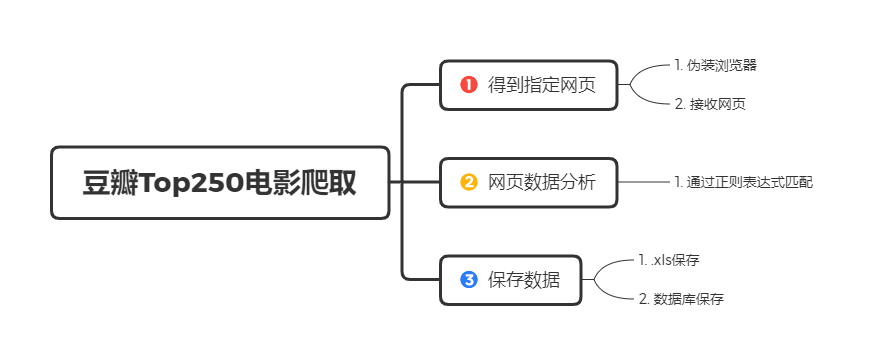
def saveData(datalist, savepath):
print("save....")
book = xlwt.Workbook(encoding="utf-8", style_compression=0) # 创建workbook对象
sheet = book.add_sheet('豆瓣电影Top250', cell_overwrite_ok=True) # 创建工作表
col = ("电影详情链接", "图片链接", "影片中文名", "影片外国名", "评分", "评价数", "概况", "相关信息")
for i in range(0, 8):
sheet.write(0, i, col[i]) # 列名
for i in range(0, 250):
print("第%d条" % (i + 1))
data = datalist[i]
for j in range(0, 8):
sheet.write(i + 1, j, data[j]) # 数据
book.save(savepath) # 保存
数据库保存
def saveData2DB(datalist, dbpath):
init_db(dbpath)
conn = sqlite3.connect(dbpath)
cur = conn.cursor()
for data in datalist:
for index in range(len(data)):
if index == 4 or index == 5:
continue
data[index] = '"' + data[index] + '"'
sql = '''
insert into movie250 (
info_link,pic_link,cname,ename,score,rated,instroduction,info)
values(%s)''' % ",".join(data)
print(sql)
cur.execute(sql)
conn.commit()
cur.close()
conn.close()
def init_db(dbpath):
sql = '''
create table movie250
(
id integer primary key autoincrement,
info_link text,
pic_link text,
cname varchar,
ename varchar,
score numeric ,
rated numeric ,
instroduction text,
info text
)
''' # 创建数据表
conn = sqlite3.connect(dbpath)
cursor = conn.cursor()
cursor.execute(sql)
conn.commit()
conn.close()
运行主函数
if __name__ == "__main__": # 当程序执行时
# 调用函数
main()
print("爬取完毕!")