1.取出一个新闻列表页的全部新闻 包装成函数。
2.获取总的新闻篇数,算出新闻总页数。
3.获取全部新闻列表页的全部新闻详情。
#coding=utf-8 import requests from bs4 import BeautifulSoup from datetime import datetime import re import time def getClickCount(newurl): newsId = re.search('\_(.*).html',newurl).group(1).split('/')[1] # 生成点击次数的Request URL clickUrl = 'http://oa.gzcc.cn/api.php?op=count&id={}&modelid=80'.format(newsId) return((requests.get(clickUrl).text.split('.html')[-1].lstrip("('").rstrip("');"))) def getNewsDetail(newurl): #读取一篇新闻的所有信息 resd = requests.get(newurl) resd.encoding = 'utf-8' soupd = BeautifulSoup(resd.text, 'html.parser') #打开新闻详细页并解析 title=soupd.select('.show-title')[0].text info=soupd.select('.show-info')[0].text dt=datetime.strptime(info.lstrip('发布时间:')[0:19],'%Y-%m-%d %H:%M:%S') if info.find('来源:')>0: source=info[info.find('来源:'):].split()[0].lstrip('来源:') else: source='none' click=getClickCount(newurl) print(dt,title,newurl,source,click) def getListPage(listPageUrl): #一个分页的所有新闻 res = requests.get(listPageUrl) res.encoding = 'utf-8' soup = BeautifulSoup(res.text, 'html.parser') for news in soup.select('li'): if len(news.select('.news-list-title')) > 0: # 获取新闻模块链接 a = news.a.attrs['href'] # 调用函数获取新闻正文 getNewsDetail(a) def getPage(): # 获取新闻列表总页数 res = requests.get('http://news.gzcc.cn/html/xiaoyuanxinwen/') res.encoding = 'utf-8' soup = BeautifulSoup(res.text, 'html.parser') n = int(soup.select('.a1')[0].text.rstrip('条')) // 10 + 1 return n firstPage='http://news.gzcc.cn/html/xiaoyuanxinwen/' getListPage(firstPage) #获取新闻列表总页数 n=getPage() for i in range(n,n+1): pageurl='http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html'.format(i) getListPage(pageurl)
截图:

4.找一个自己感兴趣的主题,进行数据爬取,并进行分词分析。
爬取的是起点小说网页一部小说目录的标题及相关信息。
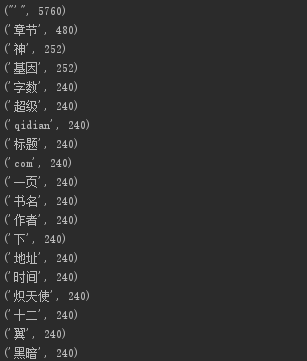
#coding=utf-8 import requests from bs4 import BeautifulSoup from datetime import datetime import re import jieba import codecs def nextPage(newurl): newsId = re.search('//read.qidian.com/chapter/(.*)', newurl).group(1).split('/')[1] return newsId def getListPage(listPageUrl): #一页小说的信息 res = requests.get(listPageUrl) res.encoding = 'utf-8' soup = BeautifulSoup(res.text, 'html.parser') config_dic={} # bookname=soup.select('.info.fl')[0].select('a')[0].text # author = soup.select('.info.fl')[0].select('a')[1].text # title = soup.select('.j_chapterName')[0].text # worknumber=soup.select('.j_chapterWordCut')[0].text # time=soup.select('.j_updateTime')[0].text config_dic['书名:']=soup.select('.info.fl')[0].select('a')[0].text config_dic['作者:']=soup.select('.info.fl')[0].select('a')[1].text config_dic['章节标题:']= soup.select('.j_chapterName')[0].text config_dic['章节字数:']=soup.select('.j_chapterWordCut')[0].text config_dic['时间:']=soup.select('.j_updateTime')[0].text config_dic['下一页地址:']= soup.select('.chapter-control.dib-wrap')[0].select('a')[2].attrs['href'] return config_dic # print('书名' + ': ' + bookname) # print('章节名' + ' :' + title) # print('章节字数' + ': ' + worknumber) # print('作者' + ': ' + author) # print('发布时间' + ': ' + time) # b = soup.select('.chapter-control.dib-wrap')[0].select('a')[2].attrs['href'] # nextPage(b) all_test = [] firstPage='https://read.qidian.com/chapter/KrpRa8cmGVT-JlVC31J8Aw2/lGUghgIS8dn4p8iEw--PPw2/' all_test.append(getListPage(firstPage)) url='https:'+all_test[0]['下一页地址:'] for i in range(1,20): # pageurl='https://read.qidian.com/chapter/KrpRa8cmGVT-JlVC31J8Aw2/{}'.format(c) new_test = getListPage(url) all_test.append(new_test) url = 'https:'+new_test['下一页地址:'] f = open('novel_text', 'a', encoding='utf-8') for i in all_test: print(i) t=str(i) f.write(t) f.close() all_uni=open('novel_text','r',encoding='utf-8') text=all_uni.read() wordlist=list(jieba.lcut(text)) #分解 Words={} for i in set(wordlist): Words[i]=wordlist.count(i) delete_word={'chapter',' ','KrpRa8cmGVT','我们', '他', ',', '他的', '你的', '呀', '和', '.',',','。',':','“','”','的','啊','?','在','了', '{','}','ue60c','ue650',' ','、','也',':','!','\','儿','这','/','-', ' ','(',')','那','有','上','便','和','只','要','小','罢','那里', '…','2016.11','?','read','把','JlVC31J8Aw2'} for i in delete_word: #删除出现的过渡词 if i in Words: del Words[i] sort_word = sorted(Words.items(), key= lambda d:d[1], reverse = True) # 排序 for i in range(20): print(sort_word[i])
截图:

解析排序后内容: