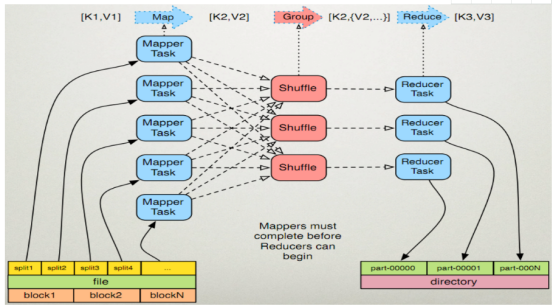
MapReduce的执行步骤:
1、Map任务处理
1.1 读取HDFS中的文件。每一行解析成一个<k,v>。每一个键值对调用一次map函数。 <0,hello you> <10,hello me>
1.2 覆盖map(),接收1.1产生的<k,v>,进行处理,转换为新的<k,v>输出。 <hello,1> <you,1> <hello,1> <me,1>
1.3 对1.2输出的<k,v>进行分区。默认分为一个区。详见《Partitioner》
1.4 对不同分区中的数据进行排序(按照k)、分组。分组指的是相同key的value放到一个集合中。 排序后:<hello,1> <hello,1> <me,1> <you,1> 分组后:<hello,{1,1}><me,{1}><you,{1}>
1.5 (可选)对分组后的数据进行归约。详见《Combiner》
Combiner编程(1.5可选步骤,视情况而定!)
每一个map可能会产生大量的输出,combiner的作用就是在map端对输出先做一次合并,以减少传输到reducer的数据量。
combiner最基本是实现本地key的归并,combiner具有类似本地的reduce功能。 如果不用combiner,那么,所有的结果都是reduce完成,效率会相对低下。使用combiner,先完成的map会在本地聚合,提升速度。
注意:Combiner的输出是Reducer的输入,Combiner绝不能改变最终的计算结果。所以从我的想法来看,Combiner只应该用于那种Reduce的输入key/value与输出key/value类型完全一致,且不影响最终结果的场景。比如累加,最大值等。
2、Reduce任务处理
2.1 多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点上。
/////////////////////////////////////////////////////////////////////////////

Map端:
1、在map端首先接触的是InputSplit,在InputSplit中含有DataNode中的数据,每一个InputSplit都会分配一个Mapper任务,Mapper任务结束后产生<K2,V2>的输出,这些输出先存放在缓存中,每个map有一个环形内存缓冲区,用于存储任务的输出。默认大小100MB(io.sort.mb属性),一旦达到阀值0.8(io.sort.spil l.percent),一个后台线程就把内容写到(spill)Linux本地磁盘中的指定目录(mapred.local.dir)下的新建的一个溢出写文件。(注意:map过程的输出是写入本地磁盘而不是HDFS,但是一开始数据并不是直接写入磁盘而是缓冲在内存中,缓存的好处就是减少磁盘I/O的开销,提高合并和排序的速度。又因为默认的内存缓冲大小是100M(当然这个是可以配置的),所以在编写map函数的时候要尽量减少内存的使用,为shuffle过程预留更多的内存,因为该过程是最耗时的过程。)
2、写磁盘前,要进行partition、sort和combine等操作。通过分区,将不同类型的数据分开处理,之后对不同分区的数据进行排序,如果有Combiner,还要对排序后的数据进行combine。等最后记录写完,将全部溢出文件合并为一个分区且排序的文件。(注意:在写磁盘的时候采用压缩的方式将map的输出结果进行压缩是一个减少网络开销很有效的方法!)
3、最后将磁盘中的数据送到Reduce中,从图中可以看出Map输出有三个分区,有一个分区数据被送到图示的Reduce任务中,剩下的两个分区被送到其他Reducer任务中。而图示的Reducer任务的其他的三个输入则来自其他节点的Map输出。
Reduce端:
1、Copy阶段:Reducer通过Http方式得到输出文件的分区。
reduce端可能从n个map的结果中获取数据,而这些map的执行速度不尽相同,当其中一个map运行结束时,reduce就会从JobTracker中获取该信息。map运行结束后TaskTracker会得到消息,进而将消息汇报给 JobTracker,reduce定时从JobTracker获取该信息,reduce端默认有5个数据复制线程从map端复制数据。
2、Merge阶段:如果形成多个磁盘文件会进行合并
从map端复制来的数据首先写到reduce端的缓存中,同样缓存占用到达一定阈值后会将数据写到磁盘中,同样会进行partition、combine、排序等过程。如果形成了多个磁盘文件还会进行合并,最后一次合并的结果作为reduce的输入而不是写入到磁盘中。
3、Reducer的参数:最后将合并后的结果作为输入传入Reduce任务中。(注意:当Reducer的输入文件确定后,整个Shuffle操作才最终结束。之后就是Reducer的执行了,最后Reducer会把结果存到HDFS上。)
/////////////////////////////////////////////////////////////////////////////
2.2 对多个map的输出进行合并、排序。覆盖reduce函数,接收的是分组后的数据,实现自己的业务逻辑, <hello,2> <me,1> <you,1>
处理后,产生新的<k,v>输出。
2.3 对reduce输出的<k,v>写到HDFS中。
///////////////////////追加////////
partition过程
1,计算(key,value)所属与的分区。
当map输出的时候,写入缓存之前,会调用partition函数,计算出数据所属的分区,并且把这个元数据存储起来。
2,把属与同一分区的数据合并在一起。
当数据达到溢出的条件时(即达到溢出比例,启动线程准备写入文件前),读取缓存中的数据和分区元数据,然后把属与同一分区的数据合并到一起。
(三)自定义partition函数
public static class Partition extends Partitioner<intwritable, intwritable=""> {
@Override
public int getPartition(IntWritable key, IntWritable value,int numPartitions) {
int Maxnumber = 65223;
int bound = Maxnumber / numPartitions + 1;
int keynumber = key.get();
for (int i = 0; i < numPartitions; i++) {
//分区算法
if (keynumber < bound * i && keynumber >= bound * (i - 1)) {
return i - 1;
}
}
return 0;
}
}
调用
job.setPartitionerClass(Partition.class);