每一个TCP套接口有一个发送缓冲区,可以用SO_SNDBUF套接口选项来改变这个缓冲区的大小。当应用进程调用 write时,内核从应用进程的缓冲区中拷贝所有数据到套接口的发送缓冲区。如果套接口的发送缓冲区容不下应用程序的所有数据(或是应用进程的缓冲区大于 套接口发送缓冲区,或是套接口发送缓冲区还有其他数据),应用进程将被挂起(睡眠)。这里假设套接口是阻塞的,这是通常的缺省设置。内核将不从write 系统调用返回,直到应用进程缓冲区中的所有数据都拷贝到套接口发送缓冲区。因此从写一个TCP套接口的write调用成功返回仅仅表示我们可以重新使用应 用进程的缓冲区。它并不告诉我们对端的 TCP或应用进程已经接收了数据。
TCP取套接口发送缓冲区的数据并把它发送给对端TCP,其过程基于TCP数据传输的所有规则。对端TCP必须确认收到的数据,只有收到对端的ACK,本端TCP才能删除套接口发送缓冲区中已经确认的数据。TCP必须保留数据拷贝直到对端确认为止。
任何UDP套接字也有缓冲区大小,不过它仅仅是可写到该套接字的UDP数据报的大小上线,如果一个应用进程写一个大于套接字发送缓冲区大小的数据报,内核将返回一个EMSGSIZE错误,既然UDP是不可靠的,他不必保存应用进程数据的副本因此不需一个真正的缓冲区。(应用进程的数据在沿协议栈向下传递时,通常被复制到某种格式的一个内核缓冲区中,然而当数据被发送后,这个副本被数据链路层丢弃了)
write()
函数定义:ssize_t write (int fd, const void * buf, size_t count);
函数说明:write()会把参数buf所指的内存写入count个字节到参数放到所指的文件内。write成功返回,只是buf中的数据被复制到了kernel中的TCP发送缓冲区。至于数据什么时候被发往网络,什么时候被对方主机接收,什么时候被对方进程读取,系统调用层面不会给予任何保证和通知。write在什么情况下会阻塞?当kernel的该socket的发送缓冲区已满时。对于每个socket,拥有自己的send buffer和receive buffer。从Linux 2.6开始,两个缓冲区大小都由系统来自动调节(autotuning),但一般在default和max之间浮动。已经发送到网络的数据依然需要暂存在send buffer中,只有收到对方的ack后,kernel才从buffer中清除这一部分数据,为后续发送数据腾出空间。接收端将收到的数据暂存在receive buffer中,自动进行确认。但如果socket所在的进程不及时将数据从receive buffer中取出,最终导致receive buffer填满,由于TCP的滑动窗口和拥塞控制,接收端会阻止发送端向其发送数据。这些控制皆发生在TCP/IP栈中,对应用程序是透明的,应用程序继续发送数据,最终导致send buffer填满,write调用阻塞。
返回值:如果顺利write()会返回实际写入的字节数。当有错误发生时则返回-1,错误代码存入errno中。
附加说明:
- write()函数返回值一般无0,只有当如下情况发生时才会返回0:write(fp, p1+len, (strlen(p1)-len)中第三参数为0,此时write()什么也不做,只返回0。
- write()函数从buf写数据到fd中时,若buf中数据无法一次性读完,那么第二次读buf中数据时,其读位置指针(也就是第二个参数buf)不会自动移动,需要程序员编程控制,而不是简单的将buf首地址填入第二参数即可。如可按如下格式实现读位置移动:write(fp, p1+len, (strlen(p1)-len)。 这样write第二次循环时变会从p1+len处写数据到fp, 之后的也由此类推,直至(strlen(p1)-len变为0。
- 在write一次可以写的最大数据范围内(貌似是BUFSIZ ,8192),第三参数count大小最好为buf中数据的大小,以免出现错误。(经过笔者再次试验,write一次能够写入的并不只有8192这么多,笔者尝试一次写入81920000,结果也是可以,看来其一次最大写入数据并不是8192,但内核中确实有BUFSIZ这个参数,具体指什么还有待研究)
#include <string.h> #include <stdio.h> #include <fcntl.h> int main() { char *p1 = "This is a c test code"; volatile int len = 0; int fp = open("/home/test.txt", O_RDWR|O_CREAT); for(;;) { int n; if((n=write(fp, p1+len, (strlen(p1)-len)))== 0) //if((n=write(fp, p1+len, 3)) == 0) { //strlen(p1) = 21 printf("n = %d ", n); break; } len+=n; } return 0; }
此程序中的字符串"This is a c test code"有21个字符,经笔者亲自试验,若write时每次写3个字节,虽然可以将p1中数据写到fp中,但文件test.txt中会带有很多乱码。唯一正确的做法还是将第三参数设为(strlen(p1) - len,这样当write到p1末尾时(strlen(p1) - len将会变为0,此时符合附加说明(1)中所说情况,write返回0, write结束。
写的本质也不是进行发送操作,而是把用户态的数据copy 到系统底层去,然后再由系统进行发送操作,send,write返回成功,只表示数据已经copy 到底层缓冲,而不表示数据已经发出,更不能表示对方端口已经接收到数据.
对于write(或者send)而言,
阻塞情况下
阻塞情况下,write会将数据发送完。(不过可能被中断),在阻塞的情况下,是会一直等待,直到write 完,全部的数据再返回.这点行为上与读操作有所不同。
原因:
读,究其原因主要是读数据的时候我们并不知道对端到底有没有数据,数据是在什么时候结束发送的,如果一直等待就可能会造成死循环,所以并没有去进行这方面的处理;
写,而对于write, 由于需要写的长度是已知的,所以可以一直再写,直到写完.不过问题是write 是可能被打断吗,造成write 一次只write 一部分数据, 所以write 的过程还是需要考虑循环write, 只不过多数情况下次write 调用就可能成功.
非阻塞情况下
非阻塞写的情况下,是采用可以写多少就写多少的策略.与读不一样的地方在于,有多少读多少是由网络发送的那一端是否有数据传输到为标准,但是对于可以写多少是由本地的网络堵塞情况为标准的,在网络阻塞严重的时候,网络层没有足够的内存来进行写操作,这时候就会出现写不成功的情况,阻塞情况下会尽可能(有可能被中断)等待到数据全部发送完毕, 对于非阻塞的情况就是一次写多少算多少,没有中断的情况下也还是会出现write 到一部分的情况.
read()
函数定义:ssize_t read(int fd, void * buf, size_t count);
函数说明:read()会把参数fd所指的文件传送count 个字节到buf 指针所指的内存中。
参数 count 是请求读取的字节数,读上来的数据保存在缓冲区buf中,同时文件的当前读写位置向后移。注意这个读写位置和使用C标准I/O库时的读写位置有可能不同,这个读写位置是记在内核中的,而使用C标准I/O库时的读写位置是用户空间I/O缓冲区中的位置。比如用fgetc读一个字节,
fgetc有可能从内核中预读1024个字节到I/O缓冲区中,再返回第一个字节,这时该文件在内核中记录的读写位置是1024,而在FILE结构体中记录的读写位置是1。注意返回值类型是ssize_t,表示有符号的size_t,这样既可以返回正的字节数、0(表示到达文件末尾)也可以返回负值-1(表示出错) read函数返回时,返回值说明了buf中前多少个字节是刚读上来的。有些情况下,实际读到的字节数(返回值)会小于请求读的字节数count,例如:读常规文件时,在读到count个字节之前已到达文件末尾。例如,距文件末尾还有30个字节而请求读100个字节,则read返回30,下次read将返回0。
从终端设备读,通常以行为单位,读到换行符就返回了。
从网络读,根据不同的传输层协议和内核缓存机制,返回值可能小于请求的字节数
返回值:返回值为实际读取到的字节数, 如果返回0, 表示已到达文件尾或是无可读取的数据。若参数count 为0, 则read()不会有作用并返回0。
注意:
read时fd中的数据如果小于要读取的数据,就会引起阻塞。
对一个管道的read只要管道中有数据,立马返回,不必等待达到所请求的字节数
read 的原则:
数据在不超过指定的长度的时候有多少读多少,没有数据就会一直等待。所以一般情况下::我们读取数据都需要采用循环读的方式读取数据,因为一次read 完毕不能保证读到我们需要长度的数据,read 完一次需要判断读到的数据长度再决定是否还需要再次读取。
阻塞情况下
在阻塞条件下,read/recv/msgrcv的行为:
- 如果没有发现数据在网络缓冲中会一直等待,
- 当发现有数据的时候会把数据读到用户指定的缓冲区,但是如果这个时候读到的数据量比较少,比参数中指定的长度要小,read 并不会一直等待下去,而是立刻返回
非阻塞情况下
在非阻塞的情况下,read 的行为
- 如果发现没有数据就直接返回,
- 如果发现有数据那么也是采用有多少读多少的进行处理.
所以read 完一次需要判断读到的数据长度再决定是否还需要再次读取。
对于读而言:阻塞和非阻塞的区别在于没有数据到达的时候是否立刻返回.
recv 中有一个MSG_WAITALL 的参数
recv(sockfd, buff, buff_size, MSG_WAITALL),
在正常情况下recv 是会等待直到读取到buff_size 长度的数据,但是这里的WAITALL 也只是尽量读全,在有中断的情况下recv 还是可能会被打断,造成没有读完指定的buff_size的长度。
所以即使是采用recv + WAITALL 参数还是要考虑是否需要循环读取的问题,在实验中对于多数情况下recv (使用了MSG_WAITALL)还是可以读完buff_size,
所以相应的性能会比直接read 进行循环读要好一些。
注意
使用MSG_WAITALL时,sockfd必须处于阻塞模式下,否则不起作用。
所以MSG_WAITALL不能和MSG_NONBLOCK同时使用。
要注意的是使用MSG_WAITALL的时候,sockfd 必须是处于阻塞模式下,否则WAITALL不能起作用。
非阻塞I/O的概念
当进程调用一个阻塞的系统函数时,该进程被置于睡眠(Sleep)状态,这时内核调度其它进程运行,直到该进程等待的事件发生了(比如网络上接收到数据包,或者调用sleep指定的睡眠时间到了)它才有可能继续运行。与睡眠状态相对的是运行(Running)状态,在Linux内核中,处于运行状态的进程分为两种情况:
- 正在被调度执行。CPU处于该进程的上下文环境中,程序计数器(eip)里保存着该进程的指令地址,通用寄存器里保存着该进程运算过程的中间结果,正在执行该进程的指令,正在读写该进程的地址空间。
- 就绪状态。该进程不需要等待什么事件发生,随时都可以执行,但CPU暂时还在执行另一个进程,所以该进程在一个就绪队列中等待被内核调度。系统中可能同时有多个就绪的进程,那么该调度谁执行呢?内核的调度算法是基于优先级和时间片的,而且会根据每个进程的运行情况动态调整它的优先级和时间片,让每个进程都能比较公平地得到机会执行,同时要兼顾用户体验,不能让和用户交互的进程响应太慢。
如果在open一个设备时指定了O_NONBLOCK标志,read/write就不会阻塞。以read为例,如果设备暂时没有数据可读就返回-1,同时置errno为EWOULDBLOCK(或者EAGAIN,这两个宏定义的值相同),表示本来应该阻塞在这里(would block,虚拟语气),事实上并没有阻塞而是直接返回错误,调用者应该试着再读一次(again)。这种行为方式称为轮询(Poll),调用者只是查询一下,而不是阻塞在这里死等,这样可以同时监视多个设备:
while(true) { 非阻塞read(设备1); if(设备1有数据到达) 处理数据; 非阻塞read(设备2); if(设备2有数据到达) 处理数据; ... }
如果read(设备1)是阻塞的,那么只要设备1没有数据到达就会一直阻塞在设备1的read调用上,即使设备2有数据到达也不能处理,使用非阻塞I/O就可以避免设备2得不到及时处理。
非阻塞I/O有一个缺点,如果所有设备都一直没有数据到达,调用者需要反复查询做无用功,如果阻塞在那里,操作系统可以调度别的进程执行,就不会做无用功了。在使用非阻塞I/O时,通常不会在一个while循环中一直不停地查询(这称为Tight Loop),而是每延迟等待一会儿来查询一下,以免做太多无用功,在延迟等待的时候可以调度其它进程执行。
while(true) { 非阻塞read(设备1); if(设备1有数据到达) 处理数据; 非阻塞read(设备2); if(设备2有数据到达) 处理数据; ... sleep(n); }
这样做的问题是,设备1有数据到达时可能不能及时处理,最长需延迟n秒才能处理,而且反复查询还是做了很多无用功。而select/poll/epoll 等函数可以阻塞地同时监视多个设备,还可以设定阻塞等待的超时时间,从而圆满地解决了这个问题。
整个write过程
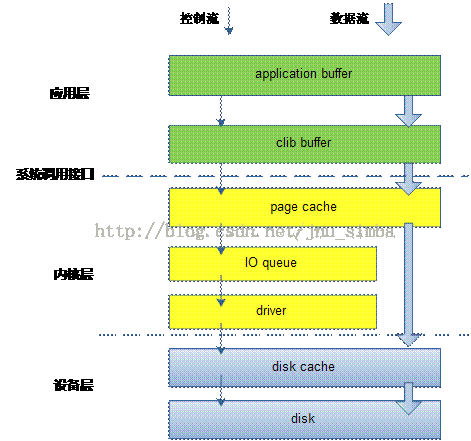
3.下面是整个write过程
- glibc write是将app_buffer->libc_buffer->page_cache
- write是将app_buffer->page_cache
- mmap可以直接获取page_cache直写
- write+O_DIRECT的话将app_buffer写到io_queue里面
- io_queue一方面将写邻近扇区的内容进行merge,另外一方面进行排序确保磁头和磁 盘旋转最少。
- io_queue的工作也需要结合IO调度算法。不过这些仅仅对于physical disk有效。
- 对于ssd而言的话,因为完全是随机写,基本没有调度算法。
- driver(filesystem module)通过DMA写入disk_cache之后(使用fsync就可以强制刷新)到disk上面了。
- 直接操作设备(RAW)方式直接写disk_cache.
O_DIRECT 和 RAW设备最根本的区别是O_DIRECT是基于文件系统的,也就是在应用层来看,其操作对象是文件句柄,内核和文件层来看,其操作是基于inode和数据块,这些概念都是和ext2/3的文件系统相关,写到磁盘上最终是ext3文件。而RAW设备写是没有文件系统概念,操作的是扇区号,操作对象是扇区,写出来的东西不一定是ext3文件(如果按照ext3规则写就是ext3文件)。一般基于O_DIRECT来设计优化自己的文件模块,是不满系统的cache和调度策略,自己在应用层实现这些,来制定自己特有的业务特色文件读写。但是写出来的东西是ext3文件,该磁盘卸下来,mount到其他任何linux系统上,都可以查看。而基于RAW设备的设计系统,一般是不满现有ext3的诸多缺陷,设计自己的文件系统。自己设计文件布局和索引方式。举个极端例子:把整个磁盘做一个文件来写,不要索引。这样没有inode限制,没有文件大小限制,磁盘有多大,文件就能多大。这样的磁盘卸下来,mount到其他linux系统上,是无法识别其数据的。两者都要通过驱动层读写;在系统引导启动,还处于实模式的时候,可以通过bios接口读写raw设备。
操作系统为了提高文件读写效率,在内核层提供了读写缓冲区。对于磁盘的写并不是立刻写入磁盘, 而是首先写入页面缓冲区然后定时刷到硬盘上。但是这种机制降低了文件更新速度,并且如果系统发生故障 的话,那么会造成部分数据丢失。这里的3个sync函数就是为了这个问题的。
- sync.是强制将所有页面缓冲区都更新到磁盘上。
- fsync.是强制将某个fd涉及到的页面缓存更新到磁盘上(包括文件属性等信息).
- fdatasync.是强制将某个fd涉及到的数据页面缓存更新到磁盘上。