提到数据挖掘,大家的第一感觉是比较高深,稍微了解的人也会被里面涉及的众多概念和算法搞得晕头转向,其实任何的工具和算法都是为了解决特定的问题而产生的,如果我们抛开这些让人看着头疼的东西,还原事物的本来面貌,我们就可以比较容易理解这些工具和算法需要解决的问题,当然这种思路只是我的一家之言,正确与否,尚未可知,但是我们可以从这里进行入手。
在日常工作中,我们经常会遇到这样的问题“我们的销售到底和哪些因素有关联,哪些因素是主要因素”,如何找到这些影响销售的因素,确定他们的影响程度大小。“这样的问题我们经常会遇到,可是我们如何去解决这类问题呢。
常规的思路可能是可能构造一张如下的表格
|
教育程度 |
性别 |
年龄 |
年收入 |
子女数 |
购买情况 |
|
大学 |
男 |
30 |
30w |
2 |
购买 |
|
初中 |
女 |
25 |
20w |
0 |
未购买 |
找到购买情况=购买,分别看教育程度,性别等各个因素有多少值,但是这样的结果可能没有什么实际意义,因为可能购买的教育程度涵盖了所有的类别,而且这样的思考方法也没有办法获知购买行为和什么因素的关联最大。因此,我们才引入了统计学的思考方式(呵呵这个我也不太懂),但是我们可以通过spss来解决这样的问题。
1. 相关软件的安装
首先是spss statistics的安装,这个就是传说中的spss了,网上很多的下载,最新的版本已经到20了,而且有破解斑斑,我用的是19,基本操作是一样的。这个软件是做数据分析的。其次是安装modeler(也就是以前说的spss clementine),从14以后改名为Modeler,这个工具主要是进行数据挖掘的,至于数据分析和数据挖掘的区别,有时间在详细说,其实上面的问题我们完全可以只用Modeler来解决
2. Modeler的安装
这个需要单独提一下,由于我本子系统安装的是win2003,安装的时候出现了“系统管理员设置了系统策略,禁止进行此安装”的提示,网上对此办法解决无外乎是修改组策略等等,试了都不管用,修改程序的兼容性,用2000和xp都不能正常安装,错误提示是一样的。后来查看ibm的modeler安装说明,发现modeler的客户端的版本不支持2003,只支持win7、vista、xp。这是因为它认为win2003是服务器,能安装server版不能安装client,它哪里知道咱们国内很多人拿2003作为个人操作系统在使用(这个思路怎么和微软如出一辙),详细的安装说明请见下面的链接。
ftp://public.dhe.ibm.com/software/analytics/spss/documentation/modeler/14.2/zh_CN/ClientInstallation_NamedSingleUserLicense.pdf
没有办法,只能用virtualbox弄出一个xp系统来,注意这个xp得是sp3才能安装Modeler14,在网上找寻了一遍没有14的破解包,好在有个15的适用,凑合用着。安装程序应该好找,我是在115网盘上找到的。
3.下面说一下数据的情况
我们首先需要把上面中的数据中的文字适用数值来替换,方法很多,spss的基本操作中就有这方面的介绍,不在赘述,得到如下形式的数据。
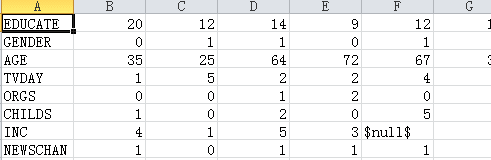
我们发现这和我们常见的数据方式不一样,对,我们需要做行列转换,在spss中在“数据”下拉框中选择“转置”,注意“名称变量”选择第一列,如下
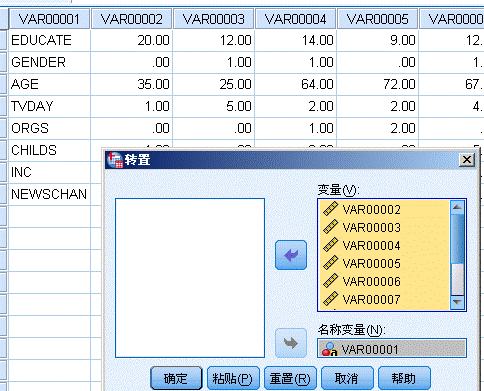
这样我们就能得到符合我们要求的数据(当然你也可以一开始就构造符合我们格式的数据)。
保存数据为.sav格式文件以便在Modeler中使用。
注意这里要非常注意变量视图中的度量标准,分为度量(Scale)、序号(Ordinal)和名义(Nominal)
如果是连续变量就用度量,分类变量就使用序号和名义
名义变量是对数据进行分类得到的变量,如按性别分为男女,按年龄分为老中青
序号变量是对数据进行排序得到的变量,如按成绩先后分为第一、第二等
度量变量是对数据经过按标准测量或使用工具测试后得到的数据,有绝对零点和相对零点的数据。绝对零点如长度、重量等;相对零点如温度、成绩、智商等
如下图所示:度量值的有教育程度、年龄、tvday、orgs
序号变量有子女数、收入
名义变量有性别、是否接受服务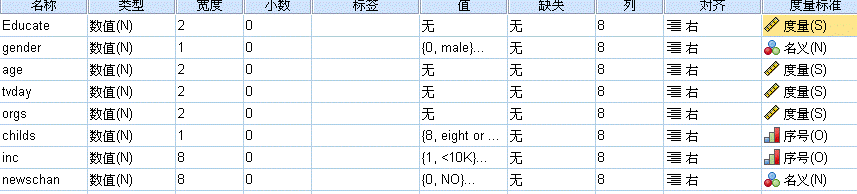
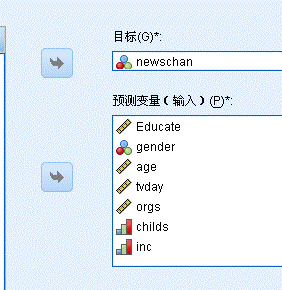
3. 启动Modeler,如下图所示,在“源”中拖动一个statistics图标到主工作区,这是我们刚才创建的.sav文件,右键编辑,把数据导入。然后在“字段选项”中拖动“类型”,以定义我们的数据文件格式。按住alt,从statistics拉一条线到“类型:图标,建立两者的联系。右键编辑,修改newschan字段为标志,因为我们是从这个字段来判别是否接受服务。
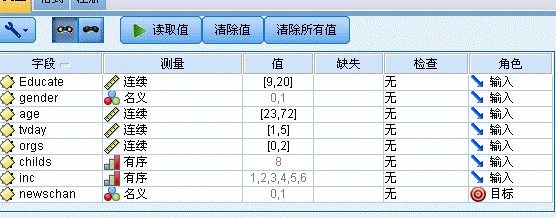
4. 下面最重要的就是建模了,我们采用C&R树,这是逻辑树的一种,至于逻辑树内部的C&R树、Quest、CHAID、C5.0的区别,在单独有机会说明。拖动到主界面。注意字段Newschan是否在“目标“中。构建选项采用默认,确定。
5. 在输出中,我们拖动“表“和”分析“,来对最终结果的数据和分析情况直观查看。
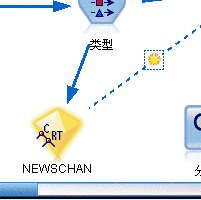
6. 在c&R树上右键运行,成功后会生成一个黄色的图标,建立这个图标和输出的两个图标的关联
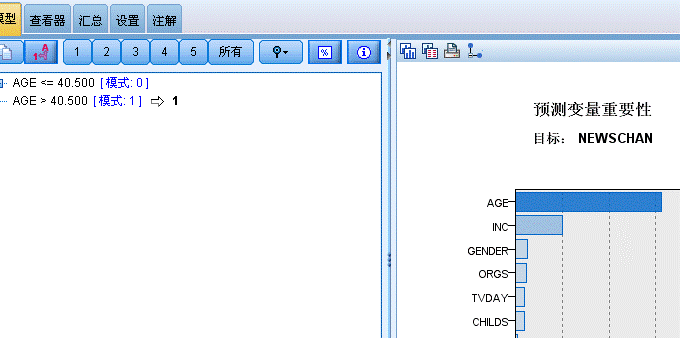
7.查看结果c&r树的结果,我们可以看到年龄的影响是最大的,约占62%(这个数值与样本数据的数据量是有直接关系的,在测试几百条数据的时候是这样,如果随机10条,可能年龄就占100%),后面我提供测试数据供大家验证。
8. 查看表和分析
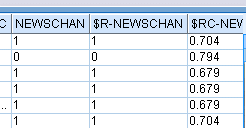
$R- 表示预测值,$RC- 表示置信度值,从数据看大部分的数据与预测值吻合
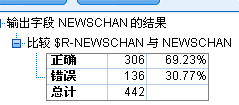
从分析结果看,预测正确率以样本数据(442条)看在70%,可信度比较高
更详细的内容大家可以参考下面的链接
http://www.ibm.com/developerworks/cn/data/library/techarticle/dm-1103liuzp/
文章内使用的数据文件如下,压缩包内两个文件,一个是csv的小数据量的数据文件 一个是402条的statistics文件,可以直接在Modeler中使用