分组
作用:将相关的元素聚拢到一起,构成一个单元素
例子1:身份证号码是一个长度为15或18个字符的字符串,如果是15位,则全部由数字组成,首位不能为0;如果是18位,则前17位全部是数字,末位可能是数字,也可能是x[插图]
// 方式一: 不够精准:虽然能够匹配到身份证号码,但有些即使不是身份证号码的数据也能匹配
/[1-9]d{13,16}[0-9x]/
// 方式二:子规则:提取前面重复部分
// 明白一点,身份证可以是15位,也可以是18位。如果是18位的话,末尾可能是x,也可能是数字
/[1-9]d{14}(d{2}[0-9x])?/
// 方式三:用或运算符: 将两种情况完全分离
/[1-9]d{14}|[1-9]d{16}[0-9x]/
例子2:使用子表达式匹配开始标签
/<[^/]([^>]*[^/])?/

例子3:根据路径获取模块名、控制器名和方法名(目前只考虑右图的三种可能情况)。名称只能是小写字母

// 感觉直接用字符串分割发给发就可以解决问题。
// 因为模块名和控制器名可能有,可能没有;先匹配模块名
//[a-z]+(/[a-z]+(_[a-z]+)?.php)?/
// 1. 有模块名一定会有,但控制器名可能有一个可能没有,可以将控制器名的正则放在一个分组里,通过 ? 控制它的有无 (/[a-z]+.php)?
// 2. 在控制器的分组中,方法名可以有一个,也可以没有。与上同理: (_[a-z]+)?
例子4:匹配邮箱。E-mail地址以@分隔为两段,之前的是用户名(username),之后的是主机名(hostname),用户名一般只容许出现数字和字母(现在有些邮件服务商也容许用户名中出现点号等字符了,这种情况复杂些,此处不做考虑),而主机名则是类似mail.google.com、mail.163.com之类的字符串。
// 用户名部分:最大长度为64位
[da-zA-Z]{0,64}
// 匹配主机名:由若干个由点分割开的域名字段组成。最后一个域名字段称为顶级域名,必须有;其前面的为子域名,可有可无;域名字段有数字、字母、中横线组成,长度为{1,63}
[-A-Za-z0-9]{1,63}
// 匹配邮箱地址
/[da-zA-Z]{0,64}@[-A-Za-z0-9]{1,63}/
多选
例子1:匹配0-255中间的所有数字: |的优先级在所有正则符中最低
/([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])/
引用分组
分组捕获:括号的作用不仅仅是把有联系的元素归拢起来并分组,它还有其他作用-使用括号之后,正则表达式会保存每个分组真正匹配的文本,等匹配完成之后,可以通过一定的方法引用分组在匹配时捕获的内容
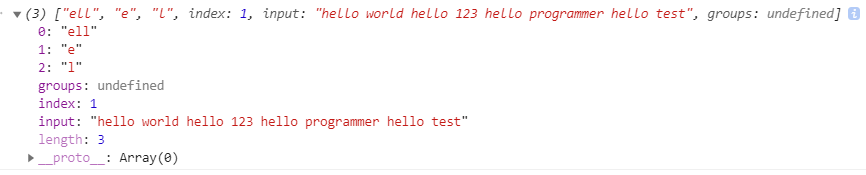
注意:在js中可以通过reg.exec('字符串')的方式可以获取子分组匹配的内容,且返回的是一个包含索引的数组(请看上面右图)。但每次只能匹配一个符合条件的子分组,要想搜索所有的子分组,得用循环。且正则是否全局对搜索方式会有影响。网址
反向引用
引用分组是在正则表达式匹配完成后引用分组的匹配结果。通过反向引用,可以在正则表达式内部引用前面分组的匹配结果,引用方式
um,其中num表示所引用分组的编号(既那个分组是第几个分组)
例子:匹配一个字符串中连续出现的字母,目前只考虑小写字母的字符串

如上图所示:1+表示匹配编号为1的子表达式的匹配结果(是匹配结果,不是匹配规则,既e/d)一次以上。
这个图不知道有什么用
非捕获分组
无论是否需要引用分组匹配的结果,只要出现括号,正则表达式在匹配时就会将子表达式匹配的结果储存起来,提供引用。这样对于那些不需要引用的子表达式就会很耗费空间,如果表达式比较复杂,处理的文本比较多,就会影响正则的性能。 为了解决上面的问题,正则表达式提供了非捕获分组。
非捕获分组就是在开括号后面紧跟一个问好和冒号,像是(?:.....)
var reg = /(d{4})-(d{2})-(d{2})/g
reg.exec('2010-12-22') // 捕获分组的反向引用:长度为4(第一个是字符串本身),每一个分组都能引用
var reg1 = /(?:d{4})-(d{2})-(d{2})/g
reg1.exec('2010-12-22') // 非捕获分组的反向引用:长度为3(第一个是字符串本身),(?:d{4})不能引用,因为没有被保存
var reg2 = /(?:d{4})-(d{2})-(d{2})-2/g
reg2.test('2010-12-22-22') // 在反向引用时,还是通过
um的形式获取前面分组的匹配结果,只不过在计算第几个分组时不包括非捕获分组

总结:为了程序的性能,以后在写不需要引用的分组时,最好使用非捕获分组的形式。
补充
/(w+.?)+/这样的形式是不可以的,捕获分组的个数不能动态变化