABLE关键字,当CHECK约束被创建后,CHECK约束的限制条件不会生效。
4.2 示例准备
drop table tb_supplier;
--创建实例表
create table tb_supplier
(
supplier_id number,
supplier_name varchar2(50),
contact_name varchar2(60)
);
4.3 创建CHECK约束
--创建check约束
alter table tb_supplier
add constraint check_tb_supplier
check (supplier_name IN ('IBM','LENOVO','Microsoft'));
4.4 验证
--supplier_name满足check约束条件,此条记录能够成功插入
insert into tb_supplier values(1, 'IBM','US');
--supplier_name不满足check约束条件,此条记录能够插入失败,并提示相关错误如下
insert into tb_supplier values(1, 'DELL','HO');
不满足条件的错误提示:
SQL Error: ORA-02290: check constraint (502351838.CHECK_TB_SUPPLIER) violated
02290. 00000 - "check constraint (%s.%s) violated"
*Cause: The values being inserted do not satisfy the named check
5. 启用CHECK约束
5.1 语法
ALTER TABLE table_name
ENABLE CONSTRAINT constraint_name;
5.2 示例
drop table tb_supplier;
--重建表和CHECK约束
create table tb_supplier
(
supplier_id number,
supplier_name varchar2(50),
contact_name varchar2(60),
/*定义CHECK约束,该约束尽在启用后生效*/
CONSTRAINT check_tb_supplier_id CHECK (supplier_id BETWEEN 100 and 9999) DISABLE
);
--启用约束
ALTER TABLE tb_supplier ENABLE CONSTRAINT check_tb_supplier_id;
6. 禁用CHECK约束
6.1 语法
ALTER TABLE table_name
DISABLE CONSTRAINT constraint_name;
6.2 示例
--禁用约束
ALTER TABLE tb_supplier DISABLE CONSTRAINT check_tb_supplier_id;
7. 约束详细信息查看
语句:
--查看约束的详细信息
select
constraint_name,--约束名称
constraint_type,--约束类型
table_name,--约束所在的表
search_condition,--约束表达式
status--是否启用
from user_constraints--[all_constraints|dba_constraints]
where constraint_name='CHECK_TB_SUPPLIER_ID';
8. 删除CHECK约束
8.1 语法
ALTER TABLE table_name
DROP CONSTRAINT constraint_name;
8.2 示例
ALTER TABLE tb_supplier
DROP CONSTRAINT check_tb_supplier_id;
————————————————
参考:https://blog.csdn.net/jssg_tzw/article/details/40985081
<视图>
1,Oracle是可以通过视图来修改Base table的。所谓base table就是用来构建视图的表,也就是视图的数据来源表。但是这种修改是有条件的。比如:
create view v_emp as select empno,ename,job,deptno from emp where deptno=10 with check option constraint emp_cnst;
如果有这个限制,那么通过视图v_emp 插入数据的deptno字段的值必须是10,否则就会报“ORA-01402: 视图 WITH CHECK OPTIDN 违反 where 子句”的异常。
2,联结视图:
create view dept1_staff as select e.ename, e.empno, e.job, d.deptno, d.dname from emp e,dept d where e.deptno in (10,30) and e.deptno = d.deptno;
将两个表的数据联结起来,看起来应该是一个内联结(Inner joint)。
对于联结视图(Joint view)的修改规则稍显复杂,设计到所谓key_preserved table的概念。通过联结视图来修改基表,只有那些key_preserved 的表才能被修改。上述创建视图语句中emp和dept通过deptno进行联结构成视图时,emp就是key_preserved 表,而dept不是。为什么?因为在dept1_staff 中empno的值唯一的而deptno不是唯一的。所以emp是key_preserved 而dept不是。因此只能通过该视图来修改emp,而不能修改dept的数据。
3,Oracle视图非常强大的功能之一在于其可以创建一个带有错误的视图。比如说视图里的字段在基表里不存在,该视图仍然可以创建成功,但是非法的且无法执行。当基表里加入了该字段,或者说某个字段修改成视图里的该字段名称,那么视图马上就可以成为合法的。这个功能很有意思。
例子:
创建基表: create table v_test (name varchar2(32),age number(12));
创建带错误的视图:
create force view view_test as select name,age,address from v_test;(注意加上force选项)
由于address字段在v_test里不存在,所以会报warning: View created with compilation errors的警告,而且执行select * from view_test;时会报“ORA-04063: view "SCOTT.VIEW_TEST" 有错误”的异常。
但是如果在v_test里加上address字段,那么视图就会合法。
对基表进行修改:
alter table v_test add (address varchar2(128));
现在再执行select * from view_test;就会执行成功了。
参考:http://www.blogjava.net/jinhualee/archive/2006/07/14/58115.html
--with read only 只允许查询
<TOP -N分析 >

分页查询rownum
对于rownum来说它是oracle系统顺序分配为从查询返回的行的编号,返回的第一行分配的是1,第二行是2,依此类推,这个伪字段可以用于限制查询返回的总行数,且rownum不能以任何表的名称作为前缀。
(1) rownum 对于等于某值的查询条件
如果希望找到学生表中第一条学生的信息,可以使用rownum=1作为条件。但是想找到学生表中第二条学生的信息,使用rownum=2结果查不到数据。因为rownum都是从1开始,但是1以上的自然数在rownum做等于判断是时认为都是false条件,所以无法查到rownum = n(n>1的自然数)。
SQL> select rownum,id,name from student where rownum=1;(可以用在限制返回记录条数的地方,保证不出错,如:隐式游标)
SQL> select rownum,id,name from student where rownum =2;
ROWNUM ID NAME
---------- ------ ---------------------------------------------------
(2)rownum对于大于某值的查询条件
如果想找到从第二行记录以后的记录,当使用rownum>2是查不出记录的,原因是由于rownum是一个总是从1开始的伪列,Oracle 认为rownum> n(n>1的自然数)这种条件依旧不成立,所以查不到记录。
查找到第二行以后的记录可使用以下的子查询方法来解决。注意子查询中的rownum必须要有别名,否则还是不会查出记录来,这是因为rownum不是某个表的列,如果不起别名的话,无法知道rownum是子查询的列还是主查询的列。
SQL>select * from(select rownum no ,id,name from student) where no>2;
NO ID NAME
---------- ------ ---------------------------------------------------
3 200003 李三
4 200004 赵四
(3)rownum对于小于某值的查询条件
rownum对于rownum<n((n>1的自然数)的条件认为是成立的,所以可以找到记录。
SQL> select rownum,id,name from student where rownum <3;
ROWNUM ID NAME
---------- ------ ---------------------------------------------------
1 200001 张一
2 200002 王二
查询rownum在某区间的数据,必须使用子查询。例如要查询rownum在第二行到第三行之间的数据,包括第二行和第三行数据,那么我们只能写以下语句,先让它返回小于等于三的记录行,然后在主查询中判断新的rownum的别名列大于等于二的记录行。但是这样的操作会在大数据集中影响速度。
SQL> select * from (select rownum no,id,name from student where rownum<=3 ) where no >=2;
NO ID NAME
---------- ------ ---------------------------------------------------
2 200002 王二
3 200003 李三
(4)rownum和排序
Oracle中的rownum的是在取数据的时候产生的序号,所以想对指定排序的数据去指定的rowmun行数据就必须注意了。
SQL> select rownum ,id,name from student order by name;
ROWNUM ID NAME
---------- ------ ---------------------------------------------------
3 200003 李三
2 200002 王二
1 200001 张一
4 200004 赵四
可以看出,rownum并不是按照name列来生成的序号。系统是按照记录插入时的顺序给记录排的号,rowid也是顺序分配的。为了解决这个问题,必须使用子查询;
SQL> select rownum ,id,name from (select * from student order by name);
ROWNUM ID NAME
---------- ------ ---------------------------------------------------
1 200003 李三
2 200002 王二
3 200001 张一
4 200004 赵四
这样就成了按name排序,并且用rownum标出正确序号(有小到大)
笔者在工作中有一上百万条记录的表,在jsp页面中需对该表进行分页显示,便考虑用rownum来作,下面是具体方法(每页显示20条):
“select * from tabname where rownum<20 order by name" 但却发现oracle却不能按自己的意愿来执行,而是先随便取20条记录,然后再order by,后经咨询oracle,说rownum确实就这样,想用的话,只能用子查询来实现先排序,后rownum,方法如下:
"select * from (select * from tabname order by name) where rownum<20",但这样一来,效率会低很多。
后经笔者试验,只需在order by 的字段上加主键或索引即可让oracle先按该字段排序,然后再rownum;方法不变: “select * from tabname where rownum<20 order by name"
取得某列中第N大的行
select column_name from
(select table_name.*,dense_rank() over (order by column desc) rank from table_name)
where rank = &N;
假如要返回前5条记录:
select * from tablename where rownum<6;(或是rownum <= 5 或是rownum != 6)
假如要返回第5-9条记录:
select * from tablename
where …
and rownum<10
minus
select * from tablename
where …
and rownum<5
order by name
选出结果后用name排序显示结果。(先选再排序)
attition:上面minus的时候要求大的一部分的数据要包含小的一部分的数据,上面介绍的是5-9行的写法,与排序无关
注意:只能用以上符号(<、<=、!=)。
select * from tablename where rownum != 10;返回的是前9条记录。
不能用:>,>=,=,Between...and。由于rownum是一个总是从1开始的伪列,Oracle 认为这种条件不成立。
对rownum进行排序的时候一定要进行子查询的格式
子表进行排序,主表进行查询,标注序号
<序列sequence>
序列: 是oacle提供的用于产生一系列唯一数字的数据库对象。
l 自动提供唯一的数值
l 共享对象
l 主要用于提供主键值
l 将序列值装入内存可以提高访问效率
创建序列:
1、 要有创建序列的权限 create sequence 或 create any sequence
2、 创建序列的语法
CREATE SEQUENCE sequence //创建序列名称
[INCREMENT BY n] //递增的序列值是n 如果n是正数就递增,如果是负数就递减 默认是1
[START WITH n] //开始的值,递增默认是minvalue 递减是maxvalue
[{MAXVALUE n | NOMAXVALUE}] //最大值
[{MINVALUE n | NOMINVALUE}] //最小值
[{CYCLE | NOCYCLE}] //循环/不循环
[{CACHE n | NOCACHE}];//分配并存入到内存中
NEXTVAL 返回序列中下一个有效的值,任何用户都可以引用
CURRVAL 中存放序列的当前值
NEXTVAL 应在 CURRVAL 之前指定 ,二者应同时有效
Create sequence seqEmp increment by 1 start with 1 maxvalue 3 minvalue 1
Cycle cache 2;
//先nextval 后 currval
Select seqEmp.nextval from dual;
Select seqEmp.currval from dual;
Cache<max-min/increment
//解释
{
Create 创建
Sequence 序列 seqEmop 序列名称
Increment by 步长
Stat with 1 开始值
Maxvalue 最大值
Minvalue 最小值
Cycle 循环 nocycle 不循环
Cache 缓存 Cache<maxvalue-minvalue/increment by//一般不采用缓存
Nextvalue 下一个
Currval 当前值
}
//实例应用
//实现id的自动递增
//第一步
create table cdpt(
id number(6),
name varchar2(30),
constraint pk_id primary key(id)
);
Create sequence seq_cdpt
Increment by 1
Start with 1
Maxvalue 999999
Minvalue 1
Nocycle
nocache
insert into cdpt values(seq_cdpt.nextval,’feffefe’);
commit;
select * from cdpt;
/使用序列
会产生裂缝
l 序列在下列情况下出现裂缝:
• 回滚
• 系统异常
>多个表同时使用同一序列
//修改序列的增量, 最大值, 最小值, 循环选项, 或是否装入内存
alter SEQUENCE sequence //创建序列名称
[INCREMENT BY n] //递增的序列值是n 如果n是正数就递增,如果是负数就递减 默认是1
[START WITH n] //开始的值,递增默认是minvalue 递减是maxvalue
[{MAXVALUE n | NOMAXVALUE}] //最大值
[{MINVALUE n | NOMINVALUE}] //最小值
[{CYCLE | NOCYCLE}] //循环/不循环
[{CACHE n | NOCACHE}];//分配并存入到内存中
修改序列的注意事项:
l 必须是序列的拥有者或对序列有 ALTER 权限
l 只有将来的序列值会被改变
l 改变序列的初始值只能通过删除序列之后重建序列的方法实现
删除序列
l 使用DROP SEQUENCE 语句删除序列
l 删除之后,序列不能再次被引用
Alter sequence seqEmp maxvalue 5;
Select seqEmp.nextval from dual;
————————————————
原文链接:https://blog.csdn.net/java958199586/article/details/7360152
实际使用的时候,insert into market_member(id,market_name,market_code) values(sequence_sccy.nextval ,'大唐',‘1213’)
<索引--INDEX>
索引是由Oracle维护的可选结构,为数据提供快速的访问。准确地判断在什么地方需要使用索引是困难的,使用索引有利于调节检索速度。 当建立一个索引时,必须指定用于跟踪的表名以及一个或多个表列。一旦建立了索引,在用户表中建立、更改和删除数据库时, Oracle就自动地维护索引。创建索引时,下列准则将帮助用户做出决定:
1) 索引应该在SQL语句的"where"或"and"部分涉及的表列(也称谓词)被建立。假如
personnel表的"firstname"表列作为查询结果显示,而不是作为谓词部分,则不论其值是什么,该表列不会被索引。
2)用户应该索引具有一定范围的表列,索引时有一个大致的原则:如果表中列的值占该表中行的2 0 %以内,这个表列就可以作为候选索引表列。假设一个表有36 000行且表中一个表列的值平均分布(大约每12000行),那么该表列不适合于一个索引。然而,如果同一个表中的其他表列中列值的行在1 0 0 0~1 5 0 0之间(占3 %~4 % ),则该表列可用作索引。
3)如果在S Q L语句谓词中多个表列被一起连续引用,则应该考虑将这些表列一起放在一个索引内, O r a c l e将维护单个表列的索引(建立在单一表列上)或复合索引(建立在多个表列上)。复合索引称并置索引。
1 主关键字的约束
关系数据库理论指出,在表中能唯一标识表的每个数据行的一个或多个表列是对象的主关键字。由于数据字典中定义的主关键字能确保表中数据行之间的唯一性,因此,在O r a c l e 8 i数据库中建立表索引关键字有助于应用调节。另外,这也减轻了开发者为了实现唯一性检查,而需要各自编程的要求。
提示使用主关键字索引条目比不使用主关键字索引检索得快。
假设表p e r s o n把它的i d表列作为主关键字,用下列代码设置约束:
alter table person add constraint person_pk primary key (id) using index storage (initial 1m next 1m
pctincrease 0) tablespace prd_indexes ;
处理下列S Q L语句时:
select last_name ,first_name ,salary from person where id = 289 ;
在查找一个已确定的“ i d”表列值时, O r a c l e将直接找到p e r s o n _ p k。如果其未找到正确的索引条目,O r a c l e知道该行不存在。主关键字索引具有下列两个独特之处:
1.1因为索引是唯一的, 所以O r a c l e知道只有一个条目具有设定值。如果查找到了所期望的条目,则立即终止查找。
1.2一旦遇到一个大于设定值的条目,索引的顺序搜索可被终止;
2 ORDER BY中用索引
ORDER BY 子句只在两种严格的条件下使用索引.
ORDER BY中所有的列必须包含在相同的索引中并保持在索引中的排列顺序.
ORDER BY中所有的列必须定义为非空.
WHERE子句使用的索引和ORDER BY子句中所使用的索引不能并列.
例如:
表DEPT包含以下列:
DEPT_CODE PK
NOT NULL
DEPT_DESC NOT NULL
DEPT_TYPE NULL
非唯一性的索引(DEPT_TYPE)
低效: (索引不被使用)
SELECT DEPT_CODE
FROM DEPT
ORDER BY DEPT_TYPE
EXPLAIN PLAN:
SORT ORDER BY
TABLE ACCESS FULL
高效: (使用索引)
SELECT DEPT_CODE
FROM DEPT
WHERE DEPT_TYPE > 0
EXPLAIN PLAN:
TABLE ACCESS BY ROWID ON EMP
INDEX RANGE SCAN ON DEPT_IDX
3 避免改变索引列的类型.
当比较不同数据类型的数据时, ORACLE自动对列进行简单的类型转换.
假设 EMPNO是一个数值类型的索引列.
SELECT …
FROM EMP
WHERE EMPNO = ‘123'
实际上,经过ORACLE类型转换, 语句转化为:
SELECT …
FROM EMP
WHERE EMPNO = TO_NUMBER(‘123')
幸运的是,类型转换没有发生在索引列上,索引的用途没有被改变.
现在,假设EMP_TYPE是一个字符类型的索引列.
SELECT …
FROM EMP
WHERE EMP_TYPE = 123
这个语句被ORACLE转换为:
SELECT …
FROM EMP
WHERE TO_NUMBER(EMP_TYPE)=123
因为内部发生的类型转换, 这个索引将不会被用到! 为了避免ORACLE对你的SQL进行隐式的类型转换, 最好把类型转换用显式表现出来. 注意当字符和数值比较时, ORACLE会优先转换数值类型到字符类型.
4 需要当心的WHERE子句
某些SELECT 语句中的WHERE子句不使用索引. 这里有一些例子.
在下面的例子里, ‘!=' 将不使用索引. 记住, 索引只能告诉你什么存在于表中, 而不能告诉你什么不存在于表中.
不使用索引:
SELECT ACCOUNT_NAME
FROM TRANSACTION
WHERE AMOUNT !=0;
使用索引:
SELECT ACCOUNT_NAME
FROM TRANSACTION
WHERE AMOUNT >0;
下面的例子中, ‘||'是字符连接函数. 就象其他函数那样, 停用了索引. 不使用索引:
SELECT ACCOUNT_NAME,AMOUNT
FROM TRANSACTION
WHERE ACCOUNT_NAME||ACCOUNT_TYPE='AMEXA';
使用索引:
SELECT ACCOUNT_NAME,AMOUNT
FROM TRANSACTION
WHERE ACCOUNT_NAME = ‘AMEX'
AND ACCOUNT_TYPE=' A';
下面的例子中, ‘+'是数学函数. 就象其他数学函数那样, 停用了索引.
不使用索引:
SELECT ACCOUNT_NAME, AMOUNT
FROM TRANSACTION
WHERE AMOUNT + 3000 >5000;
使用索引:
SELECT ACCOUNT_NAME, AMOUNT
FROM TRANSACTION
WHERE AMOUNT > 2000 ;
下面的例子中,相同的索引列不能互相比较,这将会启用全表扫描.
不使用索引:
SELECT ACCOUNT_NAME, AMOUNT
FROM TRANSACTION
WHERE ACCOUNT_NAME = NVL(:ACC_NAME,ACCOUNT_NAME);
使用索引:
SELECT ACCOUNT_NAME, AMOUNT
FROM TRANSACTION
WHERE ACCOUNT_NAME LIKE NVL(:ACC_NAME,'%');
如果一定要对使用函数的列启用索引, ORACLE新的功能: 基于函数的索引(Function-Based Index) 也许是一个较好的
方案.
CREATE INDEX EMP_I ON EMP (UPPER(ename)); /*建立基于函数的索引*/
SELECT * FROM emp WHERE UPPER(ename) = ‘BLACKSNAIL'; /*将使用索引*/
5 怎样监控无用的索引
Oracle 9i以上,可以监控索引的使用情况,如果一段时间内没有使用的索引,一般就是无用的索引
语法为:
开始监控:alter index index_name monitoring usage;
检查使用状态:select * from v$object_usage;
停止监控:alter index index_name nomonitoring usage;
当然,如果想监控整个用户下的索引,可以采用如下的脚本:
set heading off
set echo off
set feedback off
set pages 10000
spool start_index_monitor.sql
SELECT 'alter index '||owner||'.'||index_name||' monitoring usage;'
FROM dba_indexes
WHERE owner = USER;
spool off
set heading on
set echo on
set feedback on
------------------------------------------------
set heading off
set echo off
set feedback off
set pages 10000
spool stop_index_monitor.sql
SELECT 'alter index '||owner||'.'||index_name||' nomonitoring usage;'
FROM dba_indexes
WHERE owner = USER;
spool off
set heading on
set echo on
set feedback on
一.索引介绍
1.1 索引的创建语法:
CREATE UNIUQE | BITMAP INDEX <schema>.<index_name>
ON <schema>.<table_name>
(<column_name> | <expression> ASC | DESC,
<column_name> | <expression> ASC | DESC,...)
TABLESPACE <tablespace_name>
STORAGE <storage_settings>
LOGGING | NOLOGGING
COMPUTE STATISTICS
NOCOMPRESS | COMPRESS<nn>
NOSORT | REVERSE
PARTITION | GLOBAL PARTITION<partition_setting>
相关说明
1) UNIQUE | BITMAP:指定UNIQUE为唯一值索引,BITMAP为位图索引,省略为B-Tree索引。
2)<column_name> | <expression> ASC | DESC:可以对多列进行联合索引,当为expression时即“基于函数的索引”
3)TABLESPACE:指定存放索引的表空间(索引和原表不在一个表空间时效率更高)
4)STORAGE:可进一步设置表空间的存储参数
5)LOGGING | NOLOGGING:是否对索引产生重做日志(对大表尽量使用NOLOGGING来减少占用空间并提高效率)
6)COMPUTE STATISTICS:创建新索引时收集统计信息
7)NOCOMPRESS | COMPRESS<nn>:是否使用“键压缩”(使用键压缩可以删除一个键列中出现的重复值)
8)NOSORT | REVERSE:NOSORT表示与表中相同的顺序创建索引,REVERSE表示相反顺序存储索引值
9)PARTITION | NOPARTITION:可以在分区表和未分区表上对创建的索引进行分区
1.2 索引特点:
第一,通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
第二,可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
第三,可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
第四,在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
第五,通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
1.3 索引不足:
第一,创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
第二,索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
第三,当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
1.4 应该建索引列的特点:
1)在经常需要搜索的列上,可以加快搜索的速度;
2)在作为主键的列上,强制该列的唯一性和组织表中数据的排列结构;
3)在经常用在连接的列上,这些列主要是一些外键,可以加快连接的速度;
4)在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的;
5)在经常需要排序的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;
6)在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
1.5 不应该建索引列的特点:
第一,对于那些在查询中很少使用或者参考的列不应该创建索引。这是因为,既然这些列很少使用到,因此有索引或者无索引,并不能提高查询速度。相反,由于增加了索引,反而降低了系统的维护速度和增大了空间需求。
第二,对于那些只有很少数据值的列也不应该增加索引。这是因为,由于这些列的取值很少,例如人事表的性别列,在查询的结果中,结果集的数据行占了表中数据行的很大比例,即需要在表中搜索的数据行的比例很大。增加索引,并不能明显加快检索速度。
第三,对于那些定义为blob数据类型的列不应该增加索引。这是因为,这些列的数据量要么相当大,要么取值很少。
第四,当修改性能远远大于检索性能时,不应该创建索引。这是因为,修改性能和检索性能是互相矛盾的。当增加索引时,会提高检索性能,但是会降低修改性能。当减少索引时,会提高修改性能,降低检索性能。因此,当修改性能远远大于检索性能时,不应该创建索引。
1.6 限制索引
限制索引是一些没有经验的开发人员经常犯的错误之一。在SQL中有很多陷阱会使一些索引无法使用。下面讨论一些常见的问题:
1.6.1 使用不等于操作符(<>、!=)
下面的查询即使在cust_rating列有一个索引,查询语句仍然执行一次全表扫描。
select cust_Id,cust_name from customers where cust_rating <> 'aa';
把上面的语句改成如下的查询语句,这样,在采用基于规则的优化器而不是基于代价的优化器(更智能)时,将会使用索引。
select cust_Id,cust_name from customers where cust_rating < 'aa' or cust_rating > 'aa';
特别注意:通过把不等于操作符改成OR条件,就可以使用索引,以避免全表扫描。
1.6.2 使用IS NULL 或IS NOT NULL
使用IS NULL 或IS NOT NULL同样会限制索引的使用。因为NULL值并没有被定义。在SQL语句中使用NULL会有很多的麻烦。因此建议开发人员在建表时,把需要索引的列设成 NOT NULL。如果被索引的列在某些行中存在NULL值,就不会使用这个索引(除非索引是一个位图索引,关于位图索引在稍后在详细讨论)。
1.6.3 使用函数
如果不使用基于函数的索引,那么在SQL语句的WHERE子句中对存在索引的列使用函数时,会使优化器忽略掉这些索引。 下面的查询不会使用索引(只要它不是基于函数的索引)
select empno,ename,deptno from emp where trunc(hiredate)='01-MAY-81';
把上面的语句改成下面的语句,这样就可以通过索引进行查找。
select empno,ename,deptno from emp where hiredate<(to_date('01-MAY-81')+0.9999);
1.6.4 比较不匹配的数据类型
也是比较难于发现的性能问题之一。 注意下面查询的例子,account_number是一个VARCHAR2类型,在account_number字段上有索引。
下面的语句将执行全表扫描:
select bank_name,address,city,state,zip from banks where account_number = 990354;
Oracle可以自动把where子句变成to_number(account_number)=990354,这样就限制了索引的使用,改成下面的查询就可以使用索引:
select bank_name,address,city,state,zip from banks where account_number ='990354';
特别注意:不匹配的数据类型之间比较会让Oracle自动限制索引的使用,即便对这个查询执行Explain Plan也不能让您明白为什么做了一次“全表扫描”。
1.7 查询索引
查询DBA_INDEXES视图可得到表中所有索引的列表,注意只能通过USER_INDEXES的方法来检索模式(schema)的索引。访问USER_IND_COLUMNS视图可得到一个给定表中被索引的特定列。
1.8 组合索引
当某个索引包含有多个已索引的列时,称这个索引为组合(concatented)索引。在 Oracle9i引入跳跃式扫描的索引访问方法之前,查询只能在有限条件下使用该索引。比如:表emp有一个组合索引键,该索引包含了empno、 ename和deptno。在Oracle9i之前除非在where之句中对第一列(empno)指定一个值,否则就不能使用这个索引键进行一次范围扫描。
特别注意:在Oracle9i之前,只有在使用到索引的前导索引时才可以使用组合索引!
1.9 ORACLE ROWID
通过每个行的ROWID,索引Oracle提供了访问单行数据的能力。ROWID其实就是直接指向单独行的线路图。如果想检查重复值或是其他对ROWID本身的引用,可以在任何表中使用和指定rowid列。
1.10 选择性
使用USER_INDEXES视图,该视图中显示了一个distinct_keys列。比较一下唯一键的数量和表中的行数,就可以判断索引的选择性。选择性越高,索引返回的数据就越少。
1.11 群集因子(Clustering Factor)
Clustering Factor位于USER_INDEXES视图中。该列反映了数据相对于已建索引的列是否显得有序。如果Clustering Factor列的值接近于索引中的树叶块(leaf block)的数目,表中的数据就越有序。如果它的值接近于表中的行数,则表中的数据就不是很有序。
1.12 二元高度(Binary height)
索引的二元高度对把ROWID返回给用户进程时所要求的I/O量起到关键作用。在对一个索引进行分析后,可以通过查询DBA_INDEXES的B- level列查看它的二元高度。二元高度主要随着表的大小以及被索引的列中值的范围的狭窄程度而变化。索引上如果有大量被删除的行,它的二元高度也会增加。更新索引列也类似于删除操作,因为它增加了已删除键的数目。重建索引可能会降低二元高度。
1.13 快速全局扫描
从Oracle7.3后就可以使用快速全局扫描(Fast Full Scan)这个选项。这个选项允许Oracle执行一个全局索引扫描操作。快速全局扫描读取B-树索引上所有树叶块。初始化文件中的 DB_FILE_MULTIBLOCK_READ_COUNT参数可以控制同时被读取的块的数目。
1.14 跳跃式扫描
从Oracle9i开始,索引跳跃式扫描特性可以允许优化器使用组合索引,即便索引的前导列没有出现在WHERE子句中。索引跳跃式扫描比全索引扫描要快的多。
下面的比较他们的区别:
SQL> set timing on
SQL> create index TT_index on TT(teamid,areacode);
索引已创建。
已用时间: 00: 02: 03.93
SQL> select count(areacode) from tt;
COUNT(AREACODE)
---------------
7230369
已用时间: 00: 00: 08.31
SQL> select /*+ index(tt TT_index )*/ count(areacode) from tt;
COUNT(AREACODE)
---------------
7230369
已用时间: 00: 00: 07.37
1.15 索引的类型
B-树索引 位图索引 HASH索引 索引编排表
反转键索引 基于函数的索引 分区索引 本地和全局索引
二. 索引分类
Oracle提供了大量索引选项。知道在给定条件下使用哪个选项对于一个应用程序的性能来说非常重要。一个错误的选择可能会引发死锁,并导致数据库性能急剧下降或进程终止。而如果做出正确的选择,则可以合理使用资源,使那些已经运行了几个小时甚至几天的进程在几分钟得以完成,这样会使您立刻成为一位英雄。下面就将简单的讨论每个索引选项。
下面讨论的索引类型:
B树索引(默认类型)
位图索引
HASH索引
索引组织表索引
反转键(reverse key)索引
基于函数的索引
分区索引(本地和全局索引)
位图连接索引
2.1 B树索引 (默认类型)
B树索引在Oracle中是一个通用索引。在创建索引时它就是默认的索引类型。B树索引可以是一个列的(简单)索引,也可以是组合/复合(多个列)的索引。B树索引最多可以包括32列。
在下图的例子中,B树索引位于雇员表的last_name列上。这个索引的二元高度为3;接下来,Oracle会穿过两个树枝块(branch block),到达包含有ROWID的树叶块。在每个树枝块中,树枝行包含链中下一个块的ID号。
树叶块包含了索引值、ROWID,以及指向前一个和后一个树叶块的指针。Oracle可以从两个方向遍历这个二叉树。B树索引保存了在索引列上有值的每个数据行的ROWID值。Oracle不会对索引列上包含NULL值的行进行索引。如果索引是多个列的组合索引,而其中列上包含NULL值,这一行就会处于包含NULL值的索引列中,且将被处理为空(视为NULL)。
技巧:索引列的值都存储在索引中。因此,可以建立一个组合(复合)索引,这些索引可以直接满足查询,而不用访问表。这就不用从表中检索数据,从而减少了I/O量。
B-tree 特点:
适合与大量的增、删、改(OLTP)
不能用包含OR操作符的查询;
适合高基数的列(唯一值多)
典型的树状结构;
每个结点都是数据块;
大多都是物理上一层、两层或三层不定,逻辑上三层;
叶子块数据是排序的,从左向右递增;
在分支块和根块中放的是索引的范围;
2.2 位图索引
位图索引非常适合于决策支持系统(Decision Support System,DSS)和数据仓库,它们不应该用于通过事务处理应用程序访问的表。它们可以使用较少到中等基数(不同值的数量)的列访问非常大的表。尽管位图索引最多可达30个列,但通常它们都只用于少量的列。
例如,您的表可能包含一个称为Sex的列,它有两个可能值:男和女。这个基数只为2,如果用户频繁地根据Sex列的值查询该表,这就是位图索引的基列。当一个表内包含了多个位图索引时,您可以体会到位图索引的真正威力。如果有多个可用的位图索引,Oracle就可以合并从每个位图索引得到的结果集,快速删除不必要的数据。
Bitmapt 特点:
适合与决策支持系统;
做UPDATE代价非常高;
非常适合OR操作符的查询;
基数比较少的时候才能建位图索引;
技巧:对于有较低基数的列需要使用位图索引。性别列就是这样一个例子,它有两个可能值:男或女(基数仅为2)。位图对于低基数(少量的不同值)列来说非常快,这是因为索引的尺寸相对于B树索引来说小了很多。因为这些索引是低基数的B树索引,所以非常小,因此您可以经常检索表中超过半数的行,并且仍使用位图索引。
当大多数条目不会向位图添加新的值时,位图索引在批处理(单用户)操作中加载表(插入操作)方面通常要比B树做得好。当多个会话同时向表中插入行时不应该使用位图索引,在大多数事务处理应用程序中都会发生这种情况。
示例
下面来看一个示例表PARTICIPANT,该表包含了来自个人的调查数据。列Age_Code、Income_Level、Education_Level和Marital_Status都包括了各自的位图索引。下图显示了每个直方图中的数据平衡情况,以及对访问每个位图索引的查询的执行路径。图中的执行路径显示了有多少个位图索引被合并,可以看出性能得到了显著的提高。
如上图图所示,优化器依次使用4个单独的位图索引,这些索引的列在WHERE子句中被引用。每个位图记录指针(例如0或1),用于指示表中的哪些行包含位图中的已知值。有了这些信息后,Oracle就执行BITMAP AND操作以查找将从所有4个位图中返回哪些行。该值然后被转换为ROWID值,并且查询继续完成剩余的处理工作。注意,所有4个列都有非常低的基数,使用索引可以非常快速地返回匹配的行。
技巧:在一个查询中合并多个位图索引后,可以使性能显著提高。位图索引使用固定长度的数据类型要比可变长度的数据类型好。较大尺寸的块也会提高对位图索引的存储和读取性能。
下面的查询可显示索引类型。
SQL> select index_name, index_type from user_indexes;
INDEX_NAME INDEX_TYPE
------------------------------ ----------------------
TT_INDEX NORMAL
IX_CUSTADDR_TP NORMAL
B树索引作为NORMAL列出;而位图索引的类型值为BITMAP。
技巧:如果要查询位图索引列表,可以在USER _INDEXES视图中查询index_type列。
建议不要在一些联机事务处理(OLTP)应用程序中使用位图索引。B树索引的索引值中包含ROWID,这样Oracle就可以在行级别上锁定索引。位图索引存储为压缩的索引值,其中包含了一定范围的ROWID,因此Oracle必须针对一个给定值锁定所有范围内的ROWID。这种锁定类型可能在某些DML语句中造成死锁。SELECT语句不会受到这种锁定问题的影响。
位图索引的使用限制:
基于规则的优化器不会考虑位图索引。
当执行ALTER TABLE语句并修改包含有位图索引的列时,会使位图索引失效。
位图索引不包含任何列数据,并且不能用于任何类型的完整性检查。
位图索引不能被声明为唯一索引。
位图索引的最大长度为30。
技巧:不要在繁重的OLTP环境中使用位图索引
2.3 HASH索引
使用HASH索引必须要使用HASH集群。建立一个集群或HASH集群的同时,也就定义了一个集群键。这个键告诉Oracle如何在集群上存储表。在存储数据时,所有与这个集群键相关的行都被存储在一个数据库块上。如果数据都存储在同一个数据库块上,并且将HASH索引作为WHERE子句中的确切匹配,Oracle就可以通过执行一个HASH函数和I/O来访问数据——而通过使用一个二元高度为4的B树索引来访问数据,则需要在检索数据时使用4个I/O。如下图所示,其中的查询是一个等价查询,用于匹配HASH列和确切的值。Oracle可以快速使用该值,基于HASH函数确定行的物理存储位置。
HASH索引可能是访问数据库中数据的最快方法,但它也有自身的缺点。集群键上不同值的数目必须在创建HASH集群之前就要知道。需要在创建HASH集群的时候指定这个值。低估了集群键的不同值的数字可能会造成集群的冲突(两个集群的键值拥有相同的HASH值)。这种冲突是非常消耗资源的。冲突会造成用来存储额外行的缓冲溢出,然后造成额外的I/O。如果不同HASH值的数目已经被低估,您就必须在重建这个集群之后改变这个值。
ALTER CLUSTER命令不能改变HASH键的数目。HASH集群还可能浪费空间。如果无法确定需要多少空间来维护某个集群键上的所有行,就可能造成空间的浪费。如果不能为集群的未来增长分配好附加的空间,HASH集群可能就不是最好的选择。如果应用程序经常在集群表上进行全表扫描,HASH集群可能也不是最好的选择。由于需要为未来的增长分配好集群的剩余空间量,全表扫描可能非常消耗资源。
在实现HASH集群之前一定要小心。您需要全面地观察应用程序,保证在实现这个选项之前已经了解关于表和数据的大量信息。通常,HASH对于一些包含有序值的静态数据非常有效。
技巧:HASH索引在有限制条件(需要指定一个确定的值而不是一个值范围)的情况下非常有用。
2.4 索引组织表
索引组织表会把表的存储结构改成B树结构,以表的主键进行排序。这种特殊的表和其他类型的表一样,可以在表上执行所有的DML和DDL语句。由于表的特殊结构,ROWID并没有被关联到表的行上。
对于一些涉及精确匹配和范围搜索的语句,索引组织表提供了一种基于键的快速数据访问机制。基于主键值的UPDATE和DELETE语句的性能也同样得以提高,这是因为行在物理上有序。由于键列的值在表和索引中都没有重复,存储所需要的空间也随之减少。
如果不会频繁地根据主键列查询数据,则需要在索引组织表中的其他列上创建二级索引。不会频繁根据主键查询表的应用程序不会了解到使用索引组织表的全部优点。对于总是通过对主键的精确匹配或范围扫描进行访问的表,就需要考虑使用索引组织表。
技巧:可以在索引组织表上建立二级索引。
2.5 反转键索引
当载入一些有序数据时,索引肯定会碰到与I/O相关的一些瓶颈。在数据载入期间,某部分索引和磁盘肯定会比其他部分使用频繁得多。为了解决这个问题,可以把索引表空间存放在能够把文件物理分割在多个磁盘上的磁盘体系结构上。
为了解决这个问题,Oracle还提供了一种反转键索引的方法。如果数据以反转键索引存储,这些数据的值就会与原先存储的数值相反。这样,数据1234、1235和1236就被存储成4321、5321和6321。结果就是索引会为每次新插入的行更新不同的索引块。
技巧:如果您的磁盘容量有限,同时还要执行大量的有序载入,就可以使用反转键索引。
不可以将反转键索引与位图索引或索引组织表结合使用。因为不能对位图索引和索引组织表进行反转键处理。
2.6 基于函数的索引
可以在表中创建基于函数的索引。如果没有基于函数的索引,任何在列上执行了函数的查询都不能使用这个列的索引。例如,下面的查询就不能使用JOB列上的索引,除非它是基于函数的索引:
select * from emp where UPPER(job) = 'MGR';
下面的查询使用JOB列上的索引,但是它将不会返回JOB列具有Mgr或mgr值的行:
select * from emp where job = 'MGR';
可以创建这样的索引,允许索引访问支持基于函数的列或数据。可以对列表达式UPPER(job)创建索引,而不是直接在JOB列上建立索引,如:
create index EMP$UPPER_JOB on emp(UPPER(job));
尽管基于函数的索引非常有用,但在建立它们之前必须先考虑下面一些问题:
能限制在这个列上使用的函数吗?如果能,能限制所有在这个列上执行的所有函数吗
是否有足够应付额外索引的存储空间?
在每列上增加的索引数量会对针对该表执行的DML语句的性能带来何种影响?
基于函数的索引非常有用,但在实现时必须小心。在表上创建的索引越多,INSERT、UPDATE和DELETE语句的执行就会花费越多的时间。
注意:对于优化器所使用的基于函数的索引来说,必须把初始参数QUERY _REWRITE _ ENABLED设定为TRUE。
示例:
select count(*) from sample where ratio(balance,limit) >.5;
Elapsed time: 20.1 minutes
create index ratio_idx1 on sample (ratio(balance, limit));
select count(*) from sample where ratio(balance,limit) >.5;
Elapsed time: 7 seconds!!!
2.7 分区索引
分区索引就是简单地把一个索引分成多个片断。通过把一个索引分成多个片断,可以访问更小的片断(也更快),并且可以把这些片断分别存放在不同的磁盘驱动器上(避免I/O问题)。B树和位图索引都可以被分区,而HASH索引不可以被分区。可以有好几种分区方法:表被分区而索引未被分区;表未被分区而索引被分区;表和索引都被分区。不管采用哪种方法,都必须使用基于成本的优化器。分区能够提供更多可以提高性能和可维护性的可能性
有两种类型的分区索引:本地分区索引和全局分区索引。每个类型都有两个子类型,有前缀索引和无前缀索引。表各列上的索引可以有各种类型索引的组合。如果使用了位图索引,就必须是本地索引。把索引分区最主要的原因是可以减少所需读取的索引的大小,另外把分区放在不同的表空间中可以提高分区的可用性和可靠性。
在使用分区后的表和索引时,Oracle还支持并行查询和并行DML。这样就可以同时执行多个进程,从而加快处理这条语句。
2.7.1.本地分区索引(通常使用的索引)
可以使用与表相同的分区键和范围界限来对本地索引分区。每个本地索引的分区只包含了它所关联的表分区的键和ROWID。本地索引可以是B树或位图索引。如果是B树索引,它可以是唯一或不唯一的索引。
这种类型的索引支持分区独立性,这就意味着对于单独的分区,可以进行增加、截取、删除、分割、脱机等处理,而不用同时删除或重建索引。Oracle自动维护这些本地索引。本地索引分区还可以被单独重建,而其他分区不会受到影响。
2.7.1.1 有前缀的索引
有前缀的索引包含了来自分区键的键,并把它们作为索引的前导。例如,让我们再次回顾participant表。在创建该表后,使用survey_id和survey_date这两个列进行范围分区,然后在survey_id列上建立一个有前缀的本地索引,如下图所示。这个索引的所有分区都被等价划分,就是说索引的分区都使用表的相同范围界限来创建。
技巧:本地的有前缀索引可以让Oracle快速剔除一些不必要的分区。也就是说没有包含WHERE条件子句中任何值的分区将不会被访问,这样也提高了语句的性能。
2.7.1.2 无前缀的索引
无前缀的索引并没有把分区键的前导列作为索引的前导列。若使用有同样分区键(survey_id和survey_date)的相同分区表,建立在survey_date列上的索引就是一个本地的无前缀索引,如下图所示。可以在表的任一列上创建本地无前缀索引,但索引的每个分区只包含表的相应分区的键值。
如果要把无前缀的索引设为唯一索引,这个索引就必须包含分区键的子集。在这个例子中,我们必须把包含survey和(或)survey_id的列进行组合(只要survey_id不是索引的第一列,它就是一个有前缀的索引)。
技巧:对于一个唯一的无前缀索引,它必须包含分区键的子集。
2.7.2. 全局分区索引
全局分区索引在一个索引分区中包含来自多个表分区的键。一个全局分区索引的分区键是分区表中不同的或指定一个范围的值。在创建全局分区索引时,必须定义分区键的范围和值。全局索引只能是B树索引。Oracle在默认情况下不会维护全局分区索引。如果一个分区被截取、增加、分割、删除等,就必须重建全局分区索引,除非在修改表时指定ALTER TABLE命令的UPDATE GLOBAL INDEXES子句。
2.7.2.1 有前缀的索引
通常,全局有前缀索引在底层表中没有经过对等分区。没有什么因素能限制索引的对等分区,但Oracle在生成查询计划或执行分区维护操作时,并不会充分利用对等分区。如果索引被对等分区,就必须把它创建为一个本地索引,这样Oracle可以维护这个索引,并使用它来删除不必要的分区,如下图所示。在该图的3个索引分区中,每个分区都包含指向多个表分区中行的索引条目。
分区的、全局有前缀索引
技巧:如果一个全局索引将被对等分区,就必须把它创建为一个本地索引,这样Oracle可以维护这个索引,并使用它来删除不必要的分区。
2.7.2.2 无前缀的索引
Oracle不支持无前缀的全局索引。
2.8 位图连接索引
位图连接索引是基于两个表的连接的位图索引,在数据仓库环境中使用这种索引改进连接维度表和事实表的查询的性能。创建位图连接索引时,标准方法是连接索引中常用的维度表和事实表。当用户在一次查询中结合查询事实表和维度表时,就不需要执行连接,因为在位图连接索引中已经有可用的连接结果。通过压缩位图连接索引中的ROWID进一步改进性能,并且减少访问数据所需的I/O数量。
创建位图连接索引时,指定涉及的两个表。相应的语法应该遵循如下模式:
create bitmap index FACT_DIM_COL_IDX on FACT(DIM.Descr_Col) from FACT, DIM
where FACT.JoinCol = DIM.JoinCol;
位图连接的语法比较特别,其中包含FROM子句和WHERE子句,并且引用两个单独的表。索引列通常是维度表中的描述列——就是说,如果维度是CUSTOMER,并且它的主键是CUSTOMER_ID,则通常索引Customer_Name这样的列。如果事实表名为SALES,可以使用如下的命令创建索引:
create bitmap index SALES_CUST_NAME_IDX
on SALES(CUSTOMER.Customer_Name) from SALES, CUSTOMER
where SALES.Customer_ID=CUSTOMER.Customer_ID;
如果用户接下来使用指定Customer_Name列值的WHERE子句查询SALES和CUSTOMER表,优化器就可以使用位图连接索引快速返回匹配连接条件和Customer_Name条件的行。
位图连接索引的使用一般会受到限制:
1)只可以索引维度表中的列。
2)用于连接的列必须是维度表中的主键或唯一约束;如果是复合主键,则必须使用连接中的每一列。
3)不可以对索引组织表创建位图连接索引,并且适用于常规位图索引的限制也适用于位图连接索引。
借鉴:https://blog.csdn.net/czh500/article/details/89464320
<同义词--SYNONYM>
create synonum mm for market_member;
select * from mm 与select * from market_member
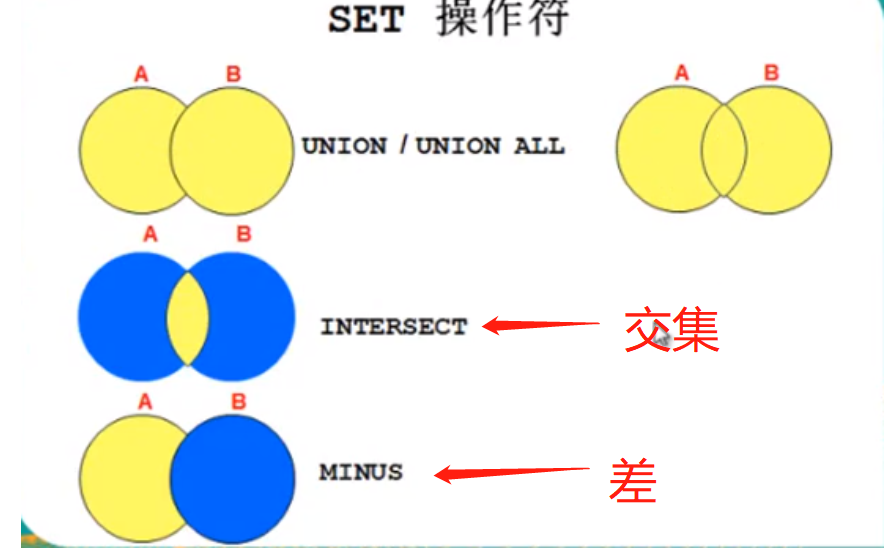
<SET操作>
<多列子查询>

<from 子句>
子查询的写法
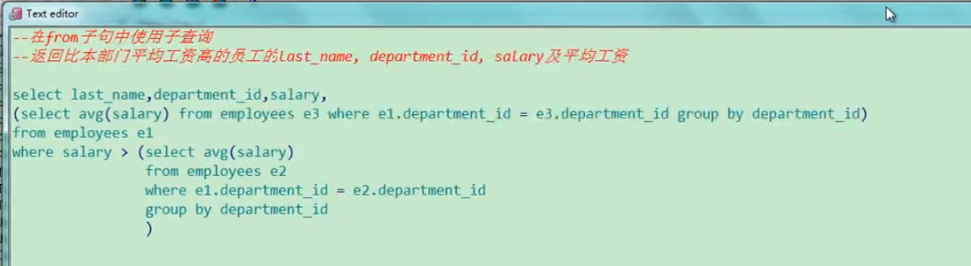
from子句的写法

<exists>
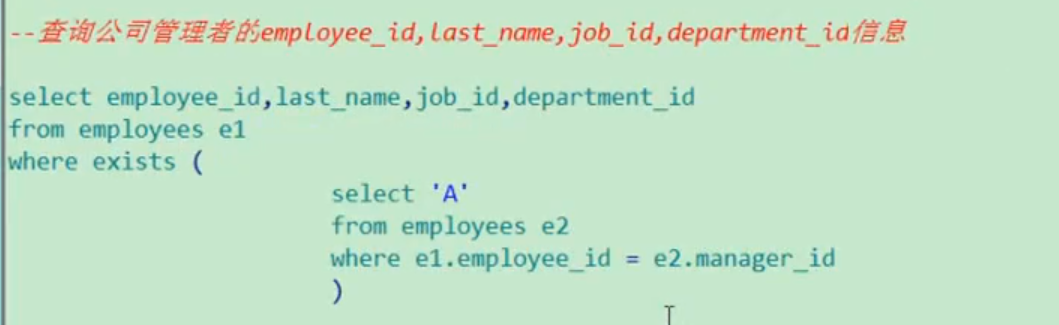
exist后面跟的子查询的select 的内容不重要,重点是判断子查询的false或者true,而且主句不用写具体的字段
<相关更新--寿光妇幼问的窦哥>
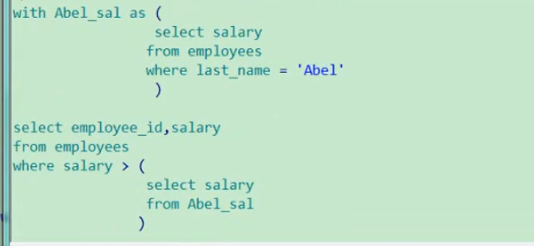
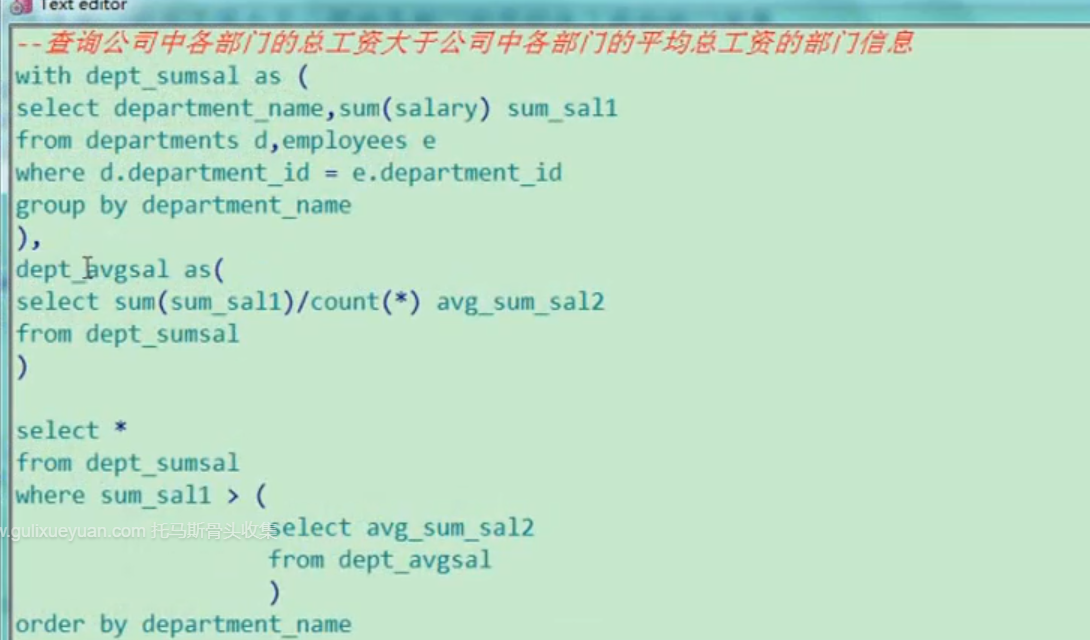
<with子句>
<流程控制语句>
if then
case when
<游标>
处理多行数据的事务一般用游标
--显示游标
1.定义游标
2.打开游标
3.提取游标数据
4.关闭游标
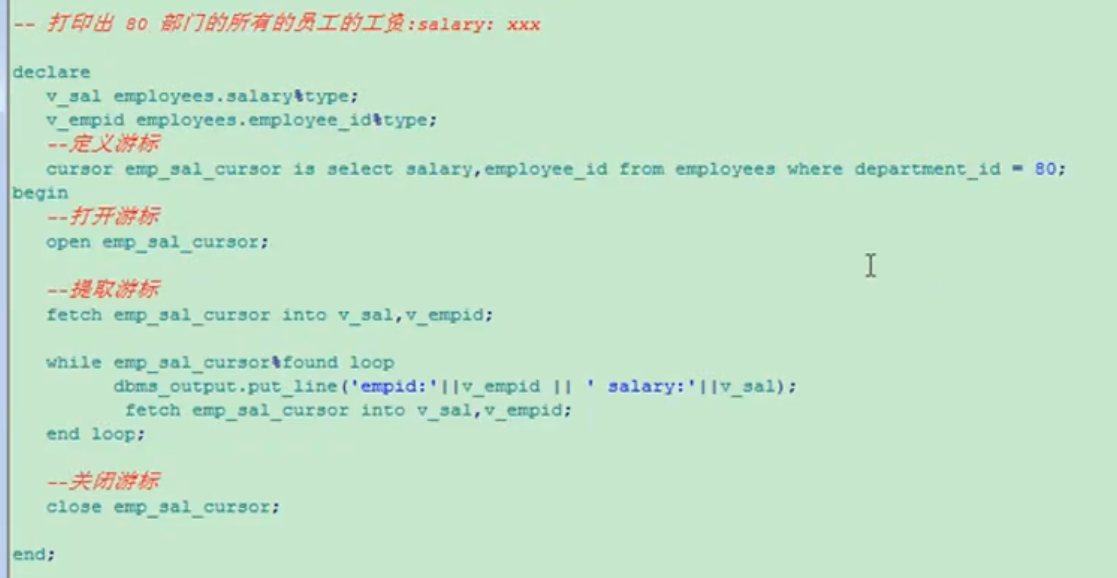
游标是SQL的一个内存工作区,由系统或用户以变量的形式定义。游标的作用就是用于临时存储从数据库中提取的数据块。在某些情况下,需要把数据从存放在磁盘的表中调到计算机内存中进行处理,最后将处理结果显示出来或最终写回数据库。这样数据处理的速度才会提高,否则频繁的磁盘数据交换会降低效率。
游标有两种类型:显式游标和隐式游标。我们常用到的SELECT...INTO...查询语句,一次只能从数据库中提取一行数据,对于这种形式的查询和DML操作,系统都会使用一个隐式游标。但是如果要提取多行数据,就要由程序员定义一个显式游标,并通过与游标有关的语句进行处理。显式游标对应一个返回结果为多行多列的SELECT语句。
游标一旦打开,数据就从数据库中传送到游标变量中,然后应用程序再从游标变量中分解出需要的数据,并进行处理。
隐式游标
如前所述,DML操作和单行SELECT语句会使用隐式游标,它们是:
* 插入操作:INSERT。
* 更新操作:UPDATE。
* 删除操作:DELETE。
* 单行查询操作:SELECT ... INTO ...。
当系统使用一个隐式游标时,可以通过隐式游标的属性来了解操作的状态和结果,进而控制程序的流程。隐式游标可以使用名字SQL来访问,但要注意,通过SQL游标名总是只能访问前一个DML操作或单行SELECT操作的游标属性。所以通常在刚刚执行完操作之后,立即使用SQL游标名来访问属性。游标的属性有四种,如下所示:
sql%found (布尔类型,默认值为null)
sql%notfound(布尔类型,默认值为null)
sql%rowcount(数值类型默认值为0)
sql%isopen(布尔类型)
当执行一条DML语句后,DML语句的结果保存在四个游标属性中,这些属性用于控制程序流程或者了解程序的状态。当运行DML语句时,PL/SQL打开一个内建游标并处理结果,游标是维护查询结果的内存中的一个区域,游标在运行DML语句时打开,完成后关闭。隐式游标只使用SQL%FOUND,SQL%NOTFOUND,SQL%ROWCOUNT三个属性.SQL%FOUND,SQL%NOTFOUND是布尔值,SQL%ROWCOUNT是整数值。
SQL%FOUND和SQL%NOTFOUND
在执行任何DML语句前SQL%FOUND和SQL%NOTFOUND的值都是NULL,在执行DML语句后,SQL%FOUND的属性值将是:
. TRUE :INSERT
. TRUE :DELETE和UPDATE,至少有一行被DELETE或UPDATE.
. TRUE :SELECT INTO至少返回一行
当SQL%FOUND为TRUE时,SQL%NOTFOUND为FALSE。
SQL%ROWCOUNT
在执行任何DML语句之前,SQL%ROWCOUNT的值都是NULL,对于SELECT INTO语句,如果执行成功,SQL%ROWCOUNT的值为1,如果没有成功或者没有操作(如update、insert、delete为0条),SQL%ROWCOUNT的值为0,而对于update和delete来说表示游标所检索数据库行的个数即更新或者删除的行数。
SQL%ISOPEN
SQL%ISOPEN是一个布尔值,如果游标打开,则为TRUE, 如果游标关闭,则为FALSE.对于隐式游标而言SQL%ISOPEN总是FALSE,这是因为隐式游标在DML语句执行时打开,结束时就立即关闭。
最后我们来说一下隐式游标中SELECT..INTO 语句,当执行的时候会有三种可能:
(1).结果集只含有一行,且select是成功的
(2).没有查询到任何结果集,引发NO_DATA_FOUND异常
(3).结果集中含有两行或者更多行,引发TOO_MANY_ROWS异常。
例子:

BEGIN
UPDATE exchangerate SET rate=7 where quarter='2011Q1';
DBMS_output.put_line('游标所影响的行数:'||SQL%rowcount);
if SQL%NotFound then
DBMS_output.put_line('NotFound为真');
DBMS_output.put_line('NofFound为假');
end if;
if SQL%Found then
DBMS_output.put_line('Found为真');
else
DBMS_output.put_line('Found为假');
end if;
if SQL%isopen then
DBMS_output.put_line('isOpen为真');
else
DBMS_output.put_line('isOpen为假');
end if;
END;
显式游标:
游标的定义和操作
游标的使用分成以下4个步骤。
1.声明游标
在DECLEAR部分按以下格式声明游标:
CURSOR 游标名[(参数1 数据类型[,参数2 数据类型...])]
IS SELECT语句;
参数是可选部分,所定义的参数可以出现在SELECT语句的WHERE子句中。如果定义了参数,则必须在打开游标时传递相应的实际参数。
SELECT语句是对表或视图的查询语句,甚至也可以是联合查询。可以带WHERE条件、ORDER BY或GROUP BY等子句,但不能使用INTO子句。在SELECT语句中可以使用在定义游标之前定义的变量。
2.打开游标
在可执行部分,按以下格式打开游标:
OPEN 游标名[(实际参数1[,实际参数2...])];
打开游标时,SELECT语句的查询结果就被传送到了游标工作区。
3.提取数据
在可执行部分,按以下格式将游标工作区中的数据取到变量中。提取操作必须在打开游标之后进行。
FETCH 游标名 INTO 变量名1[,变量名2...];
或
FETCH 游标名 INTO 记录变量;
游标打开后有一个指针指向数据区,FETCH语句一次返回指针所指的一行数据,要返回多行需重复执行,可以使用循环语句来实现。控制循环可以通过判断游标的属性来进行。
下面对这两种格式进行说明:
第一种格式中的变量名是用来从游标中接收数据的变量,需要事先定义。变量的个数和类型应与SELECT语句中的字段变量的个数和类型一致。
第二种格式一次将一行数据取到记录变量中,需要使用%ROWTYPE事先定义记录变量,这种形式使用起来比较方便,不必分别定义和使用多个变量。
定义记录变量的方法如下:
变量名 表名|游标名%ROWTYPE;
其中的表必须存在,游标名也必须先定义。
4.关闭游标
CLOSE 游标名;
显式游标打开后,必须显式地关闭。游标一旦关闭,游标占用的资源就被释放,游标变成无效,必须重新打开才能使用。
现在通过一个例子来学习一下显示游标的使用方法:
有一个表原来结构是如下的
create table EXCHANGERATE ( QUARTER VARCHAR2(20), RATE NUMBER(10,4), DESCRIPTION VARCHAR2(900), ID VARCHAR2(10) not null, CURRENCY VARCHAR2(100) )
这是一个汇率表里面维护着的是季度 币种和汇率的关系,现在有一个新的需求是在原来表的基础上增加一列名字为currentmonth,变为季度、季度中月份、 币种和汇率的关系,
并且使原来每个季度对应的币种和汇率变成每个季度 对应该季度月份 币种和汇率,每个月的默认值为原来季度对应的值。
例如 原来 2013Q2 CNY 6.2
现在我们要变为2013Q2 2013-04 CNY 6.2 2013Q2 2013-05 CNY 6.2
2013Q2 2013-06 CNY 6.2 三条记录。
通过分析以上需求,我们首先要增加一列:
alter table exchangerate add currentmonth varchar2(20);
然后我们通过在匿名块中通过显示游标来实现以上需求:
declare v_year varchar2(20); v_month number; p_rate exchangerate%rowtype;
cursor c_rate is select * from exchangerate t where t.currentmonth is null;
begin open c_rate; loop
fetch c_rate into p_rate; v_year:=substr(p_rate.quarter, 0, 4); v_month:=(to_number(substr(p_rate.quarter,6,1)) - 1) * 3;
for i in 1 .. 3 loop insert into exchangerate(id,quarter,currentmonth,rate,currency,Description)
values(SEQUENCE_EXCHANGERATE.nextval,p_rate.quarter,
to_char(to_date(v_year||(v_month+i),'yyyyMM'),'yyyy-MM'),p_rate.rate,p_rate.currency,p_rate.description); end loop;
exit when c_rate%notfound;
end loop;
close c_rate;
end; /
我们把上面的例子有游标的for循环来改写一下。
显式游标的for循环
declare
v_year varchar2(20);
v_month number;
cursor c_rate is select * from exchangerate t where t.currentmonth is null;
begin
for p_rate in c_rate loop
v_year:=substr(p_rate.quarter, 0, 4);
v_month:=(to_number(substr(p_rate.quarter,6,1)) - 1) * 3;
for i in 1 .. 3 loop
insert into exchangerate(id,quarter,currentmonth,rate,currency,Description)
values(SEQUENCE_EXCHANGERATE.nextval,p_rate.quarter,
to_char(to_date(v_year||(v_month+i),'yyyyMM'),'yyyy-MM'),p_rate.rate,p_rate.currency,p_rate.description);
end loop;
end loop;
end;
/
我们可以看到游标FOR循环确实很好的简化了游标的开发,我们不在需要open、fetch和close语句,不在需要用%FOUND属性检测是否到最后一条记录,这一切Oracle隐式的帮我们完成了。
隐式游标的for循环
declare v_year varchar2(20); v_month number; begin for p_rate in (select * from exchangerate t where t.currentmonth is null) loop v_year:=substr(p_rate.quarter, 0, 4); v_month:=(to_number(substr(p_rate.quarter,6,1)) - 1) * 3;
for i in 1 .. 3 loop insert into exchangerate(id,quarter,currentmonth,rate,currency,Description)
values(SEQUENCE_EXCHANGERATE.nextval,p_rate.quarter,
to_char(to_date(v_year||(v_month+i),'yyyyMM'),'yyyy-MM'),p_rate.rate,p_rate.currency,p_rate.description); end loop; end loop; end; /
显示游标中游标参数的传递
例子:就以上面的表来说 加入我们在定义游标时不确定查询条件中的值,这时我们可以通过游标参数来解决
declare v_year varchar2(20); v_month number; p_rate exchangerate%rowtype; cursor c_rate(p_quarter varchar2) --声明游标带参数
is
select * from exchangerate t where t.quarter<=p_quarter; begin open c_rate(p_quarter=>'2011Q3');--打开游标,传递参数值 loop fetch c_rate into p_rate; update exchangerate set rate=p_rate.rate+1 where id=p_rate.id; exit when c_rate%notfound; end loop; close c_rate; end;
游标变量
游标是数据库中一个命名的工作区,当游标被声明后,他就与一个固定的SQL想关联,在编译时刻是已知的,是静态的.它永远指向一个相同的查询工作区.
游标变量是动态的可以在运行时刻与不同的SQL语句关联,在运行时可以取不同的SQL语句.它可以引用不同的工作区.
如何定义游标类型
TYPE ref_type_name IS REF CURSOR
[RETURN return_type];
声明游标变量
cursor_name ref_type_name;
ref_type_name 是后面声明游标变量时要用到的我们的游标类型(自定义游标类型,即CURSOR是系统默认的,ref_type_name是我们定义的 );
return_type代表数据库表中的一行,或一个记录类型
TYPE ref_type_name IS REF CURSOR RETURN EMP%TYPE
RETURN 是可选的,如果有是强类型,可以减少错误,如果没有return是弱引用,有较好的灵活性.
游标变量的操作
例子:
declare
v_year varchar2(20);
v_month number;
p_rate exchangerate%rowtype;
type rate is ref cursor;--定义游标变量
c_rate rate; --声明游标变量
begin
open c_rate for select * from exchangerate t where t.quarter='2011Q3';--打开游标变量
loop
fetch c_rate into p_rate;--提取游标变量
update exchangerate set rate=p_rate.rate+1 where id=p_rate.id;
exit when c_rate%notfound;
end loop;
--将同一个游标变量对应到另一个SELECT语句
open c_rate for select * from exchangerate t where t.quarter='2011Q2';--打开游标变量
loop
fetch c_rate into p_rate;--提取游标变量
update exchangerate set rate=p_rate.rate-1 where id=p_rate.id;
exit when c_rate%notfound;
end loop;
close c_rate;--关闭游标变量
end;
游标表达式
Oracle在SQL语言中提供了一个强有力的工具:游标表达式。一个游标表达式从一个查询中返回一个内嵌的游标。在这个内嵌游标的结果集中,每一行数据包含了在SQL查询中的可允许的数值范围;它也能包含被其他子查询所产生的游标。
因此,你能够使用游标表达式来返回一个大的和复杂的,从一张或多张表获取的数据集合。游标表达式的复杂程度,取决于查询和结果集。然而,了解所有从Oracle RDBMS提取数据的可能途径,还有大有好处的。
你能够在以下任何一种情况使用游标表达式:
(1)、 显式游标声明
(2)、动态SQL查询。
(3)、REF CURSOR 声明和变量。
你不能在一个隐式查询中使用游标表达式。
游标表达式的语法是相当简单的:
CURSOR (查询语句)
当Oracle从父游标或外围游标那里检取包含游标表达式的数据行时,Oracle就会隐式地打开一个内嵌的游标,这个游标就是被上述的游标表达式所定义。在以下情况发生时,这个内迁游标将会被关闭:
(1)、你显式地关闭这个游标。
(2)、外围或父游标被重新执行,关闭或撤销。
(3)、当从父游标检取数据时,发生异常。内嵌游标就会与父游标一起被关闭。
使用游标表达式
你可以通过两种不同的,但是非常有用的方法来使用游标表达式:
1. 在一个外围查询中把字查询作为一列来检取数据。
2. 把一个查询转换成一个结果集,而这个结果集就可以被当成一个参数传递给一个流型或变换函数。
例子:
CREATE OR REPLACE PROCEDURE emp_report(p_locid NUMBER)
IS
TYPE refcursor IS REF CURSOR;
CURSOR all_in_one IS
SELECT l.city, CURSOR(
SELECT d.department_name, CURSOR (
SELECT e.last_name
FROM employees e
WHERE e.DEPARTMENT_ID = d.DEPARTMENT_ID
) as ename
FROM departments d
WHERE d.LOCATION_ID = l.LOCATION_ID
) as dname
FROM locations l
WHERE l.location_id = p_locid;
departments_cur refcursor;
employees_cur refcursor;
v_city locations.city%type;
v_dname departments.department_name%type;
v_ename employees.last_name%type;
i integer :=1;
j integer :=1;
k integer :=1;
BEGIN
OPEN all_in_one;
LOOP
FETCH all_in_one INTO v_city, departments_cur;
EXIT WHEN all_in_one%NOTFOUND;
LOOP
FETCH departments_cur INTO v_dname, employees_cur;
EXIT WHEN departments_cur%NOTFOUND;
LOOP
FETCH employees_cur INTO v_ename;
EXIT WHEN employees_cur%NOTFOUND;
dbms_output.put_line(i || ' , ' || j || ' , ' || k || '----' || v_city || ' ,' || v_dname || ' ,' || v_ename );
k := k + 1;
END LOOP;
j := j + 1;
END LOOP;
i := i + 1;
END LOOP;
END;
/
数据处理--DDL
创建表
1.直接命令创建
2.复制表结构
3,复制表结构及数据
数据处理
1)alter --add,modify,rename,drop
(1).ALTER TABLE (表名) ADD (列名 数据类型);
Alter Table Employ Add (weight Number(38,0)) ;
(2).ALTER TABLE (表名) MODIFY (列名 数据类型);
Alter Table Employ Modify (weight Number(13,2)) ;
(3).ALTER TABLE (表名) RENAME COLUMN (当前列名) TO (新列名); /不需要括号
Alter Table Emp Rename Cloumn weight To weight_new ;
(4)ALTER TABLE (当前表名) RENAME TO (新表名);
ALTER TABLE bouns RENAME TO bonus_new;
(5)
ALTER TABLE (表名) DROP COLUMN (列名);
ALTER TABLE emp DROP COLUMN weight_new ;
(6).alter USER user IDENTIFIEDBY ’newpassword’REPLACE ’oldpassword’;
2) DROP
DROP TABLE TABLE_NAME ;
3)truncate --无法回滚
DDL没法回滚,增删改可以回滚,即DML可以回滚
1.分组函数
max(),min(),avg(),count(),sum()
min(),max(),可以进行求最大值的类型有:日期、数值、字符
avg(),只能对字符进行处理,
分组函数不能使用where作为过滤,可以使用having对分组函数进行过滤
二、子查询
单行只查询--子查询的结果返回一个值,
常用的符号:=, >, <, <=, >=, <>,
多行只查询--子查询的结果返回多个值,
常用的符号:in ,any ,all

all相反,any是任一,all是任意(所有)
上面的子查询还可以写成 <(select min(salary) from employee where job_id='IT_PROG')
oracle的方法
oracle中的round()方法的用法
Round( ) 函数
-------------------------------------------------------------------------------------------
用between and截取日期段
select kfrq from ms_cf01 where kfrq between to_date('2017-11-1 00:00:00','yyyy-mm-dd hh24:mi:ss') and to_date('2017-11-06 23:59:59','yyyy-mm-dd hh24:mi:ss')
to_char(ghrq,'yyyy-mm-dd')='2016-03-28'
CASE WHEN b.brxb = 1 THEN '男' WHEN b.brxb = 2 THEN '女' end AS 性别,
round((SYSDATE - b.csny)/365) AS 年龄,
select sum(zjje) from v_zy_fymx where fyrq
>=to_date('2017-01-01 00:00:00','yyyy-mm-dd hh24:mi:ss')
and fyrq <to_date('2018-01-01 00:00:00','yyyy-mm-dd hh24:mi:ss') and YPLX=1 or YPLX=2