一.当使用request模块请求的时候,requests首先会对url进行编码,可以通过抓包软件查看
import requests res = requests.get('https://www.baike.com/wiki/林俊杰',verify=False) print(res) print(res.url)
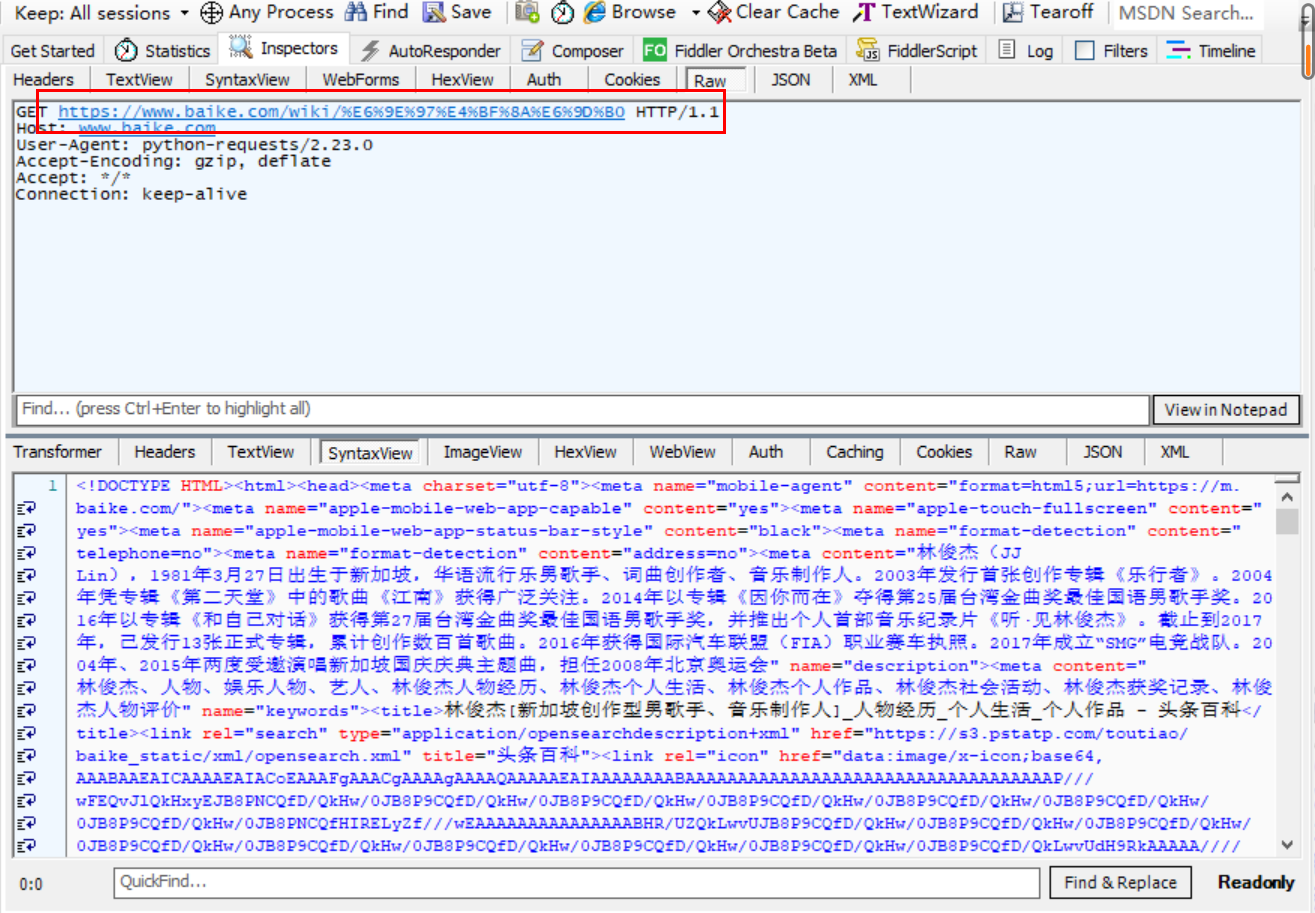
如图,requests模块会对我们请求的url进行编码,那么他是在哪里做的呢?我们看下源码
首先是get方法
def get(url, params=None, **kwargs): r"""Sends a GET request. :param url: URL for the new :class:`Request` object. :param params: (optional) Dictionary, list of tuples or bytes to send in the query string for the :class:`Request`. :param **kwargs: Optional arguments that ``request`` takes. :return: :class:`Response <Response>` object :rtype: requests.Response """ kwargs.setdefault('allow_redirects', True) return request('get', url, params=params, **kwargs)
把我们的参数传给request了,我们看看request方法
def request(method, url, **kwargs): with sessions.Session() as session: return session.request(method=method, url=url, **kwargs)
原来是利用session进行了请求,我们在看看session.request方法
def request(self, method, url, req = Request( method=method.upper(), url=url, headers=headers, files=files, data=data or {}, json=json, params=params or {}, auth=auth, cookies=cookies, hooks=hooks, ) prep = self.prepare_request(req) proxies = proxies or {} settings = self.merge_environment_settings( prep.url, proxies, stream, verify, cert ) # Send the request. send_kwargs = { 'timeout': timeout, 'allow_redirects': allow_redirects, } send_kwargs.update(settings) resp = self.send(prep, **send_kwargs) return resp
把请求参数构建res对象传给prepare_request方法了,那么我们看看prepare_request方法
def prepare_request(self, request): auth = request.auth if self.trust_env and not auth and not self.auth: auth = get_netrc_auth(request.url) p = PreparedRequest() p.prepare( method=request.method.upper(), url=request.url, files=request.files, data=request.data, json=request.json, headers=merge_setting(request.headers, self.headers, dict_class=CaseInsensitiveDict), params=merge_setting(request.params, self.params), auth=merge_setting(auth, self.auth), cookies=merged_cookies, hooks=merge_hooks(request.hooks, self.hooks), ) return p
把参数交给PreparedRequest类构建对象再传给在传给prepare方法
看下prepare方法
def prepare(self, method=None, url=None, headers=None, files=None, data=None, params=None, auth=None, cookies=None, hooks=None, json=None): """Prepares the entire request with the given parameters.""" self.prepare_method(method) self.prepare_url(url, params) self.prepare_headers(headers) self.prepare_cookies(cookies) self.prepare_body(data, files, json) self.prepare_auth(auth, url) self.prepare_hooks(hooks)
又调用了self.prepare_url(url, params)处理
def prepare_url(self, url, params): """Prepares the given HTTP URL.""" if isinstance(url, bytes): url = url.decode('utf8') else: url = unicode(url) if is_py2 else str(url) # Remove leading whitespaces from url url = url.lstrip() # Don't do any URL preparation for non-HTTP schemes like `mailto`, # `data` etc to work around exceptions from `url_parse`, which # handles RFC 3986 only. if ':' in url and not url.lower().startswith('http'): self.url = url return # Support for unicode domain names and paths. try: scheme, auth, host, port, path, query, fragment = parse_url(url) except LocationParseError as e: raise InvalidURL(*e.args) if not scheme: error = ("Invalid URL {0!r}: No schema supplied. Perhaps you meant http://{0}?") error = error.format(to_native_string(url, 'utf8')) raise MissingSchema(error) if not host: raise InvalidURL("Invalid URL %r: No host supplied" % url) # In general, we want to try IDNA encoding the hostname if the string contains # non-ASCII characters. This allows users to automatically get the correct IDNA # behaviour. For strings containing only ASCII characters, we need to also verify # it doesn't start with a wildcard (*), before allowing the unencoded hostname. if not unicode_is_ascii(host): try: host = self._get_idna_encoded_host(host) except UnicodeError: raise InvalidURL('URL has an invalid label.') elif host.startswith(u'*'): raise InvalidURL('URL has an invalid label.') # Carefully reconstruct the network location netloc = auth or '' if netloc: netloc += '@' netloc += host if port: netloc += ':' + str(port) # Bare domains aren't valid URLs. if not path: path = '/' if is_py2: if isinstance(scheme, str): scheme = scheme.encode('utf-8') if isinstance(netloc, str): netloc = netloc.encode('utf-8') if isinstance(path, str): path = path.encode('utf-8') if isinstance(query, str): query = query.encode('utf-8') if isinstance(fragment, str): fragment = fragment.encode('utf-8') if isinstance(params, (str, bytes)): params = to_native_string(params) enc_params = self._encode_params(params) if enc_params: if query: query = '%s&%s' % (query, enc_params) else: query = enc_params url = requote_uri(urlunparse([scheme, netloc, path, None, query, fragment])) self.url = url
对url进行了一系列处理之r后又调用requote_uri方法
def requote_uri(uri): """Re-quote the given URI. This function passes the given URI through an unquote/quote cycle to ensure that it is fully and consistently quoted. :rtype: str """ safe_with_percent = "!#$%&'()*+,/:;=?@[]~" safe_without_percent = "!#$&'()*+,/:;=?@[]~" try: # Unquote only the unreserved characters # Then quote only illegal characters (do not quote reserved, # unreserved, or '%') return quote(unquote_unreserved(uri), safe=safe_with_percent) except InvalidURL: # We couldn't unquote the given URI, so let's try quoting it, but # there may be unquoted '%'s in the URI. We need to make sure they're # properly quoted so they do not cause issues elsewhere. return quote(uri, safe=safe_without_percent)
最终都是进行编码了。
这里主要是想说:
1.在url中传入中文是没问题,只要url值正常的url,有对应的页面,都可以借助requests进行请求,request模块自动的帮你编码
2.如果你不想那个url被编码,要么你用白哦准模块
二.简单修改源码使其不会被编码
with request.urlopen(url) as response: data = response.read() return data.decode('utf-8')