一.pandas数据结构介绍
在pandas中有两类非常重要的数据结构,即序列Series和数据框DataFrame。Series类似于numpy中的一维数组,
除了通吃一维数组可用的函数或方法,而且其可通过索引标签的方式获取数据,还具有索引的自动对齐功能;DataFrame
类似于numpy中的二维数组,同样可以通用numpy数组的函数和方法,而且还具有其他灵活应用,后续会介绍到。
二.pandas数据结构之Series
#使用模块之前先导入
import pandas as pd from pandas import Series from pandas import DataFrame import numpy as np
1.series
Series是一种类似与一维数组的对象,由下面两部分组成
values:一组数据(ndarray)
index:相关的数据索引标签
1)Series的创建
两种创建方式:
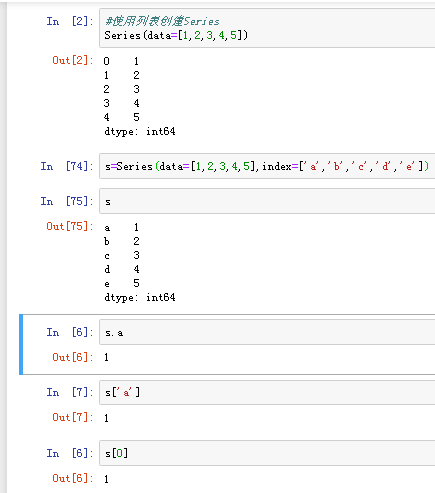
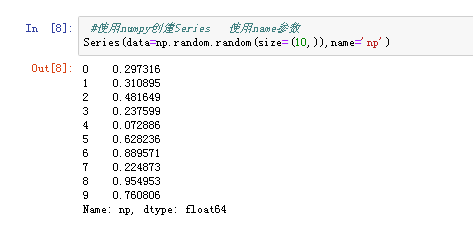
(1)由列表或numpy数组创建
默认索引为0到n-1的整形索引
(2)由字典创建:不能在使用index.但是依然存在默认索引 注意:数据源必须为一维数据
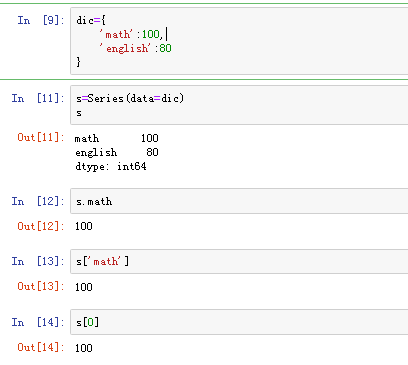
2)Series的索引和切片 可以使用中括号取单个索引(此时返回的是元素类型),或者中括号里一个列表取多个索引(此时返回的是一个Series类型) (1) 显式索引 使用index中的元素作为索引值 使用s.loc[](推荐):注意,loc中括号中放置的一定是显式索引 注意:此时是闭区间
(2)隐式索引:
使用整数作为索引值
使用.iloc[](推荐) iloc中括号中放置的必须是隐式索引
注意:此时是半开区间

切片:隐式索引切片和显式索引切片
显式索引切片:index和loc
隐式索引切片:整数索引值和iloc
3)Series的基本概念
可以把Series看成是一个有序的字典
向Series增加一行:相当于给字典增加一组键值对
可以通过shape,size,index,values等得到series的属性

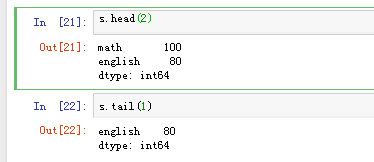
可以使用s.head()和s.tail()分别查看前n个值和后n个值:
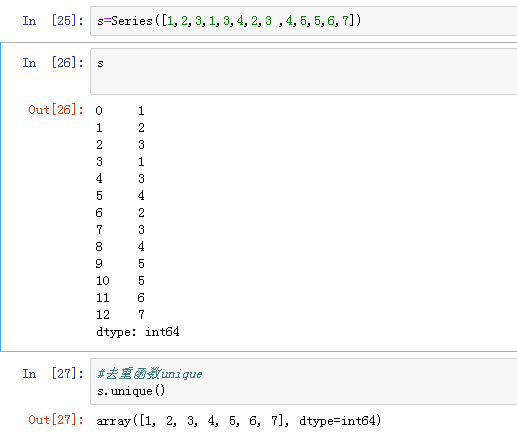
对Series元素进行去重:
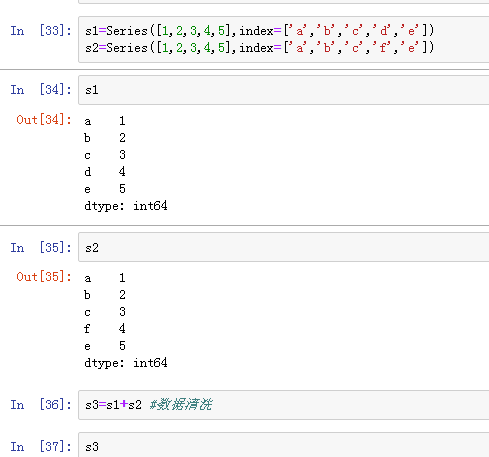
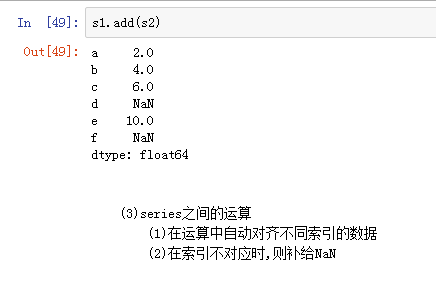
当索引没有对应值时,可能出现缺失数据NaN(not a number)的情况 使得两个Series进行相加:

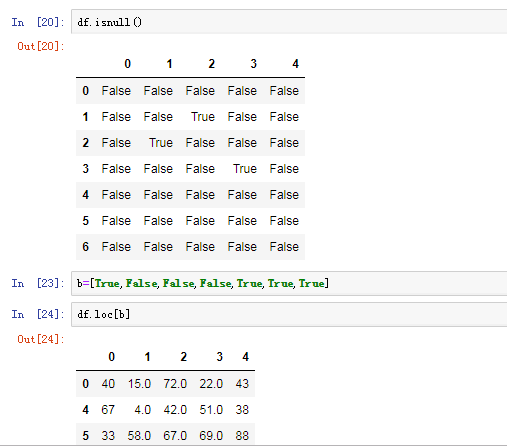
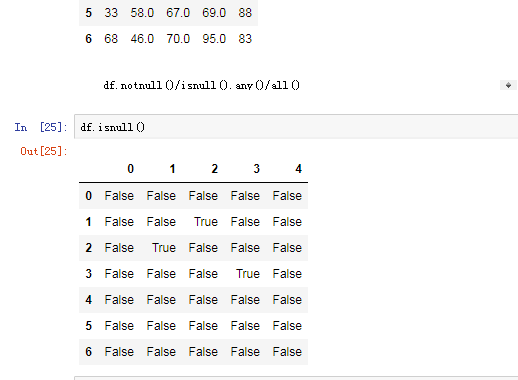
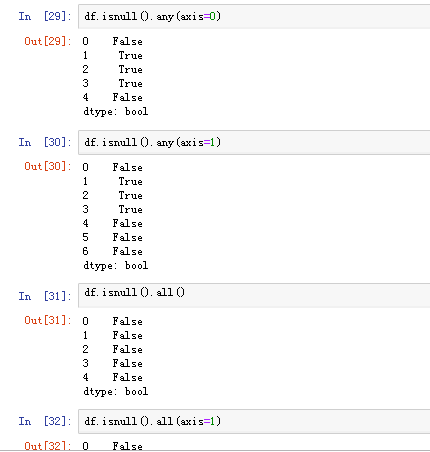
可以使用pd.isnull(),pd.notnull(),或者s.isnull(),notnull(),函数检测缺失数据
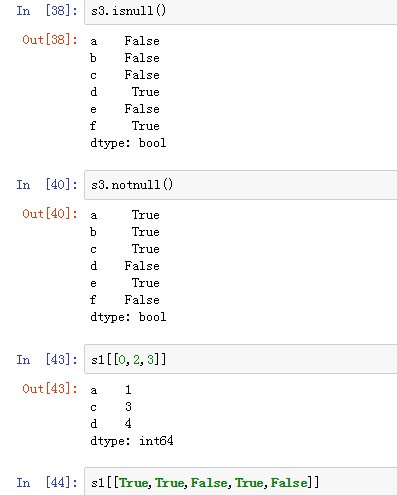
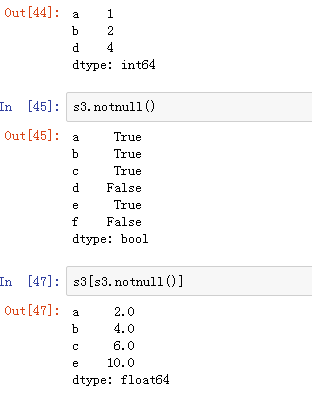
4)Series的运算 (1)+ - * / (2) add() sub() mul() div() :s1.add(s2,fill_value=0)
三.pandas数据结构之DataFrame
DataFrame是一个[表格型]的数据结构.DataFrame由按一定顺序排列的多列数据组成.设计之初也是将Series的使用场景从一维拓展到多维.DataFrame既有的行索引,又有列索引
行索引:index
列索引:columns
值:values
1)DataFrame的创建
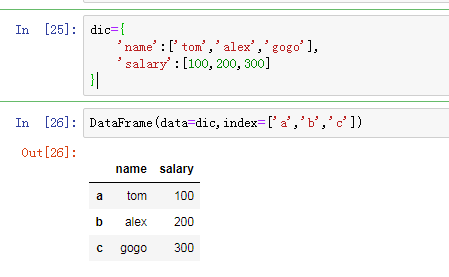
最常用的方法是传递一个字典创建.DataFrame以字典的键作为每一[列]的名称,
以字典的值(一个数组)作为每一列
此外,DataFrame会自动 加上每一行的索引.
使用字典创建的DataFrame后,则columns(列索引)参数将不可被使用
同Series一样,若传入的列与字典的键不匹配,则相应的值为NaN
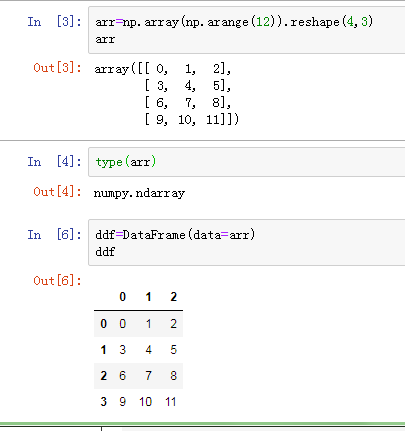
(1)使用numpy创建DataFrame:

Dataframe的属性:
values,colunmns,index,shape

(2)使用字典创建DataFrame
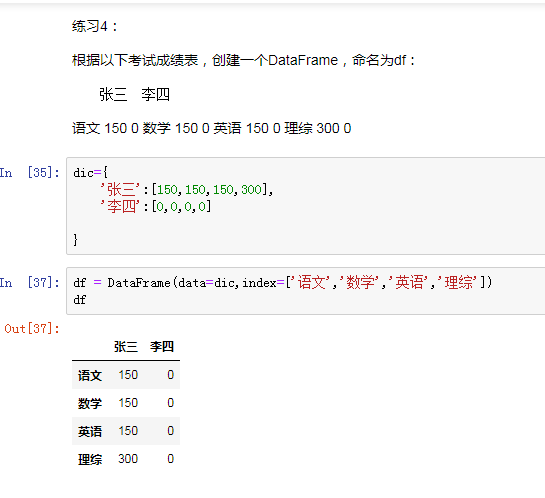
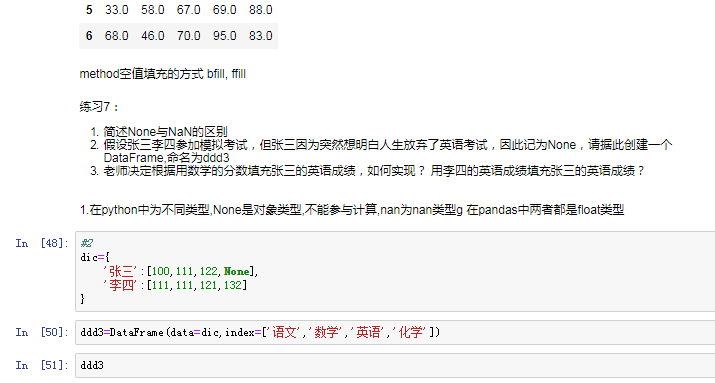
(3)使用多维数组创建
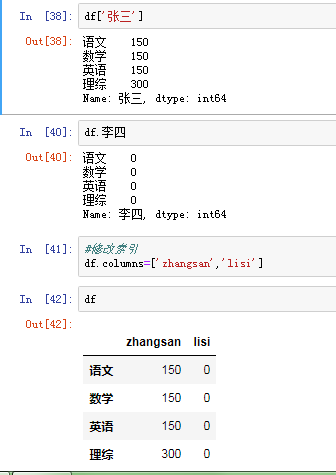
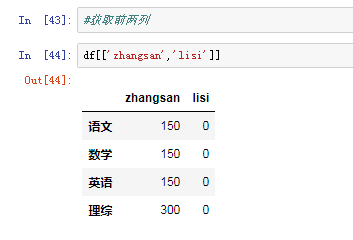
2)DataFrame的索引 (1)对列进行索引 通过类似字典的方式df['q'] 通过属性的方式 df.q
可以将DataFrame的列获取为一个Series.返回的Series拥有原DataFrame相同的索引 ,且name的属性也已经设置好了,就是相应的列名
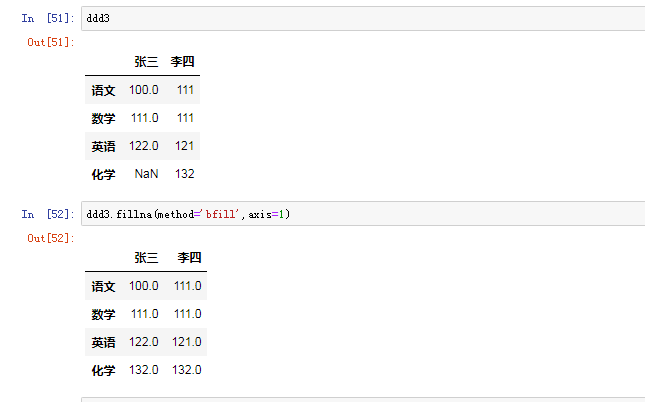
(2)对行进行索引
使用.loc[]加index来进行行索引(显示索引)
使用.iloc[]加整数来进行行索引(隐式索引)
同样返回一个Series,index为原来的columns
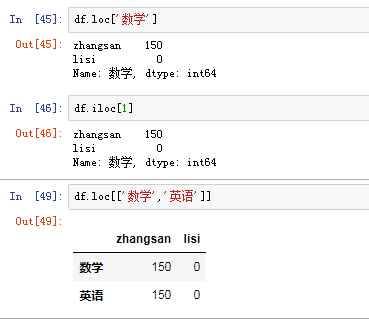
(3)对元素索引的方法 使用列索引 使用行索引(iloc[3,1] or loc ['c','q']) 行索引在前,列索引在后
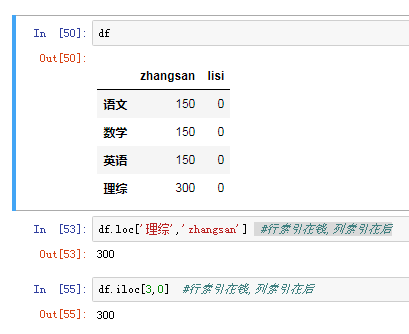
3)切片
注意: 直接使用中括号时候: 索引表示的是列索引,切片表示的是行切片
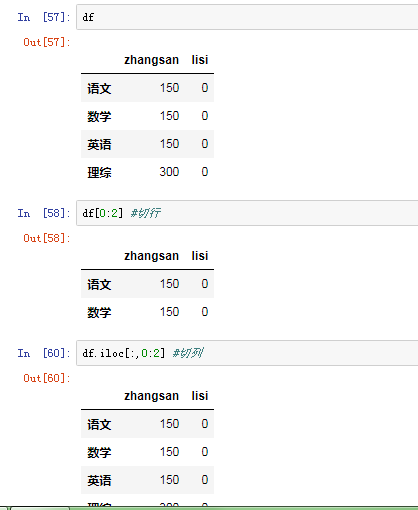
4)DataFrame的运算
同Series一样:
在运算中自自动对齐不同索引的数据
如果索引不对应,则补给NaN 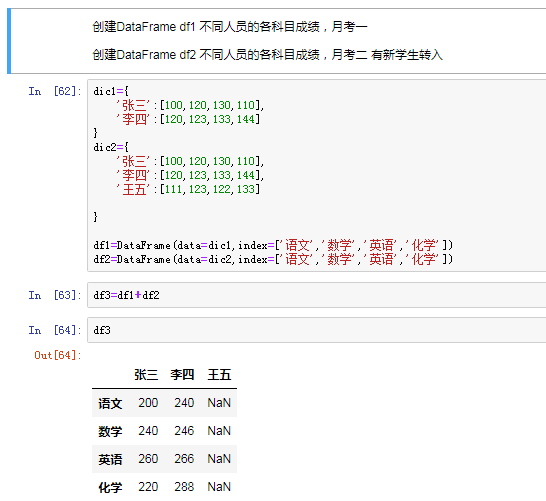
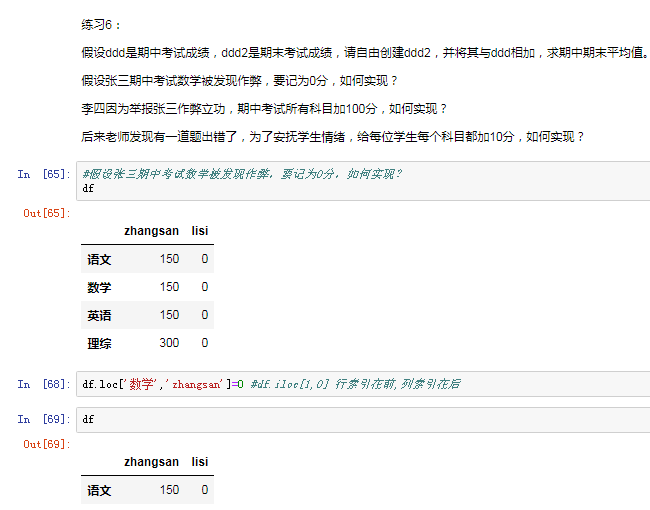
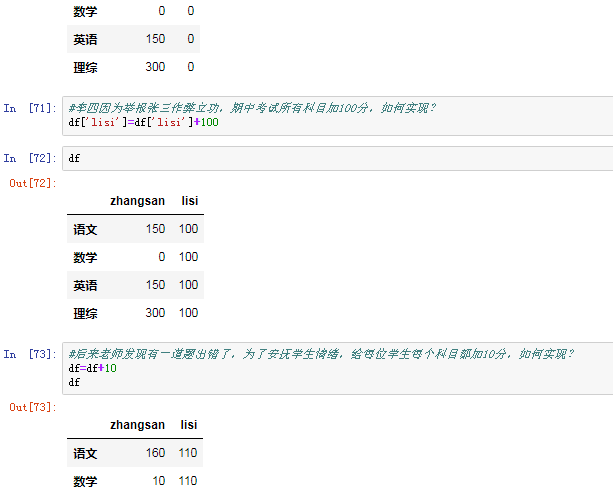
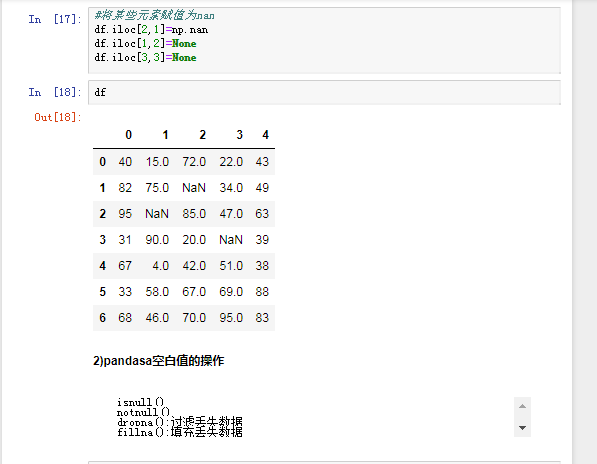
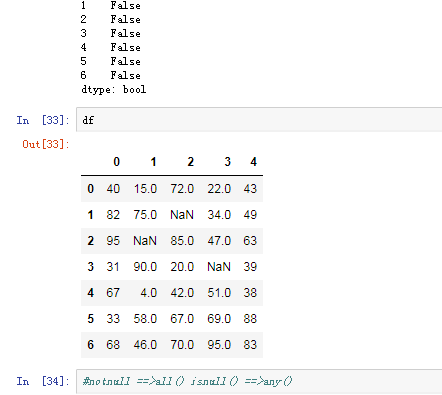
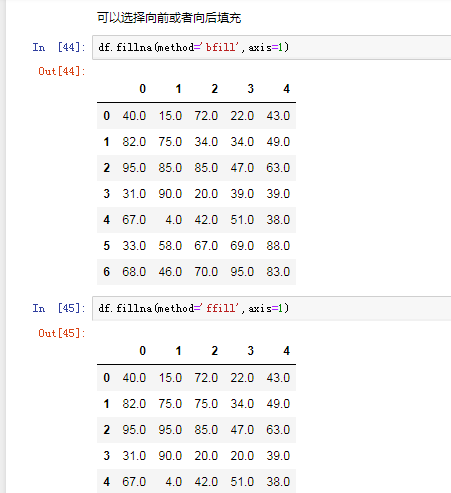
四.pandas之丢失数据的处理
有两种丢失数据
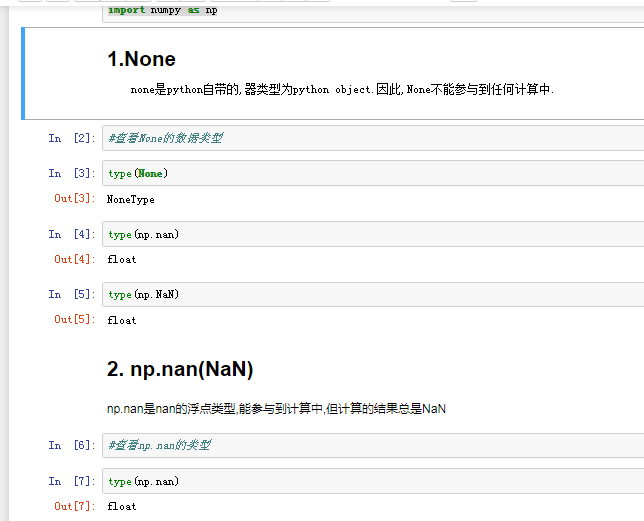
None
np.nan(NaN)