1. 前言
很多年前就想将这些年工作中积累的优化经验撰写成文章,但懒癌缠身,迟迟未动手,近期总算潜下心写成文章。
涉及到具体优化技巧时,我会尽量阐述原理和依据,让读者知其然也知其所以然。
要完全读懂这篇文章,要求读者有一定的计算机语言/图形学/游戏引擎基础。希望读者看完后能将自己的游戏性能优化到一定的高度,使得游戏的效果和效率在高/中/低端设备都能符合或超出产品的预期。
为了方便描述,下面很多地方我会以之前在西山居做的一款RTS移动游戏项目(简称游戏Z)举例,以Unity为图例,可举一反三用到其他商业或自研引擎中。
1.1 性能优化的重要性
想必玩过游戏的人会经常感叹:游戏怎么那么卡?手机怎么那么烫?耗电怎么那么快?
其实这些问题都归结于性能问题,性能优化对游戏的重要性不言而喻。
对新游戏项目,中前期可能一直在赶需求赶效果,忽略了性能优化的工作,到中后期性能瓶颈必然会凸显。如果前期做到有效组织资源,制定美术规范,完善开发流程和工具链,后期优化起来会顺手很多,少走很多弯路。
1.2 优化Tips
很多年前,我刚大学毕业,就听到一位图形界的大神说过:优化无止境,优化的最高境界是不渲染。
以前不能完全明白他的话,觉得有点夸张,但我做过几个游戏项目的性能优化工作之后,深有体会,这么多年过去,言犹在耳,应验了真香定律!
优化的本质就是不渲染或少渲染或用更省的方法渲染。
1.2.1 分清主次
优化性能首先要找出性能瓶颈,对性能影响最大的地方先优化,接着对次影响的进行优化,以此类推。
如果能遵守这条规则,优化效果和花费时间的曲线关系大致如下图:

即前期的优化效果会非常明显,但随着时间的推移,花的时间越来越多,优化的效果反而逐渐放缓。这告诉我们:
1. 首先找出性能瓶颈,优化效果最明显;
2. 优化无止境,后期优化效果和时间比降低,要适可而止。
1.2.2 善用分析工具
工欲善其事必先利其器。善用分析工具可以快速定位出性能瓶颈,达到事半功倍的效果。
性能分析工具请参看:1.3 辅助工具
1.2.3 平衡好性能和效果
每个游戏偏重点不一样,有些游戏偏重效果而不太讲究性能,有些游戏偏重效率而牺牲效果,有些游戏两者需兼顾。
从我的经验而言,大多数游戏开发者或者玩家,更偏重性能。举个例子,大多数人在玩吃鸡游戏时,为了帧率稳定和耗电慢一点,将所有的画质参数开至最低。
若为性能故,效果皆可抛。
1.2.4 定制优化参考指标
每个项目在优化前,需要定制一个具体的指标参数,比如高中低端机跑在什么设备上,要达到什么样的帧数等等。
游戏Z定的参考指标如下表:

此标准是2017年上半年定的,现在可以酌情放宽参数。
定好标准后,就以此为依据进行优化,参数指标达到后即可认为优化任务完成。
1.2.5 做好效果等级管理
建议将等级管理逻辑抽象成单独的模块,增加QualityManager的角色,负责统筹管理和实现等级相关的逻辑。其它模块要只要调用这模块的接口,可以轻易实现差异化逻辑。
此外,QualityManager可以收集游戏关键参数:fps/网络Ping值/流量,对外提供查询接口。
1.2.6 具体情况具体分析
每个游戏项目的具体情况不一样,不可生搬硬套本文涉及的参数和方法,否正可能适得其反,花费了时间,性能没能很好地提上去。
1.3 辅助工具
目前市面上分析工具很多,特性和适用的平台都不同,下面就简单介绍常用的工具,具体使用方法另行搜索。
1.3.1 引擎分析工具
1. Unity的Profiler

Unity Profiler可以查看CPU/GPU/内存/音频/物理/网络等模块的具体消耗参数,是Unity游戏必备的性能分析工具。
2. Unreal
Unreal 3及之前的版本要先用命令行生成profiler文件,再通过UnrealFrontend加载生成的文件查看消耗数。
Unreal 4提供了类似Unity的Profiler的窗口,更加便捷。
更多参看:Unreal Profiler Tool Reference
1.3.2 IDE分析工具
1. Visual Studio的性能探查器

VS只可运行在windows平台,可对当前项目/指定的exe/运行的进程进行CPU和GPU性能采样并查看具体的消耗指标。
2. XCode的Instruments

XCode只可运行在Mac OS,可调试Mac OS和iOS的APP的CPU/GPU/内存等性能参数。
3. Android Studio的Profiler

Android Studio可运行在Windows和Mac OS,但只可分析Android的APP,参数包括CPU/内存/网络等。
1.3.3 GPU厂商工具
几乎每个GPU大厂都提供了调试自家产品的GPU分析工具。它们与引擎和IDE的工具最大的不同点是:可以查看每次Draw Call的渲染状态/引用的资源/绘制的画面,以及其它独特参数。
1. Tegra Graphics Debugger(NV)

工具本身可运行在各个主流系统,也可以分析OpenGL和Vulkan,但只支持NV旗下的Tegra K1和X1系列GPU。
2. Mali Graphics Debugger(Arm)

类似于Tegra Graphics Debugger, 但全面支持OpenGL的各种版本,还支持Vulkan和OpenCL的调试。
3. PVRTrace(Imagination Technology)
只可调试使用Imagination Technology公司GPU的App。
4. Adreno Profiler(高通)
只可调试使用高通旗下GPU的App。
5. PerfHud(NV)
只支持PC程序,非常强大的GPU调试工具,但无法调试移动设备,需要依赖模拟器。
6. PerfHud ES(NV)
PerfHud移动版,支持移动设备调试, 需要下载整个CodeWorks for Android开发包。
1.3.4 其它第三方工具
1. PIX(MS)
只运行在windows平台,只支持DirectX的分析。
2. 资源优化
病从口入,资源好比是入口,它们若出现问题,会引发一连串性能问题。相反,资源若是优化得好,后面所有章节的性能都可受益。这也是把资源优化的章节提到最前的原因。
2.1 纹理优化
纹理优化的目的是让它们占用的内存尽量的小,那么纹理加载进内存后,大小计算公式如下:
纹理内存大小(字节) = 纹理宽度 x 纹理高度 x 像素字节
像素字节 = 像素通道数(R/G/B/A) x 通道大小(1字节/半字节)
从上面公式可以看到,纹理加载进内存后的大小跟尺寸/像素通道数/通道大小都有关系,我们就从它们着手优化,还可以通过提高复用率和合成图集达到优化的目的。
2.1.1 纹理尺寸
美术常犯的一个错误是不管什么角色什么场景,都会给模型贴上很大尺寸的贴图,通常大于1024x1024。

比如游戏Z是斜45度固定视角对战游戏,在画面中角色渲染所占的画面很小(约150x150),但美术在最初给所有角色模型都制作了1024x1024的贴图。
根据项目实际情况,我将所有角色贴图都缩小至256x256,角色贴图占用缩小至1/16。
除了角色贴图,武器/装备/特效/场景等等所有涉及的贴图都缩小至合适的大小。这里的合适大小是指渲染对象在画面中大多数情况下不可能达到的最大尺寸,这个尺寸最好保持2的N次方。
2.1.2 纹理通道
通道优化的目的是降低像素所占的大小,可以通过以下方法达到目的:
1. 去除Alpha通道。可以减少通道数量,适用于不需要Alpha混合或Alpha Test的角色和物件。
2. 应用单通道图。也可以减少通道数量,比如灰度图,地形高度图,掩码图,Shader掩码图等等。
3. 使用16位代替32位图。例如RGB444/RGBA4444就可以减少像素通道大小。
4. 压缩贴图适应不同的平台。例如:
Windows可以压缩成DDS,其中DDS细分DX1~DX5共5种格式,每种应用场景略有不同,但它们只能用于DirectX。
Android可以压缩成ETC1(不带Alpha)或ETC2(可带Alpha)。
iOS可以压缩成PVRTC格式。
它们都是GPU直接支持的纹理格式,可以显著减少内存/显存/带宽的占用。
5. 避免使用JPG/高压缩率的PNG/GIF等低质量格式。因为当前主流商业引擎在游戏发布过程中,会自动压缩所有纹理,而保留原画质的纹理可以减少纹理压缩后的画质损失。
2.1.3 提高纹理复用率
以下方法提高贴图复用率:
1. 建立共享图库。将通用的元素放至共享库,例如按钮/进度条/背景/UI通用元素等。
2. 用九宫格图代替大块背景图。九宫格在游戏开发中是比较常见的UI组件。
3. 纹理元素通过变换可组合成复合纹理。例下图,上下左右对称的背景图可以用4张相同贴图实例通过旋转/翻转后获得。

4. 九宫格+UI元素可以组合成很复杂但消耗相对较小的UI界面。
2.1.4 纹理图集
图集就是一堆小尺寸纹理元素合成的纹理贴图(如下图)。

图集可以降低IO加载次数,也可以减少Draw Calls(详见4.2 Batch合批)。
但也有副作用,一是可能超出设备支持的最大尺寸,二是可能出现大片空白像素(如下图)。

对于副作用一,可以限制图集的最大尺寸(通常不要超过2048x2048),分拆成多张图集。
对于副作用二,可以针对性地调整纹理元素的布局或尺寸,使得合成的图集尽可能占满有效像素。
适合生成图集的资源有:UI界面,道具图标,角色头像,技能图标,序列帧,特效等等。
如果是Unity引擎,可以用SpritePacker很方便地生成和预览图集。
如果是自研引擎,可以用TexturePacker的命令行工具合成。
2.2 UI
2.2.1 UI图集
所有UI元素都生成图集,而且确保每个界面生成单独的图集,这样可以在界面销毁时可以及时释放UI纹理。
要尽量确保每个界面只引用到自己的图集和共享库图集,避免引用到其它界面的图集。

上图所示,界面A引用界面A图集和共享图集是允许的,但尽量不要引用界面B等其它图集。
但实际在游戏开发过程中,很难保证美术做到这一点,通常存在以下问题:
1. 如果界面A确实要用到界面B图集的某个元素,怎么办?
参考解决方法:要看被引用元素的通用度,如果只是界面A和B在用,可以将被引用元素拷贝到界面A图集下;如果其它界面也会引用到,就可以将它移到共享图库。
2. 有些UI纹理很大且很多界面都有用到,如果放在共享图库会导致共享图库急剧膨胀,怎么办?
参考解决方法:大尺寸纹理建议用九宫格+细节图,或通过组合的方式来代替。
3. 如何保证美术制作的UI只引用到自身图集和共享图集?
参考解决方法:实现批处理检查工具,找出每个UI界面引用到的图集列表,引用的图集超过2个便是不合格。
2.2.2 UI层次
由于UI元素很多,主流商业引擎都会对它们合批以减少Draw Calls,但合批优化是有条件的:
1. 使用相同的材质。使用引擎默认UI材质+UI图集可以满足这个条件。
2. 绘制顺序是连续的。UI的绘制顺序通常就是在场景中的节点顺序。
下图有4张UI图片,但它们都用了系统默认材质,都是共享图集的元素,并且它们在场景中的顺序也是相连的,所以满足合批优化的条件,最终SetPass Calls(Draw Calls)是1。

然而,在实际制作UI过程中,经常会破坏UI合批优化的条件:
1. 同个界面往往会引用自身图集和共享图集,破坏优化条件1。
2. 界面通常都带有文本,而文本通常是引擎自动生成的另外一张或若干张图集,破坏优化条件1。
3. UI节点层次混乱,不同图集的元素相互交叉,破坏优化条件2。
4. 部分UI元素使用了自定义材质或Shader,破坏优化条件1。
分析了原因,在UI制作时,就要尽量避免这些情况发生。
2.2.3 UI的其它优化
1. 禁用MipMaps。MipMaps的原理是根据绘制对象在绘制空间的大小选取合适的纹理层级,它会增加30%的内存/显存开销。而UI通常都是等长等宽的,跟摄像机距离无关,所以要禁用UI的MipMaps。
2. 保持UI纹理的原始尺寸。缩放通常会带来额外的开销,而且会使UI变模糊,降低画质。
3. 避免使用大尺寸的背景图。大背景图耗内存,通常还不能共用。可用九宫格+细节图组合而成。
2.3 字体
说字体是性能的杀手毫不为过。
游戏使用的字体一般是ttf格式,单个ttf字库少则5~10M,多则10~20M。
在文本绘制前,引擎会将字库加载进内存,占用较大的内存空间;在文本绘制时,引擎会在内存中开辟若干张纹理图集缓存字体纹理。
每个字至少要两个三角形,若是有阴影/描边/发光等效果,三角形数量扩大数倍之多(如下图)。


可以通过以下建议优化字体的性能:
1. 控制字体文件数量。除了系统默认字体,自定义字体控制在1~2个为宜。
2. 少用字体的阴影/描边/发光等效果。
3. 剔除字库中无用的字形。可以借助FontSubsetGUI或FontPruner给字库瘦身。

字库瘦身更多参看这里。
2.4 模型
模型特别是带有骨骼动画的模型在性能消耗中占据非常大的比重,它们会显著增加CPU/GPU/内存/显存的负担。所以,模型的优化尤为重要。
模型涉及的数据比较多,包含了顶点/索引/材质等,而顶点又可能包含pos/color/uv/normal/tagent/skin等数据,我们可以从这些数据着手优化。

上图的模型顶点包含了pos/color/uv/normal/skin等数据。
2.4.1 模型数据
模型的顶点数据通常包含pos/uv,但color/normal/skin等数据视不同类型的物件区分对待。比如,对于静态物体,可以去除skin;如果无需顶点变色,则可以去除color。
模型内pos.xyz/uv.xy/color.rgba等等数据默认用32位浮点数存储,它们的数据表示范围远远超出大多数游戏的应用场景,可以将它们压缩至16位浮点数。
模型的索引数据存储了三角形引用的顶点序号,默认用32位unsigned int存储,但绝大多数模型不可能超出16位unsigned short的范围,故用16位整型足矣。
Unity引擎在Model的Import面板可设置优化参数(下图)。

2.4.2 模型辅助工具
美术制作出的模型通常是高精度模型,虽然效果好,但往往在中低端机不需要这么高的精度,这时候就要借助一些工具进行优化。
下面主要介绍Unity的工具,其它引擎应该有类似的工具。
MeshBaker:模型合并插件,可以对多个模型合成一个模型,从而减少模型个数,降低Draw Calls。多用于静态物体合并,比如场景和地面静态物体。
SimpleLOD:模型减面库,可以离线或运行时给模型进行减面优化,也可以方便地做成批处理工具。
2.4.3 模型美术规范
一个模型尽量只用一个材质,材质使用的贴图大小要合理,太大浪费内存,太小画质会模糊。
建模时,剔除模型内部等不可见的顶点和三角面,合并重叠或相邻的顶点,减少模型的顶点数和面数。为防止美术制作的模型精度过高,有必要对模型的顶点和面数做限制。
若模型带骨骼动画,需对骨骼数量做限制,单个模型的骨骼数量最好限定70个以内,否正很多低端设备无法支持GPU蒙皮。对模型进行分类,重要模型骨骼数可以多一些,次重要或不重要的更少骨骼数。
游戏Z对各类模型的限制如下表:

2.5 场景
地形若是不复杂(比如王者荣耀/LOL的战斗场景),尽量不用Terrain,用简易模型代替,地表细节可用一张纹理表示,地表纹理取合适大小,通常不超过1024x1024。
地形网格和地面静态物体去掉阴影,如果某些物件确实需要阴影,可以让美术在制作地表纹理时加上阴影。
地形有很多不可见的地方,可以删减那里的模型网格。
地面通常有很多装饰物和特效,要关注它们的面数等规格是否超出了限制。
一个场景只用一个平行光,实时像素光不要超过一个。用Lighting Map代替实时光,Lighting Map纹理尺寸不宜太大。
对场景的面数和物体数量做限制。使用合批工具离线将地表相似的静态物体合并,减少场景复杂度。
对场景使用画质分级策略,比如低画质下,用最低模的场景,隐藏场景特效等。
地表如有导航网格,导航网格可以采用更精简的模型,复杂的边缘可以简化成简单的几何多边形。

上图展示的是游戏Z的一个场景,虽然地表物体比较复杂,但地形网格(绿线所示)很简单,用少量的三角面表示了复杂的地表构造。
2.6 粒子
粒子特效也是性能的一个大杀手,主要体现在:
1. 每帧计算量大。涉及发射器/效果器/曲线插值等,耗费CPU性能。
2. 频繁操作内存。粒子在生命周期里,实例持续不断地创建/删除,即便有缓存机制下,依然避免不了内存的频繁读取和碎片化。
3. 每帧更新数据到GPU。从Lock顶点Buffer到写入数据到GPU,会引发线程等待,也加重CPU到GPU带宽的负担。
4. 增加大量Draw Calls。粒子特效通常五花八样,使用很多材质,导致引擎无法合批优化,大量增加绘制次数。
5. 导致Overdraw(过绘制)。粒子一般会开启Alpha Blend,在同屏粒子多的情况下,会造成严重的Overdraw。

上图展示的是游戏Z主界面的过绘制情况,越白代表过绘制越严重,可以看出用了粒子的地方,颜色趋向白色。
即然粒子导致性能严重下降,首先得从资源上着手优化和规范。具体方式有:
1. 优化粒子属性。关闭阴影,关闭光照;若可以去掉纹理的Alpha通道,并关闭Alpha Blend和Alpha Test;
2. 禁用粒子的高级特效。如模型粒子/模型发射器/粒子碰撞体等。
3. 用最少的粒子效果器。关闭不必要的粒子效果器,采用简单的方式代替。
4. 控制粒子的材质数量。一个特效通常包含了若干个粒子系统,它们尽量使用内置材质,使用相同的材质实例。
5. 控制粒子的尺寸和贴图大小。可以粒子的尺寸,可以减缓过绘制,控制贴图大小,可以减少带宽和提高渲染性能。
6. 制定粒子特效美术规范。下面是游戏Z的粒子规范。
粒子美术规范
单个粒子的发射数量不超过50个。
减少粒子的尺寸,面积越大就会消耗更多的性能。
粒子贴图必须是2的N次方,尽量控制64x64以内,极少量128x128或256x256,最大不超过256x256。
尽可能去掉粒子贴图的Alpha通道。
尽量不用Alpha Test。
尽量使用已有的材质,提高合并渲染的优化概率。
材质优先用Mobile目录下的材质。
尽可能不用模型做粒子,如果使用,要控制模型面数在100以内,最大粒子数在5以内。
单个特效渲染数据限制:
小型特效(如受击特效、Buff特效)的面数和顶点数在80以内,贴图在64*64以内,材质数2个以内。
中型特效(如技能特效)的面数和顶点数在150以内,贴图在128*128以内,材质数4个以内。
大型特效(如全局特效、大火球)的面数和顶点数在300以内,贴图在256*256以内,材质数6个以内。
2.7 材质
材质若控制不好,会破坏引擎的合批优化,提高渲染消耗。所以在项目前期,就有必要对材质做管理和规范。
1. 充分使用引擎内置材质。引擎内置材质能满足基本材质需求,而且通常做了优化,所以首选内置材质。如果是移动游戏,一般引擎也有移动版的材质库。
2. 建立共享的自定义材质库。如果引擎内置材质不满足项目需求,就需要通过添加自定义材质来解决。对于自定义材质,要妥善管理,对它们进行分类,按规律命名。这样对材质共享和管理都大有裨益。
3. 定期检查新加入的材质是否与已有的重复。如果有相似的材质,则删除重复的。这个工作可以由主程或主美执行,也可以通过工具协助检查。
2.8 制定美术规范
制定美术规范时,需与主美/主策/制作人协商,结合项目具体情况,给出合理的美术规范参数,并撰写成文档。
定好规范后,有必要定时检查项目里的所有美术规范是否符合规范,揪出不符合的资源,让美术修改。
检查美术是否合规,可以写批处理工具,提高效率。
特效/场景/角色资源若不能批量处理成高中低配版本,就建议美术为各个画质等级制作不同的资源。
3. CPU优化
性能优化最主要的一部分工作是CPU,CPU性能优化好了,离目标就成功了一半。
3.1 缓存计算结果
缓存计算是空间换时间的经典应用,它适用于那些耗费大量CPU计算而计算结果无需每帧变化的逻辑。
实现伪代码:
std::map<KeyType, ValueType> _cache;
ValueType Calculate(KeyType key)
{
// 先尝试从缓存中获取结果,有就直接返回。
if (_cache.count(key) > 0)
{
return _cache[key];
}
// 缓存不存在,执行真正的计算,并缓存计算结果。
ValueType res = DoCalculation(key);
_cache[key] = res;
return res;
}
适用场景举例:
1. 复杂数学计算。Sin/Cos/Pow/Sqrt等运算要花费一定计算量,如果是第一次计算,可以将结果缓存起来,下次遇到相同的计算,直接从缓存中取值。
2. 物理模拟结果。物体的物理模拟过程耗费大量计算,但有些物体模拟完之后就处于静止状态,可以将它之前的模拟结果存下来,防止每帧更新计算。现代主流商业引擎都支持这种优化。
3. 光照贴图。光照贴图是离线将场景的静态光影计算并缓存成贴图,渲染时只需要采样光照贴图的颜色,极大降低了光照计算复杂度。
4. 搜索结果。例如场景节点搜索,场景节点一般采用树形结构,如果查找的节点很深,将显著增加遍历次数,此时很有必要将查找结果缓存起来。
5. 逻辑模块复杂的计算。游戏的逻辑模块,涉及到复杂的计算都可尝试用缓存法降低CPU负担。
3.2 预处理
缓存法利用空间换时间的思想,会增加内存开销;而预处理是将时间转移的思想,它并不会增加内存消耗。
将需要花费大量时间加载或运算的逻辑,在启动程序后/加载场景时/切换界面前/进入战斗前等时机预先计算或加载,避免渲染时因CPU负载过高出现帧率波动或卡顿现象。
3.3 限帧法
限帧法简单粗暴,但效果显著,是常见的一种优化手段。
限制频率的对象可以是World.Update,物理模拟,粒子计算,角色AI处理,角色状态更新等等。
限帧可以通过以下方法实现:
1. 计数法。用一个变量记录更新次数,每累计到某个数才执行更新。
int _frameCounter = 0
void Update(float time)
{
_frameCounter += 1;
// 更新频率降为每10帧一次。
if (_frameCounter % 10 == 0)
{
DoUpdate(); // 执行真正的更新
_frameCounter = 0; // 重置计数器
}
}
2. 计时器。利用Timer机制触发,每隔固定时间触发一次更新。
3. 协程。协程是运行于主线程的伪线程,但可以模拟异步操作,没有多线程的副作用。故而也可以用于限帧操作。
4. 事件触发。每帧查询状态改成事件触发,也是游戏常用的一种优化手段,用来限帧也非常有效。
3.4 主次法
主次法跟LOD技法有异曲同工之妙。思路也是将物件按重要程度划分为高中低级别,然后不同级别采用不同复杂度的效果或计算。
这种思路在游戏中可以广泛应用,基本所有消耗高的逻辑或模块都可以采用这个技法。例如:
1. 画质等级。将游戏分为若干等级,画质最高到最低采用不同的渲染技术或资源,区别对待。
2. 资源等级。场景/特效/灯光/物理效果/导航等等模块都可以根据画质等级或物件等级对应不同级别的资源,整体上可以减少消耗,又能兼顾画质效果。
3. 角色分级。主角英雄/Boss等和小怪物/NPC区分开来,前者更新频率更高,AI行为更复杂更智能,而后者采用简单效果或降频更新。
3.5 多线程

上面这张搞笑动图相信很多人都看过,它形象生动地表明了当今设备多核常态化但主核承担大部分工作忙到“吐血”而其它核在打酱油的囧态。
在游戏开发中,我们可以将一些逻辑通过创建线程的方式独立出去,交给其它CPU核心处理,以缓解上面提到的现象。
可独立成线程处理的模块:
1. 文件IO。建立一个IO线程,定时检查文件队列是否有数据,若有便启动IO加载,直至文件队列为空,又回到空闲轮询状态。主线程就不会以为文件IO而处于等待状态。
2. 骨骼动画。如果同屏动画角色多,将占据大量CPU计算。可创建一个或多个线程处理骨骼动画计算,加速渲染流程。但随之而来的是同步问题。
3. 粒子计算。粒子的多线程跟骨骼动画类似,也存在同步问题。
4. 渲染线程。将渲染抽离出一个线程,主要是解决CPU与GPU相互等待的问题。常见的一种做法是建立一个渲染线程,定期去查询渲染队列是否有数据,如果有就提交至GPU进行绘制。
5. 音视频编解码。如果游戏有涉及音频频播放,而它们又占据了较大的消耗,那么开辟独立的线程处理音视频编解码是有必要的。
6. 加密解密。加密解密涉及的算法通常较复杂,占用较多CPU性能,而且常常伴随着文件IO或网络IO,所以此时非常有必要将它们交给独立的线程处理。
7. 网络IO。目前大多数游戏都会开辟一个线程专门收发网络数据,以避免网络处理影响主线程。
值得注意的是,线程切换会带来额外开销,同步和死锁问题也会提高逻辑复杂度和调试难度,是悬在程序员头上的一把大刀。
3.6 引擎模块
引擎内部最耗CPU性能的模块通常有:骨骼动画/粒子计算/物理模拟/导航网格/相机裁剪和渲染等等。
3.6.1 动画
降低动画采用频率。
减少关键帧数据。
缓存动画的插值结果。
用简单曲线插值(线性插值)代替复杂插值(贝塞尔曲线)。
判断动画所附对象的可见性,如不可见,则不更新动画。
控制同屏动画的个数。
不同画质加载不同级别的动画资源。
3.6.2 物理
静态物理只用静态碰撞体。
降低物理模拟频率。
禁用复杂的碰撞体(如模型碰撞体),取而代之的是用若干个简单几何碰撞体组合。
若物体不可见,则关闭物理模拟。
控制同屏物理物体个数。
对物体的重要程度做分级,重要性低的角色采用简单物理效果或者删除物理效果。
Raycast射线检查虽好用,但性能消耗也高,要尽量降低视频频率,防止重复调用。
3.6.3 粒子
粒子资源优化:详见2.6。
部分粒子特效考虑转成序列帧渲染。
考虑是否可用缓存/预加载/预计算的优化方式。
对特效的重要程度分级,不重要的粒子不计算或者降频。
若GPU的负担比CPU小,可以将粒子更新计算移至GPU端。
粒子物体可见性判断,不可见则不计算和渲染。
3.6.4 导航
简化导航网格,用最少的面数表达复杂地面的导航构造,比如用平面代替地面凹凸不平的路面。(详见2.5)
寻路计算复杂,逻辑上须控制调用频率,避免扎堆寻路。
3.7 逻辑优化
逻辑的消耗也是CPU负担高的罪魁祸首,主要体现在AI/算法/脚本等等模块。
3.7.1 AI优化
为了简化玩家操作和让怪物更加拟人化,目前大多数游戏都加入了AI功能,而AI行为树(下图)是实现AI的关键。

但是正常情况下,AI行为树要每帧更新,每次需从根节点搜寻,一直找到合适的节点才更新,最坏的情况会遍历整棵树。
下面有几种方法优化AI行为树:
1. 缓存当前Action节点路径。即将当前正在更新的节点和其父亲节点都缓存起来,下次要更新时优先这个路径搜寻,避免遍历整颗树。如果当前Action节点是持续性的,则这段时间内无需搜索节点,直接更新该节点即可。
2. 降低AI的更新频率。即强制降低AI频率达到减负的目的,另外还可以尝试主次法/摊帧法/动态调帧法优化AI的更新。
3.7.2 算法优化
思路是找出最耗CPU的算法或逻辑,优化之。
1. 空间换时间。利用预排序/预处理/缓存/动态规划等等思路换取CPU的性能。
2. 选取更快的算法。属于数据结构和算法的范畴,思路是将O(n2)降低成O(n)或O(logn),具体可以参看《算法导论》《游戏编程算法与技巧》《游戏核心算法编程内幕》等书籍。
3.7.3 脚本优化
通常引擎底层是用C++等Native语言实现,而脚本用动态语言(Java/C#/Lua/Python)实现,它们中间隔着一层厚重的模拟器或封装层。Unity引擎与C#之间的关系如下图:

Unity在打包游戏时会通过Mono将C#代码生成IL中间语言,如果是iOS平台,还会通过IL2CPP生成C++代码。简单点说,Unity引擎核心和C#等脚本语言的交互要通过Mono厚重的中间层。由此产生了额外的开销,导致脚本语言运行效率低下。
可以通过以下一些方法降低脚本的开销:
1. 删除脚本内的空回调。即便脚本对象的回调函数为空,但也会产生引擎核心与脚本层的开销。
2. 脚本对象如果引用其他对象,可以在初始化时缓存。
class Tester
{
private Object _obj = null;
void init()
{
_obj = FindObject("MyObjectName"); // 初始化时先找到物体。
}
void update()
{
if (_obj)
{
_obj.update(); // 帧内直接访问。
}
}
}
3. 帧更新/循环语句内避免产生堆的临时对象。可以将临时对象移至循环语句外,或声明成类的成员,在初始化时赋值。
4. 利用可见性回调。在可见性回调内做禁止/恢复比较耗时的操作。
5. 字符串接很容易引起临时对象,需警惕。可采用更高效的拼接方式,如C#的StringBuilder。
3.7.4 条件测试
条件测试主要用于耗时的调用优化,将每帧必然更新的操作,加入各种条件检查,以减少耗时操作的概率。
void Update()
{
DoCalculation(); // 耗时操作
}
// 改成:
void Update()
{
// 加入各种条件测试
if (_dirty && _visible && _moved && _timeInterval>0.1)
{
DoCalculation();
}
}
3.7.5 避免重复
游戏一般涉及的模块众多,角色状态机复杂,触发事件多且杂,往往会在同一帧内多次调用同一个耗时API,引发额外的开销。
可以通过条件测试,时间间隔,Log输出,调用栈调试等方法解决这个问题。
4. 渲染优化
渲染优化的目的是减少Draw Calls,减少渲染状态切换开销,降低显存占用,降低带宽和GPU负担。
在讲解渲染优化之前,先了解渲染性能消耗点。
1. Draw Call数量。
Draw Call有些引擎也称为SetPass Call。一个Draw Call就是游戏调用OpenGL/D3D等图形渲染的绘制API一次(如OpenGL的glDrawArray和glDrawElements)。
一次Draw Call完整地跑完了整个渲染管线(下图),期间要涉及的数据/状态/计算很多,绘制前会先创建各种GPU数据,还可能每帧更新这些数据,数据更新又涉及到带宽。

所以,每帧Draw Call数量是衡量渲染性能的关键指标。
2. 渲染状态切换。
每次Draw Call前会对图形渲染层设置一系列的渲染状态,如是否开启深度测试/是否开启Alpha Test/是否开启Alpha Blend等等。这些状态通过图形渲染的驱动层最终应用到GPU中(下图)。

从上图可以看到,应用程序(游戏)发送的渲染指令,会经过OpenGL/DirectX等图形层和显卡驱动层,最终才能应用到GPU硬件。
由于当代显卡驱动做了很多工作:状态管理/容错处理/逻辑计算/显存管理等等,属于重度封装,会消耗较多性能。
所以,尽可能减少状态切换,是优化渲染性能的重要措施。
3. 带宽负载。
此处的带宽是指CPU经过主板总线传输数据到GPU的能力,单位通常是GB/s。当然GPU也可通过总线传输数据到CPU,但传输能力远远低于CPU到GPU。

上图所示,CPU和GPU通过PCI-e总线相连,它们之间的传输能力是有上限的,这个上限就是带宽。如果绘制需要传输的数据大于带宽(即带宽负载过高),就会出现画面卡顿/跳帧/撕裂/延迟/黑屏等等各种异常。
4. 显存占用。
显存即显卡的内存,是集成在GPU内部的专用内存。通常用于存储顶点/索引/纹理/各种Buffer等数据。
如果游戏显存占用过高,便会出现显存分配失败,导致画面异常甚至程序崩溃。
5. GPU计算量。
现代显卡基本都支持可编程渲染管线,涉及Vertex Shader/Geometry Shader/Fragment Shader(下图),还涉及光栅化/片元操作。所以,如果Shader过于复杂或者片元过多,会极大提高GPU计算量,降低渲染性能。

了解渲染具体开销后,就可以用下面的方法着手优化。
4.1 合批(Batch)
合批(Batch)是将若干个模型合成一个模型,从而可以只调用一次Draw Call的优化手段。合批解决的是Draw Call数量问题。
合批的条件是所有被合的所有模型都引用同一个材质,否正无法正常合批。
4.1.1 离线合批(Offline Batch)
离线合批就是在游戏运行前,先用工具把相关资源做合批处理,以减轻引擎实时合批的负担。
适合离线合批的是静态模型和场景物件。如场景地表装饰面:石头/砖块等等。
离线合批方式有:
1. 美术利用专业建模工具合批。如3D Max/Maya等。
2. 利用引擎插件或工具。如Unity的插件MeshBaker和DrawCallMinimizer,可以将静态物体进行合批。
3. 自制离线合批工具。如果第三方插件无法满足项目需求,就要程序专门实现离线合批工具。
4.1.2 实时合批(Runtime Batch)
不同于离线合批,实时合批是游戏引擎在游戏运行期完成的。Unity引擎分为静态合批和动态合批。
1. 静态合批(Static Batch)
符合静态合批的条件有两个:一是模型有Static标记(即物体是静态的,不能有移动/动画/物理等),二是引用同一个材质实例。
为了提高静态合批的概率,尽可能将场景物件设为静态,并且类似的物件引用相同的材质。
2. 动态合批(Dynamic Batch)
动态合批是针对可以运动的模型,但有更苛刻的要求,例如Unity要求:
- 模型少于300个顶点,少于900个顶点属性。
- 不能有镜像Transform。
- 使用同一材质实例(注意:是实例,相同的材质不同的实例,也是不行的)。
- 使用相同的光照图(Lightmaps)。
- 不能用多Pass Shader。
4.1.3 合批副作用
合批优化虽能降低Draw Calls,但也有副作用:
1. 增加CPU消耗。需要消耗CPU计算将多个模型合成一个,还涉及材质排序和搜集等操作。
2. 增加内存。需要额外开辟内存存储合成的模型。
3. 合成的模型顶点数有限制。移动游戏通常用16位索引,若合成的模型超出16位无符号整数的范围,渲染会出现异常。
4.2 渲染状态优化
4.2.1 状态缓存
在引擎侧,可以使用状态缓存减少渲染管线的切换。伪代码:
class RenderStateCache
{
public:
void InitRenderStates();
{
for (RenderStateType t=RenderStateType.begin; t<RenderStateType.end; ++i)
{
_renderStateCache[t] = GetRenderStateFromDevice(t);
}
}
void SetRenderState(RenderStateType state, RenderStateValue value)
{
// 如果要设置的状态和当前缓存的一样,则忽略。
if (_renderStateCache.count(state) > 0 && _renderStateCache[state] == value)
{
return;
}
_renderStateCache[state] = value;
SetRenderStateToDevice(state, value);
}
private:
std::map<RenderStateType, RenderStateValue> _renderStateCache;
};
4.2.2 渲染状态建议
1. 少用Alpha Blend。开启Alpha Blend了一般会关闭深度测试,无法利用深度测试剔除多余片元,导致片元数量增加,造成过绘制。所以要尽量少用。
2. 禁用Alpha Test。现代部分移动端GPU采用了特殊的渲染优化方式,如PowerVR采用Tile Based Deferred Rendering方式(下图右),而Alpha Test会破坏Early-Z优化技术,可用Alpha Blend代替。更多看这里。

3. 开启背面裁剪。背面裁剪可以将背向摄像机的面片剔除,减少顶点和片元的数据量。
4. 开启MipMaps。开启后,渲染时会自动根据画面尺寸选择合适大小的纹理,从而降低带宽,也可以降低锯齿,提高画质效果。但UI界面不能开启,原因见2.2.3。
5. 关闭雾。只在固定管线适用。
6. 少用抗锯齿。图形API内置的抗锯齿通常会增加纹理采样次数数倍之多(下图),所以要慎用。

4.3 控制绘制顺序
控制模型绘制顺序的目的是充分利用深度测试,减少片元后续操作。特别是Early-Z技术的引入,此法效果更明显。
绘制顺序是:先绘制已做好排序的不透明物体,再绘制Alpha Tested物体,最后渲染透明物体。
伪代码:
void Render()
{
// 1. 绘制不透明物体
SortOpaqueObjectsInViewSpace(); // 对不透明物体进行排序,须在相机空间,离相机近的排在前面。
DrawOpaqueObjects(); // 绘制不透明物体,离相机近的先绘制。
// 2. 绘制Alpha测试物体
SortAlphaTestedObjectsInViewSpace(); // 对Alpha测试物体进行排序,须在相机空间,离相机近的排在前面。
DrawAlphaTestedObjects(); // 绘制Alpha测试物体,离相机近的先绘制。
// 3. 绘制透明物体(注意:绘制顺序跟不透明物体刚好相反)
SortTransparentObjectsInViewSpace(); // 对不透明物体进行排序,须在相机空间,离相机远的排在前面。
DrawTransparentObjects(); // 绘制不透明物体,离相机远的先绘制。
}
4.4 多线程渲染
在单线程渲染架构中,CPU性能消耗过高会影响GPU的渲染帧率,反之,GPU渲染过慢也会让CPU一直处于等待状态。
多线程渲染就是为了解决CPU和GPU相互等待的问题。
以Metal/Vulkan等架构出现为界限,将它们分成两个阶段。
4.4.1 软件级多线程渲染
早期的图形API和硬件架构都不支持多线程渲染,此阶段多线程渲染能做的优化比较受限,只能将渲染提交独立成一个线程,使之不会卡逻辑线程。
开源图形渲染引擎OGRE的多线程渲染实现方式有两种:
1. Middle-level Multithread。
每个渲染物体都有两份实例,主线程改变其中一份数据,在下一帧给渲染线程使用。(下图)

这种方式实现很复杂,要维护物体的两份实例,也不容易在多核CPU做扩展,不能充分发挥多核CPU的优势。
2. Low-level Multithread。

这种实现方式是将渲染物体的顶点等数据拷贝一份,逻辑线程修改其中一份数据,下一帧给渲染线程使用。
除了以上两种方案外,可以给逻辑线程的若干逻辑(如Update/粒子/动画)开辟多个线程(下图),并行计算,缩短整体处理时间。

4.4.2 硬件级多线程渲染
近几年,Metal/Vulkan图形架构横空出世,基于硬件级别的多线程渲染的时代终于到来。它们的特点:
1. 轻量化的驱动层。
OpenGL的API和驱动做了很多逻辑封装,用状态机的方式实现渲染(下图左)。而Metal/Vulkan与之不同的是,在驱动层只做少量的工作,为应用程序提供直接访问GPU硬件的接口,属于轻量级封装(下图右)。


从API架构上看,Metal/Vulkan的性能已胜出一大筹。
2. 支持硬件级的多线程渲染。
Metal/Vulkan支持并行渲染指令,方便CPU各个线程各自提交渲染指令和数据。
下图展示的是其中一种渲染方式,由多个线程创建不同的绘制命令,再由单独的线程管理渲染命令队列,统一提交给GPU绘制。

由于图形API已经支持多线程渲染指令提交,再结合上一节讲到的若干方案,将如虎添翼,渲染性能也会发生质的提升。
目前主流商业引擎已经支持Metal/Vulkan,Unity2018.3已经支持Metal/Vulkan:

Unity在Rendering设置面板可以开启多线程渲染:

4.5 光照模型(Lighting/Illumination Model)
4.5.1 Flat Shading(平面着色)
根据表面法向量计算光照,并应用到整个面片上。速度最快,效果最差,容易暴露物体的多边形本质(下图)。

4.5.2 Gouraud Shading(高洛德着色)
根据顶点法向量计算光照,再用插值计算出整个面的光照。效果比Flat shading稍好,但高光部分有瑕疵,过渡不够自然(下图)。

可结合Phong Shading做优化,高光弱时用Gouraud Shading,高光强时用Phong Shading,可平衡效果和效率。
4.5.3 Lambert Shading(兰伯特着色)
物体表面向各个方向等强度的反射光,这种等同地向各个方向散射的现象称为光的漫反射。
Lambert定律:反射光线的强度与表面法线和光源方向之间的夹角成正比(下图)。它是一种理想的漫反射模型,但着色效果比高洛德要平滑。

计算公式:![]()
4.5.4 Half Lambert Shading(半兰伯特着色)
Lambert着色有个缺陷,就是背面受光少,经常处理死黑状态,与受光面反差太大(下图左)。
于是其中的一种改进方案诞生了,它就是Half Lambert Shading,它渲染的画面明暗关系没那么强烈,过渡更加自然(下图右)。

计算公式:![]()
其中a和b是常数,通常都取0.5,而且a+b = 1.0。
4.5.5 Phong Shading(冯氏着色)
Phong着色将光照分成自发光(Emissive)/环境光(Ambient)/漫反射(Diffuse)/高光(Specular)四个部分,每个部分独自计算光照贡献量。是当前广泛应用的一种光照模型。

其中高光计算公式:![]()
Phong着色效果如下:

4.5.6 Blinn-Phong Shading
由于Phong模型要用到反射矢量r,而r计算比较耗时(下图),故有了Blinn Phong。
![]()
Blinn Phong是Phong的一个改进,做法是摒弃反射矢量r,引入l和v的中间矢量h,然后利用n和h的夹角进行计算。

高光计算公式:![]()
它渲染出的高光范围更大(下图),真实感不如Phong着色,但胜在效率更高。

4.5.7 光照模型的选择
从性能上做比较:Flat > Gouraud > Lambert > Half Lambert > Blinn-Phong > Phong。
但画质效果刚好相反,所以每个游戏需根据具体需求做选择。也可以采用分级策略,高中低画质分别采用不同的光照模型。
4.6 渲染路径(Rendering Path)
4.6.1 经典顶点光(Legacy Vertex Lit)
严格来说,它也是前向渲染的一种,但有些引擎(如Unity)将它单独抽离出来。由于光照计算在顶点,所以效果和消耗跟4.5.2 Gouraud Shading类似,是早期GPU使用较多的一种渲染方式。
4.6.2 前向渲染(Forward Rendering)
前向渲染是传统的一种渲染方式,受到广泛的硬件支持。它渲染的思路就是按照渲染管线的流程一步步渲染,最终将颜色绘制到Render Target(下图)。

它的消耗跟物体数量和灯光数量有关,是O(Nobject * Nlight)的关系,对于灯光数量较多的场景,显得力不从心。
光照计算伪代码:
Color color = Color.black;
for each(light in lights)
{
for each(object in objectsEffectedByLight)
{
color += object.color * light.color;
}
}
有些引擎(如Unity)在灯光数量多的情况下,会做一些优化:对所有灯光按亮度进行排序,将最亮的那部分灯光做逐像素计算,中间的一部分做逐顶点计算,排在后面的用球谐函数(SH,Spherical Harmonics)模拟。(见下图)

4.6.3 延迟渲染(Deferred Shading)
延迟渲染的精髓在于将灯光计算延后,与场景物体数量解耦。
具体做法是:先将所有物体渲染一遍,但不计算光照,将物体渲染后的像素数据(Position/Normal/DiffuseColor和其他参数)存于各自的GBuffer;然后,利用这些数据采用后处理方式做光照计算。(下图)

实现伪代码:
// 第一遍:渲染物体不带光照的数据,存于各自GBuffer。
for each(object in objects)
{
RenderObjectDataToGBuffers(object);
}
// 第二遍:将所有光照对所有像素做计算。
for each(light in lights)
{
Color color = Color.black;
for each(pixel in pixels)
{
color += CalculateLightColor(light, pixelDatas);
}
WriteColorToFinalRenderTarget(color);
}
由于最耗时的光照计算延迟到后处理阶段,所以跟场景的物体数量解耦,只跟Render Targe尺寸相关,复杂度是O(Nlight * Wrendertarget * Hrendertarget)。
延迟渲染并没有在低端设备支持,它要求OpenGL ES 3.0以上,多渲染纹理以及更多的显存和带宽。
4.6.4 基于瓦片的延迟渲染(Tile-Based Deferred Rendering,TBDR)
针对Deferred Shading的缺点,出现了一种改进方案,它就是Tile-Based Deferred Rendering。此种渲染方式已广泛应用于GPU图形渲染架构中。
实现思路:
1. 将渲染纹理分成一个个小块(Tile),通常是32x32。
2. 根据Tile内的Depth计算出其Bounding Box。
3. 判断Tile的Bounding Box和Light是否求交。
4. 摒弃不相交的Light,得到对Tile有作用的Light列表。
5. 遍历所有Tile,计算每个Tile有作用的Llight列表的光照。
4.6.5 渲染路径总结
前面已经描述了各个方式的优缺点,下面详细列出它们的性能消耗及平台要求。

此外,还有Forward+,Physically Based Rendering(PBR),Legacy Deferred Rendering(Unity)等渲染方式,这里不详细描述,有兴趣的可以找资料了解。
4.7 场景管理和遮挡剔除
4.7.1 场景管理
场景管理的是在游戏场景内所有具有空间属性的物体。目的是为了快速查找物体,减少物体更新,加快物理碰撞,以及渲染的遮挡剔除。
常见的场景管理方式有二叉空间分割树(BSP)/四叉树(平面空间)/八叉树(三维空间)/入口(Portail)。


上图左展示的是四叉树,图右展示的是八叉树。具体的原理和实现方式这里不描述,有兴趣的另行搜索。
4.7.2 遮挡剔除(Occlusion Culling)
遮挡剔除技术是将不在相机视截体内的物体进行剔除,不送入渲染管线处理,从而减少很多渲染物体。


上图左是没有启用遮挡剔除的场景,右图是启用剔除后的场景,可以看出,超过一半的物体被剔除渲染,优化效果非常明显。
与场景管理(4.5)的方式结合,可以实现快速剔除算法。
Unity的遮挡剔除需要设置遮挡体(Occluder)和被遮挡体(Occludee)。详见这里。
4.8 阴影
阴影的实现方式有很多种,消耗和效果各异。
4.8.1 贴图阴影
贴图的方式最简单,做法是制作一张阴影纹理,放到物体脚下(下图),跟随物体一起运动。

贴图阴影渲染非常简单,只需要两个三角面,适用于低端机型。
如果地面是起伏不平的,贴图会被地面遮挡,可以将阴影贴图用贴花技术紧贴地面。
但贴花依然有可能跟其它动态物体发生异常遮挡。
4.8.2 Projector(投射阴影)
Projector技术是预先指定光源位置和截头体(Frustum),然后算出物体在其它物体的投影。(下图)

它可以将物体投影到任意平面上,但跟贴图阴影一样不能表达被投影物体的轮廓。适用于中等画质效果。
4.8.3 Shadow Map(阴影图)

阴影图技术是将物体放入灯光空间(上图)渲染,得到灯光空间的深度图(也称阴影图),然后在正常渲染时只要让某个片元在灯光空间的深度与阴影图做比较,就可判断出该片元是否处在阴影之中(下图)。

Shadow Map技术可以渲染物体在任意平面的投影,渲染的效果最接近真实世界(下图),但性能消耗会高很多,它会增加Draw Calls,增加显存占用。通常适用于高端机型或重要角色。

4.8.4 阴影的分级策略
ShadowMap效果最好,但最耗性能,而贴图方式刚好相反。
这就要根据项目具体情况做出分级策略,针对不同画质不同重要程度的物体采用不同的阴影渲染方式。下表是游戏Z的分级策略。

4.9 带宽优化
带宽优化的目的是减少CPU与GPU之间的数据传输。
4.9.1 LOD(Level Of Detail)
LOD即细节层次,根据物体在画面的大小选用不同级别的资源,以减少渲染和带宽的消耗。
LOD在图形渲染中应用广泛,适用的对象有模型LOD,地表LOD,材质LOD,植被/树LOD,灯光LOD,纹理LOD(MipMaps)等等。
下图所示的是物体离相机越来越远,采用不同LOD的物体,其中LOD0精度最高,LOD2精度最低。

Unity引擎是通过LODGroup组件实现模型LOD的。(下图)

4.9.2 GPU Instance
GPU Instance技术应用于绘制相同Mesh的多个实例,每个实例都可以有独自的参数(如Color/Position/Scale等)。这种技术可以减少带宽,只需传入一份Mesh数据,就可以绘制任意多个实例。
常用于绘制建筑,地表装饰物,粒子,草,树,植被等等。

上图所示的场景共有1900多个小球,但Batch数只有24,这就是开启了GPU Instance的效果。但它对平台有一定要求:

4.9.3 GPU Skin
CPU Skin最基本的角色动画实现方式,它可以方便地实现很复杂的动画操作,如融合/渐隐/组合/串接等等。但它的缺点也显而易见,占用大量CPU计算性能,难以并行计算,每帧需传送模型顶点数据到GPU,增加带宽负载。
GPU Skin的做法是将骨骼矩阵列表作为Uniform传入Shader,然后在Vertex Shader中对模型顶点进行蒙皮计算。它可以并行计算,减轻CPU负载,此外,由于每帧传入GPU的数据是骨骼矩阵,不是顶点数据,极大降低了带宽负载。
当然,GPU Skin也有缺陷。它会提高GPU负载,最高骨骼数往往受限于平台(如OpenGL ES 2.0不能超过250个Vector4数据量),而且也不利于做复杂的动画操作。
Unity引擎可以在PlayerSettings面板开启GPU skin(下图)。

此外,GPU Skin还可以结合GPU Instance技术,以渲染大量相同角色的骨骼动画。详见这里。
4.9.4 GPU粒子
GPU粒子的优缺点和GPU Skin类似,支持粒子的并行运算,减少带宽负载,但它同样难以实现粒子的高级特性(软粒子/碰撞等)。
Unity对模型粒子做了特殊优化,支持GPU Instancing(下图)。

4.9.5 正确使用Buffer标记
OpenGL的Buffer标记有以下几种:
GL_STREAM_DRAW
GL_STREAM_READ
GL_STREAM_COPYGL_STATIC_DRAW
GL_STATIC_READ
GL_STATIC_COPYGL_DYNAMIC_DRAW
GL_DYNAMIC_READ
GL_DYNAMIC_COPY
1. DRAW:Buffer数据将会被送往GPU进行绘制。
2. READ:Buffer数据会被CPU应用程序读取。
3. COPY:Buffer数据会被用于绘制和读取。
4. STATIC:一次修改,多次使用。可用于静态模型顶点数据。
5. DYNAMIC:多次修改,多次使用。可用于带动画的模型顶点数据,粒子系统的数据。
6. STREAM:多次修改,一次使用。可用于特殊场合,比如编辑器数据。
Buffer的标记各有用途,所以选择合适的类型可以减少带宽负载和显存占用。
4.10 Shader优化
1. 避免使用耗时的数学运算。如pow,exp,log,sin,cos,tan等等。
2. 使用更低精度的浮点数。OpenGL ES的浮点数有三种精度:highp(32位浮点), mediump(16位浮点), lowp(8位浮点),很多计算不需要高精度,可以改成低精度浮点。
precision mediump float; // Defines precision for float and float-derived (vector/matrix) types.
uniform lowp sampler2D sampler; // Texture2D() result is lowp.
varying lowp vec4 color;
varying vec2 texCoord; // Uses default mediump precision.
3. 禁用discard操作。原因见4.2.2。
4. 避免重复计算。
precision mediump float;
float a = 0.9;
float b = 0.6;
varying vec4 vColor;
void main()
{
gl_FragColor = vColor * a * b; // a * b每个像素都会计算,导致冗余的消耗。
}
5. 向量延迟计算。
highp float f0, f1;
highp vec4 v0, v1;
v0 = (v1 * f0) * f1; // v1和f0计算后返回一个向量,再和f1计算,多了一次向量计算。
// 改成:
v0 = v1 * (f0 * f1); // 先计算两个浮点数,这样只需跟向量计算一次。
6. 充分利用向量分量掩码。
highp vec4 v0;
highp vec4 v1;
highp vec4 v2;
v2.xz = v0 * v1; // v2只用了xz分量,比v2 = v0 * v1的写法要快。
7. 避免计算数组下标。在shader使用动态下标会导致较大的开销。
8. 警惕动态纹理采样(Dynamic Texture Lookup,也叫Dependent Texture Read)。也就是说在shader中,纹理坐标做了更改,就是动态纹理采样(也称依赖式纹理读取)。在OpenGL ES 2.0的架构下,动态纹理采样会出现较大的性能问题;3.0则没有这问题。详细看这里。
varying vec2 vTexCoord;
uniform sampler2D textureSampler;
void main()
{
vec2 modifiedTexCoord = vec2(1.0 - vTexCoord.x, 1.0 - vTexCoord.y); // 纹理坐标改变了
gl_FragColor = texture2D(textureSampler, modifiedTexCoord); // 触发了Dynamic Texture Lookup/Dependent Texture Read。
}
9. 避免临时变量。
10. 避免使用for等循环语句。可以尝试展开。
11. 尽量将Pixel Shader计算移到Vertex Shader。例如像素光改成顶点光。
12. 将跟顶点或像素无关的计算移到CPU,然后通过uniform传进来。
13. 分级策略。不同画质不同平台采用不同复杂度的算法。
4.11 UI优化
UI除了资源优化(2.2)之外,可以在渲染上做一些优化措施。
1. 避免不同图集的控件交叉。交叉会增加draw calls,所以要避免。
2. 动态区域和静态区域分离。即文字/道具等动态控件放在同一层,而其它静态的控件尽量放至同一层,可以提高合批的概率。
4.12 其它渲染优化
4.12.1 避免后处理
后处理是场景物体渲染完成后,对渲染纹理做逐像素处理,以便实现各种全屏效果,包含以下效果:
- 抗锯齿:Anti-aliasing (FXAA & TAA)
- 环境光散射:Ambient Occlusion
- 屏幕空间反射:Screen Space Reflection
- 雾:Fog
- 景深:Depth of Field
- 运动模糊:Motion Blur
- 人眼调节:Eye Adaptation
- 发光:Bloom
- 颜色校正:Color Grading
- 颜色查找表:User Lut
- 色差:Chromatic Aberration
- 颗粒:Grain
- 暗角:Vignette
- 噪点:Dithering
Unity的后处理栈:

虽然后处理可以渲染出非常多的很酷很真实的效果,但是消耗也不容小觑。
特别是在移动端,由于移动设备硬件架构的特殊设计,会导致更为严重的性能问题,主要原因是:
1. 更慢的依赖式纹理读取(slower dependent texture reads)。关于依赖式纹理读取的解释看这里。
2. 缺少硬件特性(missing hardware features)。
3. 额外的渲染纹理解析消耗(extra render target resolve costs)。
所以移动游戏要尽量避免使用后处理。
4.12.2 降分辨率
降分辨率是最粗暴最有效的提升渲染性能的方法。
由于当前很多智能设备分辨率都是超高清,动辄2K以上,但CPU/GPU却跟不上,如果使用原始屏幕分辨率,就会出现严重的卡帧/掉帧现象。
通常可以将屏幕分辨率降到一半,这样渲染纹理/深度Buffer/纹理等等数据都可以缩减到原来的1/4,极大降低了CPU/GPU/带宽各项指标的消耗。
5. 内存优化
内存优化目的是加快IO,防止卡主线程,防止频繁操作(创建/删除)内存,避免内存碎片化和占用过高。
5.1 缓存法
与CPU的缓存计算类似,思路是将需要重复创建的对象缓存起来,销毁时将它放入缓存列表,再次创建时优先从缓存列表中读取。
实现伪代码:
Array<Object> _objectCache;
Object CreateObject()
{
// 先尝试从缓存中获取对象
if (_objectCache.size() > 0)
{
return _objectCache.pop_back();
}
return new Object();
}
void DestroyObject(Object obj)
{
_objectCache.push_back(obj); // 删除时将其放入缓存列表。
}
缓存法可以降低内存的创建/删除频率,避免碎片化。
常用于数量多且创建频繁的物体,如小兵,NPC,血条,特效,道具,各类图标等等。
5.2 内存池
内存池技术是现代主流引擎的标配,目的是避免内存碎片化,加速内存分配和管理。
实现思想通常是由引擎预先创建一块较大的内存(也可动态调整),这块内存通过有效的数据结构和算法策略,统一管理小块内存的分配和回收,并为逻辑层提供内存相关的操作接口。
内存池实现的方式很多,各有优劣,不一而足。下图是其中的一种实现方式:
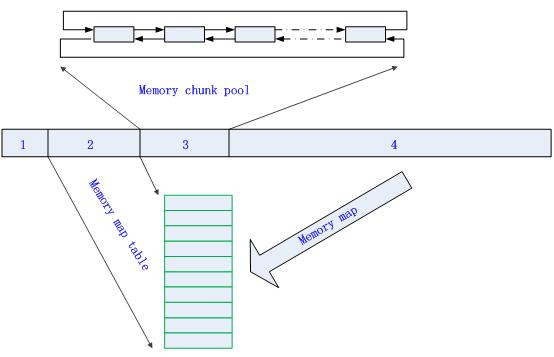
分配的内存分为四个部分:第1部分是内存池结构体信息;第2部分是内存映射表;第3部分是内存Chunk缓冲区;第4部分是可分配内存区。更多参看这里。
5.3 资源管理器
资源管理器是将所有需要用到的文件资源统一管理起来,统一创建,加载,释放,回收等,为的是提高复用率,减少资源冗余和内存开销,也是现代引擎必备的一个模块。
假如没有资源管理器,势必会造成资源的冗余,同一份资源可能存在很多份内存数据(下图)。

上图所示中,每个模型(Model)引用了一份网格(Mesh)内存数据,3个模型实例就有3份Mesh内存数据,造成Mesh内存资源的冗余。
而有了资源管理器的统一管理,所有引用到文件资源的实例都指向了同一份内存数据(下图),避免了内存资源冗余,降低内存和IO消耗。

资源管理器的实现比较简单,主要是运用模板将物体类型抽象出来,然后每个物体类型用一个map<filePath, objectData>的表存储。具体实现这里不累述。
5.4 控制GC
GC是Garbage Collect的简称,意为垃圾回收,是游戏引擎中采用一定策略回收内存池或托管堆里的无用内存和缓存区无用对象的一种技术。
GC机制就是防止内存占用过多过久,是一种自动调节内存占用的常用技法。
GC的触发一般分为两种:
1. 引擎触发。一般是时间间隔到了,或者内存占有量到了某个阈值,引擎便会触发GC。
2. 用户调用。通常引擎也提供了API给游戏应用,以便逻辑层可以控制GC的时机。例如Unity的GC.Collect()接口可以触发GC操作。
但是触发GC需要遍历内存池/托管堆/各类缓存表,还可能引发内存碎片整理操作,所以它需要耗费一定的CPU性能,是引起掉帧和卡顿的罪魁祸首之一。
那么,我们就需要在逻辑层采用一些方法,避免触发GC,或者减少触发GC的处理时间。
常用的方法:
1. 避免频繁创建/删除。这个好理解,频繁创建删除对象,会引起很多内存碎片和无用对象,增加触发GC的几率和时间。
2. 帧更新内尽量避免临时对象和创建内存。
3. for/while等循环内避免避免临时对象和创建内存。
4. 尽量避免申请大块内存。申请大块内存会导致内存暴涨,提升GC的几率。
5. 避免内存泄漏。这个需要每个技术人员的职业技能和觉悟,也可以通过一些辅助工具检查内存泄漏,详见1.3。
6. 主动调用GC。比如在进入战斗前后,切换场景前后,切换主要界面前后调用GC,可以一定程度上减少内存占用,避免掉帧/卡顿。
5.5 逻辑优化
逻辑优化的目标是尽量避免无用的内存操作,防止内存泄漏,尽快释放内存,减少全局变量的使用,关注第三方库的内存消耗。
6. 卡顿优化
相信很多研发者或玩家,都遇到这种情况:游戏大部时间运行都很流畅,但在战斗的某些时刻或者打开某些界面会卡一下,甚至卡很久。这个现象就是卡顿。
引发卡顿的原因有很多,但主要有:
1. 突发大量IO。
2. 短时大量内存操作。
3. 渲染物体突然暴涨。
4. 触发GC。
5. 加载资源量多的场景或界面。
6. 触发过多过复杂的逻辑。
避免或者缓解卡顿的技法也是围绕以上原因展开。
6.1 降帧法
跟3.3的方法类似,通过强制降低更新频率,减缓卡顿的时间。
6.2 摊帧法
摊帧法就是本来需要在同一帧处理的逻辑分为若干份,分摊到若干帧去处理,从而缓解同一帧的处理时间,减缓卡顿现象。
例如,本来在同一帧需要创建10个小兵,这个很可能会引发卡顿,那么可以每帧只创建2个,分摊到5帧创建完。
适用此法的还有资源的加载,AI的更新,物理的更新,耗时逻辑的处理等等。
此外,还可以用预处理(3.2),主次法(3.4)来避免卡顿。
6.3 限制数量法
如果降帧法,摊帧法,预处理,主次法都无法解决现象,卡顿原因又刚好是因为物体数量过多,那么限制数量就非常有必要了。
做法就非常简单,当场景内创建某种物体(角色,特效,血条等)的数量到底最大值时,便强制不再创建。
此法可能会引起逻辑的一些错误和不好的游戏体验,需谨慎使用和处理。
6.4 逻辑优化
如果卡顿是逻辑过于复杂引起的,就需要针对性地优化逻辑。每个项目的逻辑不一样,这里无法给出具体的优化措施。
6.5 IO优化
因IO慢引起主线程等待,从而导致游戏卡顿的现象非常普遍,下面有一些常用的优化技法。
6.5.1 预加载
将耗时的IO提前到某个时刻(游戏启动时,场景加载时,进入主界面时等)加载,比如有些角色资源大,可以在加载战斗场景时提前加载,以免战斗过程中卡顿。
6.5.2 异步加载
将IO异步化,以避免卡主线程。此技法应用非常普遍了,不再累述。
6.5.3 压缩资源
将本来零散的文件压缩成单个文件,或者对大文件利用一定算法(如哈夫曼编码)压缩,减少文件大小。这样也可以降低IO时间。
当然,压缩资源也有副作用,需占用多一份内存,解压缩过程也要耗费额外的CPU。
6.5.4 多级缓存
我们都知道CPU的频率是最高的,目前家用PC的主频可达3.2GHz甚至更高,CPU内有L1~L3缓存,它们速度略有差别;内存的存取速度远低于CPU,一般是2~3GHz,约是CPU的1/10。硬盘存取速度又远低于内存,普遍是0.1Gb/s,远低于内存读取速度。而网络更慢,目前即便是光纤,也不过0.02Gb/s。
通常我们能操控的是内存/磁盘和网络的数据,所以只要关注它们的速度,它们的速度关系大致如下图。

所以,多级缓存策略应运而生。
做法跟缓存法类似,只是多了层磁盘缓存,实现伪代码:
map<string, ObjectType> _memoryCache;
ObjectType CreateObject(string objectPath)
{
// 1. 先尝试从内存缓存中读取,有就直接返回。
if (_memoryCache.count(objectPath) > 0)
{
return _memoryCache[objectPath];
}
ObjectType obj = NULL;
// 2. 再尝试从磁盘加载。
if (FileExisted(objectPath))
{
obj = LoadObjectFromFile(objectPath);
_memoryCache[objectPath] = obj;
return obj;
}
// 3. 最后才从网络下载
DownloadObjectFromNet(objectPath);
obj = LoadObjectFromFile(objectPath);
_memoryCache[objectPath] = obj;
return obj;
}
6.5.5 控制Log
游戏的Log通常会隔一段时间存档,如果逻辑处理不好,很可能引发卡顿。比如,每帧输出大量调试log,会引发频繁存档。
游戏Z在早期,也曾发生卡顿现象,后来经Profiler分析发现是Log存档引发的。
所以,有必要对Log做出一些优化。
1. 避免帧更新输出Log。防止Log数据迅速膨胀引起频繁存档或增加存档时间。
2. 改进Log存档机制。可以适当改进Log存档机制,比如每隔多少时间存档一次,或者Log数据到达一定量级触发。
3. 建立Log等级。可以将Log分为Info,Warning,Error几个级别,不重要的log不存档。
4. 异步存档。将存档Log的逻辑防止单独的线程,防止卡主线程。
5. 避免无用的log。这就要在逻辑层控制log输出,避免无效的log。
6.5.6 JSON代替XML
游戏数据存储一般有两种:二进制和文本格式。二进制格式数据量最小,但可读性和扩展性差,适合存储模型/纹理/字体/音频等数据。文本格式的特点跟二进制刚好相反,适合存储配置信息。
最常见的文本格式有JSON和XML两种,其中JSON对比XML有诸多优点:
1. 数据量少。表达同样的数据,JSON格式可以比XML少40%(见下)。
<?xml version="1.0" encoding="utf-8" ?>
<country>
<name>中国</name>
<province>
<name>福建</name>
<citys>
<city>福州</city>
<city>南平</city>
</citys>
</province>
<province>
<name>广东</name>
<citys>
<city>广州</city>
<city>深圳</city>
<city>梅州</city>
</citys>
</province>
</country>
{
name: "中国",
provinces: [
{ name: "福建", citys: { city: ["福州", "南平"]} },
{ name: "广东", citys: { city: ["广州", "深圳", "梅州"]} }
]
}
2. 可读性更佳。上面两段分别是XML和JSON表达相同的数据,谁可读性更佳一目了然。
3. 更快的解析。JSON因为数据量更小,IO也会更快,解析速度当然也更快。
每个游戏都有大量逻辑数据需要存档,比如角色信息,技能信息,场景信息,配置信息等等。这些数据如果适合用文本格式存储,首选JSON无疑。
6.6 使用进度条
如果上面那些章节都无法解决卡顿现象,可以尝试使用进度条。
思路是将卡顿逻辑抽离出来,分成若干阶段(step),每完成一个step,给一帧时间刷新UI进度条。当然也可以用异步方式实现。
伪代码:
HandleStep1();
RefreshProgressBar(1 / n);
WaitForNextFrame();
HandleStep2();
RefreshProgressBar(2 / n);
WaitForNextFrame();
...
HandleStepN();
RefreshProgressBar(1);
WaitForNextFrame();
7. 耗电优化
游戏耗电和游戏卡并无必然联系,有些游戏在某些设备上虽然运行很流畅,但发现耗电很厉害,玩了不到半个小时,电量已经出现警报。
游戏耗电的原因主要是因为:CPU占用普遍高,内存操作频繁,磁盘IO频繁,渲染消耗普遍高,导致带宽负载和GPU消耗高。
前面介绍的章节基本可以降低耗电,也是优化耗电的必要措施。尤其是以下章节对耗电优化更明显:
2. 资源优化
3.3 限帧法
3.4 主次法
3.6 引擎模块优化
4 渲染优化
5.4 控制GC
6. 5 IO优化
除了以上章节,还可以用动态调整帧率和画质的优化技法。
7.1 动态调整限帧
游戏逻辑通常可以获取当前设备的电量,若可以,则每隔一段时间获取一次电量信息,可以统计出单位耗电量,如果发现单位时间耗电量过高,而游戏帧率又很高(比如大于50),可以主动降低帧率(比如30)。
7.2 动态调整画质
做法跟动态限帧类似,只是调整的是画质等级,而不是帧率。当然也可以一起结合使用。
8. 网络优化
网络优化的目的是让网络包更小,响应更及时,消耗更少流量,不卡主线程。
8.1 减少无用字段
网络包中通常包含了很多信息,诸如角色位置,朝向,状态等。
如果是2.5D游戏,则位置z分量可以弃掉;朝向只在xz平面上,所以只需要发送RotationY。
通过这种减少无用字段,可以一定程度上降低网络包大小。
8.2 降低字段精度
通常逻辑里的很多信息都是4字节,包括角色位置,朝向,技能或Buff信息等。但很多时候,这些信息不可能达到4字节数的最大值,可以压缩至2字节甚至1字节。
比如,同样是位置,场景的尺寸通常在2字节数的表示范围内(-32512~32512),可以将位置的x/y/z压缩至2字节发送。同样地,朝向RotationY可以2字节表示。
8.3 避免重复发送
游戏网络模块须有效限制部分协议在短时间内重复发送,例如玩家在短时间内按了很多次抽奖按钮。
所以需要一种机制来限制。比如可以在网络协议定义时,加个标记,表明该协议不能在某个时间段内重复发送。
8.4 网络异步化
开辟独立的线程处理收发网络协议包,是游戏常见的优化手段,可以避免与主线程相互等待。
8.5 压缩无效字节
压缩无效字节是指通过一种方式剔除每个字段内高位全0的数据。
比如角色等级50,如果用int32表示,是00000000 00000000 00000000 00110010,高位3个字节全是0,可以压缩至1字节。
这里有一种压缩字节的方法,跟utf8编码方式类似。
utf8的编码方式(x代表有效位):
1字节(最大有效位7) :0xxxxxxx
2字节(最大有效位11):110xxxxx 10xxxxxx
3字节(最大有效位16):1110xxxx 10xxxxxx 10xxxxxx
4字节(最大有效位21):11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
5字节(最大有效位26):111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
6字节(最大有效位31):1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
比如角色等级50,有效位是6,用1字节便够了,压缩成00110010(红色是压缩位标记)。
如果是数字1000,int32表示为00000000 00000000 00000011 11101000,有效位是10,需要2字节编码,压缩后是11001111 10101000(红色是压缩位标记)。
采用这种压缩方式,普遍可以用1~2个字节取代4字节数据,压缩效果比较明显。
8.6 压缩协议包
8.5压缩的是字段内数据,每个数据包其实有很多相同的数字,可以用目前主流的压缩方法再对网络包做一次压缩。
游戏最常用的压缩方法是zlib开源库,还可以用lz4方法。具体实现可以另外寻资料,这里不详述。
9. 总结
看到这里,基本也就结束本文内容了,希望此文能给各位游戏开发这带来实质的优化技法或者新的思路。
当然还需要说一下性能优化常见的一些误区。
9.1 优化误区
9.1.1 文件小的图片占用内存也小
有些人以为图片文件小,它占用的内存也会小,所以有些人将图片转成高压缩率的jpg格式。
那么这个看法和做法是否妥当呢?
根据2.1章节,可以看出图片占用的内存大小跟图片的尺寸和像素格式相关,跟文件格式没关系。
所以,图片转成jpg只是压缩了文件大小,但并不能降低内存开销!
9.1.2 合批的数据越大越好
有人会认为即然合批能够降低渲染消耗,是不是让合批后的数据越大越好,以便更多地降低Draw Call呢?
答案是否定的。
原因有二:
1. 移动游戏的模型索引通常做了优化,只用16位表示,也就是说如果合批后的顶点数超过65025,便会越界,导致渲染异常。
2. 太大的数据量可能无法充分利用LOD,遮挡剔除等技术,导致过多的数据送入GPU,反而增加带宽和GPU消耗。
9.1.3 片元等同于像素
片元(fragment)是GPU内部的几何体光栅化后形成的最小表示单元,它经过一系列片元操作(alpha测试,深度测试,模板测试等)后,才可能最终写入渲染纹理成为像素(pixel)。
所以,片元不是像素,但有概率成为像素。
================ 全文终 ================
特别说明:
1. 部分图片来自网络,侵删。
2. 欢迎各路大神提供更多优化技法,我会纳入合理建议,并将提议者列入感谢名单。
感谢名单:
暂无
3. 欢迎分享本文链接。
4. 未经本人同意,禁止转载。
参考文献:
《OpenGL编程指南(第四版)》
《OpenGL ES 2.0编程指南》
《计算机图形学(第三版)》
《实时计算机图形学(第二版)》
Understanding optimization in Unity
Performance Optimization for Mobile Devices
50 Tips for Working with Unity (Best Practices)
WWDC 2018:写给 OpenGL 开发者们的 Metal 开发指南
Lighting in vertex and fragment shader
OpenGLInsights-TileBasedArchitectures