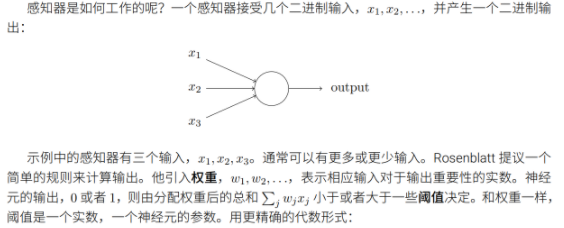
感知机
感知机:实现二分类(实际上,我们可以用感知机来计算任何简单的逻辑功能,后面会提到)
感知机有一个输出(0或1),表示具体的类别
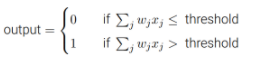
将代数式变换形式,有
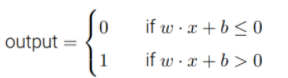
感知机:(通过配置可以模拟门电路,括号里的没感觉有啥用,但感觉很牛(doge))
我们可以用感知机来计算任何简单的逻辑功能:
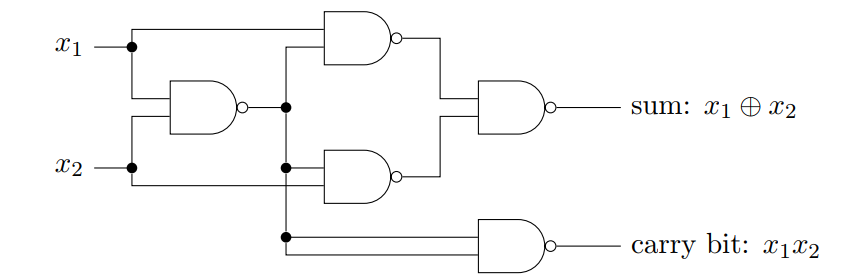
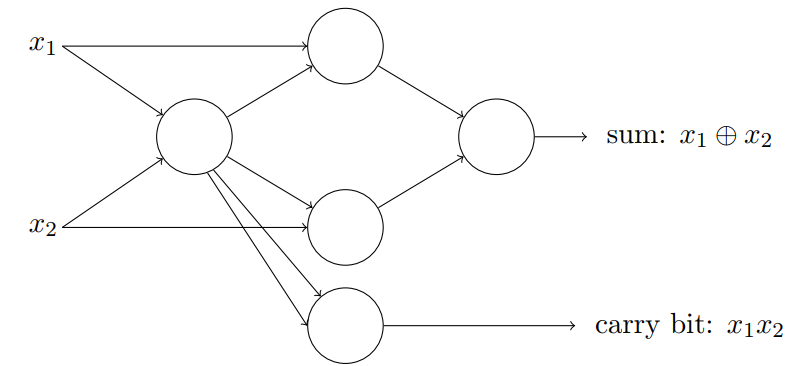
实际上,上图中每个感知机只有一个输出,只是被多次使用(为了看得好看)
S型神经元
S型神经元:S 型神经元和感知器类似,但是被修改为权重和偏置的微⼩改动只引起输出的微⼩变化
tips:感知机⽹络中单个感知器上⼀个权重或偏置的微⼩改动有时候会引起那个感知器的输出完全翻转,如 0 变到 1
$z=w*x+b$
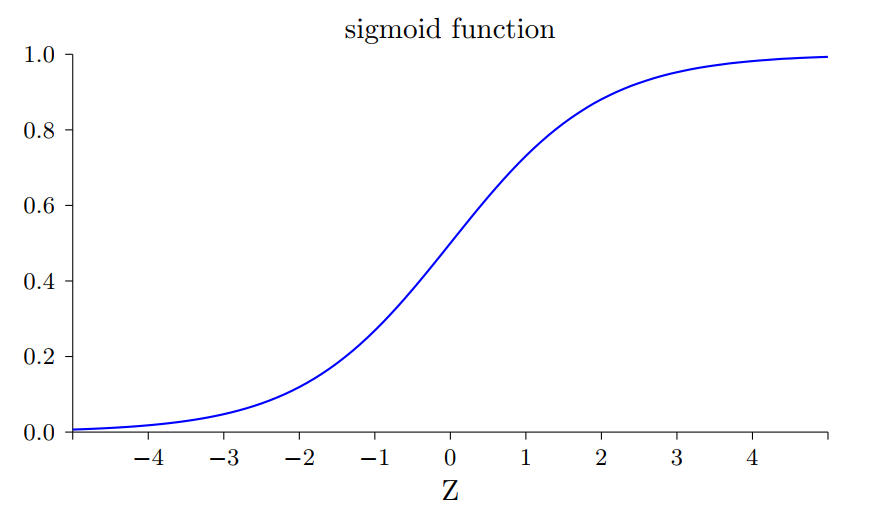
$\sigma(z)=\frac{1}{1+e^{-z}}$,其中$\sigma$被称为S型函数
把它们放在⼀起来更清楚地说明,⼀个具有输⼊ x1; x2; : : :,权重 w1; w2; : : :,和偏置 b 的 S型神经元的输出是: $\frac{1}{1+exp(-\sum_jw_jx_j-b)}$
tips:$\sigma$的精确形式不重要,重要的是他的形状。他是阶跃函数的平滑后的版本
神经网络的架构
神经网络的架构:输入侧,隐藏层,输出层
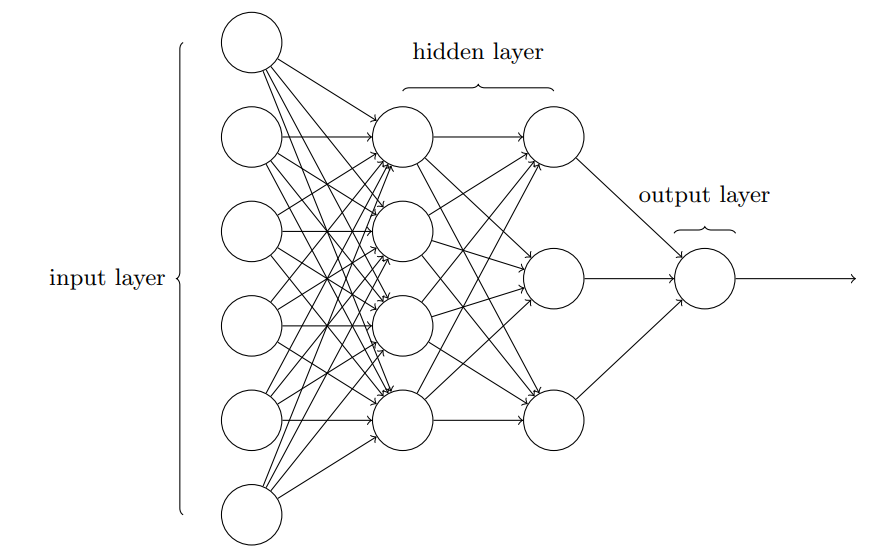
前馈神经⽹络 :以上⼀层的输出作为下⼀层的输⼊
递归神经网路:有可行的反馈环路(因为⼀个神经元的输出只在⼀段时间后⽽不是即刻影响它的输⼊,在这个模型中回路并不会引起问题)
使用梯度下降进行学习
使用梯度下降法进行学习:核心思想就是最小化代价函数
使用梯度下降进行迭代:如下
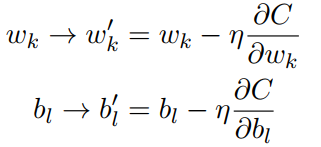
tips:值得提一下,对于改变代价函数大小的参数,和⽤于计算权重和偏置的小批量数据的更新规则,会有不同的约定。(可以自己下载一些相关代码看看)
模型参数:模型参数是根据数据自动估算的
模型超参数:模型超参数是手动设置的,并且在过程中用于帮助估计模型参数
模型参数和模型超参数的介绍:https://zhuanlan.zhihu.com/p/37476536
使用demo——手写数字识别 遇到的问题:实际上遇到的主要问题就是python3对python2的不兼容
先按照书上的记录进行执行,遇到问题再看下问题出在什么地方,在对照着一一解决
1、如果用pycharm这样的编译器就会有添加第三方库和自己的库的问题,第三方库如numpy 在网上和容易搜到。但是对自己定义的模块要是想import 的话就悲催了(对我这样的小白来说)
1)发现找不到import需要引用的模块了(就是找不到你想include的自己写的文件了):https://mp.weixin.qq.com/s/JCYzP3Xhf0RU3svEl-aIDg (注意,其中的打印库函数路径中print(requests.__file__)中的__是两个_) 或者可以直接复制这里的代码
import nmupy
print(numpy.__file__)
2)依然是上面的问题:也可以不用pycharm这样的编译器,可以用cmd命令窗口,将当前目录用 cd 命令(这个命令,网上自己查查)切换到包含你的main函数文件和自定义模块(需要被import的)的文件夹下,直接python your_mian.py 一下 就行了。其中your_main代指你自己的主函数
2、碰到了TypeError: object of type ‘zip’ has no len()这样的问题:https://blog.csdn.net/qq_37764129/article/details/89488367 。但是注意,他前面的替换(if test_data: n_test = len(test_data))我没用,只用了下图所示的内容。具体的可以自己试试。
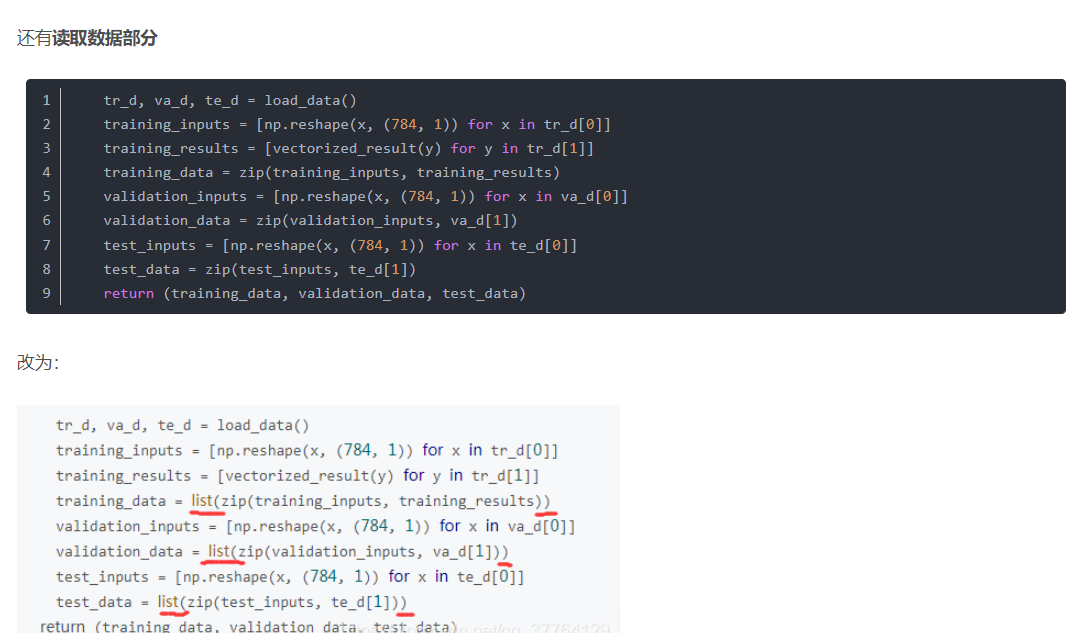
3、tips:书中的意思是在shell里面直接打入他的代码,我不太会搞。于是就把他的代码另外写了一个python文件,就放在我们cd 的文件夹中 在cmd中执行这个文件就行了。
MNIST数据集的标准化:通过在命令窗口查看mnist数据集中返回的数据,可以看到其中的单个像素的数值都不是灰度值,全都是0到1之间(这一点有待验证,从我看的几个数据好像是这样)
这是数据集标准化的介绍:https://blog.csdn.net/Harpoon_fly/article/details/84987589
mnist 数据集中的组织结构(以自己写的简化数据集为例,只展示形式,具体值都是瞎搞的):
通过数据集中自带的python脚本,最后返回到神经网络输入层的是归一化后的数据(应该为的是神经元的输入要在0,1之间)

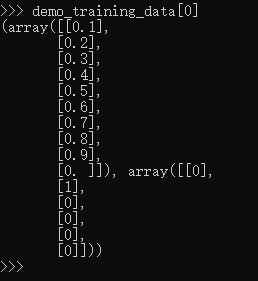
可以看到,demo_training_data里面有两个元素,分别为两幅图片和对应的标签。每个元素的组织是先是一个10维的向量,代表归一化的像素数据;然后是一个5维的向量(其中只有一个数是非0的,代表这张图是这个数)
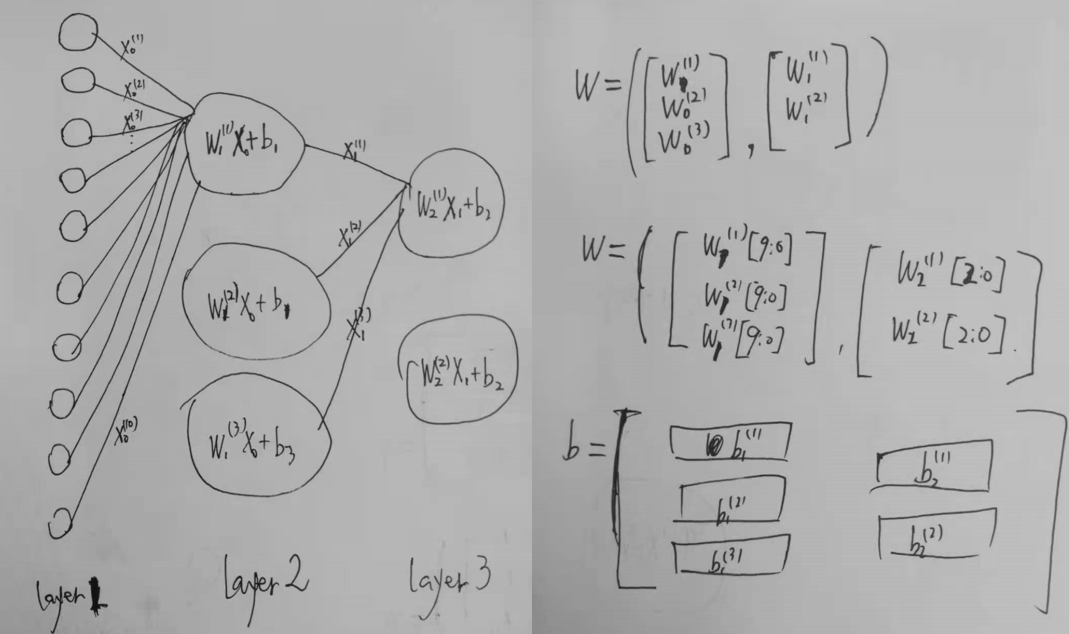
程序中feedforward里面的权重W,偏置的组织形式:(以Network[10,3,2]为例,即三层神经网络,各层神经元个数分别为10,3,2,)
网络示意图:如下(其中的上标、下标是自己写的,只是为了理解,标准的下标标注方法请自行到标准教材或论文中查看)
$W=\begin{pmatrix}
W_1^{[1]}[9:0]& W_2^{[1]}[2:0]\\
W_1^{(2)}[9:0]& W_2^{[2]}[2:0]\\
W_1^{(3)}[9:0]&
\end{pmatrix}$
$b=\begin{pmatrix}
b_1^{(1)}& b_2^{(1)}\\
b_1^{(2)}& b_2^{(2)}\\
b_1^{(3)}&
\end{pmatrix}$
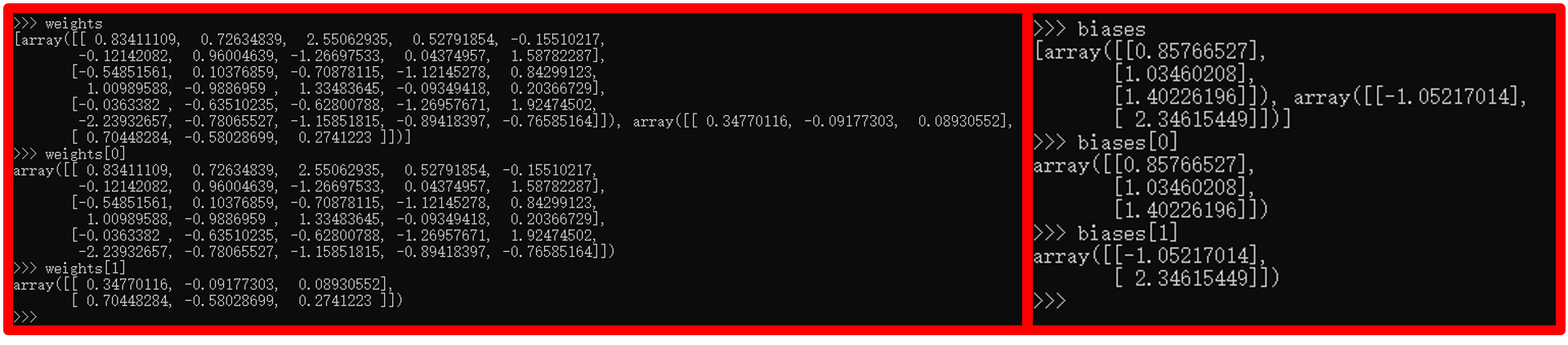
这里weigths,biases是自己写的例子以Network[10,3,2]为例,不是实际的数据集。但可以看到weights的组织形式,weights有两个元素,一个是3*1的列表(列表内是10维向量),对应对输入层的输出的权重$W_1$,这个$W_1$在上上图中显示在layer2中的神经元中;以此类推weights的第二个列表元素显示在layer3中的神经元中。biases有两个元素,一个是3*1的列表(列表就是一个数),对应上上图中显示在layer2中的神经元中;以此类推biases的第二个列表元素显示在layer3中的神经元中。
tips:这里有三层网络,但是权重只有对layer1输出$X_0【10个】$的权重$W_1【3*1*10个】$,对layer2输出$X_1【3个】$的权重$W_2【2*1*3个】$偏置只有对layer1中计算有$b_1【3*1*1个】$,对layer2中计算有$b_2【2*1*1个】$
这里讲述的下标可能会有些乱,大概表现的意思就是,第一层神将元内部没有权重和偏置(因为这里的第一层为输入层)
手写数字识别代码
可以从这里下载数据和代码:https://github.com/mnielsen/neural-networks-and-deep-learning/archive/master.zip
因为python版本问题,自己把代码改了点:
代码如下:


import mnist_loader import network training_data, validation_data, test_data = mnist_loader.load_data_wrapper() net = network.Network([784, 30, 10]) #设置有3层网络,各层神经元个数为784,30,10 net.SGD(training_data,30, 10, 3.0, test_data=test_data) #迭代30次,
""" mnist_loader ~~~~~~~~~~~~ A library to load the MNIST image data. For details of the data structures that are returned, see the doc strings for ``load_data`` and ``load_data_wrapper``. In practice, ``load_data_wrapper`` is the function usually called by our neural network code. """ #### Libraries # Standard library #import cPickle # in python3.X,this package is changed,you can use this :"import _pickle as cPickle" to use import _pickle as cPickle import gzip # Third-party libraries import numpy as np def load_data(): """Return the MNIST data as a tuple containing the training data, the validation data, and the test data. The ``training_data`` is returned as a tuple with two entries. The first entry contains the actual training images. This is a numpy ndarray with 50,000 entries. Each entry is, in turn, a numpy ndarray with 784 values, representing the 28 * 28 = 784 pixels in a single MNIST image. The second entry in the ``training_data`` tuple is a numpy ndarray containing 50,000 entries. Those entries are just the digit values (0...9) for the corresponding images contained in the first entry of the tuple. The ``validation_data`` and ``test_data`` are similar, except each contains only 10,000 images. This is a nice data format, but for use in neural networks it's helpful to modify the format of the ``training_data`` a little. That's done in the wrapper function ``load_data_wrapper()``, see below. """ #f = gzip.open('../data/mnist.pkl.gz', 'rb') #f = gzip.open('C:/Users/ASICLAB/Desktop/neural-networks-and-deep-learning/data/mnist.pkl.gz', 'rb') f = gzip.open('./mnist.pkl.gz', 'rb') #training_data, validation_data, test_data = cPickle.load(f) training_data, validation_data, test_data = cPickle.load(f, encoding='bytes') f.close() return (training_data, validation_data, test_data) def load_data_wrapper(): """Return a tuple containing ``(training_data, validation_data, test_data)``. Based on ``load_data``, but the format is more convenient for use in our implementation of neural networks. In particular, ``training_data`` is a list containing 50,000 2-tuples ``(x, y)``. ``x`` is a 784-dimensional numpy.ndarray containing the input image. ``y`` is a 10-dimensional numpy.ndarray representing the unit vector corresponding to the correct digit for ``x``. ``validation_data`` and ``test_data`` are lists containing 10,000 2-tuples ``(x, y)``. In each case, ``x`` is a 784-dimensional numpy.ndarry containing the input image, and ``y`` is the corresponding classification, i.e., the digit values (integers) corresponding to ``x``. Obviously, this means we're using slightly different formats for the training data and the validation / test data. These formats turn out to be the most convenient for use in our neural network code.""" # tr_d, va_d, te_d = load_data() # training_inputs = [np.reshape(x, (784, 1)) for x in tr_d[0]] # training_results = [vectorized_result(y) for y in tr_d[1]] # training_data = zip(training_inputs, training_results) # validation_inputs = [np.reshape(x, (784, 1)) for x in va_d[0]] # validation_data = zip(validation_inputs, va_d[1]) # test_inputs = [np.reshape(x, (784, 1)) for x in te_d[0]] # test_data = zip(test_inputs, te_d[1]) # return (training_data, validation_data, test_data) tr_d, va_d, te_d = load_data() training_inputs = [np.reshape(x, (784, 1)) for x in tr_d[0]] training_results = [vectorized_result(y) for y in tr_d[1]] training_data = list(zip(training_inputs, training_results)) validation_inputs = [np.reshape(x, (784, 1)) for x in va_d[0]] validation_data = list(zip(validation_inputs, va_d[1])) test_inputs = [np.reshape(x, (784, 1)) for x in te_d[0]] test_data = list(zip(test_inputs, te_d[1])) return (training_data, validation_data, test_data) def vectorized_result(j): """Return a 10-dimensional unit vector with a 1.0 in the jth position and zeroes elsewhere. This is used to convert a digit (0...9) into a corresponding desired output from the neural network.""" e = np.zeros((10, 1)) e[j] = 1.0 return e
""" network.py ~~~~~~~~~~ A module to implement the stochastic gradient descent learning algorithm for a feedforward neural network. Gradients are calculated using backpropagation. Note that I have focused on making the code simple, easily readable, and easily modifiable. It is not optimized, and omits many desirable features. """ # C:\Users\ASICLAB\Desktop\neural-networks-and-deep-learning\data #### Libraries # Standard library import random # Third-party libraries from imp import reload import numpy as np import mnist_loader # Use mnist_data # import sys # reload(sys) # sys.setdefaultencoding("utf-8") class Network(object): #python中类的讲解 https://www.liaoxuefeng.com/wiki/1016959663602400/1017496031185408 def __init__(self, sizes): #以下所有的都以Network[10,3,2]举例即三层,各层神经元个数为10,3,2 """The list ``sizes`` contains the number of neurons in the respective layers of the network. For example, if the list was [2, 3, 1] then it would be a three-layer network, with the first layer containing 2 neurons, the second layer 3 neurons, and the third layer 1 neuron. The biases and weights for the network are initialized randomly, using a Gaussian distribution with mean 0, and variance 1. Note that the first layer is assumed to be an input layer, and by convention we won't set any biases for those neurons, since biases are only ever used in computing the outputs from later layers.""" self.num_layers = len(sizes) self.sizes = sizes self.biases = [np.random.randn(y, 1) for y in sizes[1:]] #randn函数返回一个或一组样本,具有标准正态分布 https://blog.csdn.net/u012149181/article/details/78913167 #其中还有列表生成式 https://www.liaoxuefeng.com/wiki/1016959663602400/1017317609699776 #sizes[1:]不包含第一行,是因为输入层不需要偏置、权值(若分配的是Network[10,3,2]) #这一行作用是为隐藏层和输出层随机分配符合正态分布的权值,输入层不分配,因为不需要 self.weights = [np.random.randn(y, x) for x, y in zip(sizes[:-1], sizes[1:])] # def feedforward(self, a): """Return the output of the network if ``a`` is input.""" for b, w in zip(self.biases, self.weights): a = sigmoid(np.dot(w, a)+b) #加权重,偏置,激活函数,注意:此处是输入的a是外部输入的像素数据(784维),进入之后通过循环先与隐藏层的权重、偏置、激活得到a #之后,通过这个循环,将这个由隐藏层得到的a用输出层的权重、偏置、激活进行计算得到最终输出 return a def SGD(self, training_data, epochs, mini_batch_size, eta, test_data=None): """Train the neural network using mini-batch stochastic gradient descent. The ``training_data`` is a list of tuples ``(x, y)`` representing the training inputs and the desired outputs. The other non-optional parameters are self-explanatory. If ``test_data`` is provided then the network will be evaluated against the test data after each epoch, and partial progress printed out. This is useful for tracking progress, but slows things down substantially.""" if test_data: n_test = len(test_data) #得到测试集数据个数 #if test_data: n_test = list(range(len(test_data))) n = len(training_data) #得到训练集数据个数 for j in range(epochs): random.shuffle(training_data) #shuffle函数表示将训练集中的数据随机排列 mini_batches = [ training_data[k:k+mini_batch_size] #每次迭代从训练集中选取mini_batch_size个数据作为迷你数据集(其中每个数据就是一张图片的数据) for k in range(0, n, mini_batch_size)] #每次迭代选取3个连续数据的起始数据随每次迭代进行加mini_batch_size个(由于数据集每次迭代都会被打乱,因此不是顺序的) for mini_batch in mini_batches: self.update_mini_batch(mini_batch, eta) if test_data: print ("Epoch {0}: {1} / {2}".format( #format为格式化输出函数,https://zhuanlan.zhihu.com/p/34827570 j, self.evaluate(test_data), n_test)) else: print ("Epoch {0} complete".format(j)) def update_mini_batch(self, mini_batch, eta): """Update the network's weights and biases by applying gradient descent using backpropagation to a single mini batch. The ``mini_batch`` is a list of tuples ``(x, y)``, and ``eta`` is the learning rate.""" nabla_b = [np.zeros(b.shape) for b in self.biases] nabla_w = [np.zeros(w.shape) for w in self.weights] for x, y in mini_batch: #mini_batch是几个(和外部输入有关)元组的集合(元组就是带标签的图片) delta_nabla_b, delta_nabla_w = self.backprop(x, y) nabla_b = [nb+dnb for nb, dnb in zip(nabla_b, delta_nabla_b)] nabla_w = [nw+dnw for nw, dnw in zip(nabla_w, delta_nabla_w)] self.weights = [w-(eta/len(mini_batch))*nw for w, nw in zip(self.weights, nabla_w)] self.biases = [b-(eta/len(mini_batch))*nb for b, nb in zip(self.biases, nabla_b)] def backprop(self, x, y): """Return a tuple ``(nabla_b, nabla_w)`` representing the gradient for the cost function C_x. ``nabla_b`` and ``nabla_w`` are layer-by-layer lists of numpy arrays, similar to ``self.biases`` and ``self.weights``.""" nabla_b = [np.zeros(b.shape) for b in self.biases] nabla_w = [np.zeros(w.shape) for w in self.weights] # feedforward activation = x activations = [x] # list to store all the activations, layer by layer zs = [] # list to store all the z vectors, layer by layer for b, w in zip(self.biases, self.weights): z = np.dot(w, activation)+b zs.append(z) activation = sigmoid(z) activations.append(activation) # backward pass delta = self.cost_derivative(activations[-1], y) * \ sigmoid_prime(zs[-1]) nabla_b[-1] = delta nabla_w[-1] = np.dot(delta, activations[-2].transpose()) # Note that the variable l in the loop below is used a little # differently to the notation in Chapter 2 of the book. Here, # l = 1 means the last layer of neurons, l = 2 is the # second-last layer, and so on. It's a renumbering of the # scheme in the book, used here to take advantage of the fact # that Python can use negative indices in lists. for l in range(2, self.num_layers): z = zs[-l] sp = sigmoid_prime(z) delta = np.dot(self.weights[-l+1].transpose(), delta) * sp nabla_b[-l] = delta nabla_w[-l] = np.dot(delta, activations[-l-1].transpose()) return (nabla_b, nabla_w) def evaluate(self, test_data): #因为只有一层隐藏层,所以只进行一次偏置、激活预算就得到最终结果(相当于10位二进制数),并与标准结果进行比较 """Return the number of test inputs for which the neural network outputs the correct result. Note that the neural network's output is assumed to be the index of whichever neuron in the final layer has the highest activation.""" test_results = [(np.argmax(self.feedforward(x)), y) #此结果是从w*x+b的结果中选取最大的值的索引并输出(这个索引) for (x, y) in test_data] return sum(int(x == y) for (x, y) in test_results) def cost_derivative(self, output_activations, y): """Return the vector of partial derivatives \partial C_x / \partial a for the output activations.""" return (output_activations-y) #### Miscellaneous functions def sigmoid(z): """The sigmoid function.""" return 1.0/(1.0+np.exp(-z)) def sigmoid_prime(z): """Derivative of the sigmoid function.""" return sigmoid(z)*(1-sigmoid(z))
import numpy as np import random sizes=[10,3,2] num_layers = len(sizes) size = sizes biases = [np.random.randn(y, 1) for y in sizes[1:]] #sizes[1:]不包含第一列,是因为输入层不需要偏置、权值 weights = [np.random.randn(y, x) for x, y in zip(sizes[:-1], sizes[1:])] #print(num_layers) #print(biases) a=np.array([[1],[2],[3],[4],[5],[6],[7],[8],[9],[10]]) b=np.array([[11],[22],[33],[44],[55]]) c=np.array([[3],[4],[5],[6],[7],[8],[9],[10],[11],[10]]) d=np.array([[33],[44],[55],[66],[77]]) A=[(a,b),(c,d)] #[np.random.randn(2, 1) #生成一个维度为2*1且符合正态分布的数据 def feedforward( a): """Return the output of the network if ``a`` is input.""" for b, w in zip(biases, weights): a = sigmoid(np.dot(w, a)+b) #加权重,偏置,激活函数, return a def sigmoid(z): """The sigmoid function.""" return 1.0/(1.0+np.exp(-z)) #results = [(np.argmax(feedforward(x)), y) #for (x, y) in A] DD=[(np.argmax(feedforward(x)), y) for (x, y) in A] print('DD=',DD) # a=np.array([[1],[2],[3],[4],[5],[6],[7],[8],[9],[10]]) # b=np.array([[11],[22],[33],[44],[55]]) # c=np.array([[3],[4],[5],[6],[7],[8],[9],[10],[11],[12]]) # d=np.array([[33],[44],[55],[66],[77]]) # # A=[(a,b),(c,d)] # n=0 # # for x,y in A: # n=n + 1 # #print('x=\n',x) # #print('y=\n',y) # #print('n=\n',n) # # print('x=',x,'y=',y,'n=',n) # # B=[[x,y] for x,y in A] # print('B=\n',B) # # results = [(np.argmax(x), y) # for (x, y) in A] # print('results=\n',results)
要运行代码,还要进数据集放在和代码相同的问价夹下:
tips:其中test_demo是为了模拟了解数据集的组织结构编的代码,不是手写数字识别代码的一部分