初尝
Python 3.7 引入了一个新的模块,这个模块就是今天要试探的 dataclass。dataclass 的用法和普通的类装饰器没有任何区别,它的作用是替换定义类的时候的:def __init__()
我们来看看如何使用它
# 我们需要引入 dataclass 包 from dataclasses import dataclass @dataclass class A: a: int b: int c: str d: str = "test" a = A(1, 2, "3") print(a)
我们执行这段代码,得到结果A(a=1, b=2, c='3', d='test')
可以看到,它的效果和
class A: def __init__(self, a, b, c, d="test"): self.a = a self.b = b self.c = c self.d = d a = A(1, 2, "3") print(a)
完全一样!使用了 dataclass 可以省下很多代码,可以帮我们节约很多时间,代码也变得很简洁了。
定义类型
我们发现,使用 dataclass 的时候,需要对初始化的参数进行类型定义,比如上面的例子里面,我为 a, b, c, d 定义的类型分别是 int, int, str 和 str。
那我建立实例的时候,传递非定义的类型的数据进去,会报错么?
答案是很明显的,是不会报错的,毕竟 python 是解释性语言嘛。
当然我们也要试试的
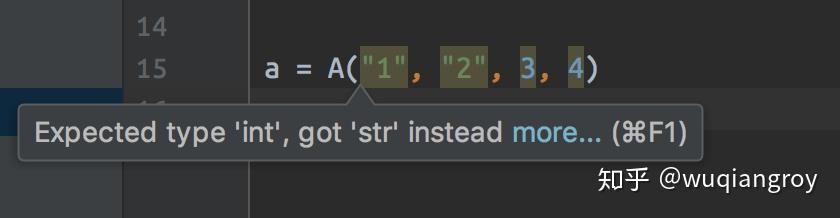
a = A("name", "age", 123, 123) print(a)
得到结果A(a='name', b='age', c=123, d=123)
果然是不会报错的。
但是在 pycharm 之类的 IDE 里面,是会提醒修改的,这点很不爽
那么我们可以使用万能的类型的么?当然是可以的,但是不建议(毕竟现在都建议写 python 的工程师加上类型检查了)
做法如下:
@dataclass class A: a: "" b: 1
这样就可以随意传参了。
我们只需要随意给一个字符串就可以了,也可以事任何的其他类型
继承
使用了 dataclass 之后,类的继承还是之前的那样么?
我们来试试
@dataclass class A: a: int b: str @dataclass class B(A): c: int d: int b = B(a=1, b="2", c=3, d=4)
就完了。
再来想想我们之前的继承 __init__ 是怎么写的
class A: def __init__(self, a: int, b: str): self.a = a self.b = b class B(A): def __init__(self, a: int, b: str, c: int, d: int): super().__init__(a, b) self.c = c self.d = d b = B(a=1, b="2", c=3, d=4)
一对比,是不是上面的代码简洁太多太多了!简直的优化利器!
使用 make_dataclass 快速创建类
除此之外,dataclasses 还提供了一个方法 make_dataclass 让我们可以快速创建类
from dataclasses import make_dataclass A = make_dataclass( "A", [("a", int), "b", ("c", str), ("d", int, 1)], namespace={'add_one': lambda self: self.a + 1})
这个和
@dataclass class A: a: int b: "" c: str d: int = 1 def add_one(self): self.a += 1
是完全一样的
field
field 在 dataclasses 里面是比较重要的功能, 用于初处理定义的参数非常有用
在 PEP 557 中是这样描述 field 的
Field objects describe each defined field. These objects are created internally, and are returned by the fields() module-level method (see below). Users should never instantiate a Field object directly.
大致意思就是 Field 对象是用于描述定义的字段的,这些对象是内部定义好了的。然后由 field() 方法返回,用户不用直接实例化 Field。
我们先看看 field 是如何使用的
from dataclasses import dataclass, field @dataclass class A: a: str = field(default="123")
可以用于设立默认值,和 a: str = "123" 一个效果,那为什么我们还需要 field 呢?
因为 field 的功能远不止这一个设置默认值,他还有很多有用的功能
- 设置是否加载到
__init__里面去
@dataclass class A: a: int b: int = field(default=10, init=False) a = A(1) # 注意,实例化 A 的时候只需要一个参数,赋给 a 的
等价于:
class A: b = 10 def __init__(self, a: int): self.a = a
- 设置是否成为
__repr__返回参数
我们在之前实例化A的时候,把实例化对象打印出来的话,是这样的:A(a=1, b=10)
那如果我们不想把特定的对象打印出来,可以这样写:
@dataclass class A: a: int b: int = field(default=1, repr=False) a = A(1) print(a)
这时候,打印的结果为 A(a=1)
- 设置是否计算
hash的对象之一a: int = field(hash=False) - 设置是否成为和其他类进行对比的值之一
a: int = field(compare=False) - 定义
field信息
from dataclasses import field, dataclass, fields @dataclass class A: a: int = field(metadata={"name": "a"}) # metadata 需要接受一个映射对象,也就是 python 的字典 metadata = fields(A) print(metadata)
打印的结果是(Field(name='a',type=<class 'int'>,default=<dataclasses._MISSING_TYPE object at 0x10f2fe748>,default_factory=<dataclasses._MISSING_TYPE object at 0x10f2fe748>,init=True,repr=True,hash=None,compare=True,metadata=mappingproxy({'name': 'a'}),_field_type=_FIELD),)
是一个 tuple,第一个即是 a 字段的 field 定义
可以通过 metadata[0].metadata["name"] 获取值
- 自定义处理定义的参数
有些字段需要我们进行一些预处理,不用传递初始值,由其他函数返回
我们可以这么写
def value(): return "123" @dataclass class A: a: str = field(default_factory=value) print(A().a) # 实例化 A 的时候已经可以不传递值了
打印的结果是 '123'
使用 dataclass 设定初始方法
使用装饰器 dataclass 的时候,设定一些参数,即可选择是否需要这些初始方法
__init__
@dataclass(init=False) class A: a: int = 1 print(A())
打印结果['__module__', '__annotations__', 'a', '__dict__', '__weakref__', '__doc__', '__dataclass_params__', '__dataclass_fields__', '__repr__', '__eq__', '__hash__', '__str__', '__getattribute__', '__setattr__', '__delattr__', '__lt__', '__le__', '__ne__', '__gt__', '__ge__', '__init__', '__new__', '__reduce_ex__', '__reduce__', '__subclasshook__', '__init_subclass__', '__format__', '__sizeof__', '__dir__', '__class__']
的确是没有 __init__ 的
__repr__field可以设置哪个参数不加入类返回值,设置@dataclass(repr=False)即可__hash__
设置是否需要对类进行hash,可以结合a: int = field(hash=True)一起设置__eq__
这是类之间比较使用的方法,
同样可以结合a: int = field(compare=True)一起设置
源码剖析
dataclasses 这个库这么强大,我们来一步步剖析它的源码吧
field 源码剖析
首先我们看看 field 的源码
def field(*, default=MISSING, default_factory=MISSING, init=True, repr=True, hash=None, compare=True, metadata=None): if default is not MISSING and default_factory is not MISSING: raise ValueError('cannot specify both default and default_factory') return Field(default, default_factory, init, repr, hash, compare, metadata)
这段代码很简单,对传入的参数进行判断之后,返回 Field 实例。
注意 default 和 default_factory 缺一不可,都是作为定义初始值的。
然后我们来看看 Field 的源码:
class Field: __slots__ = ('name', 'type', 'default', 'default_factory', 'repr', 'hash', 'init', 'compare', 'metadata', '_field_type', ) def __init__(self, default, default_factory, init, repr, hash, compare, metadata): self.name = None self.type = None self.default = default self.default_factory = default_factory self.init = init self.repr = repr self.hash = hash self.compare = compare self.metadata = (_EMPTY_METADATA if metadata is None or len(metadata) == 0 else types.MappingProxyType(metadata)) self._field_type = None def __repr__(self): return ('Field(' f'name={self.name!r},' f'type={self.type!r},' f'default={self.default!r},' f'default_factory={self.default_factory!r},' f'init={self.init!r},' f'repr={self.repr!r},' f'hash={self.hash!r},' f'compare={self.compare!r},' f'metadata={self.metadata!r},' f'_field_type={self._field_type}' ')') def __set_name__(self, owner, name): func = getattr(type(self.default), '__set_name__', None) if func: # There is a __set_name__ method on the descriptor, call # it. func(self.default, owner, name)
基本没有什么可以说的,就是简单的类,功能也就一个 __set_name__
我们注意一下 __repr__ 里面的有个细节:f'name={self.name!r},', 比如 self.name 为 "name", 这里会返回 "name='name',"
dataclass 源码剖析
接下来我们来看 dataclass 的源码
def dataclass(_cls=None, *, init=True, repr=True, eq=True, order=False, unsafe_hash=False, frozen=False): def wrap(cls): return _process_class(cls, init, repr, eq, order, unsafe_hash, frozen) if _cls is None: return wrap return wrap(_cls)
这是一个很常见的装饰器
当我们定义类的时候,把类本身作为 _cls 参数传递进去,这时候返回一个 _process_class 函数的值
实例化类的时候,这时候 _cls 为 None, 返回 wrap 对象
接着我们来看 _process_class 源码
这段代码比较长,我们删减部分(不影响核心功能),删除的是生成初始化函数的部分,有兴趣的读者可以自己查看一下。
def _process_class(cls, init, repr, eq, order, unsafe_hash, frozen): fields = {} setattr(cls, _PARAMS, _DataclassParams(init, repr, eq, order, unsafe_hash, frozen)) any_frozen_base = False has_dataclass_bases = False for b in cls.__mro__[-1:0:-1]: base_fields = getattr(b, _FIELDS, None) if base_fields: has_dataclass_bases = True for f in base_fields.values(): fields[f.name] = f if getattr(b, _PARAMS).frozen: any_frozen_base = True cls_annotations = cls.__dict__.get('__annotations__', {}) cls_fields = [_get_field(cls, name, type) for name, type in cls_annotations.items()] for f in cls_fields: fields[f.name] = f if isinstance(getattr(cls, f.name, None), Field): if f.default is MISSING: delattr(cls, f.name) else: setattr(cls, f.name, f.default) setattr(cls, _FIELDS, fields) if init: has_post_init = hasattr(cls, _POST_INIT_NAME) flds = [f for f in fields.values() if f._field_type in (_FIELD, _FIELD_INITVAR)] _set_new_attribute(cls, '__init__', _init_fn(flds, frozen, has_post_init, '__dataclass_self__' if 'self' in fields else 'self', )) return cls
这段代码,最后将传进来的 cls 返回出去,也就是返回的是类本身(初始化类的时候)
我们来看第一句代码:
setattr(cls, _PARAMS, _DataclassParams(init, repr, eq, order,
unsafe_hash, frozen))
_PARAMS 为前面定义的变量,值为 __dataclass_params___DataclassParams 是一个类
这句话就是把 _DataclassParams 实例作为值,__dataclass_params__ 作为属性赋给 cls
所以,我们在查看定义的类的所有属性的时候,会有一个 __dataclass_params__ 属性,然后我们打印看看:_DataclassParams(init=True,repr=True,eq=True,order=False,unsafe_hash=False,frozen=False)
即是 _DataclassParams 实例
第二段代码
fields = {} any_frozen_base = False has_dataclass_bases = False for b in cls.__mro__[-1:0:-1]: base_fields = getattr(b, _FIELDS, None) if base_fields: has_dataclass_bases = True for f in base_fields.values(): fields[f.name] = f if getattr(b, _PARAMS).frozen: any_frozen_base = True
前两行都是定义变量,直接从第三行开始。cls.__mro__[-1:0:-1] 这代表取 cls 本身和继承的类,按照新式类的顺序从子类到父类排序
(详情见:mro)
然后不要第一个(即自己本身),剩下的进行倒序排列,这时候,所有类的顺序已经变成了父类到子类,这时候第一个为 object_FIELDS 为前面定义的变量,为 __dataclass_fields__
轮询排好序的类,如果由 __dataclass_fields__ 属性,则进行前面的定义的变量操作,把所有的取到的值加入 fields。
只有用 @dataclass 生成的类才会有这个属性。
第三段代码
cls_annotations = cls.__dict__.get('__annotations__', {}) cls_fields = [_get_field(cls, name, type) for name, type in cls_annotations.items()] for f in cls_fields: fields[f.name] = f if isinstance(getattr(cls, f.name, None), Field): if f.default is MISSING: delattr(cls, f.name) else: setattr(cls, f.name, f.default)
cls_annotations = cls.__dict__.get('__annotations__', {})
这句话就是为了取出我们定义的所有字段
只要我们定义字段是
a: int
b: str
这样的,就会自动有 __annotations__ 属性
可以参看 PEP 526
然后赋予 cls 属性操作
这步操作就是我们能够进行类取值的关键
第四段代码
setattr(cls, _FIELDS, fields)
将 fields (最早定义的一个字典)作为值,赋给 cls 的属性 __dataclass_fields__
第五段代码
if init: has_post_init = hasattr(cls, _POST_INIT_NAME) flds = [f for f in fields.values() if f._field_type in (_FIELD, _FIELD_INITVAR)] _set_new_attribute(cls, '__init__', _init_fn(flds, frozen, has_post_init, '__dataclass_self__' if 'self' in fields else 'self', ))
这段代码表示,一旦设置 __init__=True,会在类里面加上这个方法。
def _set_new_attribute(cls, name, value): if name in cls.__dict__: return True setattr(cls, name, value) return False
_set_new_attribute 是一个为类赋予属性的方法
至此,dataclass 源码剖析完毕
make_dataclass 源码剖析
源码为:
def make_dataclass(cls_name, fields, *, bases=(), namespace=None, init=True, repr=True, eq=True, order=False, unsafe_hash=False, frozen=False): if namespace is None: namespace = {} else: namespace = namespace.copy() seen = set() anns = {} for item in fields: if isinstance(item, str): name = item tp = 'typing.Any' elif len(item) == 2: name, tp, = item elif len(item) == 3: name, tp, spec = item namespace[name] = spec else: raise TypeError(f'Invalid field: {item!r}') if not isinstance(name, str) or not name.isidentifier(): raise TypeError(f'Field names must be valid identifers: {name!r}') if keyword.iskeyword(name): raise TypeError(f'Field names must not be keywords: {name!r}') if name in seen: raise TypeError(f'Field name duplicated: {name!r}') seen.add(name) anns[name] = tp namespace['__annotations__'] = anns cls = types.new_class(cls_name, bases, {}, lambda ns: ns.update(namespace)) return dataclass(cls, init=init, repr=repr, eq=eq, order=order, unsafe_hash=unsafe_hash, frozen=frozen)
流程很详细,就是解析我们定义的 fields,然后赋予 __annotations__属性,最后使用 dataclass 生成一个类。
从其中的流程判断来看,fields 里面最长只允许我们设置三个值,第一个名字,第二个类型,第三个是 fields 对象。
源码剖析至此结束
尾声
从功能上来看,dataclass 为我们带来了比较好优化类方案,提供的各类方法也足够用,可以在之后的项目里面逐渐使用起来。
从源码上来看,源码整体比较简洁,使用了比较少见的 __annotations__,技巧足够,代码简单易学。
建议新手可以从此入手,即可学习装饰器也可学习优秀代码。