相关模块
- xlrd: 读excel表格,新版本仅支持xls格式,久版本可支持xlsx格式
- xlwt:写excel表格,不可修改已存在的excel表格
- xlutils:结合xlrd可实现那修改excel
- xlsxwriter:只支持新建excel向其中写入数据,不支持对已有excel的读取和修改。支持附加图标
- xlwings: 读写excel,并且能够进行单元格格式的修改。
- openpyxl:读写excel,只能处理.xlsx文件
- win32com:读写excel,可实现整个excel文档的复制
- pandas:读写excel
- PyExcelerator(Platform: Win,Unix-like) :读写excel文件,但不可修改已存在excel,常用于写excel
1.xlrd
import xlrd
data = xlrd.open_workbook('abcd.xls') # 打开xls文件
tem_excel = xlrd.open_workbook('日统计.xls', formatting_info=True) #携带格式打开一个文件
table = data.sheets()[0] # 打开第一张表
nrows = table.nrows # 获取表的行数
for i in range(nrows): # 循环逐行打印
if i == 0:# 跳过第一行
continue
print (table.row_values(i)[:13]) # 取前十三列
2.xlwt
import xlwt
wbk = xlwt.Workbook()
sheet = wbk.add_sheet('sheet 1')
sheet.write(0,1,'test text')#第0行第一列写入内容
wbk.save('test.xls')
3.xlutils
https://xlutils.readthedocs.io/en/latest/ (参考文档)
该软件包提供了用于处理excel文件的实用程序的集合。
- xlutils.copy 用于将xlrd.Book对象复制到xlwt.Workbook对象的工具
- xlutils.display 实用程序功能,用于xlrd以用户友好和安全的方式显示有关对象的信息
- xlutils.filter 用于将现有Excel文件拆分和过滤为新Excel文件的微型框架
- xlutils.margins 用于查找多少Excel文件包含有用数据的工具
- xlutils.save 用于将xlrd.Book对象序列化回Excel文件的工具
- xlutils.styles 用于格式化信息的工具表示了Excel文件中的样式
- xlutils.view 易于使用的工作簿工作表中包含的数据视图
xlutils.copy,配合xlrd和xlrt,可修改已存在的excel表格。
from xlrd import open_workbook
from xlutils.copy import copy
rb = open_workbook('balances.xlsx', on_demand=True) #**使用on_demand = True,open_workbook()会占用更少的内存**
rb.sheet_by_index(0).cell(0,1).value
wb = copy(rb) #use xlutils.copy to copy the xlrd.Book object into an xlwt.Workbook object
#Now that you have an xlwt.Workbook, you can modify cells and then save the changed workbook back to a file:
wb.get_sheet(0).write(0,1,'changed!')
wb.save('test.xls') #注:**一定要保存为xls格式,否则会因格式错误导致文件无法打开**
xlutils.display,该模块包含quoted_sheet_name()和 cell_display()功能,可轻松安全地显示所返回的信息xlrd。
4.xlsxwriter
5.xlwings
xlwings可以和matplotlib、numpy以及pandas无缝连接,支持读写numpy、pandas数据类型,将matplotlib可视化图表导入到excel中。
官方文档:http://docs.xlwings.org/zh_CN/latest/
Here are the last versions of xlwings to support:
Python 3.5: 0.19.5
Python 2.7: 0.16.6
基本操作:
import xlwings as xw
import pandas as pd
import matplotlib.pyplot as plt
#与工作簿建立连接
#wb = xw.Book() # this will create a new workbook
wb = xw.Book('balances.xlsx') # connect to a file that is open or in the current working directory
#wb = xw.Book(r'C:path ofile.xlsx') # on Windows: use raw strings to escape backslashes
sht = wb.sheets['sheet'] #初始化工作表(sheet)对象
#如查找的工作表不存在,则会报错 com_error: (-2147352567, '发生意外。', (0, None, None, None, 0, -2147352565), None)
#读写数据
sht.range('A1').value = 'Foo 1'
print(sht.range('A1').value)
#区域扩展
sht.range('A1').value = [['Foo 1', 'Foo 2', 'Foo 3'], [10.0, 20.0, 30.0]]
print(sht.range('A1').expand().value)
#强大的转换器 能够处理大多数数据类型的双向转换,包括Numpy arrays和Pandas DataFrames
df = pd.DataFrame([[1,2], [3,4]], columns=['a', 'b'])
sht.range('A1').value = df
print(sht.range('A1').options(pd.DataFrame, expand='table').value)
#Matplotlib 图表可以作为图片放在Excel中展示
fig = plt.figure()
plt.plot([1, 2, 3, 4, 5])
sht.pictures.add(fig, name='MyPlot', update=True)

与工作簿建立连接:
xw.Book 提供了连接到工作簿的最简单的方法: 它在所有的app实例中查找指定的工作簿,如果同一个工作簿在多个app实例中存在,就会返回一个错误信息。 连接活动app实例中的工作簿用 xw.books ,连接指定app实例中的工作簿用:
6.openpyxl
https://openpyxl.readthedocs.io/en/stable/ (参考文档)
创建工作表
from openpyxl import Workbook
#Create a workbook
wb = Workbook() #获取工作簿
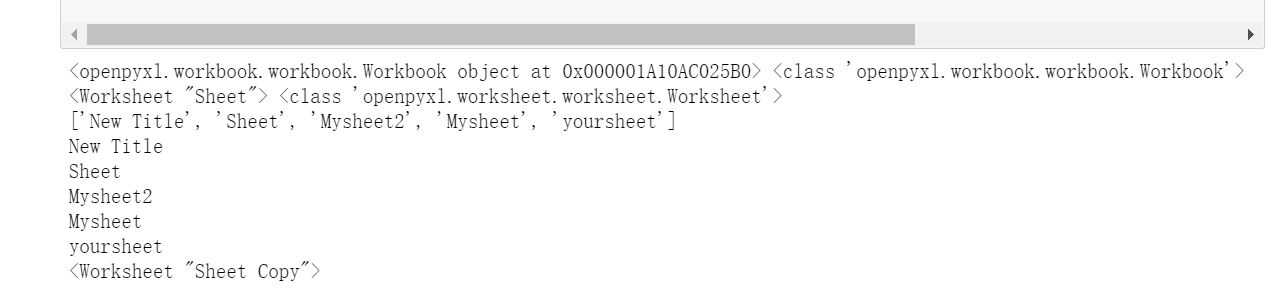
print(wb,type(wb))
ws = wb.active #获取工作表,该方法默认参数是0,总是得到第一个工作表.(获取工作簿时默认会有一个名为sheet的工作表)
print(ws,type(ws))
ws1 = wb.create_sheet("Mysheet") # insert at the end (default)
ws2 = wb.create_sheet("Mysheet", 0) # insert at first position
ws3 = wb.create_sheet("Mysheet", -1) # insert at the penultimate position
ws4 = wb.create_sheet("yoursheet") # insert at the penultimate position
ws2.title = "New Title" #修改工作表名,Sheets are given a name automatically when they are created. They are numbered in sequence (Sheet, Sheet1, Sheet2, …)
ws5 = wb["New Title"] #给工作表命名后,就可以将其作为工作簿的键,获取该工作表
print(wb.sheetnames) #查看工作簿中所有工作表的名称
for sheet in wb: #遍历工作簿
print(sheet.title)
target = wb.copy_worksheet(ws) #在单个工作簿中创建工作表的副本,注意不能在工作簿之间复制工作表。如果工作簿以只读或仅写 模式打开,则不能复制工作表
#Copy an existing worksheet in the current workbook
#.. warning::
# This function cannot copy worksheets between workbooks.
# worksheets can only be copied within the workbook that they belong
print(target)
运行结果
操作数据
from openpyxl import Workbook
#Create a workbook
wb = Workbook() #获取工作簿
ws = wb.active #获取工作表
**#访问一个单元格**
c = ws['A4'] #单元格可以直接作为工作表的键进行访问,返回A4处的单元格,如果尚未存在则创建一个
print(c,type(c))
ws['A4'] = 4 #可以直接配置值
d = ws.cell(row=4, column=2, value=10) #使用行和列表示法访问单元格
#注:在内存中创建工作表时,它不包含任何单元格。它们是在首次访问时创建的。
**#访问多个单元格**
cell_range = ws['A1':'C2'] #使用切片访问单元格范围,返回一个嵌套元组
print(11,cell_range)
colC = ws['C']
print(22,colC)
col_range = ws['C:D']
row10 = ws[10] #返回第10行的数据,得到一个包含各单元格对象的元组
print(33,row10)
row_range = ws[5:10] #返回5-10行的单元格对象
print(44,row_range)
#也可以使用Worksheet.iter_rows()方法,同样,该Worksheet.iter_cols()方法将返回列,但出于性能原因,该Worksheet.iter_cols()方法在只读模式下不可用。
for row in ws.iter_rows(min_row=1, max_col=3, max_row=2):
for cell in row:
print(cell)
#如果需要遍历文件的所有行或列,则可以使用以下 Worksheet.rows属性或Worksheet.columns属性,该Worksheet.columns属性在只读模式下不可用。
tuple(ws.rows)

仅值
from openpyxl import Workbook
#Create a workbook
wb = Workbook() #获取工作簿
ws = wb.active #获取工作表,该方法默认参数是0,总是得到第一个工作表.(获取工作簿时默认会有一个名为sheet的工作表)
n = 1
for x in range(1,4):
for y in range(1,4):
ws.cell(row=x, column=y,value=n)
n += 1
for row in ws.values: #Worksheet.values属性,仅返回单元格值
for value in row:
print(value)
for row in ws.iter_rows(min_row=1, max_col=3, max_row=2, values_only=True):
#values_only参数,只返回单元格的值
print(row)

数据存储
一旦有了Cell,我们可以为其分配一个值
from openpyxl import Workbook
#Create a workbook
wb = Workbook() #获取工作簿
ws = wb.active #获取工作表,该方法默认参数是0,总是得到第一个工作表.(获取工作簿时默认会有一个名为sheet的工作表)
n = 1
for row in ws.iter_rows(min_row=1, max_col=3, max_row=2):
for cell in row:
cell.value = n #为cell分配值
n = n + 2
for row in ws.values:
for value in row:
print(value)
wb.save('balances.xlsx') #保存到文件,操作将覆盖现有文件,而不会发出警告

从文件加载
使用openpyxl.load_workbook()打开现有的工作簿
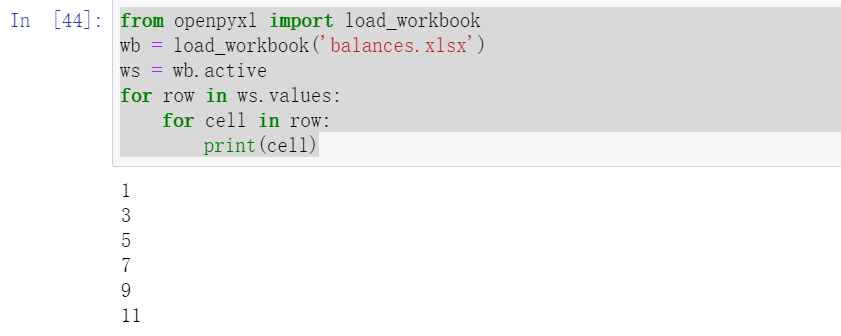
from openpyxl import load_workbook
wb = load_workbook('balances.xlsx')
ws = wb.active
for row in ws.values:
for cell in row:
print(cell)
简单使用
- 写工作簿
from openpyxl import Workbook
from openpyxl.utils import get_column_letter
wb = Workbook()
dest = 'empty_book.xlsx'
ws1 = wb.active
ws1.title = 'range names'
for row in range(1,10):
ws1.append(range(8))
ws2 = wb.create_sheet(title='pi')
ws2['F2'] = 3.14
ws3 = wb.create_sheet(title='data')
for row in range(10,20):
for col in range(27,32):
_ = ws3.cell(column=col, row=row, value="{0}".format(get_column_letter(col)))
wb.save(filename=dest)
- 阅读现有工作簿
from openpyxl import load_workbook
wb = load_workbook(filename = 'empty_book.xlsx')
sheet_ranges = wb['range names']
print(sheet_ranges['D6'].value)
注:在load_workbook中可以使用几个标志。data_only控制具有公式的单元格是否具有公式(默认值)或Excel上次读取工作表时存储的值。keep_vba控制是否保留任何Visual Basic元素(默认)。如果保留它们,则它们仍不可编辑。
*使用数字格式
import datetime
from openpyxl import Workbook
wb = Workbook()
ws = wb.active
# set date using a Python datetime
ws['A1'] = datetime.datetime(2010, 7, 21)
ws['A1'].number_format

*使用公式
from openpyxl import load_workbook
ws = wb.active
# add a simple formula
ws["A1"] = "=SUM(1, 1)"
wb.save("empty_book.xlsx")
*只读模式(用于大量读取数据)
from openpyxl import load_workbook
wb = load_workbook(filename='large_file.xlsx', read_only=True)
ws = wb['big_data']
for row in ws.rows:
for cell in row:
print(cell.value)
# Close the workbook after reading
wb.close()
*只写模式(用于大量写入数据)
要转储大量数据时,需确保已安装lxml
from openpyxl import Workbook
wb = Workbook(write_only=True)
ws = wb.create_sheet()
# now we'll fill it with 100 rows x 200 columns
for irow in range(100):
ws.append(['%d' % i for i in range(200)])
# save the file
wb.save('new_big_file.xlsx') # doctest: +SKI
插入和删除行
from openpyxl import load_workbook
#openpyxl.worksheet.worksheet.Worksheet.insert_rows()
#openpyxl.worksheet.worksheet.Worksheet.insert_cols()
#openpyxl.worksheet.worksheet.Worksheet.delete_rows()
#openpyxl.worksheet.worksheet.Worksheet.delete_cols()
wb = load_workbook(filename = 'empty_book.xlsx')
ws = wb.active
ws.insert_rows(7) #插入空行
ws.delete_cols(6, 3) #删除行
wb.save('empty_book.xlsx')
移动范围
ws.move_range("D4:F10", rows=-1, cols=2) #将范围内的单元格D4:F10向上移动一列,向右移动两列。单元将覆盖任何现有单元。
7.win32com
pywin32直接包装了几乎所有的Windows API,可以方便地从Python直接调用。
https://github.com/mhammond/pywin32 (源码)
http://www.yfvb.com/help/win32sdk/ (win32中文参考手册)
https://docs.microsoft.com/en-us/search/ (win32英文参考手册)
https://github.com/wuxc/pywin32doc/blob/master/PyWin32.chm (pywin32文档)
安装pywin32后,在lib的site-packages下面的win32目录下,有一个demos。
安装
python -m pip install pywin32 -i https://pypi.tuna.tsinghua.edu.cn/simple
from win32com.client import Dispatch
import win32com.client
8.pandas
https://www.pypandas.cn/ (pandas中文网)推荐
https://pandas.pydata.org/pandas-docs/stable/ (参考文档)推荐
pandas利器:
- DataFrame是Pandas中的一个表格型的数据结构,包含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型等),DataFrame即有行索引也有列索引,可以被看做是由Series组成的字典。
- Series是一种类似于一维数组的对象,是由一组数据以及一组与之像相关的数据标签(即索引)组成,仅由一组数据也可以产生简单的Series对象。
该模块处理excel时依赖xlrd和openpyxl模块,需提前安装好
import pandas as pd
#导入数据
df = pd.read_excel('balances.xlsx') #方式一:直接读取,默认读取到这个Excel的第一个表单,参数可选(io[, sheet_name, header, names, …])
#df = pd.ExcelFile.parse('sheet') #方式二:根据sheet索引
#pandas操作Excel的行列
data=df.head()#默认读取前5行的数据,得到一个二位矩阵
print(data,type(data))
#获取所有数据
data1=df.values#
print(data1,type(data1))
#读取指定的单行,数据会存在列表里面
data=df.iloc[0].values #0表示第一行 这里读取数据并不包含表头
print("第一行数据:
{0}".format(data))
#读取指定的多行,数据会存在嵌套的列表里面
data=df.iloc[[1,2]].values #读取指定多行的话,就要在iloc[]里面嵌套列表指定行数
print("读取指定行的数据:
{0}".format(data))
#读取指定的行列
data=df.iloc[1,2] #读取第一行第二列的值,这里不需要嵌套列表
print("读取指定行的数据:
{0}".format(data))
#读取指定的多行多列值
data=df.iloc[[1,2],[True,False,False]].values#读取第一行第二行的title以及data列的值,这里需要嵌套列表
print("读取多行多列值:
{0}".format(data))
#读取所有行的指定列
data=df.iloc[:,0:2].values#读所有行前3列的值,这里需要嵌套列表
print("读取所有行指定列的数据:
{0}".format(data))
#获取行号并打印输出
print("输出行号列表",df.index.values)
#获取列名并打印输出
print("输出列标题",df.columns.values)
#获取指定行的值
print("输出值",df.sample(3).values)#这个方法类似于head()方法以及df.values方法
#获取指定列的值
print("输出值
",df['data'].values)
#导出数据
df.to_excel('out.xlsx',sheet_name='sheet1',index=True) #方法一
writer = pd.ExcelWriter('out.xlsx') #方法二,同时需要在多个工作表中写入时使用
df.to_excel(writer,sheet_name='sheet2',index=True)
df.to_excel(writer,sheet_name='sheet3',index=True)
writer.save()
9.PyExcelerator
安装
https://sourceforge.net/projects/pyexcelerator/
使用方法:
http://blog.donews.com/limodou/a460033.aspxrchive/2005/07/09/460033.aspx
拓展
https://www.cnblogs.com/yangguanghuayu/p/11778595.html (xlrd和xlwt)
https://www.cnblogs.com/zhang-can/p/7652702.html (xlrd和xlwt)
https://blog.csdn.net/weixin_40612082/article/details/89710773 (xlrd和xlwt,字体边框格式相关)
https://blog.csdn.net/qq404766692/article/details/8365542(win32com和PyExcelerator使用)
https://www.cnblogs.com/wanglle/p/11455758.html (openpyxl)
https://blog.csdn.net/qq_42067550/article/details/105466112 (xlutils模块无法拷贝)
https://www.zhihu.com/tardis/sogou/art/54847656 (win32com复制整个excel表格)
https://blog.csdn.net/peiwang245/article/details/100544691 (win32com详细用法)
https://www.py.cn/jishu/jichu/12879.html (基本语法)
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple gevent (pip镜像)
Linux下,修改 ~/.pip/pip.conf (没有就创建一个), 修改 index-url至tuna,内容如下:
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
windows下,直接在user目录中创建一个pip目录,如:C:Usersxxpip,新建文件pip.ini,内容如下:
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
d:python3.5python.exe -m pip install --upgrade pip