目录
引子
读了关于可扩展前端讨论的一些文章,翻译记录。
原文:Scalable Frontend #1 — Architecture Fundamentals
正文
关于软件开发中“可扩展性”一词最常见的两个含义,与随着时间推移代码库的性能和可维护性有关。你可以同时拥有它们,但是注重良好的可维护性,可以让优化性能变的更容易,且不会影响应用程序其余部分。更重要的是在前端,与后端有一个重要的区别:本地状态。
在这个系列文章中,我们将讨论如何使用经过实际测试的方法,开发和维护一个可扩展的前端应用程序。我们大多数示例将使用 React 和 Redux ,但我们将经常与其他技术栈进行比较,展示如何达到相同的效果。让我们以讨论架构开始这个系列,这是你软件中最重要的部分。
软件架构是什么?
软件架构到底是什么?说它是软件中最重要的部分似乎有些虚夸,请容我继续说下去。
架构是你如何让软件的各个单元彼此合作,以强调必须要做出的最重要决策,并推迟次要决策和实现细节。设计软架构意味着将实际应用程序与其支持的技术脱离开来。你的实际应用程序不了解数据库、AJAX 请求或 GUI ;代替的是,由代表了你的软件所涵盖概念的用例和定义域单元组成,不考虑执行用例的参与者或数据持久化的位置。
关于架构,还有一些重要的事情要说:它不意味着文件组织,也不意味着你是如何命名文件和文件夹。
前端开发中的层次
区分什么是重要什么是次要的一种方式是使用分层,每一层都有不同具体的职责。基于分层的架构中,一种常见的方式是将其分为四层:应用层(application)、定义域层(domain)、基础设施层(infrastructure)和输入层(input)。这四层在文章 NodeJS and Good Practices 中有更好的解释。我们建议你在继续之前阅读该文章的第一部分。你不必阅读第二部分,因为它是关于 NodeJS 的。
定义域层和应用层在前端和后端之间没有什么不同,因为它们与技术无关,但我们对于输入层和基础设施层不能这么说。在 web 浏览器中,通常在输入层(视图)有一个参与者,因此我们甚至可以将其称为视图层 。另外,前端没有访问数据库或队列引擎的权限,因此我们在前端基础设施层中找不到这些。而我们将发现的是封装 AJAX 请求、浏览器 cookie 、LocalStorage 甚至与 WebSocket 服务器交互单元的抽象。主要的区别只是抽象的内容,所以你甚至可以拥有接口完全相同但底层技术不同的前端和后端存储库。你能想象一个好的抽象是多么的棒吗?
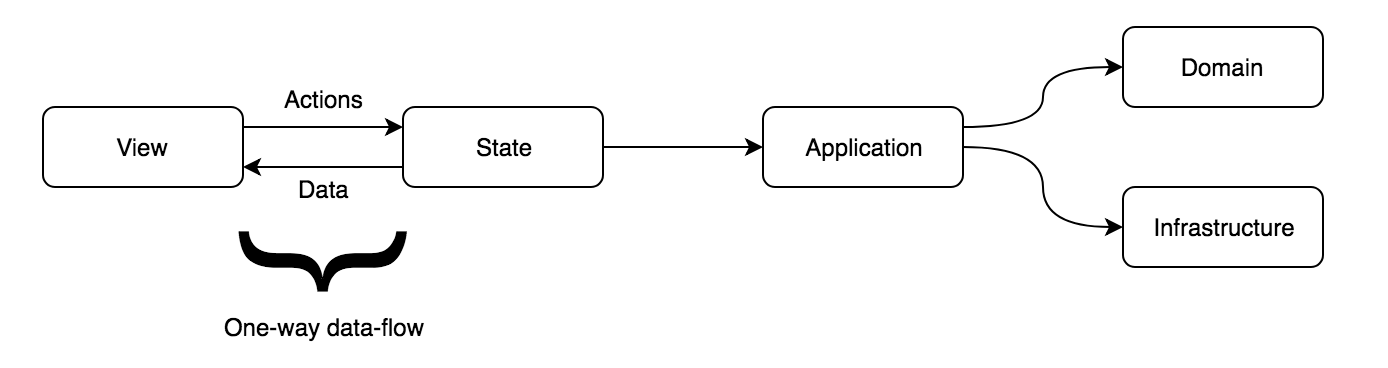
无论你是使用 React、Vue、Angular 还是其它工具来创建你的视图都没有关系。重要的是要遵循输入层没有任何逻辑的规则,这样将输入参数传递给下一层。对于基于分层架构的前端,还有另一个重要规则:要让输入/视图层始终与本地状态保持同步,你应该遵循单向数据流。这个词听上去熟悉吗?我们可以通过增加特定的第五层来实现这一点:状态,也称为存储。
状态层
当遵循单向数据流时,我们从不更改或转换从视图中直接接收的数据。代替的是,我们会从视图中分发“ actions ”。它是这样运行的:一个 action 向数据源发送一条消息,数据源更新自己,然后用新数据重新渲染视图。请注意,绝不会有从视图到存储的直接通道,因此如果两个子视图使用相同的数据,那么你就可以从其中任何一个子视图分发 action ,这都将导致它们用新数据重新渲染。看起来我是在专门讨论 React 和 Redux ,但并不是这样的;你可以用几乎所有现代前端框架或库,实现相同的效果,比如 React + context API、Vue + Vuex、Angular + NGXS ,甚至使用 Ember 的 data-down action-up 方法(又称 DDAU)。你甚至可以使用 jQuery 的事件系统发送 actions !
这一层负责管理前端本地和不断变化的状态,如从后端获取的数据、在前端创建但未持久化的临时数据,或请求状态等临时信息。如果你还在琢磨,这就是 actions 和它们对应负责更新状态的处理程序所在的层。
尽管在 actions 中能够直接看到带有业务规则和用例定义的代码库是很常见,但是如果你仔细阅读其它层的描述,会发现我们已经有了放置用例和业务规则的地方,而且并不是状态层。这是否意味着我们的 actions 现在成了用例?不!那么我们应该如何看待它们?
让我们思考一下…我们说过 actions 不是用例,我们已经有了一个层来放置用例。视图应该分发 actions ,它们接收来自视图的信息,将其交给用例,根据响应分发新的 actions ,最后更新状态—更新视图并结束单向数据流。现在 actions 听起来难道不像是控制器吗?它们不就是一个从视图中获取参数,传递给用例,并根据用例的结果进行响应的地方吗?你就是应该这样看待他们。这里不应该有复杂的逻辑或直接的 AJAX 调用,因为这些是另一层的职责。状态层应该只知道如何管理本地存储,仅此而已。
还有一个重要因素在起作用。由于状态层管理视图层使用的本地存储,你将注意到这两个存储以某种方式产生了耦合。状态层中只有一些数据只用于视图,例如一个布尔标志,表示如果一个请求仍处于挂起状态,那么视图就可以显示一个加载中的旋转器,这完全没有问题。不要因为这个而自责,你没必要过度概括状态层。
依赖注入(Dependency injection)
好的,分层很酷,但它们是如何相互通信的呢?我们如何使一个层依赖于另一个层而不产生耦合?有没有可能测试一个 action 的所有可能输出,而不执行它所委托的用例?是否可以在不触发 AJAX 调用的情况下测试用例?当然可以,我们可以通过依赖注入来实现。
依赖注入是一种在创建单元的过程中接收其耦合依赖项作为参数的技术。例如,在类的构造函数中接收类的依赖项,或者使用 React/Redux 将组件连接到存储数据,并将所需的数据和 actions 作为 props 注入。理论并不复杂,对吧?实践也不应该复杂,所以让我们以一个 React/Redux 应用程序作为例子。
我们刚刚说过,使用 React/Redux 连接是一种在视图和状态层之间实现依赖注入的方法,并且简单明了。但是我们之前也说过,actions 将业务逻辑委托给用例,那么我们如何将用例(应用层)注入到 actions(状态层)中呢?
让我们设想一下,你有一个对象,其中包含应用程序的每个用例的方法。这个对象通常被称为依赖容器。是的,这看起来很奇怪,而且不能很好地扩展,但这并不意味着用例的实现就在这个对象内部。这些只是委托给用例的方法,而用例的定义是在其它地方。在应用程序中,所有用例集中在一个对象,比分布在整个代码库中很难找到它们要好得多。有了这个对象,我们需要做的就是将它注入到 actions 中,让他们各自决定将触发什么用例,对吧?
如果你使用 redux-thunk ,那么使用 withExtraArgument 方法实现它非常简单,它允许你在每个 thunk 操作中将容器作为 getState 之后的第三个参数注入。如果你使用 redux-saga ,我们将容器作为 run 方法的第二个参数传递,这种方法应该是简单的。如果你使用 Ember 或 Angular ,那么内置的依赖注入机制应该就足够了。
这样做将使 actions 与用例解耦,因为你不需要在定义 actions 时,在每个文件中手动导入用例。此外,现在将 action 从用例中分开来测试非常简单:只需注入一个完全符合你需求的模拟用例即可。如果用例失败,你想测试用例失败时将调度什么 action 吗?注入一个总是失败的模拟用例,然后测试 action 如何响应它。不需要考虑实际用例是如何工作的。
好极了,我们已经将状态层注入到视图层,将应用程序层注入到状态层。剩下的呢?我们如何将依赖注入到用例中来构建依赖容器?这是一个重要的问题,并且有很多方法可以解决。首先,不要忘了检查你使用的框架是否内置了依赖注入,例如 Angular 或 Ember 。如果已内置,你就不应该自造。如果没有,你可以用两种方法来完成:手动完成,或者在一个包的协助下完成。
手动完成应该简单明了:
- 按照类或闭包定义你的单元,
- 先实例化那些没有依赖关系的,
- 实例化依赖于它们的对象,将它们作为参数传递,
- 复上述步骤,直到实例化了所有用例,
- 导出它们。
太抽象了?看看几个代码示例:
import api from './infra/api'; // has no dependencies
import { validateUser } from './domain/user'; // has no dependencies
import makeUserRepository from './infra/user/userRepository';
import makeArticleRepository from './infra/article/articleRepository';
import makeCreateUser from './app/user/createUser';
import makeGetArticle from './app/article/getArticle';
const userRepository = makeUserRepository({
api
});
const articleRepository = makeArticleRepository({
api
});
const createUser = makeCreateUser({
userRepository,
validateUser
});
const getArticle = makeGetArticle({
userRepository,
articleRepository
});
export {
createUser,
getArticle
};
export default ({ validateUser, userRepository }) => async (userData) => {
if(!validateUser(userData)) {
throw new Error('Invalid user');
}
try {
const user = await userRepository.add(userData);
return user;
} catch(error) {
throw error;
}
};
export default ({ api }) => ({
async add(userData) {
const user = await api.post('/users', userData);
return user;
}
});
你将注意到,重要的部分——用例,在文件末尾被实例化,并作为一个单独对象被导出,因为它们将被注入到 actions 中。其余的代码不需要知道存储库是如何创建和工作的。这并不重要,只是一个技术细节。对于用例来说,存储库是否发送 AJAX 请求或在 LocalStorage 中持久化某些内容并不重要;这些并不是用例的职责。如果你希望在 API 仍处于开发阶段时使用 LocalStorage ,之后再切换到对在线 API 的调用,那么只要与 API 通信的代码,和与 LocalStorage 通信的代码遵循相同的接口,就不需要更改用例。
你可以像上面所描述的那样,很好的手动执行注入,即使你有几十个用例、存储库、服务等等。如果构建所有依赖关系变得太混乱,只要不增加耦合,你就可以始终使用依赖注入包。
测试你的 DI 包是否足够好的一个经验法则是,检查从手动方法切换到使用库是否只需要接触容器代码。如果不是,那么这个包就过于入侵,你应该选择一个不同的包。如果你真的想使用包,我们推荐 Awilix 。它的使用非常简单,脱离手动方式只需要接触容器文件。这里有由包的作者编写的一系列好文章介绍如何和为什么使用它。
接下来
好了,我们已经讨论了架构以及如何以一种好的方式连接层!在下一篇文章中,我们将展示一些真正的代码和刚刚谈到的层的通用模式,除了状态层,它将在另一篇文章中介绍。花些时间来吸收这些概念;当我们深入了解这些模式时,它们会很有用,一切都会更有意义。再见!
推荐链接
- NodeJS and Good Practices
- Bob Martin — Architecture the Lost Years
- Rebecca Wirfs-Brock — Why We Need Architects (and Architecture) on Agile Projects
- Domain-Driven Design