sklearn.pipeline
pipeline的目的将许多算法模型串联起来,比如将特征提取、归一化、分类组织在一起形成一个典型的机器学习问题工作流。
优点:
1.直接调用fit和predict方法来对pipeline中的所有算法模型进行训练和预测
2.可以结合grid search对参数进行选择。
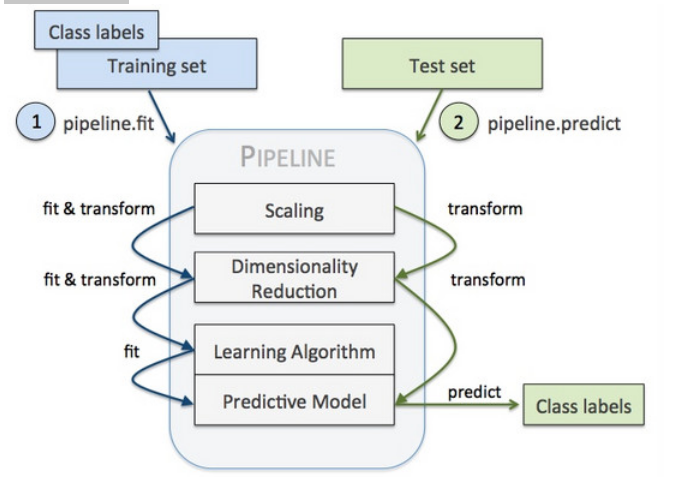
1.DictVectorizer、DecisionTreeClassifier——>pipeline模型
import pandas as pd
import numpy as np
titanic = pd.read_csv('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt')
titanic.head()
titanic.info()
X = titanic[['pclass','age','sex']]
y = titanic['survived']
X['age'].fillna(X['age'].mean(),inplace=True)
X.info()
from sklearn.cross_validation import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.25,random_state=33)
X_train = X_train.to_dict(orient='record')
X_test = X_test.to_dict(orient='record')
#将非数值型数据转换为数值型数据
from sklearn.feature_extraction import DictVectorizer
from sklearn.tree import DecisionTreeClassifier
from sklearn.pipeline import Pipeline
'''
vec = DictVectorizer()
vec.fit_transform(data)
clf = DecisionTreeClassifier(random_state=0)
clf.fit(X_train,y_train)
clf.predict(X_test)
'''
clf = Pipeline([('vecd',DictVectorizer(sparse=False)),('dtc',DecisionTreeClassifier())])
vec = DictVectorizer(sparse=False)
clf.fit(X_train,y_train)
y_predict = clf.predict(X_test)
from sklearn.metrics import classification_report
print (clf.score(X_test,y_test))
print(classification_report(y_predict,y_test,target_names=['died','survivied']))
2.结合GridSearch进行参数调优
from sklearn.datasets import fetch_20newsgroups
import numpy as np
news = fetch_20newsgroups(subset='all')
from sklearn.cross_validation import train_test_split
X_train,X_test,y_train,y_test = train_test_split(news.data[:3000],news.target[:3000],test_size=0.25,random_state=33)
from sklearn.feature_extraction.text import TfidfVectorizer
vec = TfidfVectorizer()
X_count_train = vec.fit_transform(X_train)
X_count_test = vec.transform(X_test)
from sklearn.svm import SVC
from sklearn.pipeline import Pipeline
#使用pipeline简化系统搭建流程,将文本抽取与分类器模型串联起来
clf = Pipeline([
('vect',TfidfVectorizer(stop_words='english')),('svc',SVC())
])
# 注意,这里经pipeline进行特征处理、SVC模型训练之后,得到的直接就是训练好的分类器clf
parameters = {
'svc__gamma':np.logspace(-2,1,4),
'svc__C':np.logspace(-1,1,3),
'vect__analyzer':['word']
}
#n_jobs=-1代表使用计算机的全部CPU
from sklearn.grid_search import GridSearchCV
gs = GridSearchCV(clf,parameters,verbose=2,refit=True,cv=3,n_jobs=-1)
%time _=gs.fit(X_train,y_train)
print (gs.best_params_,gs.best_score_)
print (gs.score(X_test,y_test))
parameters变量里面的key都有一个前缀,不难发现,这个前缀其实就是在Pipeline中定义的操作名。二者相结合,是我们的代码变得十分简洁。