一. 进程概述
先来看一下Oracle 11g 的架构图。 看起来比较模糊,我已经上传到了csdn 的下载。 是个pdf 文件, 2m 多。 那个看起来比较清楚。 也对每个进程做了解释。
下载地址:Oracle 11g 架构图 from Oracle University
http://download.csdn.net/source/2346700

进程是操作系统中的一种机制,它可执行一系列的操作步。在有些操作系统中使用作业(JOB)或任务(TASK)的术语。一个进程通常有它自己的专用存储区。ORACLE进程的体系结构设计使性能最大。
ORACLE实例有两种类型:单进程实例 和 多进程实例。
单进程ORACLE(又称单用ORACLE)是一种数据库系统,一个进程执行全部ORACLE代码。由于ORACLE部分和客户应用程序不能分别以进程执行,所以ORACLE的代码和用户的数据库应用是单个进程执行。在单进程环境下的ORACLE 实例,仅允许一个用户可存取。例如在MS-DOS上运行ORACLE 。
多进程ORACLE实例(又称多用户ORACLE)使用多个进程来执行ORACLE的不同部分 ,对于每一个连接的用户都有一个进程。
在多进程系统中,进程分为两类:用户进程 和ORACLE进程。当一用户运行一应用程序,如PRO*C程序或一个ORACLE工具(如SQL*PLUS),为用户运行的应用建立一个用户进程。
ORACLE进程又分为两类:服务器进程 和 后台进程。
服务器进程用于处理连接到该实例的用户进程的请求。当应用和ORACELE是在同一台机器上运行,而不再通过网络,一般将用户进程和它相应的服务器进程组合成单个的进程,可降低系统开销。然而,当应用和ORACLE运行在不同的机器上时,用户进程经过一个分离服务器进程与ORACLE通信。它可执行下列任务:
1) 对应用所发出的SQL语句进行语法分析和执行。
2) 从磁盘(数据文件)中读入必要的数据块到SGA的共享数据库缓冲区(该块不在缓冲区时)。
3) 将结果返回给应用程序处理。
系统为了使性能最好和协调多个用户,在多进程系统中使用一些附加进程,称为后台进程。在许多操作系统中,后台进程是在实例启动时自动地建立。一个ORACLE实例可以有许多后台进程,但它们不是一直存在。
后台进程有:
DBWR(Database Write) : 数据库写入程序
LGWR(Log Write) : 日志写入程序
CKPT(Checkpoint) : 检查点
SMON (System Monitor): 系统监控
PMON(Process Monitor) : 进程监控
ARCH(Archive) : 归档
RECO : 恢复
LCKn : 封锁;
这是RAC 环境启动时,各个进程的启动顺序:
PMON started with pid=2, OS id=18042
DIAG started with pid=3, OS id=18044
PSP0 started with pid=4, OS id=18051
LMON started with pid=5, OS id=18053
LMD0 started with pid=6, OS id=18055
LMS0 started with pid=7, OS id=18057
MMAN started with pid=8, OS id=18061
DBW0 started with pid=9, OS id=18063
LGWR started with pid=10, OS id=18065
CKPT started with pid=11, OS id=18067
SMON started with pid=12, OS id=18069
RECO started with pid=13, OS id=18071
CJQ0 started with pid=14, OS id=18073
MMON started with pid=15, OS id=18075
MMNL started with pid=16, OS id=18077
每个后台进程与ORACLE数据库的不同部分交互。 其中SMON、PMON、DBWn、CKPT、LGWR 是五个必须的ORACLE后台进程。
二. 进程详细说明
1. DBWR进程
该进程执行将缓冲区写入数据文件,是负责缓冲存储区管理的一个ORACLE后台进程。当缓冲区中的一缓冲区被修改,它被标志为“弄脏”,DBWR的主要任务是将“弄脏”的缓冲区写入磁盘,使缓冲区保持“干净”。由于缓冲存储区的缓冲区填入数据库或被用户进程弄脏,未用的缓冲区的数目减少。当未用的缓冲区下降到很少,以致用户进程要从磁盘读入块到内存存储区时无法找到未用的缓冲区时,DBWR将管理缓冲存储区,使用户进程总可得到未用的缓冲区。
ORACLE采用LRU(LEAST RECENTLY USED)算法(最近最少使用算法)保持内存中的数据块是最近使用的,使I/O最小。
触发DBWR进程的条件有:
1. DBWR超时,大约3秒
2. 系统中没有多余的空缓冲区来存放数据
3. CKPT 进程触发DBWR
在有些平台上,一个实例可有多个DBWR。在这样的实例中,一些块可写入一磁盘,另一些块可写入其它磁盘。
2. LGWR进程
该进程将日志缓冲区写入磁盘上的一个日志文件,它是负责管理日志缓冲区的一个ORACLE后台进程。
触发LGWR进程的条件有:
1. 用户提交
2. 有1/3重做日志缓冲区未被写入磁盘
3. 有大于1M的重做日志缓冲区未被写入磁盘
4. 3秒超时
5. DBWR 需要写入的数据的SCN大于LGWR记录的SCN,DBWR 触发LGWR写入。
日志缓冲区是一个循环缓冲区。当LGWR将日志缓冲区的日志项写入日志文件后,服务器进程可将新的日志项写入到该日志缓冲区。LGWR 通常写得很快,可确保日志缓冲区总有空间可写入新的日志项。
注意:有时候当需要更多的日志缓冲区时,LWGR在一个事务提交前就将日志项写出,而这些日志项仅当在以后事务提交后才永久化。
ORACLE使用快速提交机制,当用户发出COMMIT语句时,一个COMMIT记录立即放入日志缓冲区,但相应的数据缓冲区改变是被延迟,直到在更有效时才将它们写入数据文件。当一事务提交时,被赋给一个系统修改号(SCN),它同事务日志项一起记录在日志中。由于SCN记录在日志中,以致在并行服务器选项配置情况下,恢复操作可以同步。
3. CKPT进程
该进程在检查点出现时,对全部数据文件的标题进行修改,指示该检查点。负责在每当缓冲区高速缓存中的更改永久地记录在数据库中时,更新控制文件和数据文件中的数据库状态信息。
RedoLog Checkpoint 和 SCN关系
http://blog.csdn.net/tianlesoftware/archive/2010/01/25/5251916.aspx
Redo Log 和Checkpoint not complete
http://blog.csdn.net/tianlesoftware/archive/2009/12/01/4908066.aspx
4. SMON进程
SMON是Oracle数据库至关重要的一个后台进程, 该进程实例启动时执行实例恢复,还负责清理不再使用的临时段, 是一种用于库的“垃圾收集者”。在具有并行服务器选项的环境下,SMON对有故障CPU或实例进行实例恢复。SMON进程有规律地被呼醒,检查是否需要,或者其它进程发现需要时可以被调用。
它做的工作包括如下7件:
(1)清理临时表空间:伴随这“真正”的临时表空间的出现,清理临时表空间的杂事已经减轻了,但它还没完全消失。例如,当建立一个索引,在创建期间分配给索引的扩展区被标志为TEMPORARY。如果Create Index会话因某些原因异常中断,SMON负责清理他们。其他操作创建的临时扩展区,SMON同样会负责。
(2) 接合空闲空间:如果你正使用数据字典管理表空间,SMON负责把那些在表空间中空闲的并且互相是邻近的extent接合成一个较大的空闲扩展区。这发生仅在带有默认的pctincrease设置为非零的存储子句的字典管理表空间。
(3) 把对于不可用文件的事务恢复成活动状态:它的角色类似在库启动期间。这时,因为文件不能用于恢复,SMON恢复在实例/崩溃恢复期间被跳过的故障事务。例如,文件可能已经在不可用或没装载的磁盘上。当文件变可用了,SMON将恢复它。
(4)执行一个RAC中故障节点的实例恢复:在一个oracle RAC配置中,当群集中的一个库实例失败(例如,实例正执行的机器故障了),一些群集中的其他节点将开启故障的实例的重做日志文件,为故障实例执行所有数据的恢复。
(5)清理OBJ$:OBJ$是一个包含库中几乎每一个对象(表,索引,触发器,视图等等)的记录的行级数据字典表。许多次,这儿存在的记录代表已删对象,或代表不在这儿的对象,在oracle的信赖机制中被使用。SMON是删除这些不在被需要的行的进程。
(6)收缩回滚段:SMON将执行回滚段的自动收缩到它的optimal尺寸,如果它被设置。
(7)“脱机”回滚段:对于DBA来,让一个有active事务的回滚段,脱机或不可用,这事是可能的。Active事务正使用这脱机回滚段是可能的。在这情况下,回滚不是真正的脱机;它被标志为“悬挂offline”。在后台进程中,SMON将周期性尽力让它真正脱机,直到成功。
SMON做许多其他事情,譬如存在DBA_TAB_MONITORING视图中的监控统计数据的洗刷,在SMON_SCN_TIME表中发现的时间戳定位信息的SCN的洗刷,等等。SMON在期间能消耗很多CPU,这应该被认为是正常的。SMON周期性的苏醒(或被其他后台进程叫醒)来执行这些管家的家庭杂事。
5. PMON进程
用于恢复失败的数据库用户的强制性进程,它先获取失败用户的标识,释放该用户占有的所有数据库资源。PMON有规律地被呼醒,检查是否需要,或者其它进程发现需要时可以被调用。
PMON进程负责在反常中断的连接之后的清理工作。例如,如果因某些原因专用服务“故障”或被kill掉,PMON就是负责处理(恢复或回滚工作)和释放你的资源。 PMON将发出未提交工作的回滚,释放锁,和释放分配给故障进程的SGA资源。除了在异常中断之后的清理外,PMON监控其他oracle后台进程,如果有必要(和有可能)重新启动他们。如果共享服务或一个分配器故障(崩溃),PMON将插手并且重启另一个(在清理故障进程之后)。
PMON将观察所有Oracle进程,只要合适或重启他们或中止进程。例如,在数据库日志写进程事件中,LGWR故障,实例故障。这是一个严重的错误,最安全的处理方法就是去立即终止实例,让正常的恢复处理数据。
PMON为实例做的另一件事是去使用Oracle TNS监听器登记。当一个实例开启的时候,PMON进程投出众所周知的端口地址,除非指向其他,来看是否监听器正在开和运行着。众所周知/默认端口是使用1521。
现在,如果监听器在一些不同端口开启会发生什么?这种情况,机制是相同的,除了监听器地址需要被LOCAL_LISTENER参数明确指定。如果监听器运行在库实例开启的时候,PMON和监听器通讯,传到它相关参数,譬如服务器名和实例的负载度量。如果监听器没被开启,PMON将周期性的试着和它联系来登记自己。
The background process PMON cleans up after failed processes by:
1. Rolling back the user’s current transaction
2. Releasing all currently held table or row locks
3. Freeing other resources currently reserved by the user
4. Restarts dead dispatchers
6. RECO进程
负责在分布式数据库环境中自动恢复那些失败的分布式事务,保证分布式事务的一致性,在分布式事务中,要么同时commit,要么同时rollback;
7. ARCH进程
该进程将已填满的在线日志文件拷贝到指定的存储设备。当数据库运行在归档模式下,归档进程负责在日志切换后将已经写满的重做日志文件复制到归档目标.
8. LCKn进程
是在具有并行服务器选件环境下使用,可多至10个进程(LCK0,LCK1……,LCK9),用于实例间的封锁。
9. MMAN 进程
内存管理,如果设定了 SGA自动管理,MMAN用来协调SGA内各组件的大小设置和大小调整。
10. MMON 进程
管理性监视器(Manageability Monitor),MMON主要用于AWR,ADDM。MMON会从SGA将统计结果写到系统表中。
MMON: The Manageability Monitor (MMON) process was introduced in 10g and is associated with the Automatic Workload Repository new features used for automatic problem detection and self-tuning. MMON writes out the required statistics for AWR on a scheduled basis.
三. DBWR、CKPT、LGWR进程之间的关系
将内存数据块写入数据文件实在是一个相当复杂的过程,在这个过程中,首先要保证安全。所谓安全,就是在写的过程中,一旦发生实例崩溃,要有一套完整的机制能够保证用户已经提交的数据不会丢失;其次,在保证安全的基础上,要尽可能的提高效率。众所周知,I/O操作是最昂贵的操作,所以应该尽可能的将脏数据块收集到一定程度以后,再批量写入磁盘中。
直观上最简单的解决方法就是,每当用户提交的时候就将所改变的内存数据块交给DBWR,由其写入数据文件。这样的话,一定能够保证提交的数据不会丢失。但是这种方式效率最为低下,在高并发环境中,一定会引起I/O方面的争用。oracle当然不会采用这种没有扩展性的方式。oracle引入了CKPT和LGWR这两个后台进程,这两个进程与DBWR进程互相合作,提供了既安全又高效的写脏数据块的解决方法。
用户进程每次修改内存数据块时,都会在日志缓冲区(redo buffer)中构造一个相应的重做条目(redo entry),该重做条目描述了被修改的数据块在修改之前和修改之后的值。而LGWR进程则负责将这些重做条目写入联机日志文件。只要重做条目进入了联机日志文件,那么数据的安全就有保障了,否则这些数据都是有安全隐患的。LGWR是一个必须和前台用户进程通信的进程。LGWR承担了维护系统数据完整性的任务,它保证了数据在任何情况下都不会丢失。
LGWR将重做条目写入联机日志文件的情况分两种:后台写(background write)和同步写(sync write)。
触发后台写的条件有四个:
1)每隔三秒钟,LGWR启动一次;
2)在DBWR启动时,如果发现脏数据块所对应的重做条目还没有写入联机日志文件,则DBWR触发LGWR进程并等待LRWR写完以后才会继续;
3)重做条目的数量达到整个日志缓冲区的1/3时,触发LGWR;
4)重做条目的数量达到1MB时,触发LGWR。
而触发同步写的条件就一个:当用户提交(commit)时,触发LGWR。
假如DBWR在写脏数据块的过程中,突然发生实例崩溃。我们已经知道,用户提交时,oracle是不一定会把提交的数据块写入数据文件的。那么实例崩溃时,必然会有一些已经提交但是还没有被写入数据文件的内存数据块丢失了。当实例再次启动时,oracle需要利用日志文件中记录的重做条目在buffer cache中重新构造出被丢失的数据块,从而完成前滚和回滚的工作,并将丢失的数据块找回来。于是这里就存在一个问题,就是oracle在日志文件中找重做条目时,到底应该找哪些重做条目?换句话说,应该在日志文件中从哪个起点开始往后应用重做条目?注意,这里所指的日志文件可能不止一个日志文件。
因为oracle需要随时预防可能的实例崩溃现象,所以oracle在数据库的正常运行过程中,会不断的定位这个起点,以便在不可预期的实例崩溃中能够最有效的保护并恢复数据。同时,这个起点的选择非常有讲究。首先,这个起点不能太靠前,太靠前意味着要处理很多的重做条目,这样会导致实例再次启动时所进行的恢复的时间太长;其次,这个起点也不能太靠后,太靠后说明只有很少的脏数据块没有被写入数据文件,也就是说前面已经有很多脏数据块被写入了数据文件,那也就意味着只有在DBWR启动的很频繁的情况下,才能使得buffer cache中所残留的脏数据块的数量很少。但很明显,DBWR启动的越频繁,那么所占用的写数据文件的I/O就越严重,那么留给其他操作(比如读取buffer cache中不存在的数据块等)的I/O资源就越少。这显然也是不合理的。
从这里也可以看出,这个起点实际上说明了,在日志文件中位于这个起点之前的重做条目所对应的在buffer cache中的脏数据块已经被写入了数据文件,从而在实例崩溃以后的恢复中不需要去考虑。而这个起点以后的重做条目所对应的脏数据块实际还没有被写入数据文件,如果在实例崩溃以后的恢复中,需要从这个起点开始往后,依次取出日志文件中的重做条目进行恢复。考虑到目前的内存容量越来越大,buffer cache也越来越大,buffer cache中包含几百万个内存数据块也是很正常的现象的前提下,如何才能最有效的来定位这个起点呢?
为了能够最佳的确定这个起点,oracle引入了名为CKPT的后台进程,通常也叫作检查点进程(checkpoint process)。这个进程与DBWR共同合作,从而确定这个起点。同时,这个起点也有一个专门的名字,叫做检查点位置(checkpoint position)。
oracle为了在检查点的算法上更加的具有可扩展性(也就是为了能够在巨大的buffer cache下依然有效工作),引入了检查点队列(checkpoint queue),该队列上串起来的都是脏数据块所对应的buffer header。
DBWR每次写脏数据块时,也是从检查点队列上扫描脏数据块,并将这些脏数据块实际写入数据文件的。当写完以后,DBWR会将这些已经写入数据文件的脏数据块从检查点队列上摘下来。这样即便是在巨大的buffer cache下工作,CKPT也能够快速的确定哪些脏数据块已经被写入了数据文件,而哪些还没有写入数据文件,显然,只要在检查点队列上的数据块都是还没有写入数据文件的脏数据块。
为了更加有效的处理单实例和多实例(RAC)环境下的表空间的检查点处理,比如将表空间设置为离线状态或者为热备份状态等,oracle还专门引入了文件队列(file queue)。文件队列的原理与检查点队列是一样的,只不过每个数据文件会有一个文件队列,该数据文件所对应的脏数据块会被串在同一个文件队列上;同时为了能够尽量减少实例崩溃后恢复的时间,oracle还引入了增量检查点(incremental checkpoint),从而增加了检查点启动的次数。
如果每次检查点启动的间隔时间过长的话,再加上内存很大,可能会使得恢复的时间过长。因为前一次检查点启动以后,标识出了这个起点。然后在第二次检查点启动的过程中,DBWR可能已经将很多脏数据块已经写入了数据文件,而假如在第二次检查点启动之前发生实例崩溃,导致在日志文件中,所标识的起点仍然是上一次检查点启动时所标识的,导致oracle不知道这个起点以后的很多重做条目所对应的脏数据块实际上已经写入了数据文件,从而使得oracle在实例恢复时再次重复的处理一遍,效率低下,浪费时间。
上面说到了有关CKPT的两个重要的概念:检查点队列(包括文件队列)和增量检查点。
检查点队列在我们上面转储出来的buffer header里可以看到,就是类似ckptq: [65abceb4,63bec66c]和fileq: [65abcfbc,63becd10]的结构,记录的同样都是指向前一个buffer header和指向后一个buffer header的指针。这个队列上面挂的也是脏数据块对应的buffer header链表,但是它与LRUW链表不同。检查点队列上的buffer header是按照数据块第一次被修改的时间的先后顺序来排列的。越早修改的数据块的buffer header排在越前面,同时如果一个数据块被修改了多次的话,在该链表上也只出现一次。而且,检查点队列上的buffer header还记录了脏数据块在第一次被修改时,所对应的重做条目在重做日志文件中的地址,也就是RBA(Redo Block Address)。同样在转储出来的buffer header中可以看到类似LRBA: [0xe9.229.0]的结构,这就是RBA,L表示Low,也就是第一次被修改的时候的RBA。但是注意,在检查点队列上的buffer header,并不表示一定会有一个对应的RBA,比如控制文件重做(controlfile redo)就不会有相应的RBA。对于没有对应RBA的buffer header来说,在检查点队列上始终处于最尾端,其优先级永远比有RBA的脏数据块的buffer header要低。8i以前,每个working set都有一个检查点队列以及多个文件队列(因为一个数据文件对应一个文件队列);而从8i开始,每个working set都有两个检查点队列,每个检查点都会由checkpoint queue latch来保护。
增量检查点是从8i开始出现的,是相对于8i之前的完全检查点(complete checkpoint)而言的。完全检查点启动时,会标识出buffer cache中所有的脏数据块,然后启动DBWR进程将这些脏数据块写入数据文件。8i之前,日志切换的时候会触发完全检查点。
而到了8i及以后,完全检查点只有在两种情况下才会被触发:
1)发出命令:alter system checkpoint;
2)除了shutdown abort以外的正常关闭数据库。
注意,这个时候,日志切换不会触发完全检查点,而是触发增量检查点。8i所引入的增量检查点每隔三秒钟或发生日志切换时启动。它启动时只做一件事情:找出当前检查点队列上的第一个buffer header,并将该buffer header中所记录的LRBA(这个LRBA也就是checkpoint position了)记录到控制文件中去。如果是由日志切换所引起的增量检查点,则还会将checkpoint position记录到每个数据文件头中。也就是说,如果这个时候发生实例崩溃,oracle在下次启动时,就会到控制文件中找到这个checkpoint position作为在日志文件中的起点,然后从这个起点开始向后,依次取出每个重做条目进行处理。
上面所描述的概念,用一句话来概括,其实就是DBWR负责写检查点队列上的脏数据块,而CKPT负责记录当前检查点队列的第一个数据块所对应的的重做条目在日志文件中的地址。从这个意义上说,检查点队列比LRUW还要重要,LRUW主要就是区分出哪些数据块是脏的,不可以被重用的。而到底应该写哪些脏数据块,写多少脏数据块,则还是要到检查点队列上才能确定的。
我们用一个简单的例子来描述这个过程。假设系统中发生了一系列的事务,导致日志文件如下所示:
事务号 数据文件号 block号 行号 列 值 RBA
T1 8 25 10 1 10 101
T1 7 623 12 2 a 102
T3 8 80 56 3 b 103
T3 9 98 124 7 e 104
T5 7 623 13 3 abc 105
Commit SCN# timestamp 106
T123 8 876 322 10 89 107
这时,对应的检查点队列则类似如下图六所示。我们可以看到,T1事务最先发生,所以位于检查点

图六
队列的首端,而事务T123最后发生,所以位于靠近尾端的地方。同时,可以看到事务T1和T5都更新了7号数据文件的623号数据块。而在检查点队列上只会记录该数据块的第一次被更新时的RBA,也就是事务T1对应的RBA102,而事务T5对应的RBA105并不会被记录。因为根本就不需要在检查点队列上记录。当DBWR写数据块的时候,在写RBA102时,自然就把RBA105所修改的内容写入数据文件了。日志文件中所记录的提交标记也不会体现在检查点队列上,因为提交本身只是一个标记而已,不会涉及到修改数据块。
这时,假设发生三秒钟超时,于是增量检查点启动。增量检查点会将检查点队列的第一个脏数据块所对应的RBA记录到控制文件中去。在这里,也就是RBA101会作为checkpointposition记录到控制文件中。
然后,DBWR后台进程被某种条件触发而启动。DBWR根据一系列参数及规则,计算出应该写的脏数据块的数量,从而将RBA101到RBA107之间的这5个脏数据块写入数据文件,并在写完以后将这5个脏数据块从检查点队列上摘除,而留下了4个脏数据块在检查点队列上。如果在写这5个脏数据块的过程中发生实例崩溃,则下次实例启动时,oracle会从RBA101开始应用日志文件中的重做条目。
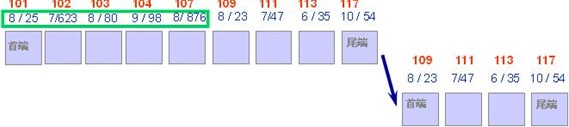
图七
而在9i以后,在DBWR写完这5个脏数据块以后,还会在日志文件中记录所写的脏数据块的块号。如下图所示。这主要是为了在恢复时加快恢复的速度。

图八
这时,又发生三秒钟超时,于是增量检查点启动。这时它发现checkpointposition为RBA109,于是将RBA109写入控制文件。如果接着发生实例崩溃,则oracle在下次启动时,就会从RBA109开始应用日志。
注:整理自网络
-------------------------------------------------------------------------------------------------------
Blog: http://blog.csdn.net/tianlesoftware
Email: dvd.dba@gmail.com
DBA1 群:62697716(满); DBA2 群:62697977(满) DBA3 群:62697850(满)
DBA 超级群:63306533(满); DBA4 群: 83829929 DBA5群: 142216823
DBA6 群:158654907 聊天 群:40132017 聊天2群:69087192
--加群需要在备注说明Oracle表空间和数据文件的关系,否则拒绝申请