PS命令
1、简介
命令:ps
对应单词:process status
作用:查看当前正在运行的进程
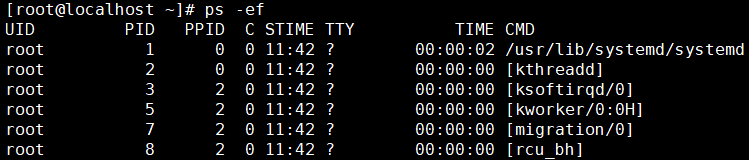
常用参数组合:ps -ef
-e参数:对应单词entire,表示全部。具体指显示系统中全部的进程信息。
-f参数:对应单词full-formate,表示完整格式。
效果:
2、进程信息中各列数据说明
| 列名 | 含义 |
|---|---|
| UID | 进程的用户信息 |
| PID | 进程id。由系统分配,不会重复。 |
| PPID | 父进程的id。父进程和子进程的关系是:父进程启动了子进程。 |
| CMD | 当前进程所对应的程序。 |
| C | 用整数表示的CPU使用率 |
| STIME | 进程启动时间 |
| TTY | 进程所在终端。所谓终端就是用户输入命令的操作界面。 |
| TIME | 进程所占用的CPU时间 |
3、父进程和子进程之间的关系
简单来说,父进程和子进程的关系是:父进程启动了子进程。我们可以使用pstree命令查看整个进程树。

4、和其他命令配合
①分屏查看进程信息
全部进程的信息太多了,一屏无法全部显示,所以我们希望可以分屏显示并由我们来控制翻页。为了达到这个目标,我们可以使用管道符号将ps -ef命令的输出数据传送给less命令。
ps -ef | less
②精确查询一个具体进程信息
我们通过Xshell远程连接Linux系统,靠的是sshd这个服务。这个服务如果正在运行中,那么一定会有这个服务对应的进程。所以下面我们来查询一下sshd这个命令的进程。

我们看到这里返回了3条结果,其中前两天都是和sshd服务相关的结果,但是最后一条不是。
root 72826 3456 0 20:06 pts/0 00:00:00 grep --color=auto sshd
仔细观察一下就能发现,这其实是grep命令本身。因为grep命令运行过程中本身也是一个进程,“grep sshd”正好也匹配sshd,所以就被选中了。但是这是一个干扰项,并不是我们真正要查询的内容,所以需要把它从查询结果中排除。

再用一层管道,使用grep命令的-v参数把匹配grep的行排除,返回不匹配的结果,这就是我们最终想要的。
kill命令
1、简介
命令:kill
作用:杀死进程
说明:kill命令本质上是给进程发送信号。
2、举例
①打开火狐浏览器
在Linux系统中打开Linux系统自带的火狐浏览器。

②查看火狐浏览器的进程id

另外一个是浏览器插件,不用管。
③使用kill命令结束火狐浏览器进程
kill -s kill 3325
另一种写法是
kill -9 3325
上面两种写法本质上都是发送kill信号给火狐浏览器进程。
top命令
1、简介
命令:top
作用:实时查看系统运行情况和健康状态。
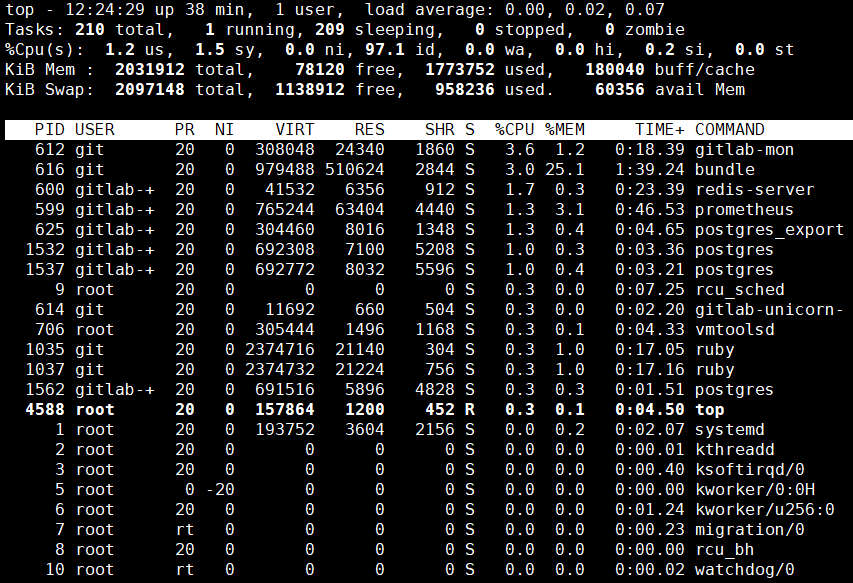
2、细节
①命令与参数
| 命令名 | 更新时间间隔(秒) | 不显示任何闲置或者僵死进程 | 通过进程id监控单一进程 |
|---|---|---|---|
| top | -d 间隔秒数 | -i | -p 进程id |
②操作控制
| 按键 | 功能 |
|---|---|
| P | 默认值,根据CPU使用率排序 |
| M | 以内存的使用率排序 |
| N | 以PID排序 |
| d | 设置数据刷新的时间间隔,单位是秒 |
| q | 退出 |
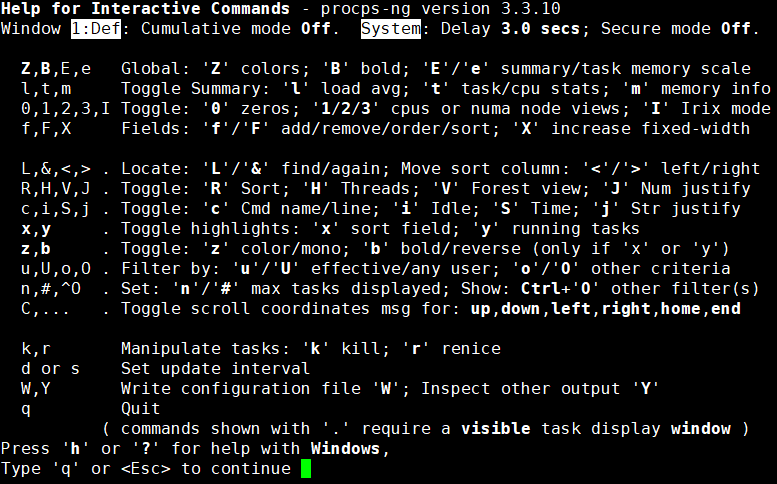
在top命令模式下按h键会显示如下的帮助信息:
③查询结果字段解释
[1]第一行信息为任务队列信息
| 内容举例 | 说明 |
|---|---|
| 12:26:49 | 系统当前时间 |
| up 1 day, 13:32 | 系统的运行时间,前面例子表示本机已经运行1天13小时32分钟 |
| 2 users | 当前登录了2个用户 |
| load average:0.00, 0.00, 0.00 | 系统在之前1分钟,5分钟,15分钟的平均负载。 一般认为小于1时,负载较小。如果大于1,系统已经超出负荷。 |
[2]第二行为进程信息
| 内容举例 | 说明 |
|---|---|
| Tasks: 95 total | 系统中的进程总数 |
| 1 running | 正在运行的进程数 |
| 94 sleeping | 睡眠的进程 |
| 0 stopped | 正在停止的进程 |
| 0 zombie | 僵尸进程。如果不是0,需要手工检查僵尸进程 |
[3]第三行为CPU信息
| 内容举例 | 说明 |
|---|---|
| Cpu(s):0.1%us | 用户空间占用的CPU百分比,us对应user |
| 0.1%sy | 内核空间占用的CPU百分比,sy对应system |
| 0.0%ni | 改变过优先级的进程占用的CPU百分比,ni对应niced |
| 99.7%id | 空闲CPU的CPU百分比 |
| 0.1%wa | 等待输入/输出的进程的占用CPU百分比,wa对应IO wait |
| 0.0%hi | 硬中断请求服务占用的CPU百分比,hi对应hardware IRQ |
| 0.1%si | 软中断请求服务占用的CPU百分比,si对应software IRQ |
| 0.0%st | st(Steal time)虚拟时间百分比,也叫被hypervisor偷走的时间。 就是当有虚拟机时,虚拟CPU等待实际CPU的时间百分比。 |
[4]第四行为物理内存信息
| 内容举例 | 说明 |
|---|---|
| 2031912 total | 物理内存的总量,单位KB |
| 70496 free | 空闲的物理内存数量 |
| 1780676 used | 已经使用的物理内存数量 |
| 174864 buff/cache | 作为缓冲的内存数量 |
使用中的内存总量(used)指的是现在系统内核控制的内存数,空闲内存总量(free)是还未纳入内核管控范围的数量。
纳入内核管理的内存不见得都在使用中,还包括过去使用过的现在可以被重复利用的内存,内核并不把这些可被重新使用的内存还给free,因此Linux系统运行过程中free内存会越来越少,但不影响系统运行。因为这表示更多的空闲内存被内核管理了。
[5]第五行为交换分区(swap)信息
| 内容举例 | 说明 |
|---|---|
| 2097148 total | 交换分区(虚拟内存)的总大小 |
| 1137824 free | 空闲交换分区的大小 |
| 959324 used | 已经使用的交互分区的大小 |
| 58640 avail Mem | 在不交换的情况下,对启动新应用程序可用内存的估计 |
交换分区是一个非常值得关注的地方,如果swap区的used数值持续发生变化那么说明在内核和交换分区之间正在持续发生数据交换,这表示内存不够用了——必须不断把内存中的数据保存到硬盘上。
netstat命令
1、简介
命令:netstat
对应单词:net status
作用:查看网络状态
常用参数:netstat -anp
| 参数名 | 作用 |
|---|---|
| -a | 显示所有正在或不在侦听的套接字。 |
| -n | 显示数字形式地址而不是去解析主机、端口或用户名。 |
| -p | 显示套接字所属进程的PID和名称。 |
2、说明
netstat命令显示的网络状态信息包含两部分内容:
- 本机和外部的连接状态信息
- 本机系统内部进程间通信信息
①网络连接信息

字段含义说明:

②进程间通信信息

我们重点关注的是网络连接信息。
3、使用技巧
①分屏查看
netstat -anp | less
②根据进程名称查看网络状态
netstat -anp | grep sshd
③根据端口号查看网络状态
netstat -anp | grep :22
这里需要注意一下,端口号本身就是一串数字,进程id也是一串数字。那么根据端口号匹配时,很多无关的进程id也会被匹配到,造成大量不必要的干扰。此时给端口号数字前加上冒号就好多了。

第四节 辅助命令
history命令
命令:history
作用:查看命令历史
用法:

将命令的运行结果写入文件:
- 覆盖写:命令 > 文件路径
- 追加写:命令 >> 文件路径
这里给大家介绍一个非常有意思的文件:/dev/null。它被称为Linux系统的黑洞,因为不管写入多少数据到这个文件,数据都会被销毁。

echo命令
1、简介
命令:echo
作用:将数据输出到standard output(标准输出),主要用来打印环境变量的值

2、关于standard output
① 本质
如果我们说把一条数据打印到标准输出,那么我们就是在说:打印到命令行窗口。
② 对比Java代码
System.out.println("Hello World!");
上面这行Java代码将字符串打印到了控制台,而如果我们我们把这段Java程序拿到Linux系统来执行,那么它就打印到standard output了。
3、输出环境变量
① Linux中引用环境变量
在Linux系统中通过$来引用环境变量,例如:$PATH
② 使用echo输出环境变量

命令帮助
1、概述
在我们学习一个新的命令时,Linux系统自带的官方命令手册就是非常权威的参考文档。而man命令和info命令都可以调出一个命令对应的文档。区别在于man命令阅读体验略好,info命令文档内容更完整。
2、用法
① man命令
命令:man
对应单词:manual
格式:man [要查询的命令]
控制方式:
| 按键 | 说明 |
|---|---|
| 空格 | 向下滚动一屏 |
| 回车 | 向下滚动一行 |
| b | 向上滚动一屏 |
| q | 退出 |
| /关键词 | 搜索关键词 n向下找 N向上找 |

② info命令
命令:info
对应单词:information
格式:info [要查询的命令]
控制方式:
| 按键 | 说明 |
|---|---|
| Up | Move up one line |
| Down | Move down one line |
| DEL | Scroll backward one screenful |
| SPC | Scroll forward one screenful |
| PgUp | Scroll backward in this window |
| PgDn | Scroll forward in this window |
其实info命令每次进入的都是同一个文档,只是不同被查询命令进入的是这个文档的不同位置而已。
③ 补充
大部分命令都有--help参数,也起到参考文档作用。

关机重启命令
1、意识
服务器端不要轻易关机!执行关机或重启操作前一定要问自己下面六个问题:
- 我现在操作的具体是哪一台服务器?
- 这台服务器是否是生产服务器?
- 这台服务器可能有哪些人登录?
- 我关机或重启后对其他人是否有影响?
- 这台服务器关机或重启是否会导致其他服务器无法正常工作?
- 我现在的操作是否必须通过关机或重启来实现?
一旦错误的关闭或重启了服务器,有可能会给公司造成无法弥补的损失。如果后果严重是有可能承担法律责任的。
2、相关命令
| 命令 | 作用 |
|---|---|
| sync | 将内存数据保存到硬盘上 |
| poweroff | 关机 |
| reboot | 重启 |
反斜杠
符号:
作用:如果一个命令特别长,那么可以使用反斜杠表示到下一行继续输入
示例:
./configure
--prefix=/usr/local/nginx
--pid-path=/var/run/nginx/nginx.pid
--lock-path=/var/lock/nginx.lock
--error-log-path=/var/log/nginx/error.log
--http-log-path=/var/log/nginx/access.log
--with-http_gzip_static_module
--http-client-body-temp-path=/var/temp/nginx/client
--http-proxy-temp-path=/var/temp/nginx/proxy
--http-fastcgi-temp-path=/var/temp/nginx/fastcgi
--http-uwsgi-temp-path=/var/temp/nginx/uwsgi
--http-scgi-temp-path=/var/temp/nginx/scgi
curl命令
命令:curl
对应单词:client url
作用:通过命令给服务器发送请求
官方文档说明节选:
curl is a tool to transfer data from or to a server, using one of the supported protocols (DICT, FILE, FTP, FTPS, GOPHER, HTTP, HTTPS, IMAP, IMAPS, LDAP, LDAPS, POP3, POP3S, RTMP, RTSP, SCP, SFTP, SMTP, SMTPS, TELNET and TFTP). The command is designed to work without user interaction.
从文档中我们可以看到curl命令支持的通信协议非常丰富,其中我们最常用的还是HTTP协议。如果有需要curl可以通过参数详细设置请求消息头。
用法举例:

通过-X参数可以指定请求方式:
curl -X POST [资源的URL地址]
nohup命令
1、提出问题
我们把一个SpringBoot工程导出为jar包,jar包上传到阿里云ESC服务器上,使用java -jar xxx-xxx.jar命令启动这个SpringBoot程序。此时我们本地的xshell客户端必须一直开着,一旦xshell客户端关闭,java -jar xxx-xxx.jar进程就会被结束,SpringBoot程序就访问不了了。
所以我们希望启动SpringBoot的jar包之后,对应的进程可以一直运行,不会因为xshell客户端关闭而被结束。

2、命令的前台运行和后台运行
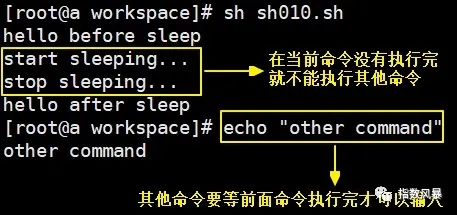
① 前台运行
默认情况下Linux命令都是前台运行的,前台运行的特点是前面命令不执行完,命令行就一直被前面的命令占用,不能再输入、执行新的命令。
#!/bin/bash
echo "hello before sleep"
sleep 20
echo "hello after sleep"
前台(默认情况)运行上面脚本的效果是:
后台运行上面脚本的效果是:
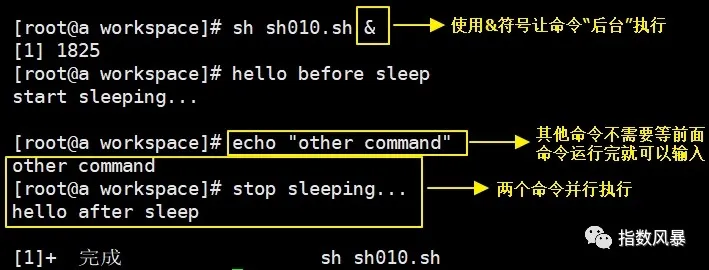
但是以后台方式运行并不能解决前面提出的问题:我们的shell客户端(例如:xshell)和服务器断开连接后,SpringBoot进程会随之结束,这显然不满足我们部署运行项目的初衷。
② 不挂断运行
所谓“不挂断”就是指客户端断开连接后,命令启动的进程仍然运行。nohup命令就是”no hang up“的缩写。使用nohup命令启动SpringBoot微服务工程的完整写法是:
nohup java -jar spring-boot-demo.jar>springboot.log 2>&1 &

wget命令
命令:wget
作用:下载文件
官方文档说明:GNU Wget is a free utility for non-interactive download of files from the Web. It supports HTTP, HTTPS, and FTP protocols, as well as retrieval through HTTP proxies.
用法:

第五节 字符串处理
正则表达式常用符号
| 符号 | 含义 |
|---|---|
| ^ | 匹配字符串开始位置的字符 |
| $ | 匹配字符串结束位置的字符 |
| . | 匹配任何一个字符 |
| * | 匹配前面的字符出现0~n次 |
| [a,m,u] | 匹配字符a或m或u |
| [a-z] | 匹配所有小写字母 |
| [A-Z] | 匹配所有大写字母 |
| [a-zA-Z] | 匹配所有字母 |
| [0-9] | 匹配所有数字 |
| 特殊符号转义 |
basename命令
返回路径字符串中的资源(文件或目录本身)部分
[root@apple w]# basename /aa/bb/cc/dd
dd
如果指定了后缀,basename会帮我们把后缀部分也去掉
[root@apple workspace]# basename /aa/bb/cc/dd.txt .txt
dd
dirname命令
返回路径字符串中的目录部分
[root@apple w]# dirname /aa/bb/cc/dd
/aa/bb/cc
cut命令
根据指定符号拆分字符串并提取。默认根据 拆分。
- -f参数:指定要提取的列
- -d参数:指定拆分依据的字符
准备测试数据:
[root@hadoop101 datas]$ touch cut.txt
[root@hadoop101 datas]$ vim cut.txt
dong shen
guan zhen
wo wo
lai lai
le le
切割提取第一列:
[root@hadoop101 datas]$ cut -d " " -f 1 cut.txt
dong
guan
wo
lai
le
切割提取第二、第三列:
[root@apple w]# cut -d " " -f 2,3 cut.txt
shen
zhen
wo
lai
la
在cut.txt中切出guan
[root@hadoop101 datas]$ cat cut.txt | grep "guan" | cut -d " " -f 1
guan
选取系统PATH变量值,第2个“:”开始后的所有路径:
[root@hadoop101 datas]$ echo $PATH
/usr/lib64/qt-3.3/bin:/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/sbin:/home/atguigu/bin
[root@hadoop101 datas]$ echo $PATH | cut -d : -f 2-
/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/sbin:/home/atguigu/bin
切割ifconfig 后打印的IP地址:
[root@apple w]# ifconfig | grep "netmask" | cut -d "i" -f 2 | cut -d " " -f 2
192.168.41.100
127.0.0.1
192.168.122.1
另一种做法:
[root@apple workspace]# ifconfig | grep netmask | cut -d " " -f 10
192.168.41.100
127.0.0.1
192.168.122.1
awk命令
一个强大的文本分析工具,把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行分析处理。
1、基本用法
awk [选项参数] ‘pattern1{action1} pattern2{action2}...’ filename
pattern:表示AWK在数据中查找的内容,就是匹配模式
action:在找到匹配内容时所执行的一系列命令
使用-F参数指定分隔符。
awk命令的内置变量包括:
| 变量名 | 说明 |
|---|---|
| FILENAME | 文件名 |
| NR | 已读取的记录 |
| NF | 浏览记录的域的个数(切割后,列的个数) |
2、测试
# 准备数据
[root@hadoop101 datas]$ sudo cp /etc/passwd ./
# 搜索passwd文件以root关键字开头的所有行,并输出该行的第7列。
[root@hadoop101 datas]$ awk -F: '/^root/{print $7}' passwd
/bin/bash
# 搜索passwd文件以root关键字开头的所有行,并输出该行的第1列和第7列,中间以“,”号分割。
[root@hadoop101 datas]$ awk -F: '/^root/{print $1","$7}' passwd
root,/bin/bash
# 只显示/etc/passwd的第一列和第七列,以逗号分割,且在所有行前面添加列名user,shell在最后一行添加"dahaige,/bin/zuishuai"。
[root@hadoop101 datas]$ awk -F : 'BEGIN{print "user, shell"} {print $1","$7} END{print "dahaige,/bin/zuishuai"}' passwd
user, shell
root,/bin/bash
bin,/sbin/nologin
。。。
atguigu,/bin/bash
dahaige,/bin/zuishuai
# 将passwd文件中的用户id增加数值1并输出
[root@hadoop101 datas]$ awk -v i=1 -F: '{print $3+i}' passwd
1
2
3
4
# 统计passwd文件名,每行的行号,每行的列数
[root@hadoop101 datas]$ awk -F: '{print "filename:" FILENAME ", linenumber:" NR ",columns:" NF}' passwd
filename:passwd, linenumber:1,columns:7
filename:passwd, linenumber:2,columns:7
filename:passwd, linenumber:3,columns:7
# 切割IP
[root@apple workspace]# ifconfig | awk -F " " '/netmask/{print $2}'
192.168.41.100
127.0.0.1
192.168.122.1
# 查询sed.txt中空行所在的行号
[root@hadoop101 datas]$ awk '/^$/{print NR}' sed.txt
5
PS:如果命令很长,可以使用反斜杠换行输入
[root@apple workspace]# awk -F :
> 'BEGIN{print "user shell"} {print $1" "$7} END{print "dahaige /bin/zuishuai"}'
> passwd
sort命令
sort命令是在Linux里非常有用,它将文件进行排序,并将排序结果标准输出。
| 参数名 | 作用 |
|---|---|
| -n | 依照数值大小排序 |
| -r | 相反顺序排序 |
| -t | 设置排序时使用的分隔字符 |
| -k | 指定需要排序的列 |
# 准备数据
[root@hadoop101 datas]$ touch sort.sh
[root@hadoop101 datas]$ vim sort.sh
bb:40:5.4
bd:20:4.2
xz:50:2.3
cls:10:3.5
ss:30:1.6
# 测试
[root@hadoop101 datas]$ sort -t : -nrk 3 sort.sh
bb:40:5.4
bd:20:4.2
cls:10:3.5
xz:50:2.3
ss:30:1.6
[root@apple workspace]# sort -nrt : -k 3 sort.txt
bb:40:5.4
bd:20:4.2
cls:10:3.5
xz:50:2.3
ss:30:1.6
xargs
1、情景举例
① 初始状态
某目录下包含下列资源:

② 需求
用一条命令删除所有名称中包含“sad”的资源,但是保留sad02
③ 分步实现
[1]列出全部资源

[2]列出名称中包含“sad”的资源
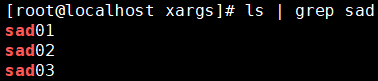
[3]进一步筛选排除sad02

此时最终筛选的结果打印到了标准输出:standard output。通过管道符号可以将标准输出转换为标准输入:standard input。但是删除命令rm不接受标准输入作为参数,只接受命令行参数。什么意思呢?

rm命令前面的管道符号把前面的stdout转换为了stdin再传输给rm命令,这种方式对于有些命令可以,但是有些命令不行。例如:mkdir、ls、rm等命令都是。什么是命令行参数呢?

[4]使用xargs命令将stdin转换为命令行参数

2、结论
xargs命令的作用:将管道符号提供的stdin数据转换为后面命令的命令行参数。
面试真题
1、京东
① 问题1:
使用Linux命令查询file1中空行所在的行号
[root@hadoop101 datas]$ awk '/^$/{print NR}' sed.txt
5
② 问题2:
有文件chengji.txt内容如下:
张三 40
李四 50
王五 60
使用Linux命令计算第二列的和并输出
[root@hadoop101 datas]$ cat chengji.txt | awk -F " " '{sum+=$2} END{print sum}'
150
[root@apple workspace]# awk '{sum+=$2} {print $1","$2} END{print "总分:"sum}' chengji.txt
张三,50
小红,60
小刚,100
总分:210
2、新浪
用shell写一个脚本,对文本中无序的一列数字排序
[root@CentOS6-2 ~]# cat test.txt
9
8
7
6
5
4
3
2
10
1
[root@CentOS6-2 ~]# sort -n test.txt|awk '{a+=$1;print $1}END{print "SUM="a}'
1
2
3
4
5
6
7
8
9
10
SUM=55
3、金和网络
请用shell脚本写出查找当前文件夹(/home)下所有的文本文件内容中包含有字符”shen”的文件名称
[root@hadoop101 datas]$ grep -r "shen" /home | cut -d ":" -f 1
/home/atguigu/datas/sed.txt
/home/atguigu/datas/cut.txt
[root@apple workspace]# grep -r "shen" /root/workspace/
/root/workspace/sed.txt:dong shen
/root/workspace/cut.txt:dong shen
[root@apple workspace]# grep -r "shen" /root/workspace/ | awk -F : '{print $1}'
/root/workspace/sed.txt
/root/workspace/cut.txt
[root@apple workspace]# grep -r "shen" /root/workspace/ | awk -F : '{print $1}' | awk -F '/' '{print $4}'
sed.txt
cut.txt