了解系列废话:
数据管理系统实现,以Greenplum作为课后实验,这里将实验报告贴出来,纯粹灌水。
1.Greenplum架构
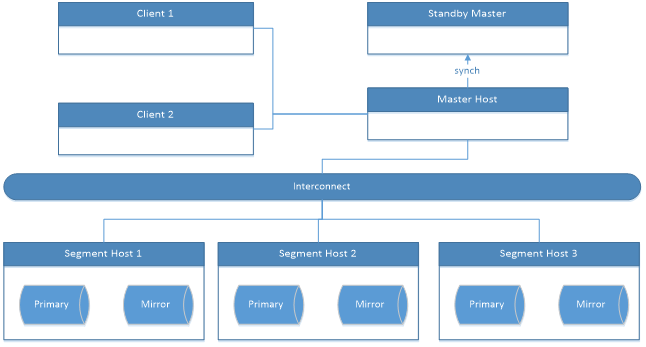
如上图所示,GP的基本结构是单master,多slave节点,客户端连接到master节点,master节点可以配置一个备机。多个segment节点都有主备两个数据区,镜像数据区存放的的是其他segment上的数据,只是目前看来,GP允许一个segment的失效,若有多个节点失效,有可能有的数据找不到镜像。节点间并不共享使用数据,而是通过internect模块相互通信。所有的客户端都是连接到master节点上,因此为了降低master的负载,master上执行的动作不会太多,只负责执行计划生成、分发、收集结果,数据字典管理,不承担数据的处理,存放等。Segment负责业务数据的存取、执行master发送过来的sql语句,彼此间对等。
2.Greenplum基本使用
首先根据教程安装好GP系统,参考了网络上的一篇博客教程:Greenplum 源码安装教程 —— 以 CentOS 平台为例http://www.cnblogs.com/arthurqin/p/5849354.html
GP安装好,并使用gpinitsystem 命令完成初始化之后,使用 psql -d postgres 可以开始使用GP。GP有一些基本命令如下:
GP服务启停
gpstart :启动GP服务。当虚拟机关闭重新登录时需要此命令。
gpstop :关闭GP服务。
gpstop -M fast :快速关闭。
gpstop –r :重启。
gpstop –u :重新加载配置文件。
登录与退出GP客户端
登录:
psql databasename
psql -d databasename -h hostname -p port -U gpusername
退出: q
查看系统库版本

数据库基本操作
创建、删除数据库
在GP初始化系统后,GP会自动创建出三个数据库postgre,template0,template1.
其中postgre用作系统内部数据的存放,既不要删除它,也不要修改它。template1是系统默认的数据,创建数据库时可以以template1为模板,创建新的数据库。template0数据库是创建template1的模板。
命令:CREATE DATABASE dbname ; DROP DATABASE dbname;
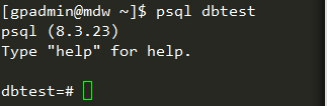
GP基本sql语法
创建简单的表
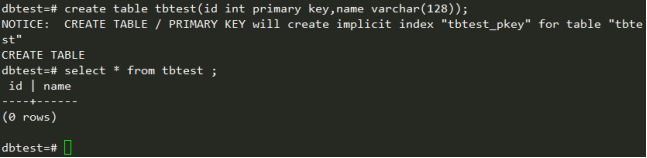
列出数据库中所有的表
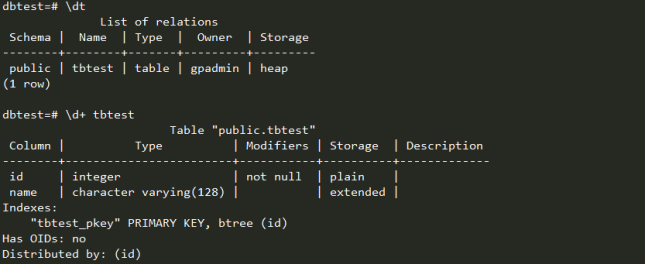
查看查询计划
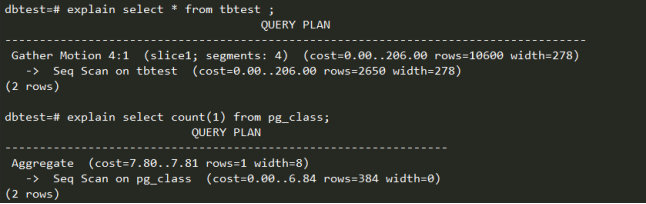
基本SQL语法查看方式,使用帮助
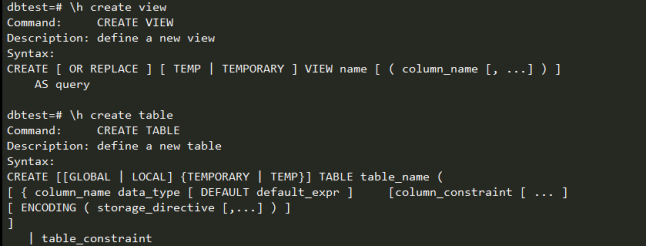
GP的SQL语法特殊说明:
A.Create table:
GP的建表语句与通常的数据库语句基本一致,但是作为分布式数据库,有一些不同的地方。 1.建表时需要制定分布键distributed by,用以散列数据到不同的segment节点;2.partition by用某个字段将表建成分区表;3.like操作创建与like的表一样的结构;4.inherits可实现表的继承。
B.SELECT
GP的select语句,与普通数据库语句一样,但是可以不指定from语句,执行函数和简单的计算。在没有添加order by子句的时候,select的结果不能保证顺序,并且两次查询的结果也不一定是一样的。
查看数据分布

C.INSERT、UPDATE/DELETE
与标准Sql用法相同。Insert语句分布键要为空,否则数据都被保存在一个节点上,造成数据分布不均匀。Insert采用批量操作,可以提升执行速度,如isnert into values(),(),()。Update 不能对分布键进行更新。 Delete 在4.3版本中支持设计子查询语句,且子查询的结果设计数据重分布。TRUNCATE直接删除物理文件,然后重建新数据文件,对整张表删除更快,例truncate tbname。



3.Greenplum系统表含义
pg_class:
GP数据字典中最重要的一个系统表,保存着所有的表、试图、索引的元数据信息,每个DDL/DML操作都必须跟这个表发送联系。
|
字段 |
类型 |
引用 |
字段说明 |
|
oid |
oid |
|
pg_class中的唯一标识 |
|
relname |
name |
|
表、索引、视图等的名称 |
|
relnamespace |
oid |
pg_namespace.oid |
包含这个关系的名字空间的oid |
|
reltype |
oid |
pg_type.oid |
对应这个表的行类型的数据类型(索引为0,没有此项) |
|
relowner |
oid |
pg_authid.oid |
关系的所有者 |
|
Relam |
oid |
pg_am.oid |
索引的访问模式(B-tree/hash等) |
|
Reltuples |
float4 |
|
表中行的数目。估计值。 |
|
relhasindex |
bool |
|
是表且至少有一个索引为true |
|
relkind |
char |
|
r=普通表或appendonly表,i=索引,s=序列,v=视图,c=复合类型,t=TOAST表,o=内存appendonly文件,u=未列入目录的临时表。 |
|
relnatts |
Int2 |
|
关系中用户字段数目(除了关系中的系统字段)。 |
|
relacl |
Aclitem[] |
|
访问权限 |
pg_atrribute:
这个表记录了关系的字段的内容。表中实际上有一些隐藏字段如记录; 数据保存在哪个segment上的gp_segment_id。
|
字段 |
类型 |
引用 |
字段说明 |
|
attrelid |
oid |
pg_class.oid |
此字段所属的表 |
|
attname |
name |
|
字段名称 |
|
atttype |
oid |
pg_type.oid |
此字段的数据类型 |
|
attstattarget |
int4 |
|
控制ANALYZE为这个字段积累的统计细节的级别。0表示不收集统计信息。 |
|
attlen |
Int2 |
|
pg_type.typlen的副本 |
|
attnum |
int2 |
|
字段数目。从1开始计数 |
|
attisdropped |
bool |
|
字段删除标记 |
|
attnonull |
bool |
|
非空约束 |
|
attndims |
int4 |
|
字段为数组,表示维数。 |
gp_distribution_policy:
保存着表的分布键。
|
字段名 |
引用 |
字段说明 |
|
localoid |
pg_class.oid |
表的oid |
|
ocaloid |
pg_attribute.attnum |
保存分布键对应的attnum的一个数组 |
pg_stats:
数据库中表的统计信息保存在pg_statistic,由ANALYZE创建记录。在这个表pg_statistic的上面有一个视图pg_stats;
|
字段 |
类型 |
引用 |
字段说明 |
|
schemaname |
name |
pg_namespace.nspname |
包含此表的的模式名称(名字空间) |
|
tablename |
name |
pg_class.relname |
表的名称 |
|
attname |
name |
pg_attribute.attname |
这一条记录描述的字段的名称 |
|
null_frace |
real |
|
记录中字段为空的百分比 |
|
avg_width |
integer |
|
记录以字节为单位的平均宽度 |
|
most_common_vals |
anyarray |
|
一个字段中最常用数值的列表。没有数值比较常见则为NULL。 |
4.参考
关于GP的参考资料,首先最好的当然是去官网上有详尽的资料,可以去参考doc目录下的内容,各种手册还是比较详细的。
官网: https://pivotal.io/big-data/pivotal-greenplum
另外若需要先刷一下中文资料,可以参考《Greenplum企业应用实战》。这个资料好像csdn上有,我也给分享了百度云连接。里面还有一个ppt,算是DBA培训手册。
https://pivotal.io/big-data/pivotal-greenplum
其他,阿里云栖社区,有些话题会讨论greenplum,也可以逛逛。但是我尝试里面的一篇文章,扩展segment节点,没能成功/(ㄒoㄒ)/~~。