Hadoop综合大作业
1.用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)词频统计。
1.首先启动hadoop,并查看环境是否齐全

2..在Hdfs上创建文件夹storyinput,并且创建并编辑story.txt。将下载的英文小说写进去。而我只是将一篇章节的英文小说放进去。
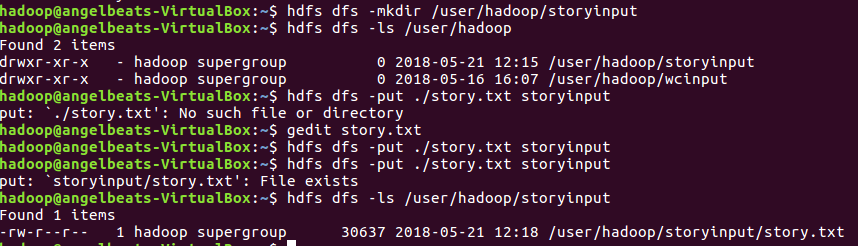
3.启动hive并创建原始文档表并将小说导入到表docs中。

4.查看内容 是否已经导入
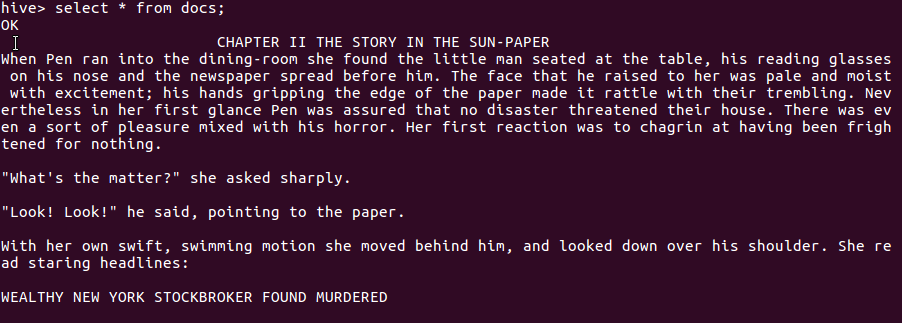
5.用HQL进行词频统计,结果放在表story_count里

6.统计结果:


2.用Hive对爬虫大作业产生的csv文件进行数据分析,写一篇博客描述你的分析过程和分析结果。
1.首先,我爬取的是网易云问答社区的几页数据,包括问题,提问者,时间和网友的回答。
之后csv文件的导出是要用到 pandas 的,需要导入pandas 后,使用pandas导出。
#coding=utf-8#coding=utf-8 # -*- coding : UTF-8 -*- import requests from bs4 import BeautifulSoup import pandas list_question=[] list_author=[] list_time=[] list_content=[] def getDetail(newsUrl): #对每个li下的回答内容进行保存获取 resd = requests.get(newsUrl) resd.encoding = 'utf-8' soupd = BeautifulSoup(resd.text, 'html.parser') question= soupd.select('.m-question')[0].select('.tlt')[0].text author= soupd.select('.m-info.f-fr')[0].select('.f-cb')[0].text time = soupd.select('.m-info.f-fr')[0].select('.m-info-time')[0].text for new in soupd.select('.cnt-qs')[0].select('.item-qs'): content = new.select('.cnt')[0].text list_question.append(question) list_author.append(author) list_time.append(time) list_content.append(content) print("提问的问题:"+str(list_question)) print("提问网友:"+str(list_author)) print("提问时间:"+str(list_time)) print("网友回答内容:"+str(list_content)) f=pandas.DataFrame( { 'questions':pandas.Categorical(list_question), 'theauthor':pandas.Categorical(list_author), 'Datatime':pandas.Categorical(list_time), 'allcontent':pandas.Categorical(list_content) } ) f.to_csv('WangyiData.csv',encoding='utf_8_sig') def Get_Pageurl(url): res = requests.get(url) res.encoding = 'utf-8' soup = BeautifulSoup(res.text, 'html.parser') for new in soup.select('.m-ask-item')[0].select('.item'): theUrl= new.select('.tlt.tlt-1')[0].select('a')[0]['href'] #获取每个li标签下的url url = 'https://sq.163yun.com' + theUrl getDetail(url) url = 'https://sq.163yun.com/ask/search?current=1&keywords=5LqR6K6h566X' #网易云问答的网站 resd = requests.get(url) resd.encoding = 'utf-8' soup1 = BeautifulSoup(resd.text, 'html.parser') Get_Pageurl(url) for i in range(2, 5): Get_Pageurl('https://sq.163yun.com/ask/search?current={}&keywords=5LqR6K6h566X'.format(i))
csv导出是这个,不加上encoding='utf_8_sig' 导出来的是会乱码的。
f.to_csv('WangyiData.csv',encoding='utf_8_sig')
下面是我的csv文件内容:

之后将导出的csv文件通过邮箱下载到linux中。
我们创造一个:lastbigwork文件之后赋予权限,将自己的csv文件放入到lastbigwork中。之后查看目录可以看到已经放入了。

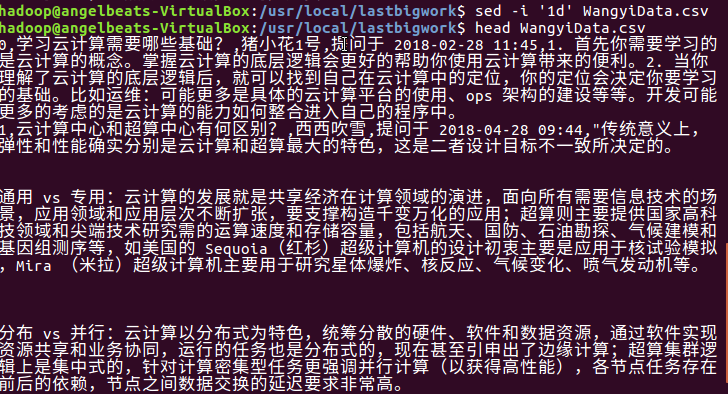
2.预处理,sed主要是用于一些简单的文本替换,-i 删除,‘1d’是指删除哪一条数据。
之后查看csv数据情况。
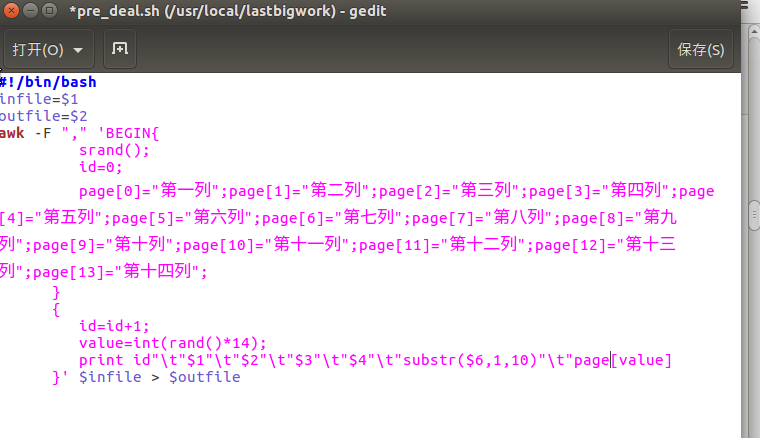
创建一个脚本文件pre_deal.sh
great pre_deal.sh #执行脚本文件后将数据存储进user_table.txt bash ./pre_deal.sh MuKeData.csv user_table.txt

脚本文件如下所示:
之后查看数据发生了什么变化,如图所示:

3.将弄好的数据导入HDFS
开启dfs,如图所示:
start-all.sh
jps


我在hdfs中创建了一个bigdatabasecase/dataset,好用于数据处理。
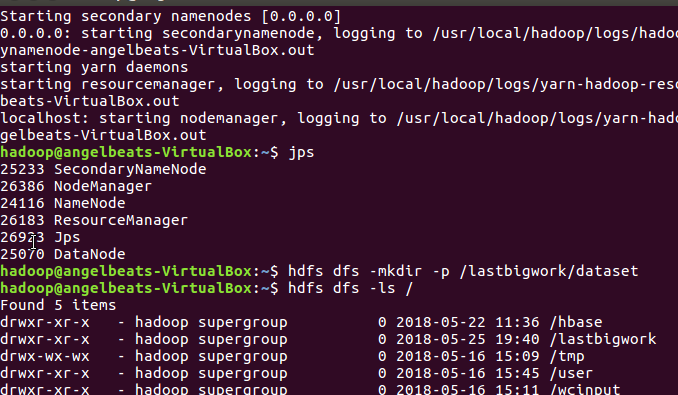
之后将user_table.txt存入到hdfs中的路径中:

验证查看前十行的数据,确定数据已经放入lastbigwork/dataset下的user_table.txt 有数据。

4.启动mysql数据库,导入到hive数据仓库中。
启动hive
因为Hive里的表出现了一些问题,所以后面的修改后再发上来。