一、读取网页的如下:
uses TxHttp, Classes, TxCommon, Frm_WebTool, SysUtils; var m_Url: string; m_Http: TTxHttp; m_PostData: string; m_WebSource: string; m_Stream: TStringStream; begin m_Http := TTxHttp.Create; // 网址 m_Url := Trim(Form_WebTool.LabeledEdit1.Text); if Trim(m_Url) = '' then begin Exit; end; // 设置Header with m_Http do begin Accept := 'text/html, application/xhtml+xml, */*'; //AcceptEncoding := 'gzip, deflate';// 是否以GZIP方式访问网站 AcceptEncoding := ''; AcceptLanguage := 'zh-CN'; ContentType := 'application/x-www-form-urlencoded'; UserAgent := 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko'; end; // 设置Cookies m_Http.SetCookies(Trim(Form_WebTool.Memo4.Text), m_Url); // 设置编码 if Form_WebTool.ComboBox2.Text = 'GB2312' then begin m_Http.Encoding := TxGB2312; end else begin m_Http.Encoding := TxUTF8; end; // Get还是POST if Form_WebTool.ComboBox1.Text = 'POST' then begin m_WebSource := m_Http.GetEx(m_Url); end else begin m_PostData := Trim(Form_WebTool.Memo3.Text); // 网页访问函数 m_WebSource := m_Http.PosEx(m_Url, m_PostData); end; // 输出网页源码 Form_WebTool.Memo1.Text := m_WebSource; // 取COOKIES Form_WebTool.Memo4.Text := m_Http.Cookies; // 取Header Form_WebTool.Memo5.Text := m_Http.GetHttpHead; m_Http.Free; end.
二、设计的界面如下:
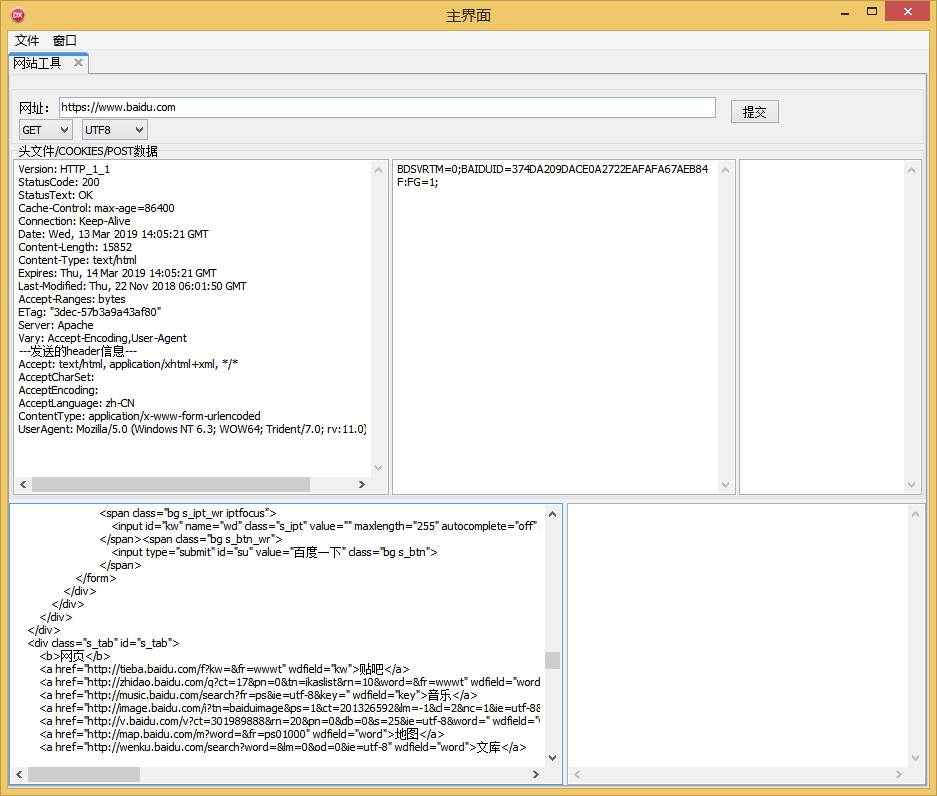
三、 左上的编辑框是我们读取的百度访问的头
Version: HTTP_1_1 StatusCode: 200 StatusText: OK Cache-Control: max-age=86400 Connection: Keep-Alive Date: Wed, 13 Mar 2019 14:05:21 GMT Content-Length: 15852 Content-Type: text/html Expires: Thu, 14 Mar 2019 14:05:21 GMT Last-Modified: Thu, 22 Nov 2018 06:01:50 GMT Accept-Ranges: bytes ETag: "3dec-57b3a9a43af80" Server: Apache Vary: Accept-Encoding,User-Agent ---发送的header信息--- Accept: text/html, application/xhtml+xml, */* AcceptCharSet: AcceptEncoding: AcceptLanguage: zh-CN ContentType: application/x-www-form-urlencoded UserAgent: Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko
四、中间部分是我们读取的COOKIES
BDSVRTM=0;BAIDUID=374DA209DACE0A2722EAFAFA67AEB84F:FG=1;
五、最下面就是我们读取的百度的页面内容了。
总结:Delphi10.3读取百度页面是非常简单方便的。
不忘初心,如果您认为这篇文章有价值,认同作者的付出,可以微信二维码打赏任意金额给作者(微信号:382477247)哦,谢谢。
