
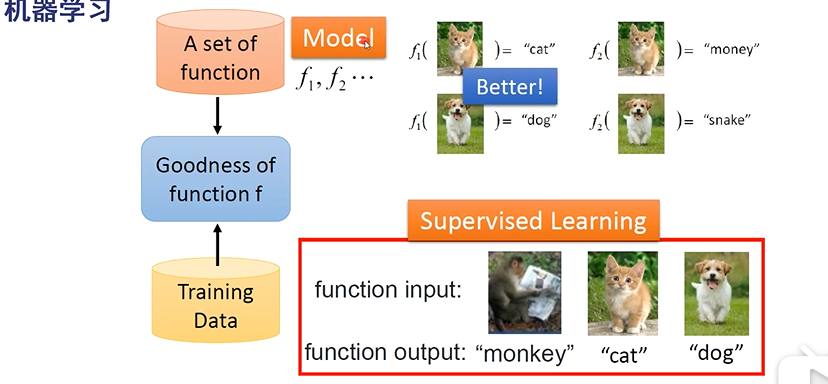

监督学习:标注数据
半监督学习:标注数据和未标注数据
无监督学习:未标注学习
监督学习的性能最可靠,用于企业

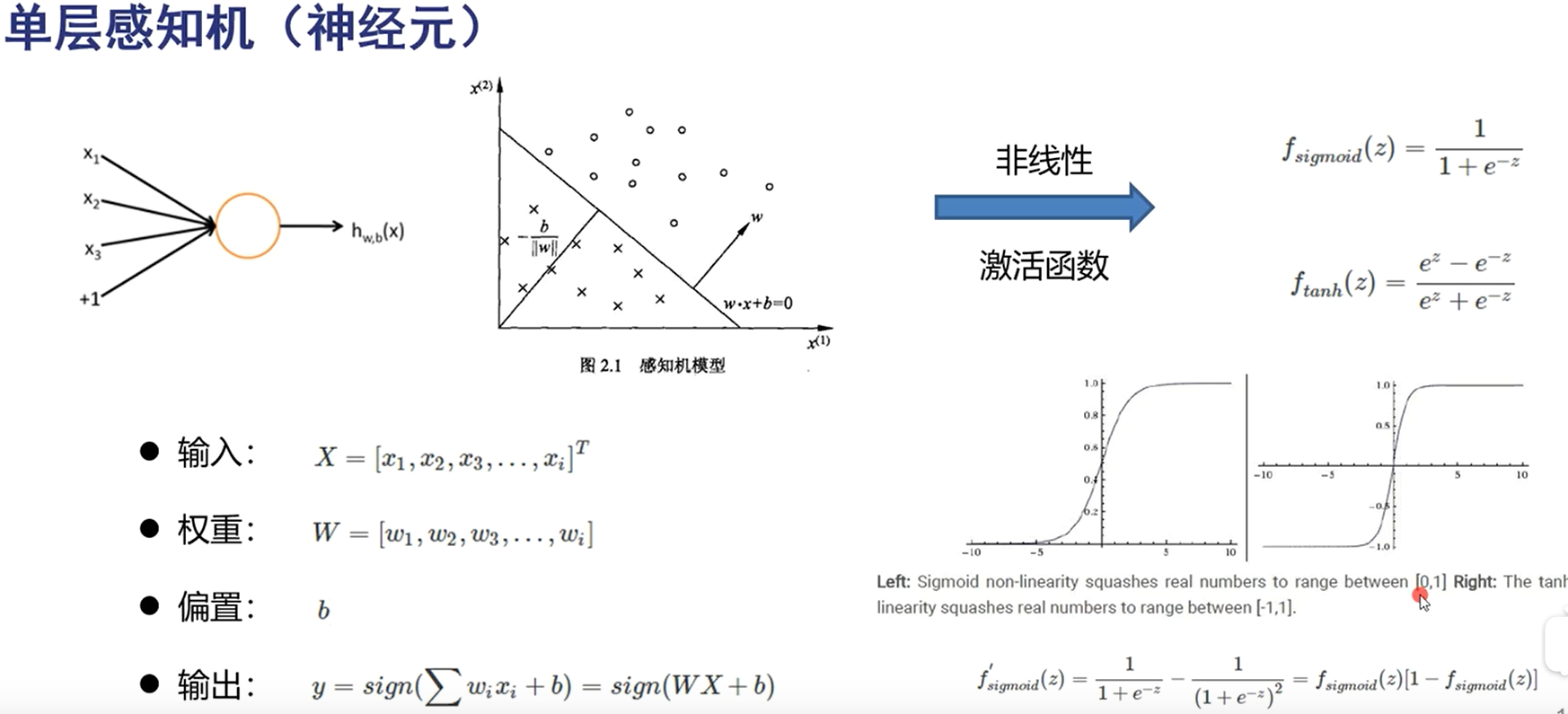


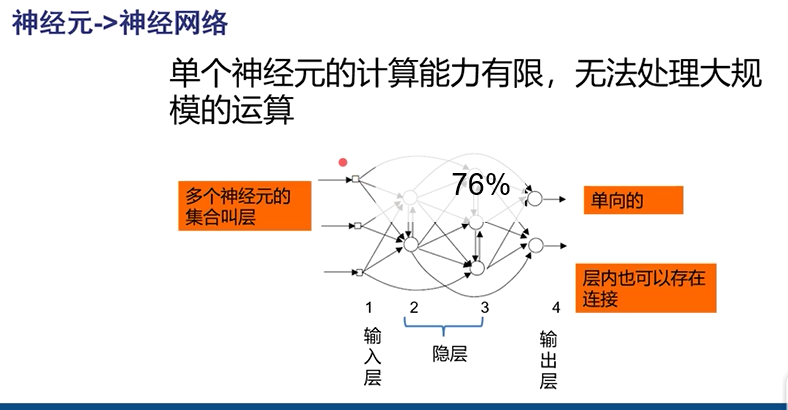
通常层间神经元不相通
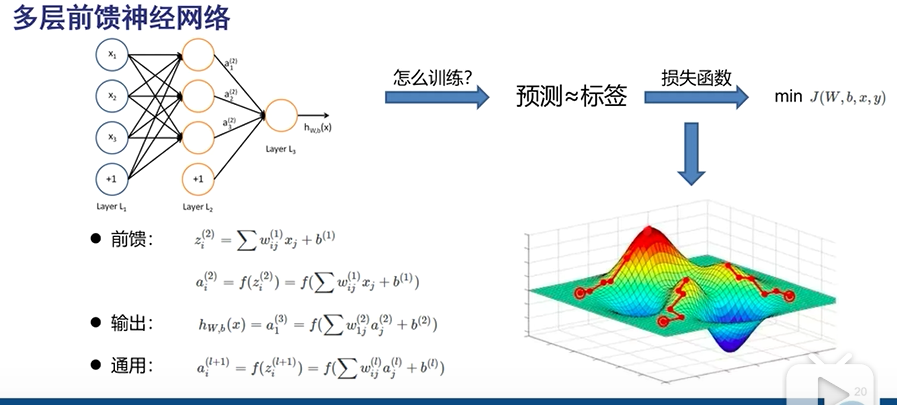
损失函数:每次都找下山最快的方向(梯度下降法)依赖于网络初始值
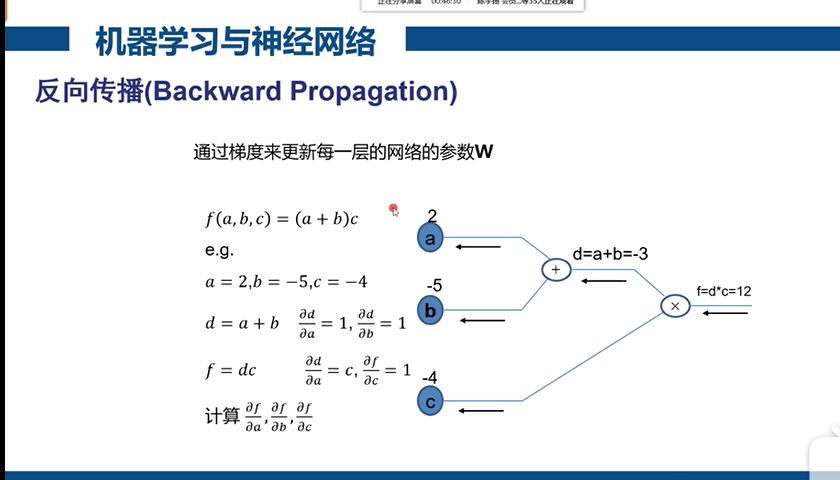
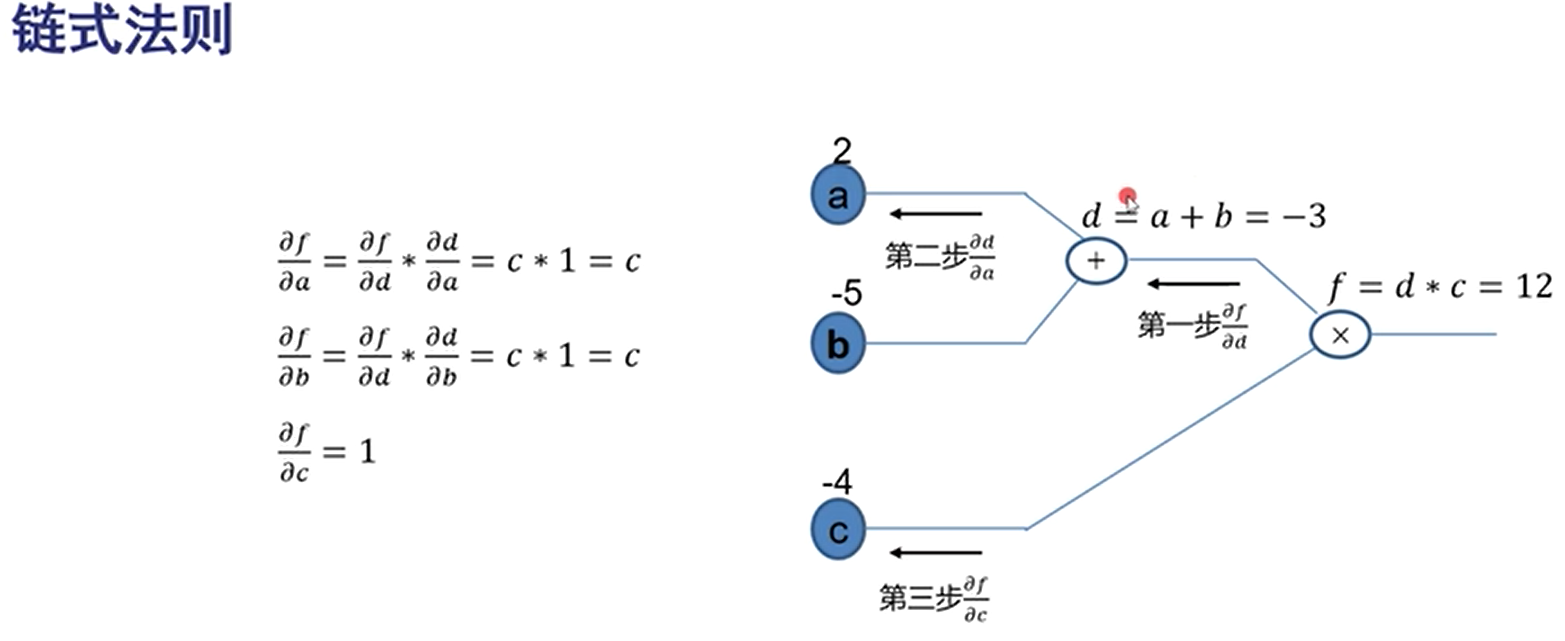

神经网络的缺点: 局部最优:下山不一定到最低点 梯度弥散:如:1 0.5 0.25 0.125(接近0)梯度为0时网络更新不动了。层数过多,梯度越来越小 参数量呈现指数级增加 尤其后两种,会造成层数过多无法训练

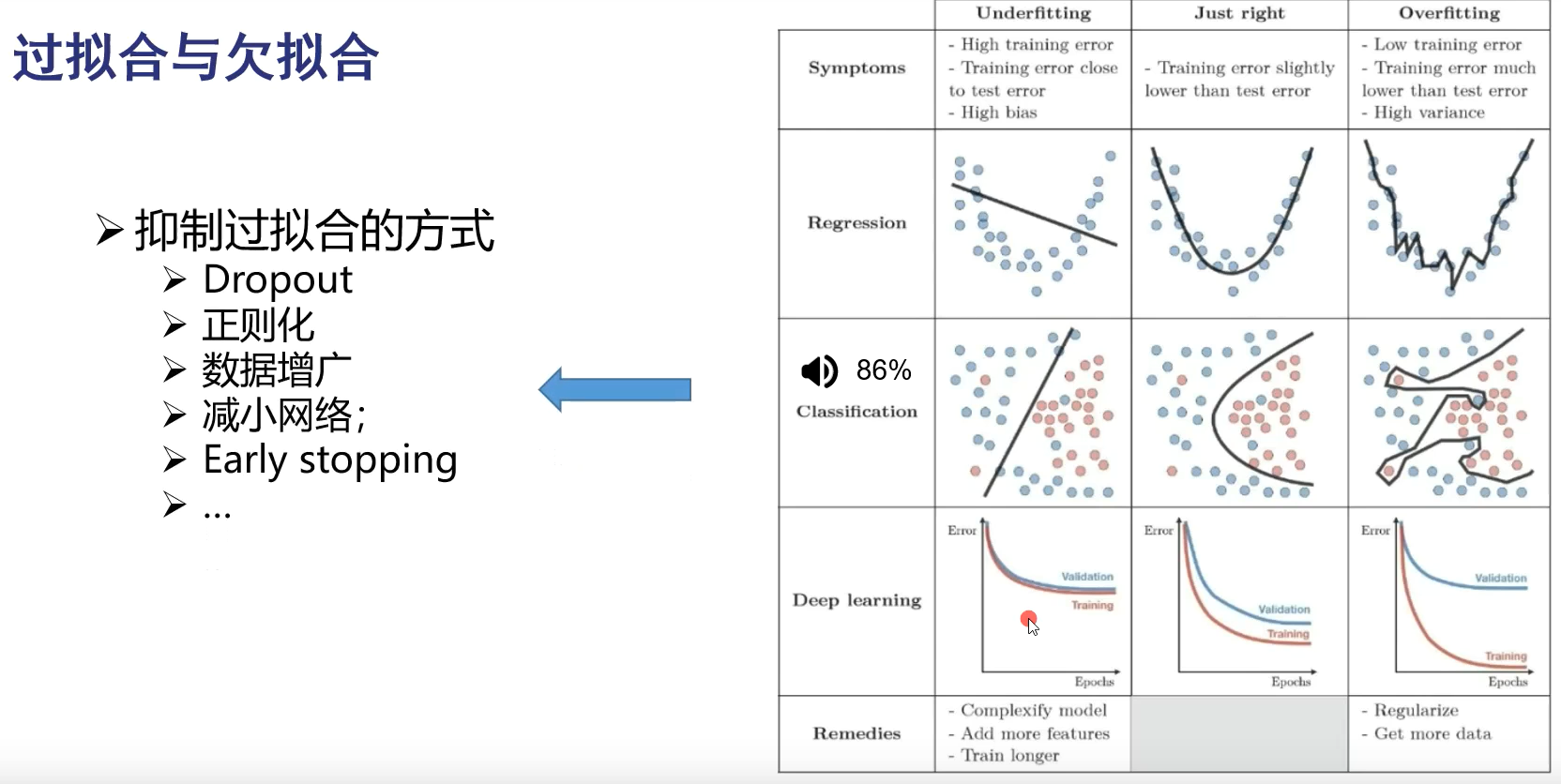
欠拟合:模型不够复杂,把模型的参数量增加或训练时间更长一些。
Dropout:每次更新网络时,随机不更新一部分神经元,防止把答案记住
正则化:对模型复杂度进行约束,不要太复杂
数据增广:把一个数据变为多个,一张图变为多个。增加训练数据量
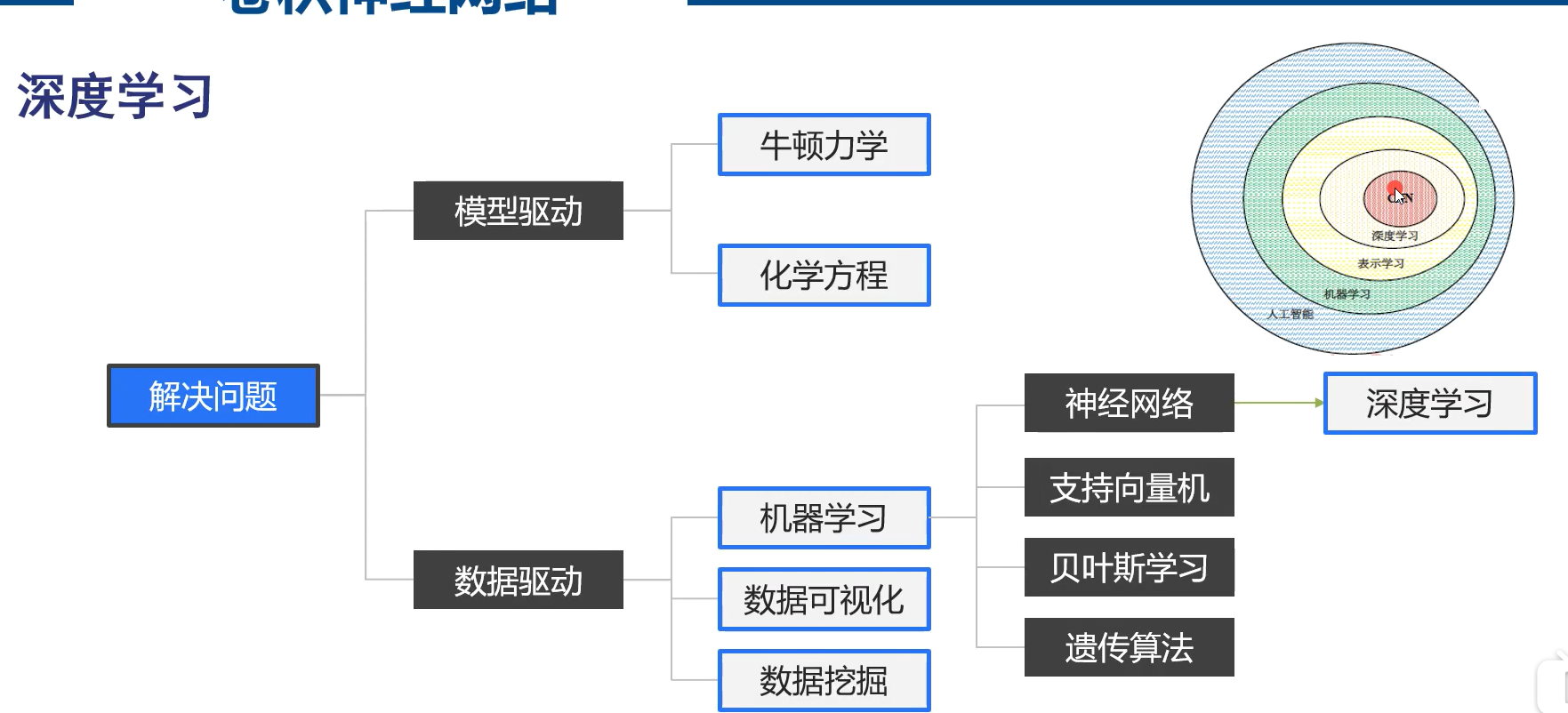
深度学习
为什么要深度?层数越多,表达能力越强
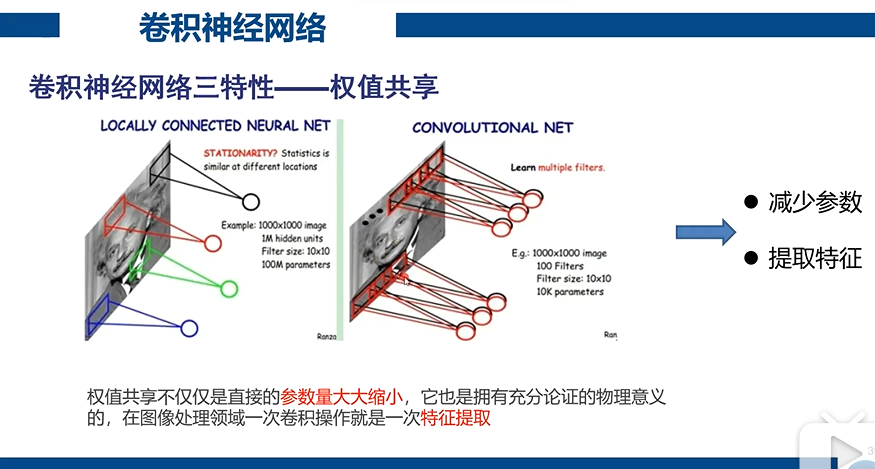
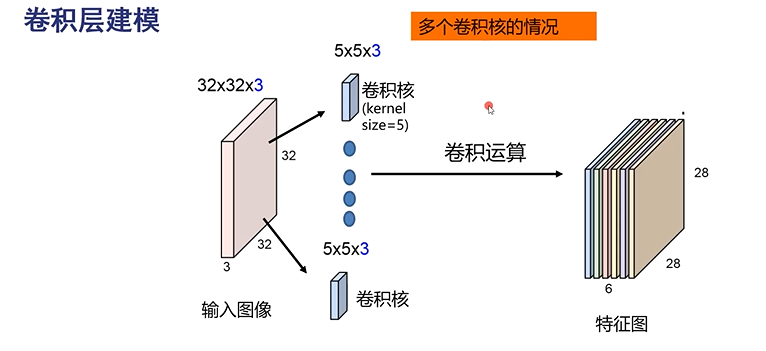
卷积是对特征的提取


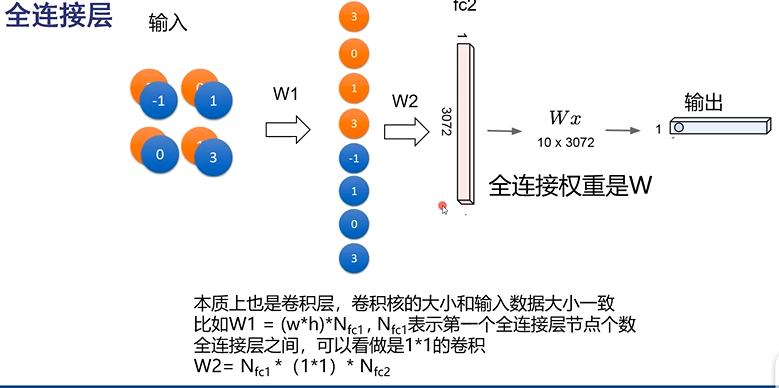
全连接数据量太大,不长远
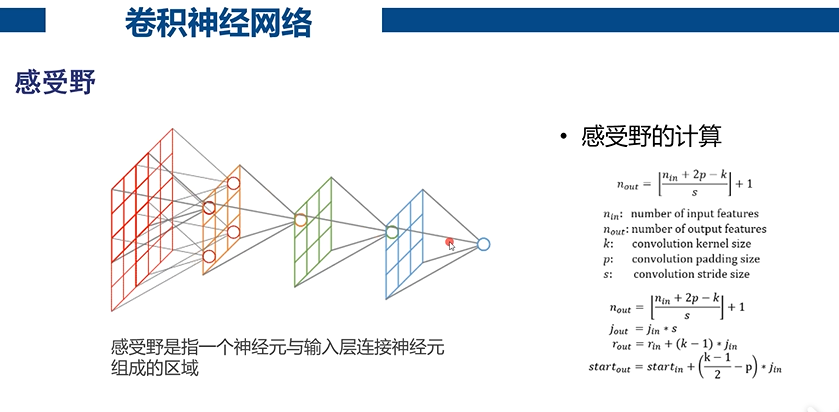
感受野:一个神经元所关注的区域,
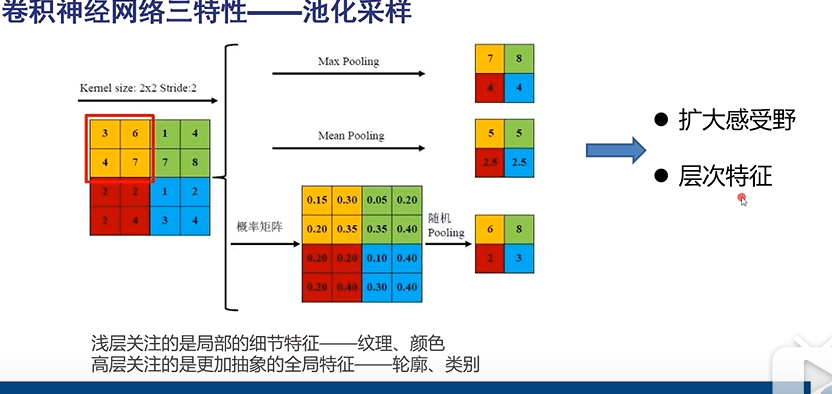
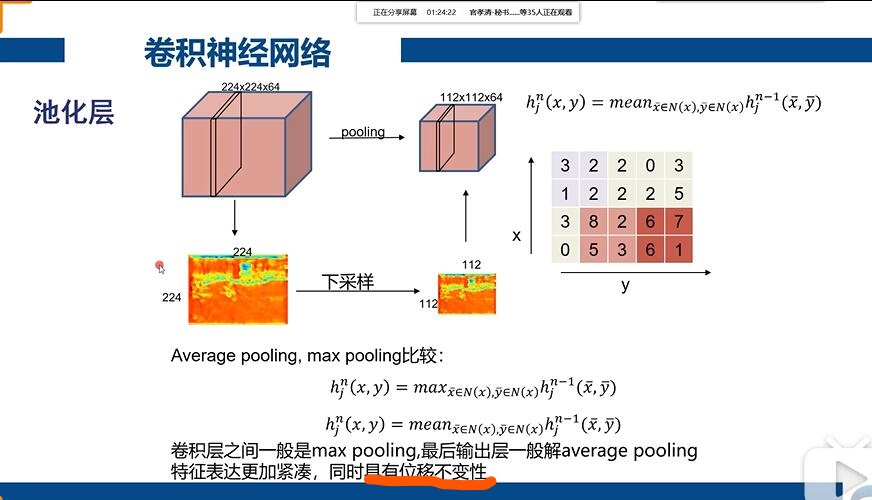
Max Pooling :只取该区域的最大值作为区域的值
Mean Pooling :平均池化,对该区域取平均值作为区域的值
这两个比较常用




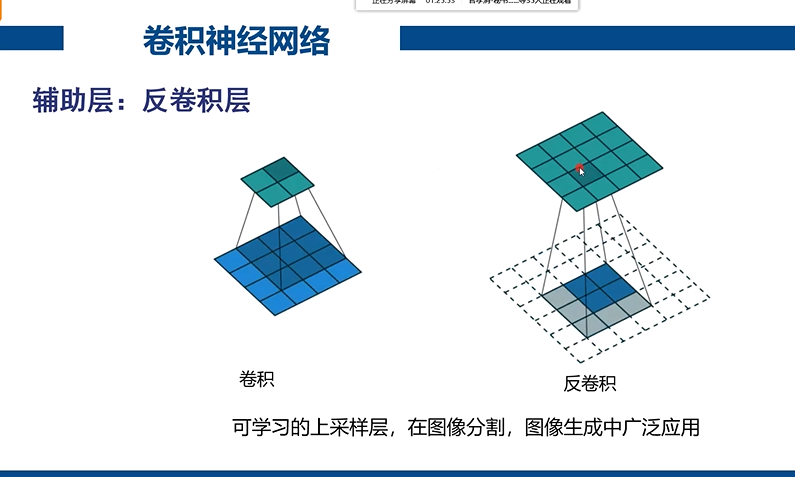
反卷积变大

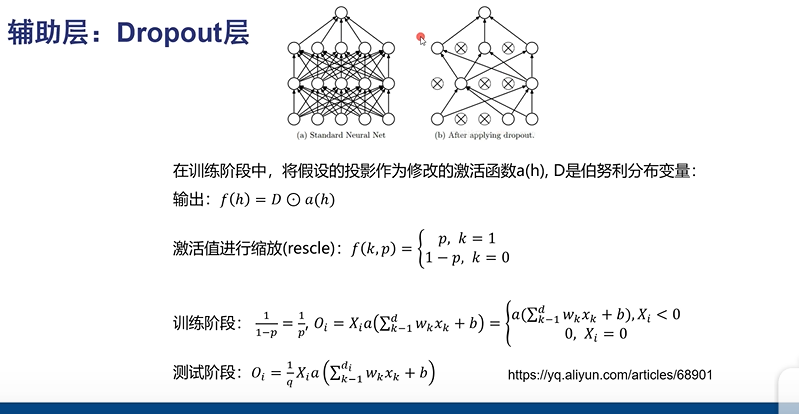
随机让一部分神经元坏死,产生误差,由于每次都随机,那么最后所有神经元都能被更新
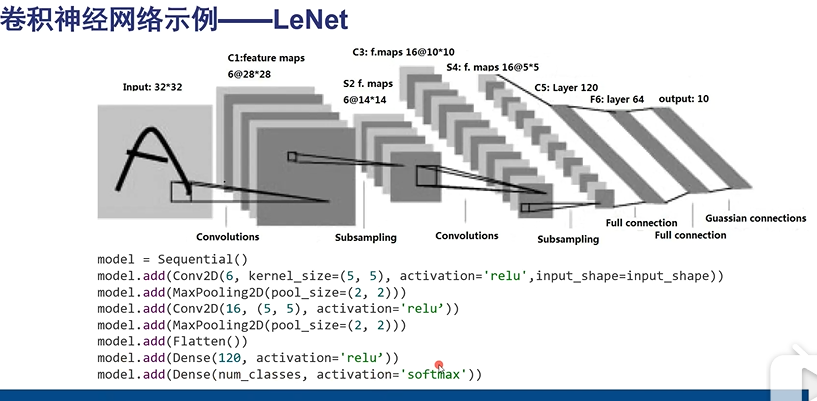
Flatten :展平
Dense:全连接
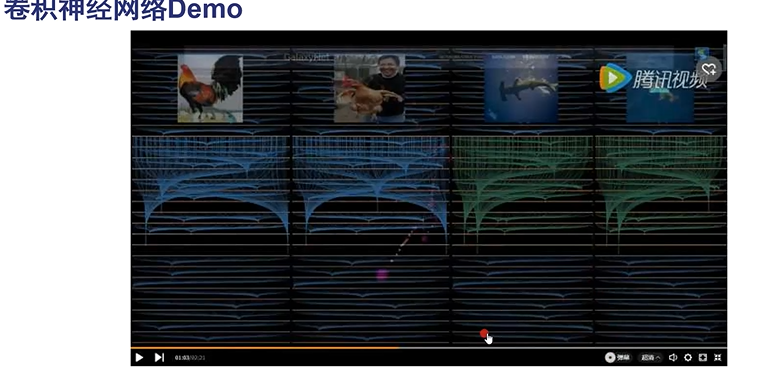
越到高层越一致(稀疏)

深度学习框架
Keras 适合新手,Caffe 工业性能高
Pytorch 科研,灵活
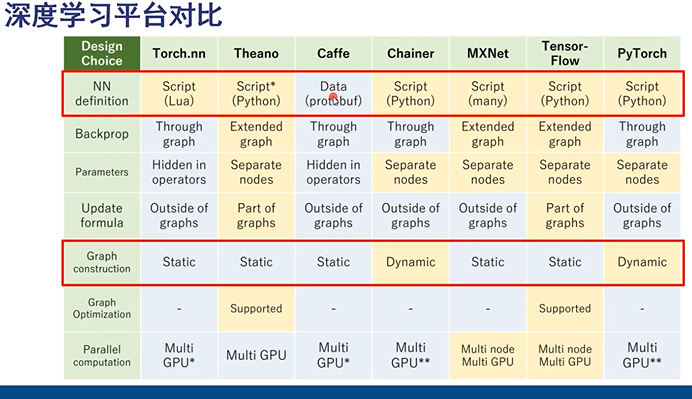
Static :运行流程定义好的,一般是一个输入进去,一个输出出来。 不知道中间的运算过程。但是稳定,适合做产品
Dynamic :运行中每一步都可随时暂停,都是动态的。出现问题每步都可以调试,适合科研
