例子的详细文档请查看modeler14.1的“数据准备实例”的药物治疗(勘察表 /C5.0)实例,这里给出一个下载的地址
http://ishare.iask.sina.com.cn/f/12577308.html
这个例子写得非常好,非常容易理解,但是他操作的步骤没有说明为什么这么做,我结合自己的感受汇总了一下思路,加入我个人的一些理解,不知道对否,但是可是算作我个人学习过程中的一种思考吧。
以下是操作的步骤
1.首先用表查看数据
2.使用图形中的分布,查看情况,了解数据的结构(这里是查看目标字段 药品的分布情况)
3.使用数据审核,查看所有数据的分布和直方图
4.使用图形中的散点图查看那些因素对目标的影响,注意选择xy轴对象,目标字段为交叠字段,从散点图可以看出一部分的关系(这里查验Na和K元素对药品的关系)
这里引申:Na-K比对药品有比较明显的趋势,那血压和胆固醇水平与药品之间是否有什么关系呢,我做了一下散点图(如下图)
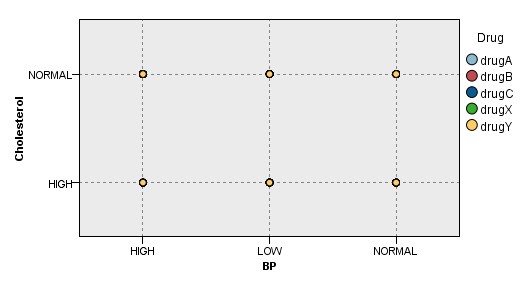
发现无论由于样例数据的胆固醇只存在高和正常,而血压数据无论高低的适用药品均为Y,是否说明Y药品适用于所有的血压和胆固醇类型人群呢?或者说药品和血压与胆固醇没有关系。其实我仔细查看发现其实不是这样的,因为散点图需要的数据为连续型数据的意义比较大,而血压和胆固醇是分类数据,样本太少,因此使用散点图去查看他们的关系是不合适的,那是否可以用其他方式呢,看下面。
5.使用图形中的网络图,来查验不同类别之间的关系(这里是查看血压和药品之间的关系)
引申:这里我们同样可以查看胆固醇和药品的关系。如下图
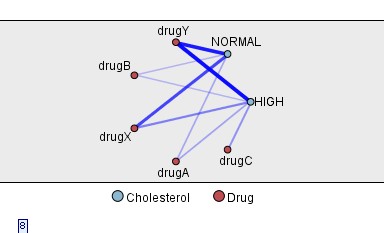
注意由于样例的胆固醇水平只有高和正常两种情况,因此可以看到除了药品C只适用于高胆固醇类型外,其他的都适用于任何类型。
如果我们选择血压、胆固醇和药品,那这个网络图会出现什么情况呢?如下图
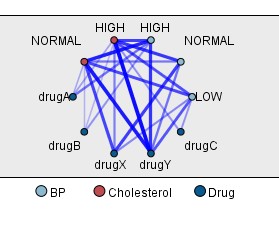
很乱啊。但是仔细看也能看出一些规律
药品Y:所有胆固醇、所有血压
药品A:所有胆固醇、高血压
药品B:所有胆固醇、高血压
药品X:所有胆固醇、非高血压
正如例子中所说,其实这样我们还不能确定参数和目标字段的关系,还得使用C5.0
但是我们采用这些建模算法之前可以使用散点图、网络图、分布图对数据的一些情况进行初步的分析,了解数据的一些大概规律,然后使用建模算法以后的结果来验证我们之前的思考,也可以算作一些验证和学习的过程吧。