Hbase总结(一)-hbase命令
下面我们看看HBase Shell的一些基本操作命令,我列出了几个常用的HBase Shell命令,如下:
|
名称 |
命令表达式 |
|
创建表 |
create '表名称', '列名称1','列名称2','列名称N' |
|
添加记录 |
put '表名称', '行名称', '列名称:', '值' |
|
get '表名称', '行名称' |
|
|
查看表中的记录总数 |
count '表名称' |
|
删除记录 |
delete '表名' ,'行名称' , '列名称' |
|
删除一张表 |
先要屏蔽该表,才能对该表进行删除,第一步 disable '表名称' 第二步 drop '表名称' |
|
查看所有记录 |
scan "表名称" |
|
查看某个表某个列中所有数据 |
scan "表名称" , ['列名称:'] |
|
更新记录 |
就是重写一遍进行覆盖 |
下面是一些常见命令的说明,在hbaseshell中输入help的帮助信息,在本文中,我们先介绍前3个,后面2个,将在下一篇博文中介绍。
COMMAND GROUPS:
Group name: general
Commands: status, version
Group name: ddl
Commands: alter, create, describe, disable,drop, enable, exists, is_disabled, is_enabled, list
Group name: dml
Commands: count, delete, deleteall, get,get_counter, incr, put, scan, truncate
Group name: tools
Commands: assign, balance_switch, balancer,close_region, compact, flush, major_compact, move, split, unassign, zk_dump
Group name: replication
Commands: add_peer, disable_peer,enable_peer, remove_peer, start_replication, stop_replication
一、一般操作
1.查询服务器状态
hbase(main):024:0>status
3 servers, 0 dead,1.0000 average load
2.查询hive版本
hbase(main):025:0>version
0.90.4, r1150278,Sun Jul 24 15:53:29 PDT 2011
二、DDL操作
1.创建一个表
hbase(main):011:0>create 'member','member_id','address','info'
0 row(s) in 1.2210seconds
2.获得表的描述
hbase(main):012:0>list
TABLE
member
1 row(s) in 0.0160seconds
hbase(main):006:0>describe 'member'
DESCRIPTION ENABLED
{NAME => 'member', FAMILIES => [{NAME=> 'address', BLOOMFILTER => 'NONE', REPLICATION_SCOPE => '0', true
VERSIONS => '3', COMPRESSION => 'NONE',TTL => '2147483647', BLOCKSIZE => '65536', IN_MEMORY => 'fa
lse', BLOCKCACHE => 'true'}, {NAME =>'info', BLOOMFILTER => 'NONE', REPLICATION_SCOPE => '0', VERSI
ONS => '3', COMPRESSION => 'NONE', TTL=> '2147483647', BLOCKSIZE => '65536', IN_MEMORY => 'false',
BLOCKCACHE => 'true'}]}
1 row(s) in 0.0230seconds
3.删除一个列族,alter,disable,enable
我们之前建了3个列族,但是发现member_id这个列族是多余的,因为他就是主键,所以我们要将其删除。
hbase(main):003:0>alter 'member',{NAME=>'member_id',METHOD=>'delete'}
ERROR: Table memberis enabled. Disable it first before altering.
报错,删除列族的时候必须先将表给disable掉。
hbase(main):004:0>disable 'member'
0 row(s) in 2.0390seconds
hbase(main):005:0>alter'member',{NAME=>'member_id',METHOD=>'delete'}
0 row(s) in 0.0560seconds
hbase(main):006:0>describe 'member'
DESCRIPTION ENABLED
{NAME => 'member', FAMILIES => [{NAME=> 'address', BLOOMFILTER => 'NONE', REPLICATION_SCOPE => '0',false
VERSIONS => '3', COMPRESSION => 'NONE',TTL => '2147483647', BLOCKSIZE => '65536', IN_MEMORY => 'fa
lse', BLOCKCACHE => 'true'}, {NAME =>'info', BLOOMFILTER => 'NONE', REPLICATION_SCOPE => '0', VERSI
ONS => '3', COMPRESSION => 'NONE', TTL=> '2147483647', BLOCKSIZE => '65536', IN_MEMORY => 'false',
BLOCKCACHE => 'true'}]}
1 row(s) in 0.0230seconds
该列族已经删除,我们继续将表enable
hbase(main):008:0> enable 'member'
0 row(s) in 2.0420seconds
4.列出所有的表
hbase(main):028:0>list
TABLE
member
temp_table
2 row(s) in 0.0150seconds
5.drop一个表
hbase(main):029:0>disable 'temp_table'
0 row(s) in 2.0590seconds
hbase(main):030:0>drop 'temp_table'
0 row(s) in 1.1070seconds
6.查询表是否存在
hbase(main):021:0>exists 'member'
Table member doesexist
0 row(s) in 0.1610seconds
7.判断表是否enable
hbase(main):034:0>is_enabled 'member'
true
0 row(s) in 0.0110seconds
8.判断表是否disable
hbase(main):032:0>is_disabled 'member'
false
0 row(s) in 0.0110seconds
三、DML操作
1.插入几条记录
put'member','scutshuxue','info:age','24'
put'member','scutshuxue','info:birthday','1987-06-17'
put'member','scutshuxue','info:company','alibaba'
put'member','scutshuxue','address:contry','china'
put'member','scutshuxue','address:province','zhejiang'
put'member','scutshuxue','address:city','hangzhou'
put'member','xiaofeng','info:birthday','1987-4-17'
put'member','xiaofeng','info:favorite','movie'
put'member','xiaofeng','info:company','alibaba'
put'member','xiaofeng','address:contry','china'
put'member','xiaofeng','address:province','guangdong'
put'member','xiaofeng','address:city','jieyang'
put'member','xiaofeng','address:town','xianqiao'
2.获取一条数据
获取一个id的所有数据
hbase(main):001:0>get 'member','scutshuxue'
COLUMN CELL
address:city timestamp=1321586240244, value=hangzhou
address:contry timestamp=1321586239126, value=china
address:province timestamp=1321586239197, value=zhejiang
info:age timestamp=1321586238965, value=24
info:birthday timestamp=1321586239015, value=1987-06-17
info:company timestamp=1321586239071, value=alibaba
6 row(s) in 0.4720seconds
获取一个id,一个列族的所有数据
hbase(main):002:0>get 'member','scutshuxue','info'
COLUMN CELL
info:age timestamp=1321586238965, value=24
info:birthday timestamp=1321586239015, value=1987-06-17
info:company timestamp=1321586239071, value=alibaba
3 row(s) in 0.0210seconds
获取一个id,一个列族中一个列的所有数据
hbase(main):002:0>get 'member','scutshuxue','info:age'
COLUMN CELL
info:age timestamp=1321586238965, value=24
1 row(s) in 0.0320seconds
6.更新一条记录
将scutshuxue的年龄改成99
hbase(main):004:0>put 'member','scutshuxue','info:age' ,'99'
0 row(s) in 0.0210seconds
hbase(main):005:0>get 'member','scutshuxue','info:age'
COLUMN CELL
info:age timestamp=1321586571843, value=99
1 row(s) in 0.0180seconds
3.通过timestamp来获取两个版本的数据
hbase(main):010:0>get 'member','scutshuxue',{COLUMN=>'info:age',TIMESTAMP=>1321586238965}
COLUMN CELL
info:age timestamp=1321586238965, value=24
1 row(s) in 0.0140seconds
hbase(main):011:0>get 'member','scutshuxue',{COLUMN=>'info:age',TIMESTAMP=>1321586571843}
COLUMN CELL
info:age timestamp=1321586571843, value=99
1 row(s) in 0.0180seconds
4.全表扫描:
hbase(main):013:0>scan 'member'
ROW COLUMN+CELL
scutshuxue column=address:city, timestamp=1321586240244, value=hangzhou
scutshuxue column=address:contry, timestamp=1321586239126, value=china
scutshuxue column=address:province, timestamp=1321586239197, value=zhejiang
scutshuxue column=info:age,timestamp=1321586571843, value=99
scutshuxue column=info:birthday, timestamp=1321586239015, value=1987-06-17
scutshuxue column=info:company, timestamp=1321586239071, value=alibaba
temp column=info:age, timestamp=1321589609775, value=59
xiaofeng column=address:city, timestamp=1321586248400, value=jieyang
xiaofeng column=address:contry, timestamp=1321586248316, value=china
xiaofeng column=address:province, timestamp=1321586248355, value=guangdong
xiaofeng column=address:town, timestamp=1321586249564, value=xianqiao
xiaofeng column=info:birthday, timestamp=1321586248202, value=1987-4-17
xiaofeng column=info:company, timestamp=1321586248277, value=alibaba
xiaofeng column=info:favorite, timestamp=1321586248241, value=movie
3 row(s) in 0.0570seconds
5.删除id为temp的值的‘info:age’字段
hbase(main):016:0>delete 'member','temp','info:age'
0 row(s) in 0.0150seconds
hbase(main):018:0>get 'member','temp'
COLUMN CELL
0 row(s) in 0.0150seconds
6.删除整行
hbase(main):001:0>deleteall 'member','xiaofeng'
0 row(s) in 0.3990seconds
7.查询表中有多少行:
hbase(main):019:0>count 'member'
2 row(s) in 0.0160seconds
8.给‘xiaofeng’这个id增加'info:age'字段,并使用counter实现递增
hbase(main):057:0*incr 'member','xiaofeng','info:age'
COUNTER VALUE = 1
hbase(main):058:0>get 'member','xiaofeng','info:age'
COLUMN CELL
info:age timestamp=1321590997648, value=x00x00x00x00x00x00x00x01
1 row(s) in 0.0140seconds
hbase(main):059:0>incr 'member','xiaofeng','info:age'
COUNTER VALUE = 2
hbase(main):060:0>get 'member','xiaofeng','info:age'
COLUMN CELL
info:age timestamp=1321591025110, value=x00x00x00x00x00x00x00x02
1 row(s) in 0.0160seconds
获取当前count的值
hbase(main):069:0>get_counter 'member','xiaofeng','info:age'
COUNTER VALUE = 2
9.将整张表清空:
hbase(main):035:0>truncate 'member'
Truncating 'member'table (it may take a while):
- Disabling table...
- Dropping table...
- Creating table...
0 row(s) in 4.3430seconds
可以看出,hbase是先将掉disable掉,然后drop掉后重建表来实现truncate的功能的。
hbase总结(二)-hbase安装
本篇介绍两种HBase的安装方式:本地安装方式和伪分布式安装方式。
安装的前提条件是已经成功安装了hadoop,而且hadoop的版本要和hbase的版本相匹配。
我将要安装的hbase是hbase-0.94.11版本,需要的hadoop是hadoop-1.2.1版本。
hbase下载地址:http://mirror.bit.edu.cn/apache/hbase/hbase-0.94.11/
将下载的hbase-0.94.11解压到相应的目录,如/usr/hbase-0.94.11
将hbase-0.90.4重命名为hbase
mv hbase-0.94.11 hbase
首先需要将hbase下的bin目录添加到系统的path中,修改/etc/profile,添加如下的内容:
export PATH=$PATH:/usr/hbase/bin
1.单机安装 修改hbase下的conf目录下的配置文件hbase-env.sh
首先,修改hbase-env.sh中的如下属性:
export JAVA_HOME=/usr/java/jdk1.6 export HBASE_MANAGES_ZK=true //此配置信息,设置由hbase自己管理zookeeper,不需要单独的zookeeper。
2.伪分布式安装 修改hbase-0.90.4下的conf目录下的配置文件hbase-env.sh和hbase-site.xml
首先,修改hbase-env.sh中的如下属性:
export JAVA_HOME=/usr/java/jdk1.6 export HBASE_CLASSPATH=/usr/hadoop/conf export HBASE_MANAGES_ZK=true
然后,修改hbase-site.xml文件

<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://192.168.70.130:9000/hbase</value> >//此属性要根据自己的hadoop的配置信息进行相应的修改
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
</configuration>
完成以上操作,就可以正常启动Hbase了,启动顺序:先启动Hadoop——>再启动Hbase,关闭顺序:先关闭Hbase——>再关闭Hadoop。
首先启动hadoop,(如果hadoop已经正常启动可以不再启动,直接查看进程是否正确,如果进程不正确,那么必须重新调试hadoop确保hadoop正常运行后再启动hbase),这里还要让HDFS处于非安全模式:bin/hadoop dfsadmin -safemode leave
start-all.sh //启动hadoop jps //查看进程
2564 SecondaryNameNode 2391 DataNode 2808 TaskTracker 2645 JobTracker 4581 Jps 2198 NameNode
启动hbase:
start-hbase.sh
jps 查看:
2564 SecondaryNameNode 2391 DataNode 4767 HQuorumPeer 2808 TaskTracker 2645 JobTracker 5118 Jps 4998 HRegionServer 4821 HMaster 2198 NameNode
可以看到,HBase的相关进程已经启动了
hbase shell
进入shell模式
HBase Shell; enter 'help<RETURN>' for list of supported commands. Type "exit<RETURN>" to leave the HBase Shell Version 0.94.12, r1524863, Fri Sep 20 00:25:45 UTC 2013 hbase(main):001:0>
通过:http://localhost:60010/master-status ,可以访问HBase状态
ZCG)12J4]Y%7BK5JIG2.png)
停止hbase 如果在操作Hbase的过程中发生错误,可以通过hbase安装主目录下的logs子目录查看错误原因
先停止hbase
stop-hbase.sh
再停止hadoop
stop-all.sh
错误解决方法:
1.报错如下: localhost: Exception in thread "main" org.apache.hadoop.ipc.RPC$VersionMismatch: Protocol org.apache.hadoop.hdfs.protocol.ClientProtocol version mismatch. (client = 42, server = 41) 所以如果遇到以上错误,就通过替换jar包解决。(一般使用新版本的hadoop 和 hbase不会出现这种错误)
替换Hbase中的jar包 需要用{HADOOP_HOME}下的hadoop-1.2.1-core.jar 替换掉{HBASE_HOME}/lib目录下的hadoop-1.2.1-append-r1056497.jar 。如果不替换jar文件Hbase启动时会因为hadoop和Hbase的客户端协议不一致而导致HMaster启动异常。
2.错误如下:
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/........../lib/slf4j-log4j12-1.5.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/........../slf4j-log4j12-1.5.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
:hadoop中lib里slf4j-api-1.4.3.jar、slf4j-log4j12-1.4.3.jar和hbase中lib里对应的这两个jar包版本不一致导致冲突,把hbase里的替换成hadoop里的就可以了
3.有时候安装hbase完全分布式时会出现奇怪的问题,先去查下集群中各个服务器时间,是否相差太多,最好一致
NTP:集群的时钟要保证基本的一致。稍有不一致是可以容忍的,但是很大的不一致会 造成奇怪的行为。 运行 NTP 或者其他什么东西来同步你的时间.
如果你查询的时候或者是遇到奇怪的故障,可以检查一下系统时间是否正确!
设置集群各个节点时钟:date -s “2012-02-13 14:00:00”
4.2014-10-09 14:11:53,824 WARN org.apache.hadoop.hbase.master.AssignmentManager: Failed assignment of -ROOT-,,0.70236052 to 127.0.0.1,60020,1412820297393, trying to assign elsewhere instead; retry=0
org.apache.hadoop.hbase.client.RetriesExhaustedException: Failed setting up proxy interface org.apache.hadoop.hbase.ipc.HRegionInterface to /127.0.0.1:60020 after attempts=1
at org.apache.hadoop.hbase.ipc.HBaseRPC.waitForProxy(HBaseRPC.java:242)
at org.apache.hadoop.hbase.client.HConnectionManager$HConnectionImplementation.getHRegionConnection(HConnectionManager.java:1278)
at org.apache.hadoop.hbase.client.HConnectionManager$HConnectionImplementation.getHRegionConnection(HConnectionManager.java:1235)
at org.apache.hadoop.hbase.client.HConnectionManager$HConnectionImplementation.getHRegionConnection(HConnectionManager.java:1222)
at org.apache.hadoop.hbase.master.ServerManager.getServerConnection(ServerManager.java:496)
at org.apache.hadoop.hbase.master.ServerManager.sendRegionOpen(ServerManager.java:429)
at org.apache.hadoop.hbase.master.AssignmentManager.assign(AssignmentManager.java:1592)
at org.apache.hadoop.hbase.master.AssignmentManager.assign(AssignmentManager.java:1329)
at org.apache.hadoop.hbase.master.AssignCallable.call(AssignCallable.java:44)
at java.util.concurrent.FutureTask$Sync.innerRun(FutureTask.java:303)
at java.util.concurrent.FutureTask.run(FutureTask.java:138)
at java.util.concurrent.ThreadPoolExecutor$Worker.runTask(ThreadPoolExecutor.java:895)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:918)
at java.lang.Thread.run(Thread.java:662)
Caused by: java.net.ConnectException: Connection refused
解决如下:
/etc/hosts里边配置出的问题
127.0.1.1 后边是对应的主机名
将127.0.1.1改为127.0.0.1,问题解决
Hbase总结(四)- Hbase与传统数据库的区别
其实说白了,这些就是事先没有认清楚互联网应用什么才是最重要的。从系统架构的角度来说,互联网应用更加看重系统性能以及伸缩性,而传统企业级应用都是比较看重数据完整性和数据安全性。那么我们就来说说互联网应用伸缩性这事儿.对于伸缩性这事儿,哥们儿我也写了几篇博文,想看的兄弟可以参考我以前的博文,对于web server,app server的伸缩性,我在这里先不说了,因为这部分的伸缩性相对来说比较容易一点,我主要来回顾一些一个慢慢变大的互联网应用如何应对数据库这一层的伸缩。
首先刚开始,人不多,压力也不大,搞一台数据库服务器就搞定了,此时所有的东东都塞进一个Server里,包括web server,app server,db server,但是随着人越来越多,系统压力越来越多,这个时候可能你把web server,app server和db server分离了,好歹这样可以应付一阵子,但是随着用户量的不断增加,你会发现,数据库这哥们不行了,速度老慢了,有时候还会宕掉,所以这个时候,你得给数据库这哥们找几个伴,这个时候Master-Salve就出现了,这个时候有一个Master Server专门负责接收写操作,另外的几个Salve Server专门进行读取,这样Master这哥们终于不抱怨了,总算读写分离了,压力总算轻点了,这个时候其实主要是对读取操作进行了水平扩张,通过增加多个Salve来克服查询时CPU瓶颈。一般这样下来,你的系统可以应付一定的压力,但是随着用户数量的增多,压力的不断增加,你会发现Master server这哥们的写压力还是变的太大,没办法,这个时候怎么办呢?你就得切分啊,俗话说“只有切分了,才会有伸缩性嘛”,所以啊,这个时候只能分库了,这也是我们常说的数据库“垂直切分”,比如将一些不关联的数据存放到不同的库中,分开部署,这样终于可以带走一部分的读取和写入压力了,Master又可以轻松一点了,但是随着数据的不断增多,你的数据库表中的数据又变的非常的大,这样查询效率非常低,这个时候就需要进行“水平分区”了,比如通过将User表中的数据按照10W来划分,这样每张表不会超过10W了。
综上所述,一般一个流行的web站点都会经历一个从单台DB,到主从复制,到垂直分区再到水平分区的痛苦的过程。其实数据库切分这事儿,看起来原理貌似很简单,如果真正做起来,我想凡是sharding过数据库的哥们儿都深受其苦啊。对于数据库伸缩的文章,哥们儿可以看看后面的参考资料介绍。
好了,从上面的那一堆废话中,我们也发现数据库存储水平扩张scale out是多么痛苦的一件事情,不过幸好技术在进步,业界的其它弟兄也在努力,09年这一年出现了非常多的NoSQL数据库,更准确的应该说是No relation数据库,这些数据库多数都会对非结构化的数据提供透明的水平扩张能力,大大减轻了哥们儿设计时候的压力。下面我就拿Hbase这分布式列存储系统来说说。
一 Hbase是个啥东东?
在说Hase是个啥家伙之前,首先我们来看看两个概念,面向行存储和面向列存储。面向行存储,我相信大伙儿应该都清楚,我们熟悉的RDBMS就是此种类型的,面向行存储的数据库主要适合于事务性要求严格场合,或者说面向行存储的存储系统适合OLTP,但是根据CAP理论,传统的RDBMS,为了实现强一致性,通过严格的ACID事务来进行同步,这就造成了系统的可用性和伸缩性方面大大折扣,而目前的很多NoSQL产品,包括Hbase,它们都是一种最终一致性的系统,它们为了高的可用性牺牲了一部分的一致性。好像,我上面说了面向列存储,那么到底什么是面向列存储呢?Hbase,Casandra,Bigtable都属于面向列存储的分布式存储系统。看到这里,如果您不明白Hbase是个啥东东,不要紧,我再总结一下下:
Hbase是一个面向列存储的分布式存储系统,它的优点在于可以实现高性能的并发读写操作,同时Hbase还会对数据进行透明的切分,这样就使得存储本身具有了水平伸缩性。
二 Hbase数据模型
HBase,Cassandra的数据模型非常类似,他们的思想都是来源于Google的Bigtable,因此这三者的数据模型非常类似,唯一不同的就是Cassandra具有Super cloumn family的概念,而Hbase目前我没发现。好了,废话少说,我们来看看Hbase的数据模型到底是个啥东东。
在Hbase里面有以下两个主要的概念,Row key,Column Family,我们首先来看看Column family,Column family中文又名“列族”,Column family是在系统启动之前预先定义好的,每一个Column Family都可以根据“限定符”有多个column.下面我们来举个例子就会非常的清晰了。
假如系统中有一个User表,如果按照传统的RDBMS的话,User表中的列是固定的,比如schema 定义了name,age,sex等属性,User的属性是不能动态增加的。但是如果采用列存储系统,比如Hbase,那么我们可以定义User表,然后定义info 列族,User的数据可以分为:info:name = zhangsan,info:age=30,info:sex=male等,如果后来你又想增加另外的属性,这样很方便只需要info:newProperty就可以了。
也许前面的这个例子还不够清晰,我们再举个例子来解释一下,熟悉SNS的朋友,应该都知道有好友Feed,一般设计Feed,我们都是按照“某人在某时做了标题为某某的事情”,但是同时一般我们也会预留一下关键字,比如有时候feed也许需要url,feed需要image属性等,这样来说,feed本身的属性是不确定的,因此如果采用传统的关系数据库将非常麻烦,况且关系数据库会造成一些为null的单元浪费,而列存储就不会出现这个问题,在Hbase里,如果每一个column 单元没有值,那么是占用空间的。下面我们通过两张图来形象的表示这种关系:
上图是传统的RDBMS设计的Feed表,我们可以看出feed有多少列是固定的,不能增加,并且为null的列浪费了空间。但是我们再看看下图,下图为Hbase,Cassandra,Bigtable的数据模型图,从下图可以看出,Feed表的列可以动态的增加,并且为空的列是不存储的,这就大大节约了空间,关键是Feed这东西随着系统的运行,各种各样的Feed会出现,我们事先没办法预测有多少种Feed,那么我们也就没有办法确定Feed表有多少列,因此Hbase,Cassandra,Bigtable的基于列存储的数据模型就非常适合此场景。说到这里,采用Hbase的这种方式,还有一个非常重要的好处就是Feed会自动切分,当Feed表中的数据超过某一个阀值以后,Hbase会自动为我们切分数据,这样的话,查询就具有了伸缩性,而再加上Hbase的弱事务性的特性,对Hbase的写入操作也将变得非常快。
上面说了Column family,那么我之前说的Row key是啥东东,其实你可以理解row key为RDBMS中的某一个行的主键,但是因为Hbase不支持条件查询以及Order by等查询,因此Row key的设计就要根据你系统的查询需求来设计了额。我还拿刚才那个Feed的列子来说,我们一般是查询某个人最新的一些Feed,因此我们Feed的Row key可以有以下三个部分构成<userId><timestamp><feedId>,这样以来当我们要查询某个人的最进的Feed就可以指定Start Rowkey为<userId><0><0>,End Rowkey为<userId><Long.MAX_VALUE><Long.MAX_VALUE>来查询了,同时因为Hbase中的记录是按照rowkey来排序的,这样就使得查询变得非常快。
三 Hbase的优缺点
1 列的可以动态增加,并且列为空就不存储数据,节省存储空间.
2 Hbase自动切分数据,使得数据存储自动具有水平scalability.
3 Hbase可以提供高并发读写操作的支持
Hbase的缺点:
1 不能支持条件查询,只支持按照Row key来查询.
2 暂时不能支持Master server的故障切换,当Master宕机后,整个存储系统就会挂掉.
四.补充
1.数据类型,HBase只有简单的字符类型,所有的类型都是交由用户自己处理,它只保存字符串。而关系数据库有丰富的类型和存储方式。
2.数据操作:HBase只有很简单的插入、查询、删除、清空等操作,表和表之间是分离的,没有复杂的表和表之间的关系,而传统数据库通常有各式各样的函数和连接操作。
3.存储模式:HBase是基于列存储的,每个列族都由几个文件保存,不同的列族的文件时分离的。而传统的关系型数据库是基于表格结构和行模式保存的
4.数据维护,HBase的更新操作不应该叫更新,它实际上是插入了新的数据,而传统数据库是替换修改
5.可伸缩性,Hbase这类分布式数据库就是为了这个目的而开发出来的,所以它能够轻松增加或减少硬件的数量,并且对错误的兼容性比较高。而传统数据库通常需要增加中间层才能实现类似的功能
下面是用详细实际操作截图比较区别
|
1.nosql数据库能否删除列 2.nosql数据库如何删除一条记录 3.nosql数据库列族和lieder区别是什么? 4.nosql操作与传统数据库的操作区别在什么地方? 对于大多数做技术的人员,都知道我们传统数据库是什么样子的,那么如下图所示,我们操作的对象是行。 也就是增删改查,都是以为对象。 1.传统数据库增加删除介绍  图1 图1下面我们以mysql为例: 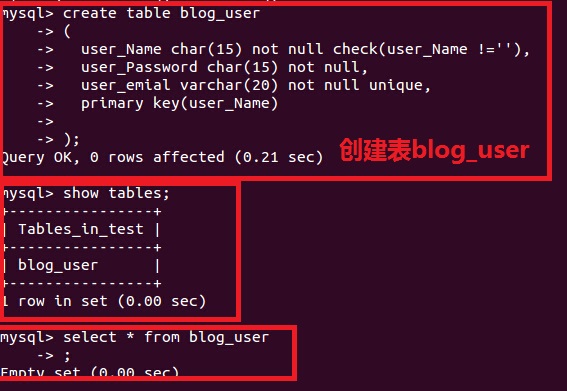 插入数据 mysql>INSERT INTO blog_user (`user_Name`,`user_Password`,`user_emial`)VALUES ('aboutyun','aboutyun', 'aboutyun@sina.com');  删除数据:
 2.Nosql数据库增加删除介绍 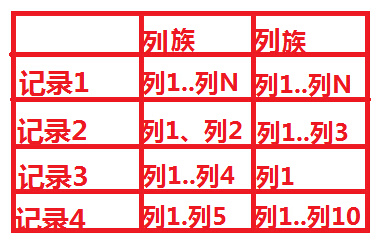 图2 以hbase为例: 创建表:
 插入数据 这里是关键点,也是很多人不容易理解的地方
 上面我们看到了 1所示是什么,我们在传统数据块里面根本没有,这是nosql所特有的,是一个rowkey,是系统自带的,也是nosql中一条记录的唯一标识。但是这个唯一标识,有跟我们的传统数据库是有所差别的。如图1所示,“记录1”便是rowkey. 2所示是我们插入的列user_Name,这也是最难以理解的地方,列竟然可以插入。并且其’value‘为3即'aboutyun' 我们插入了列,下面我们来查看一下效果:  下面来解释一下上面的含义: 我们会看到 1为rowkey,插入数据’www.aboutyun.com‘, 2为列族下面列的名字user_Name 3我们并没有在设计的添加这个列族,所以这个是系统自带的,这个是记录的操作时间,以时间戳的形式放到hbase里面。 4是我们插入的user_Name的值 下面我们在插入password:
 再次查询结果:
 到这里,我们看到两行记录,传统数据块认为这是两行数据,对于nosql,这是一条记录。 删除列数据 删除数据分为删除列和删除记录 1.删除列 这里面的删除,没有删除 delete 'blog_user','www.aboutyun.com','userInfo:user_Password'  从上面我们看出列被删除了 2.删除记录:
这是删除之前显示结果,这里已经是  删除后结果 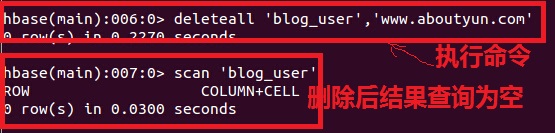 总结 对于传统数据库,增加列对于一个项目来讲,改变是非常大的。但是对于nosql,插入列和删除列,跟传统数据库里面的增加记录和删除记录类似 |
Hbase总结(五)-hbase常识及habse适合什么场景
当我们对于数据结构字段不够确定或杂乱无章很难按一个概念去进行抽取的数据适合用使用什么数据库?答案是什么,如果我们使用的传统数据库,肯定留有多余的字段,10个不行,20个,但是这个严重影响了质量。并且如果面对大数据库,pt级别的数据,这种浪费更是严重的,那么我们该使用是什么数据库?hbase数个不错的选择,那么我们对于hbase还存在下列问题:
1.Column Family代表什么?
2.HBase通过row和column确定一份数据,这份数据的值可能有多个版本,为什么会存在多个版本?
3.查询的时候会显示那个版本?
4.它们的存储类型是什么?
5.tableName是什么类型?
6.RowKey 和 ColumnName是什么类型?
7.Timestamp 是什么类型?
8.value 是什么类型?
带着以上几个问题去读下面内容:
引言
团队中使用HBase的项目多了起来,对于业务人员而言,通常并不需要从头搭建、维护一套HBase的集群环境,对于其架构细节也不一定要深刻理解(交由HBase集群维护团队负责),迫切需要的是快速理解基本技术来解决业务问题。最近在XX项目轮岗过程中,尝试着从业务人员视角去看HBase,将一些过程记录下来,期望对快速了解HBase、掌握相关技术来开展工作的业务人员有点帮助。我觉得作为一个初次接触HBase的业务开发测试人员,他需要迫切掌握的至少包含以下几点:
深入理解HTable,掌握如何结合业务设计高性能的HTable
掌握与HBase的交互,反正是离不开数据的增删改查,通过HBase Shell命令及Java Api都是需要的
掌握如何用MapReduce分析HBase里的数据,HBase里的数据总要分析的,用MapReduce是其中一种方式
掌握如何测试HBase MapReduce,总不能光写不管正确性吧,debug是需要的吧,看看如何在本机单测debug吧
本系列将围绕以上几点展开,篇幅较长,如果是HBase初学者建议边读边练,对于HBase比较熟练的,可以选读下,比如关注下HBase的MapReduce及其测试方法。
从一个示例说起
传统的关系型数据库想必大家都不陌生,我们将以一个简单的例子来说明使用RDBMS和HBase各自的解决方式及优缺点。
以博文为例,RDBMS的表设计如下: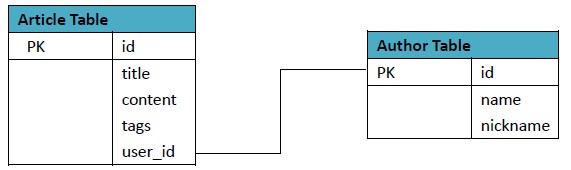
为了方便理解,我们以一些数据示例下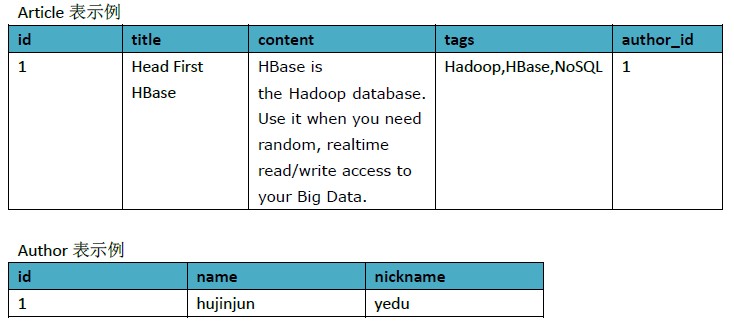
上面的例子,我们用HBase可以按以下方式设计
同样为了方便理解,我们以一些数据示例下,同时用红色标出了一些关键概念,后面会解释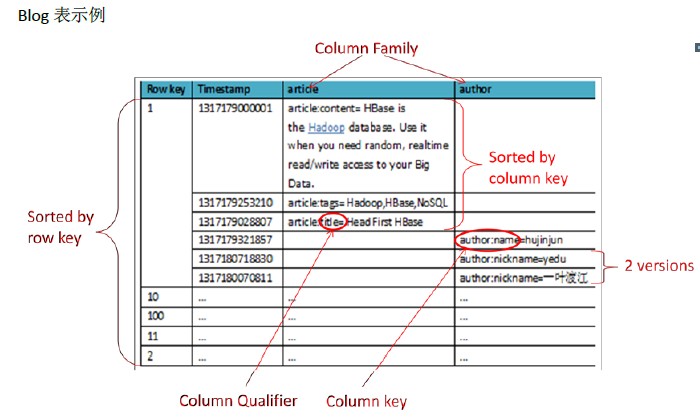
HTable一些基本概念
Row key
行主键, HBase不支持条件查询和Order by等查询,读取记录只能按Row key(及其range)或全表扫描,因此Row key需要根据业务来设计以利用其存储排序特性(Table按Row key字典序排序如1,10,100,11,2)提高性能。
Column Family(列族)
在表创建时声明,每个Column Family为一个存储单元。在上例中设计了一个HBase表blog,该表有两个列族:article和author。
Column(列)
HBase的每个列都属于一个列族,以列族名为前缀,如列article:title和article:content属于article列族,author:name和author:nickname属于author列族。
Column不用创建表时定义即可以动态新增,同一Column Family的Columns会群聚在一个存储单元上,并依Column key排序,因此设计时应将具有相同I/O特性的Column设计在一个Column Family上以提高性能。同时这里需要注意的是:这个列是可以增加和删除的,这和我们的传统数据库很大的区别。所以他适合非结构化数据。
Timestamp
HBase通过row和column确定一份数据,这份数据的值可能有多个版本,不同版本的值按照时间倒序排序,即最新的数据排在最前面,查询时默认返回最新版本。如上例中row key=1的author:nickname值有两个版本,分别为1317180070811对应的“一叶渡江”和1317180718830对应的“yedu”(对应到实际业务可以理解为在某时刻修改了nickname为yedu,但旧值仍然存在)。Timestamp默认为系统当前时间(精确到毫秒),也可以在写入数据时指定该值。
Value
每个值通过4个键唯一索引,tableName+RowKey+ColumnKey+Timestamp=>value,例如上例中{tableName=’blog’,RowKey=’1’,ColumnName=’author:nickname’,Timestamp=’ 1317180718830’}索引到的唯一值是“yedu”。
存储类型
TableName 是字符串
RowKey 和 ColumnName 是二进制值(Java 类型 byte[])
Timestamp 是一个 64 位整数(Java 类型 long)
value 是一个字节数组(Java类型 byte[])。
存储结构
可以简单的将HTable的存储结构理解为
即HTable按Row key自动排序,每个Row包含任意数量个Columns,Columns之间按Column key自动排序,每个Column包含任意数量个Values。理解该存储结构将有助于查询结果的迭代。
话说什么情况需要HBase
半结构化或非结构化数据
对于数据结构字段不够确定或杂乱无章很难按一个概念去进行抽取的数据适合用HBase。以上面的例子为例,当业务发展需要存储author的email,phone,address信息时RDBMS需要停机维护,而HBase支持动态增加.
记录非常稀疏
RDBMS的行有多少列是固定的,为null的列浪费了存储空间。而如上文提到的,HBase为null的Column不会被存储,这样既节省了空间又提高了读性能。
多版本数据
如上文提到的根据Row key和Column key定位到的Value可以有任意数量的版本值,因此对于需要存储变动历史记录的数据,用HBase就非常方便了。比如上例中的author的Address是会变动的,业务上一般只需要最新的值,但有时可能需要查询到历史值。
超大数据量
当数据量越来越大,RDBMS数据库撑不住了,就出现了读写分离策略,通过一个Master专门负责写操作,多个Slave负责读操作,服务器成本倍增。随着压力增加,Master撑不住了,这时就要分库了,把关联不大的数据分开部署,一些join查询不能用了,需要借助中间层。随着数据量的进一步增加,一个表的记录越来越大,查询就变得很慢,于是又得搞分表,比如按ID取模分成多个表以减少单个表的记录数。经历过这些事的人都知道过程是多么的折腾。采用HBase就简单了,只需要加机器即可,HBase会自动水平切分扩展,跟Hadoop的无缝集成保障了其数据可靠性(HDFS)和海量数据分析的高性能(MapReduce)。