
这里我要强调一下什么叫做异常,机器到底要看到什么就是Anormaly。其实是取决你提供给机器什么样的训练数据
应用


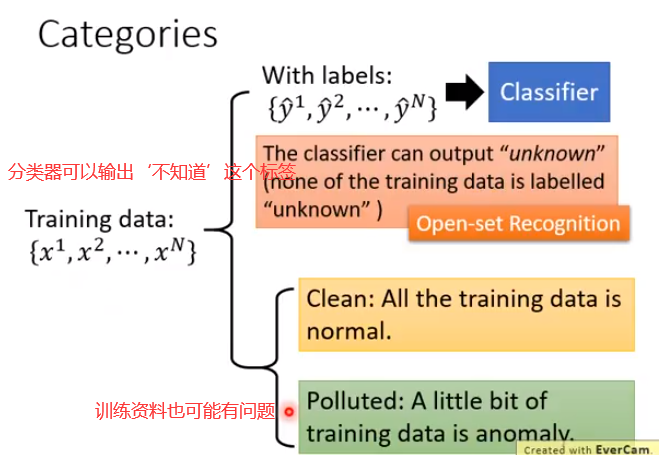
1.若你有一个classifier,你希望这个classifier具有:看到不知道的数据会标上这是未知物的能力,这算是异常侦测的其中一种,又叫做Open-set Recognition
2.训练资料已经被混杂了一些异常的资料
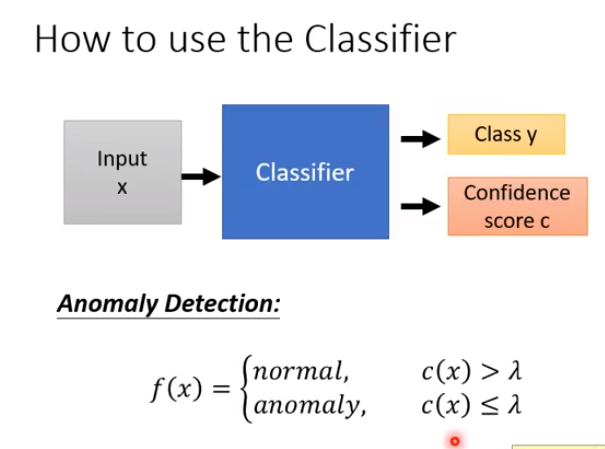
用classifier 的confidence score c 进行anomoly detection
分类器的输出是一个几率分布(distribution)若输出特别平均,那这张图片就是异常的图片
根据信心分数来进行异常检测不是唯一的方法,因为输出的是distribution,那么就可以计算交叉熵(entropy)。
交叉熵(entropy)越大就代表输出越平均,代表机器没有办法去肯定输出的图片是哪个类别,表示输出的信心分数是比较低。

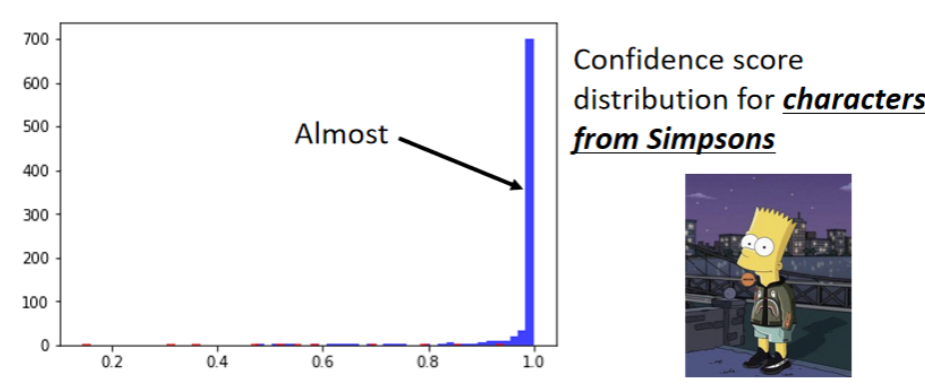
辛普森家庭成员的分类器
我们可以发现,如果输入的是辛普森家庭的人物,分类器输出比较高信心分数。如果输入不是辛普森家庭的任务,分类器输出的信心分数是比较低。但是输入凉宫春日的图片,分类器输出柯阿三的信心分数为0.99。
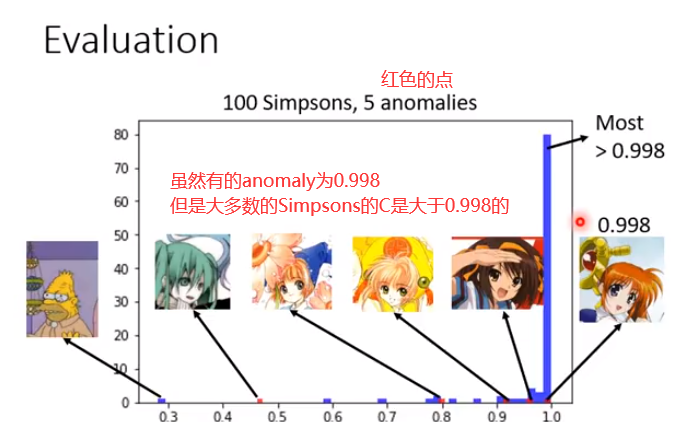
若输入大量的训练资料(将之前的介绍辛普森家庭的那张投影片中的kaggle链接中的数据作为训练资料(有数千张辛普森家庭人物))输入至分类器中,输出的信息分数分布如图所示。
几乎所有的辛普家庭的人物输入分类器中,无论是否辨识有错都会给出一个较高的信心分数。但还是发现若辨识若有错误会得到较低的信心分数,如图所示的红色点就是辨识错误图片的信心分数的分布。
蓝色区域分布相较于红色区域集中在1.0,有很高的信心分数认为是辛普森家庭的人物。

若输入其它动画的人物图片(15000张图片),其分类器输出的信心分数如题所示,我们会发现有10分之一图片的信心分数比较高(不是辛普森家庭的人物,但给了比较高的分数),
多数的图片得到的信心分数比较低(辛普森家庭的人物和不是辛普森家庭的人物在分类器输出的信息分数是有所差别的)。
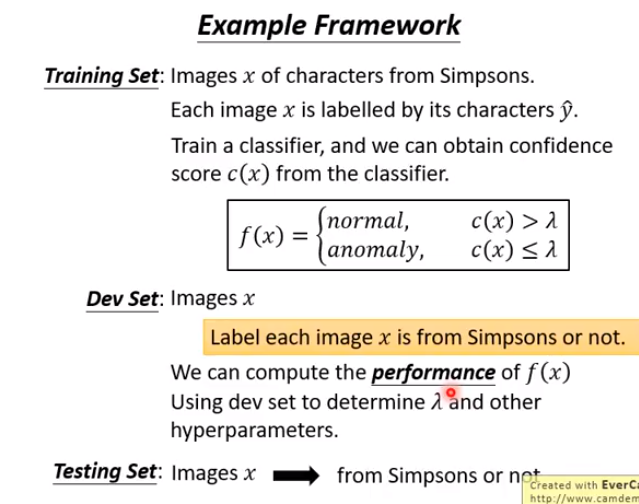
你能够在Dev Set衡量一个异常侦测系统的结果表现以后,你就可以拿来调整阀值(threshold),可以找出让最好的阀值(threshold)

我们知道异常侦测其实是一个二元分类(binary classification)的问题。在二元分类中我们都是用正确率来衡量一个系统的好坏,
但是在异常侦测中正确率并不是一个好的评估系统的指标。你可能会发现一个系统很可能有很高的正确率,但其实这个系统什么事都没有做。
为什么这样呢?因为在异常侦测的问题中正常的数据和异常的数据之间的比例是非常悬殊的

不同的方式来衡量异常检测系统的好坏

.Detected :认为是错的
左侧的图:(不正常的情况):在Anomaly里面,只有一个被识别出是异常.在Normal里面,有一个被识别为异常
Cost Table A:
异常的没被识别到扣1分
正常的被识别为异常扣100分
Cost Table B:
异常的没被识别到扣100分
正常的被识别为异常扣1分
不同的Cost表用在不同的情况,如医院检查癌症
用B好(没有癌症却被检查出癌症问题不大,但是有癌症却被告之没病问题很大)
可能遇到的问题

如果我们直接用一个分类器来侦测输入的资料是不是异常的,当然这并不是一种很弱的方法,但是有时候无法给你一个perfect的结果,我们用这个图来说明用classifier做异常侦测时有可能会遇到的问题。
假设现在做一个猫和狗的分类器,将属于的一类放在一边,属于狗的一类放在一边。若输入一笔资料即没有猫的特征也没有狗的特征(草泥马,马莱貘),机器不知道该放在哪一边,就可能放在这个boundary上,
得到的信息分数就比较低,你就知道这些资料是异常的。
你有可能会遇到这样的状况:有些资料会比猫更像猫(老虎),比狗还像狗(狼)。机器在判断猫和狗时是抓一些猫的特征跟狗的特征,也许老虎在猫的特征上会更强烈,狼在狗的特征上会更强烈。
对于机器来说虽然有些资料在训练时没有看过(异常),但是它有非常强的特征会给分类器很大的信心看到某一种类别。

在解决这个问题之前我想说辛普森家庭人物脸都是黄的,如果用侦测辛普森家庭人物的classifier进行侦测时,会不会看到黄脸的人信心分数会不会暴增呢?
所以将三玖的脸涂黄,结果侦测为是宅神,信心分数为0.82;若再将其头发涂黄,结果侦测为丽莎,信心分数为1.00。若将我的脸涂黄,结果侦测为丽莎,信心分数为0.88。

当然有些方法可以解这个问题,其中的一个解决方法是:假设我们可以收集到一些异常的资料,我们可以教机器看到正常资料时不要只学会分类这件事情,要学会一边做分类一边看到正常的资料信心分数就高,
看到异常的资料就要给出低的信心分数。
但是会遇到的问题是:很多时候不容易收集到异常的数据。有人就想出了一个神奇的解决方法就是:既然收集不到异常的资料,那我们就通过Generative Model来生成异常的资料。
这样你可能遇到的问题是:生成的资料太像正常的资料,那这样就不是我们所需要的。所以还要做一些特别的constraint,让生成的资料有点像正常的资料,但是又跟正常的资料又没有很像。
接下来就可以使用上面的方法来训练你的classifier。
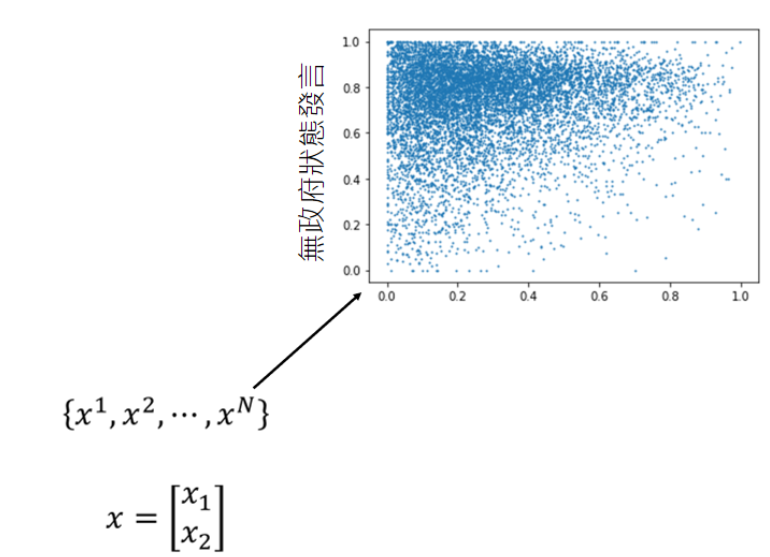
接下来我们再讲第二个例子,在第二个例子中我们没有classifier,我们只能够收集到一些资料,但没有这些资料的label
我们现在只有大量的训练资料,但是没有label。我们刚才可以根据分类器的conference来判断是不是异常的资料,我们在没有classifier的情况下可以建立一个模型,
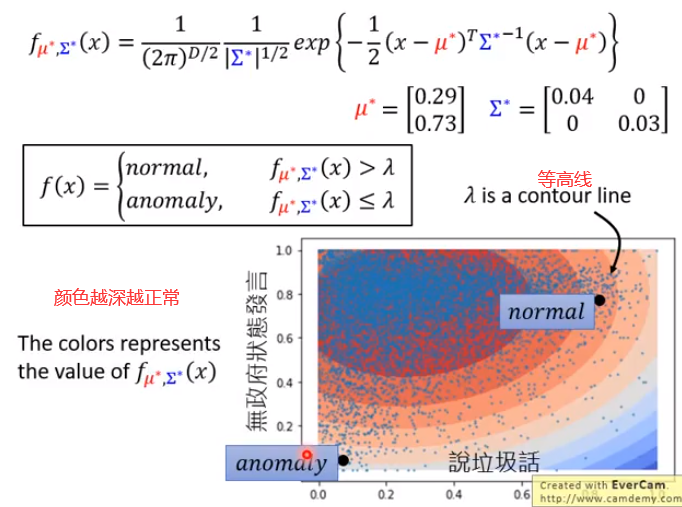
这个模型是告诉我们P(x)的几率有多大。(根据这些训练资料,我们可以找出一个几率模型,这个模型可以告诉我们某一种行为发生的概率多大)。
如果有一个玩家的几率大于某一个阀值(threshold),我们就说他是正常的;如果几率小于某一个阀值(threshold),我们就说他是异常的。
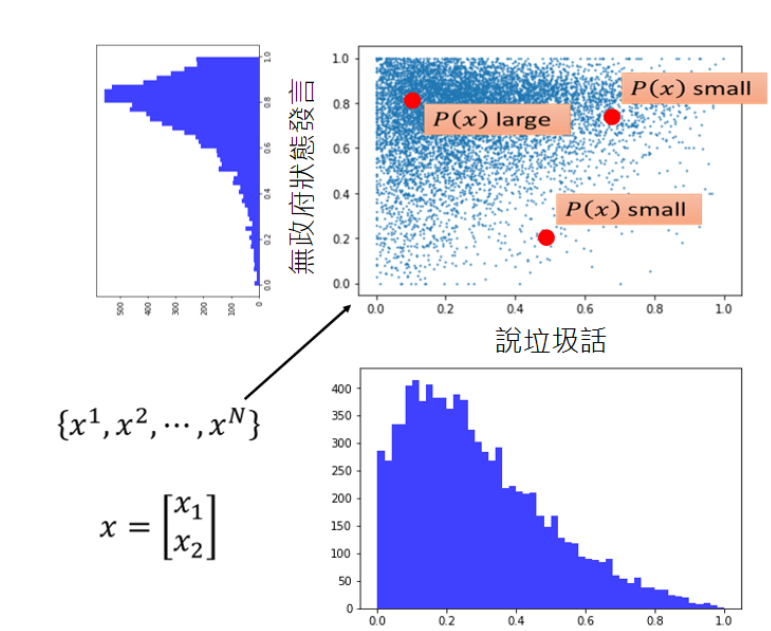
我们还没有讲任何的几率模型,从这个图上可以很直觉的看出一个玩家落在说垃圾的话几率低,通常在无政府状态下发言,这个玩家有可能是一个正常的玩家。
假设有玩家落在有五成左右的几率说垃圾话,二成的几率在无政府状态下发言;或者落在有七成左右的几率说垃圾话,七成的几率在无政府状态下发言,
显然这个玩家比较有可能是一个不正常的玩家。我们直觉上明白这件事情,但是我们仍然希望用一个数值化的方法告诉我们玩家落在哪里会更加的异常。
那么这种数值化的方法可以用高斯分布(用样本估计总体)
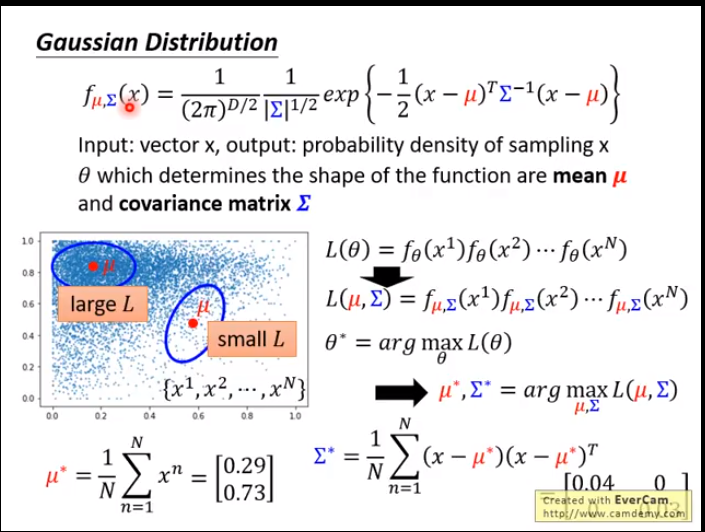
D:X的维度
加入更多的特征
由于得到的f 比较大,可以取Log

还可以使用自动编码器(Auto-Encoder)
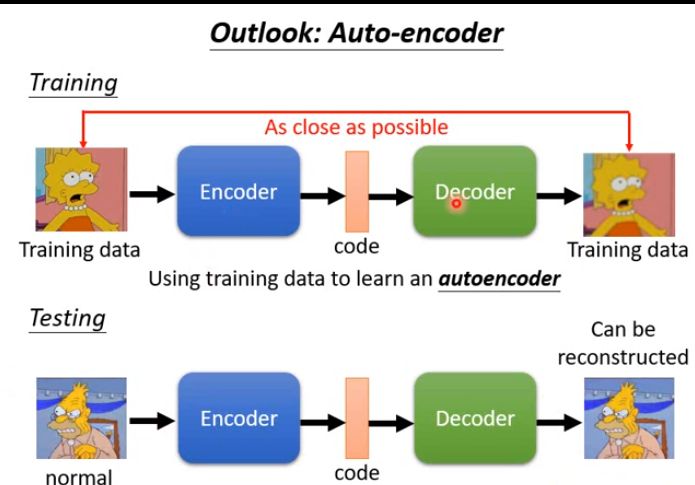

code:vector
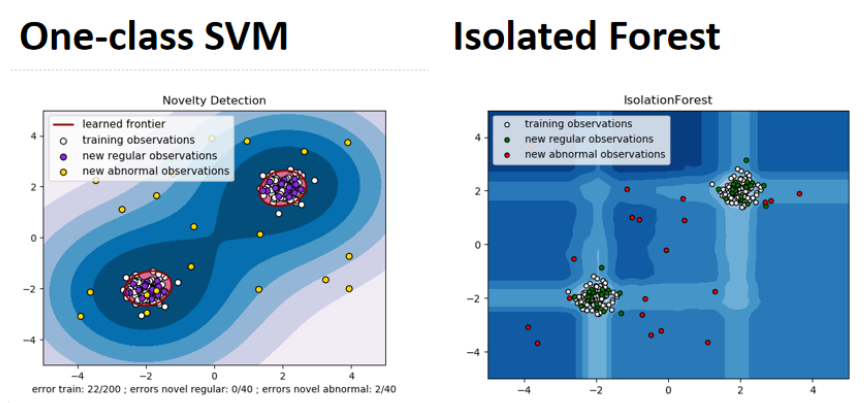
machine learning中也有其它做异常侦测的方法,比如SVM的One-class SVM,只需要正常的资料就可以训练SVM,
然后就可以区分正常的还是异常的资料。在Random Forset的Isolated Forest,它所做的事情跟One-class SVM所做的事情很像(给出正常的训练进行训练,模型会告诉你异常的资料是什么模样)。