最近服务端开发需要用Log系统,于是研究了下APACHE下的Log框架。
目前日志系统,支持的语言有C++,PHP,.NET,JAVA。当然我是用Java服务端,选择用log4j吧。但突然发现log4j 2比较有趣,官网也提到性能上有比1.X有更大的提升,关于log4j的文章网上有很多了。
那么我们就来学习下log4j 2吧。
至于个人的选择,我有时候不太喜欢使用调试器。原因之一是因为它复杂数据结构和控制流程的细节需要让我去思考;特别是单步跟踪更麻烦,点击语句和思考花费的时间耗费更多。
如果用输出的话,则需要较少的时间来决定在哪里把打印语句,而不是去思考单步代码的关键部分和使用快捷键去单步调试。更重要的是,调试语句留在程序中;调试会话是短暂的。
Logging确实有它的缺点。它可以使应用程序变得更慢。如果太详细,可能会导致滚动越界,而看不到全部的。为了减轻这些影响,log4j被设计为是可靠的,快速的和可扩展的
LOG4J™ 2
log4j的1.x中已被广泛采用并在许多应用中使用。然而,经过多年的发展上有所放缓。由于其需要严格遵守非常老版本的Java,它变得更难以维持。其办法,SLF4J/ Logback向框架许多需要改进。那么,为什么有Log4j 2呢?这里有几个原因。
1.Log4j 2被设计作为审计日志框架。Log4j1.x和Logback在失去events 时而重新配置。 Log4j 2不会。在Logback的Appenders中异常应用程序中是绝对看不到的。在Log4j 2中Appenders可以被配置为允许异常渗到应用
2.Log4j 2包含LMAX Disruptor库基础上的下一代无锁异步Loggers 。在多线程情况下异步Loggers 具有10倍的吞吐量和比Log4j1.x和Logback幅度更低的延迟。
3.Log4j 2采用了插件系统,添加新的Appenders, Filters, Layouts, Lookups, 和Pattern Converters更加容易。
4.由于插件的系统配置简单。Entries 配置中不需要指的类名。
5.支持Message对象。Message允许的有趣和复杂的结构支持,通过日志系统传递有效地操作。用户可以自由创建自己的消息类型和编写自定义的 Layouts, Filters ,Lookups并操作他们。
6.Log4j的1.x的支持上的Appender的过滤器。 Logback加入TurboFilters允许由一个Logger处理的事件之前进行过滤。Log4j 2支持可配置为由一个Logger处理之前处理事件,因为它们是由一个Logger或Appenders处理。
7.许多Logback的Appender不接受Layouts,并且只发送数据的固定格式。大多数的Log4j 2Appenders接受Layouts,允许数据在所需的任何格式来传送。
8.在Log4j的1.x和Logback布局返回一个String。这导致了在Logback编码器讨论的问题。 Log4j 2采用了更简单的方法,布局总是返回一个字节数组。这具有它意味着他们可以在几乎任何追加程序被使用,而不是仅写入到OutputStream的优点。
9.系统日志的Appender同时支持TCP和UDP以及支持BSD的系统日志和RFC5424格式。
10.Log4j的2利用了Java 5的并发支持的优势,进行以尽可能低的水平锁定。 Log4j的1.x中已经知道死锁问题。其中许多是固定的Logback但许多Logback类仍然需要在相当高的水平同步。
架构
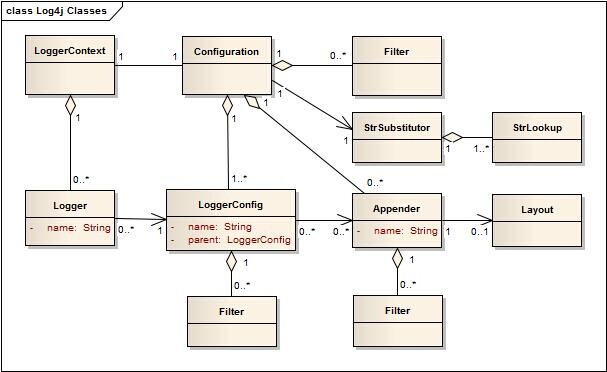
Logger层级
通过纯System.out.println是任何日志API的第一个也是最重要的优点,在于它能够关闭一些调试,让别人顺利打印。这种能力假定日志空间,即所有可能的记录语句的空间,根据开发者选择的标准进行分类。
在Log4j的1.x中的Logger层次结构是通过Loggers之间的关系维护。在Log4j的2.x版本中这种关系不再存在。替代的是,该层次结构被保持在LoggerConfig对象之间的关系。
Loggers和LoggerConfigs被称为实体(entities)。Loggers名称是区分大小写的,他们按照分层的命名规则:命名层次跟java包名类似,如
例如,命名为“com.foo”的LoggerConfig是名为“com.foo.Bar”LoggerConfig的父类。同样,“Java”的是“java.util中的”和“java.util.Vector中”的祖先的父母。这种命名方式应该是开发人员最熟悉的。
根LoggerConfig驻留在LoggerConfig层次结构的顶部。它的特点在于它总是存在,这是每一个层次结构的一部分。直接链接到根LoggerConfig的Logger代码如下:
Logger logger = LogManager.getLogger(LogManager.ROOT_LOGGER_NAME);
或者,更简单地:
Logger logger = LogManager.getRootLogger();
所有其他的Logger可以使用LogManager.getLogger静态方法通过使所需Logger的名称进行检索。在Log4j的2.x中可以查到更多API信息。
LoggerContext
该LoggerContext作为锚点的记录系统。然而,也可以有多个活动LoggerContexts,这要看应用情况而定。在LoggerContext更多细节在日志分离( Log Separation )的部分。
配置
每个LoggerContext有一个活跃的配置。配置包含了所有的附加目的地,上下文范围过滤器,LoggerConfigs并包含参考StrSubstitutor。在重新配置过程中有两个Configuration 对象将存在。一旦所有的Logger都被重定向到新的配置,旧的配置将被停止,并丢弃。
Logger
Loggers 通过调用LogManager.getLogger创建。该Logger本身不执行任何直接的动作。它只是一个名字,并和LoggerConfig有关。它扩展AbstractLogger并实现所需的方法。通过配置修改Logger可以和不同LoggerConfig关联的,从而导致需要修改其行为。
调用LogManager.getLogger方法具有相同的名字总是会返回一个引用完全相同的Logger对象。
例如,在
Logger X = LogManager.getLogger(“jy02432443”);
Logger Y = LogManager.getLogger(“jy02432443”);
x和y是指完全相同的Logger对象,可以用==。
log4j的环境配置通常是在应用程序初始化的时候。首选的方法是通过读取配置文件。这个在配置章节已经讨论过了。
Log4j中可以很容易地为Logger软件组件命名。这可以通过在每类中实例化一个Logger,与Logger名称相同的类的完全限定名来完成(如tl.lan或org.lan)。这是定义Logger的有效和直接的方法。
作为日志输出带有产生日志Logger的名字,这个命名策略可以很容易地识别出日志信息的来源。 Log4j的不限制尽可能多的Logger。开发人员可以自由根据需要来命名Logger。
一般用类的名字命名Logger比较常见,方便的方法LogManager.getLogger(Object.class)设置为自动使用调用类的完全限定类名作为Logger的名字。
该类它们所在的位置来命名Logger似乎是目前已知的最好的策略。
LoggerConfig
当Logger中的日志记录配置被声明时候时就会创建LoggerConfig对象。该LoggerConfig包含了一组过滤器必须允许LogEvent可以通过之前,它会被传递给任何附加Appenders。它包含对应该用于处理该事件的一组Appenders。
Log Levels(级别)
LoggerConfigs将被分配一个日志级别。一组内置的级别,包括TRACE,DEBUG,INFO,WARN,ERROR和FATAL。Log4j的2.x还支持自定义日志级别(custom log levels)。另一种机制是使用Markers来获得更多的粒度。
Log4j的1.x和Logback都有“Level继承”的概念。在Log4j的2.x版本中,Loggers 和LoggerConfigs是两个不同的对象,所以这个概念的实现方式不同。每个Loggers 参考相应LoggerConfig,反过来又可以参照其父类,从而达到相同的效果。
下面是五个表与各分配的level值,这将与每个Logger相关联所产生的level。请注意,在所有这些情况下,如果根LoggerConfig未配置,被分配默认level将给它。
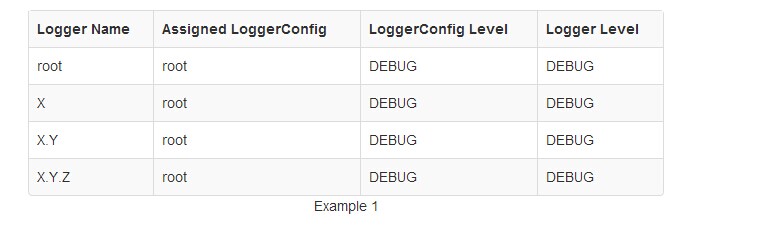
在例1中,只有根Logger的配置和具有日志级别。所有其它Logger引用根LoggerConfig和使用它的级别。
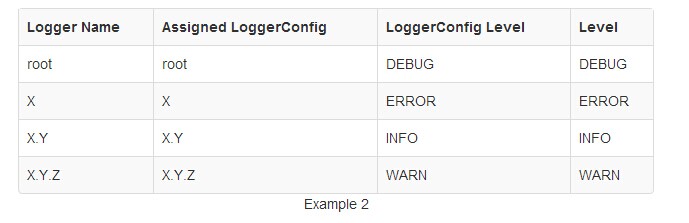
在例2中,所有的Logger有一个配置LoggerConfig,并从中获得自己的level。
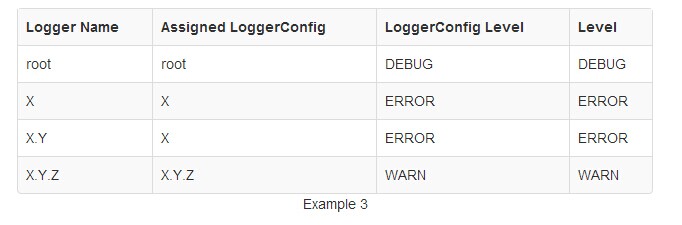
在示例3中,Loggers root中,X和XYZ各自具有LoggerConfig,并且相同的名称。在XY loggers 没有配置LoggerConfig匹配名称,它使用LoggerConfig X的配置,因为那是LoggerConfig其名称的Logger的首要名字。
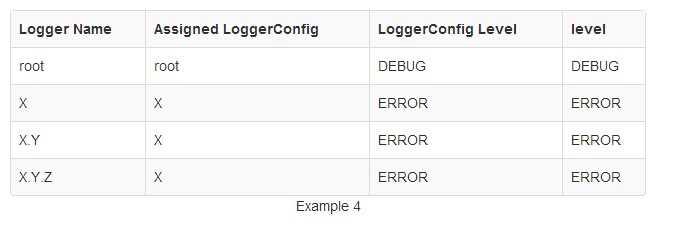
在例4中,Logger root和X每个已配置LoggerConfig具有相同的名称。该Logger XY和XYZ没有配置LoggerConfigs,同样的道理,因为它是LoggerConfig其名称具有最长匹配的Logger的名字开始,就是跟X一样的级别。
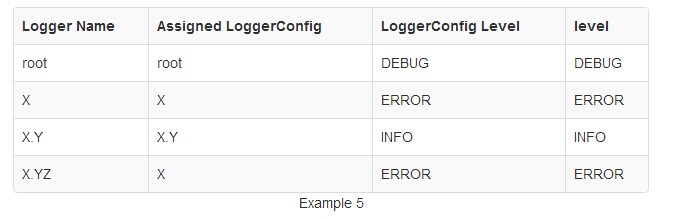
在例5中,loggers root.X和XY每个已配置LoggerConfig具有相同的名称。该记录仪X.YZ没有配置LoggerConfig等会从分配给它的LoggerConfig X的级别
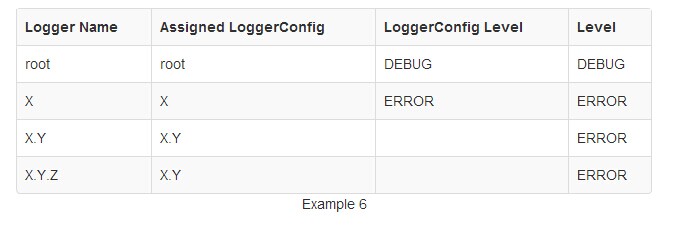
在例6,LoggerConfig XY它没有配置级别,它继承了LoggerConfig X,Logger的XYZ 继承LoggerConfig XY,但XY不具有LoggerConfig一个完全匹配的名字,所以它也继承了LoggerConfig X日志记录级别。
下面这张图是事件级别和config级别的参照

过滤器
除了自动日志级别过滤如前节所述,发生的是,log4j提供了一个 Filters来控制,再LoggerConfig之后和调用Appenders之前。非常相似防火墙过滤器,每个过滤器可以返回三种结果之一,接受,拒绝或中立。接受的响应意味着,没有其它的滤镜应该叫和事件应该处理。拒绝的应答装置的情况下,应立即忽略和控制应返回给调用者。中立的响应表示事件应传递给其他的过滤器。如果没有其他过滤器的事件将被处理。
Appender
以选择性地启用或禁用根据其Logger记录的请求的能力是图片的一部分。在Log4j允许日志请求打印到多个目的地。在log4j的说话,输出目的地叫做Appender的。目前,追加程序的控制台,文件,远程套接字服务器,Apache Flume,JMS,远程UNIX系统日志守护
进程和各种数据库的API。可以参考Appenders类查询可用的详细信息。一个Logger可以附加一个或多个Appender。
一个appender可以通过调用当前配置的addLoggerAppender方法将其添加到Logger。如果LoggerConfig匹配Logger的名称不存在,则创建的Appender并将它附属到Logger上,然后所有的Logger将被通知更新他们的LoggerConfig引用。
如果一个控制台appender被添加到根Logger,此时所有的日志请求至少会在控制台上打印。如果另外一个File appender添加到LoggerConfig,如C,则启用了C和C的孩子会在一个文件中产生日志,同时也在控制台上打印。它可以覆盖此默认行为,除非你使
用additivity="false",具体可参加下面的表格

Logger默认情况下additivity="true"。
布局(Layout)
通常情况下,用户想自定义,不仅是输出目的地,而且输出格式。这是通过与相关联的Appender中添加一个布局(Layout)完成。布局负责根据用户的意愿格式化的LogEvent,而一个appender负责发送格式化输出到目的地。 PatternLayout是标准的log4j发行版的一部分,可以让用户根据类似于C语言中的printf函数的转换模式指定输出格式。
例如,在转换模式的PatternLayout“%r [%t] %-5p %c - %m%n”会输出一个类似于:
176 [main] INFO org.foo.Bar - Located nearest gas station.
第一个字段是毫秒,因为该程序开始经过的毫秒数。第二个是产生记录请求的线程。第三个是日志表的级别。第四个是与日志请求相关联的Logger的名称。 “ - ”后的文本是具体的输出内容。
Log4j的附带了许多不同的布局对各种用例,如JSON,XML,HTML和Syslog(包括新的RFC5424版本)。
同样重要的是,log4j将根据用户指定的标准,使日志消息的内容。例如,如果您经常需要登录橙子,在当前项目中使用的对象类型,那么你可以创建一个接受一个橙子实例的OrangeMessage并传递给Log4j的,这样的橙子对象可以被格式化成一个合适的字节数组时
从Log4j的1.x迁移到Log4j的2.x
http://logging.apache.org/log4j/2.x/manual/migration.html
Log4j 2 API
http://logging.apache.org/log4j/2.x/manual/api.html
程序流程跟踪输出参考
http://logging.apache.org/log4j/2.x/manual/flowtracing.html
数据库跟踪输出参考
http://logging.apache.org/log4j/2.x/manual/markers.html
配置Log4j的2.0x版本
http://logging.apache.org/log4j/2.x/manual/configuration.html
配置比较重要,如果英语看不蛮懂的,我做下简单描述。
1.代码启动的时候设置System.setProperty("log4j.configurationFile", "log4j2.xml"); log4j2.xml文件名随意,扩展名别改。xml文件放在src目录下即可
2.如果没有设置配置文件新建ConfigurationFactory,实现接口生成DefaultConfiguration,默认配置中有
一个ConsoleAppender附属于根logger。
一个PatternLayout设置模式“%d个{HH:MM:SS.SSS}[%T]%-5level%记录器{36} - %MSG%N”连接到ConsoleAppender
请注意,在默认情况下的Log4j指定根记录器位Level.ERROR。默认情况下的配置等同于如下XML配置
<?xml version="1.0" encoding="UTF-8"?> <Configuration status="WARN"> <Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d{HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n"/> </Console> </Appenders> <Loggers> <Root level="error"> <AppenderRef ref="Console"/> </Root> </Loggers> </Configuration>
比如你在代码中加入logger.trace,上面的配置是不会输出的,但吧Root level="trace"就可以显示了,这里需要上面的参考事件级别和config级别的对应图。但也有可能两个包下都有trace,但你只想某个包中显示trace。其他情况都是error级别你可以这么配置
<logger name="com.foo.Bar" level="TRACE"/> <Root level="ERROR"> <AppenderRef ref="STDOUT"> </Root>
但是如果你这么配置
<?xml version="1.0" encoding="UTF-8"?> <Configuration status="WARN"> <Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d{HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n"/> </Console> </Appenders> <Loggers> <Logger name="com.foo.Bar" level="trace"> <AppenderRef ref="Console"/> </Logger> <Root level="error"> <AppenderRef ref="Console"/> </Root> </Loggers> </Configuration>
com.foo.Bar跟踪消息会出现两次。这是因为第一次使用Logger “com.foo.Bar”相关的appender ,首先输出到控制台。接着,“com.foo.Bar”,的父类是根logger,被引用。该事件被传递给它的appender,它也是写入到控制台,从而导致二个实例。这是被称为可加性。虽然说是相当方便的功能,在许多情况下,这种行为被认为是不可取的,因此可以通过对记录器设置加属性来禁用它:
<?xml version="1.0" encoding="UTF-8"?> <Configuration status="WARN"> <Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d{HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n"/> </Console> </Appenders> <Loggers> <Logger name="com.foo.Bar" level="trace" additivity="false"> <AppenderRef ref="Console"/> </Logger> <Root level="error"> <AppenderRef ref="Console"/> </Root> </Loggers> </Configuration>
一旦事件到达其加设置为false的事件log,那么将不会被传递给任何其父log,无论父log如何设置additivity。
下面是正常模式下的XML结构
<?xml version="1.0" encoding="UTF-8"?>; <Configuration> <Properties> <Property name="name1">value</property> <Property name="name2" value="value2"/> </Properties> <Filter type="type" ... /> <Appenders> <Appender type="type" name="name"> <Filter type="type" ... /> </Appender> ... </Appenders> <Loggers> <Logger name="name1"> <Filter type="type" ... /> </Logger> ... <Root level="level"> <AppenderRef ref="name"/> </Root> </Loggers> </Configuration>
例如ConsoleAppender类可以使用这样的组合
<Appender type="Console" name="name"> <Filter type="type" ... /> </Appender>
当然最建议大家还是使用强制模式,语法比较严格,如下面的XML所示:
<?xml version="1.0" encoding="UTF-8"?> <Configuration status="debug" strict="true" name="XMLConfigTest" packages="org.apache.logging.log4j.test"> <Properties> <Property name="filename">target/test.log</Property> </Properties> <Filter type="ThresholdFilter" level="trace"/> <Appenders> <Appender type="Console" name="STDOUT"> <Layout type="PatternLayout" pattern="%m MDC%X%n"/> <Filters> <Filter type="MarkerFilter" marker="FLOW" onMatch="DENY" onMismatch="NEUTRAL"/> <Filter type="MarkerFilter" marker="EXCEPTION" onMatch="DENY" onMismatch="ACCEPT"/> </Filters> </Appender> <Appender type="Console" name="FLOW"> <Layout type="PatternLayout" pattern="%C{1}.%M %m %ex%n"/><!-- class and line number --> <Filters> <Filter type="MarkerFilter" marker="FLOW" onMatch="ACCEPT" onMismatch="NEUTRAL"/> <Filter type="MarkerFilter" marker="EXCEPTION" onMatch="ACCEPT" onMismatch="DENY"/> </Filters> </Appender> <Appender type="File" name="File" fileName="${filename}"> <Layout type="PatternLayout"> <Pattern>%d %p %C{1.} [%t] %m%n</Pattern> </Layout> </Appender> <Appender type="List" name="List"> </Appender> </Appenders> <Loggers> <Logger name="org.apache.logging.log4j.test1" level="debug" additivity="false"> <Filter type="ThreadContextMapFilter"> <KeyValuePair key="test" value="123"/> </Filter> <AppenderRef ref="STDOUT"/> </Logger> <Logger name="org.apache.logging.log4j.test2" level="debug" additivity="false"> <AppenderRef ref="File"/> </Logger> <Root level="trace"> <AppenderRef ref="List"/> </Root> </Loggers>