一.分组操作 关键字$group
1.和distinct去重的比较
db.getCollection("2020062401").distinct('姓名')
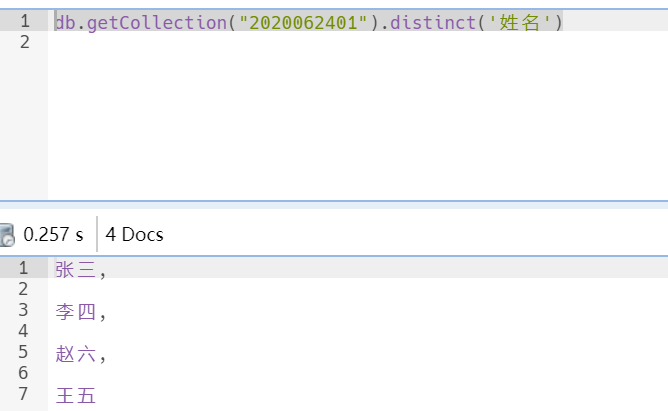
返回的是一个列表
使用¥group分组
db.getCollection("2020062401").aggregate([ { $group: { _id: "$去重的字段名"} }])
如:
db.getCollection("2020062401").aggregate([ { $group: { _id: "$姓名"} }])
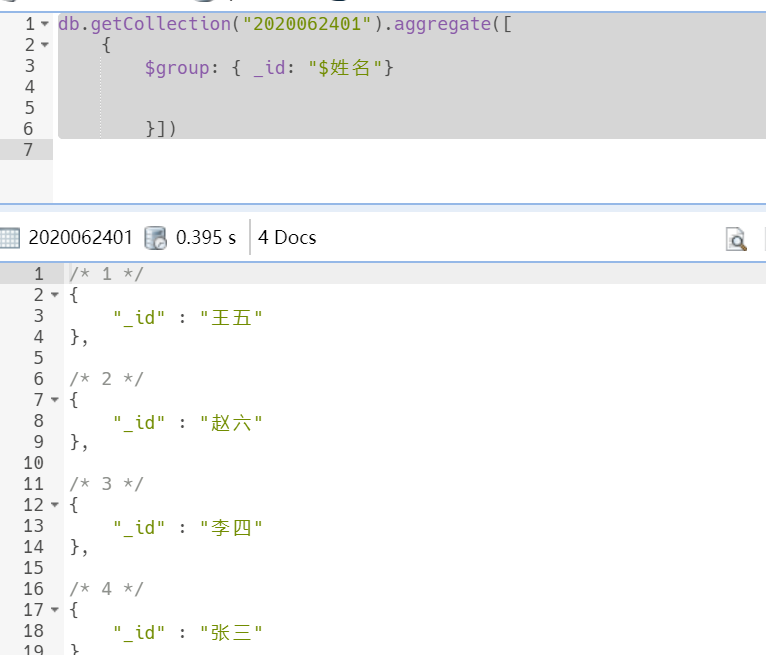
返回的是四条记录
二.分组计算
语法如下:
db.getCollection("2020062401").aggregate([ { $group: { _id: "$用来去重的字段名", "max_score":{"$max":"$字段名"}, "min_score":{"$min":"$字段名"}, "avg_score":{"$avg":"$字段名"}, "sum_score":{"$sum":"$字段名"}, } }])
如:
db.getCollection("2020062401").aggregate([ { $group: { _id: "$姓名", "max_score":{"$max":"$分数"}, "min_score":{"$min":"$分数"}, "avg_score":{"$avg":"$分数"}, "sum_score":{"$sum":"$分数"}, } }])

在这里引入了“$max”“$min”“$sum”和“$avg”四个关键字, 它们的用法都很简单, 全部都是:{$关键字: $已有的字段}提示:原则上, “ $sum” 和“ $avg” 的值对应的字段的值应该都是数字。 如果强行使用值为非数字的字段, 那么“ $sum” 会返回0,“ $avg” 会返回“ null” 。 而字符串是可以比较大小的, 所以, “ $max” 与“ $min” 可以正常应用到字符串型的字段。其中, “$sum”的值还可以使用数字“1”, 这样查询语句就变成了统计每一个分组内有多少条记录,
如:
db.getCollection("2020062401").aggregate([ { $group: { _id: "$姓名", "max_score":{"$max":"$分数"}, "min_score":{"$min":"$分数"}, "avg_score":{"$avg":"$分数"}, "sum_score":{"$sum":"$分数"}, "doc_sum":{"$sum":1}, } }])

分组取最新的数据($last取最后插入的数据,也就是最新的)
db.getCollection("2020062401").aggregate([ { $group: { _id: "$姓名", "date":{$last: "$日期"}, "score":{$last: "$分数"} } } ])
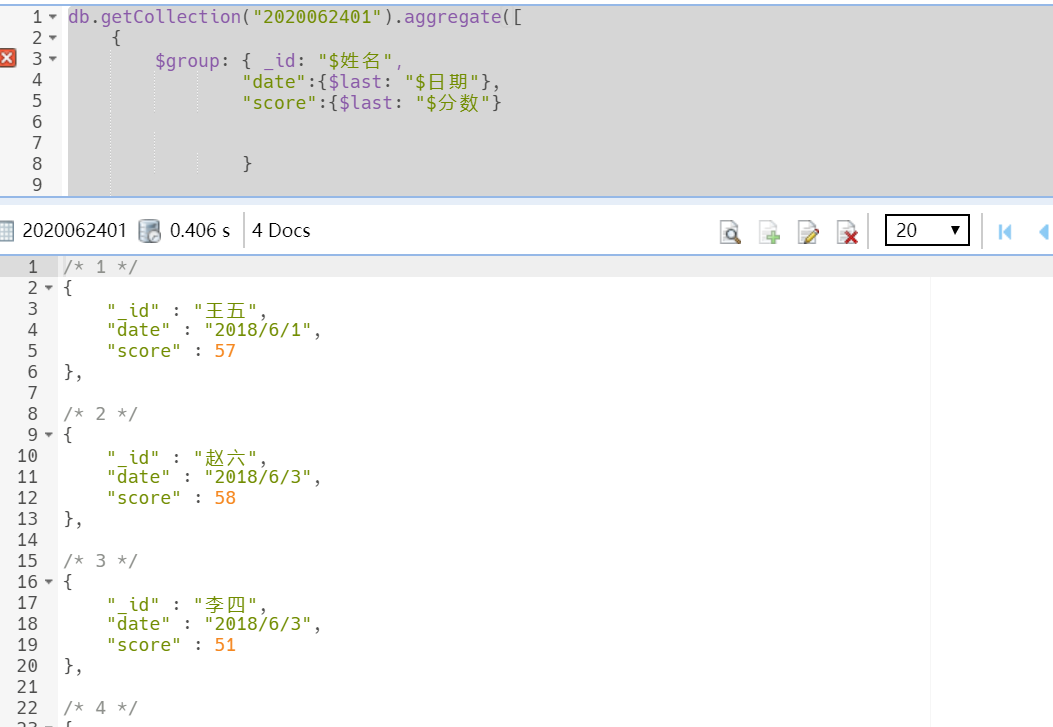
分组取最新的数据($first取最早插入的数据,也就是第一一条)
db.getCollection("2020062401").aggregate([ { $group: { _id: "$姓名", "date":{$first: "$日期"}, "score":{$first: "$分数"} } } ])

三.拆分数组 $unwind
语法:
db.getCollection("20200624").aggregate([{$unwind: "$size"}])
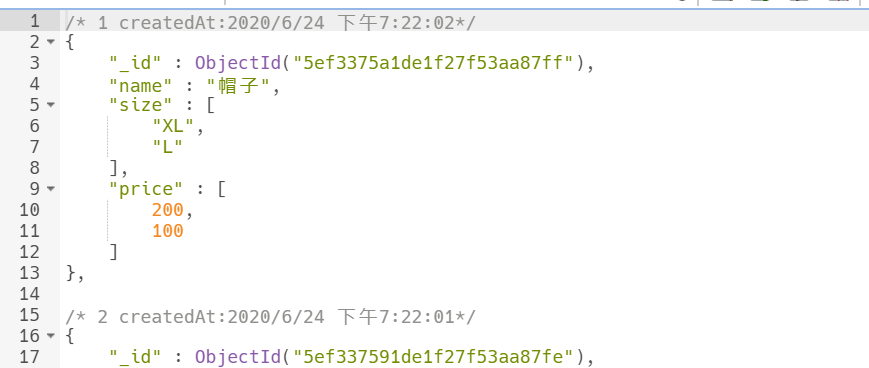
原来的数据结构:
使用unwind拆分后
db.getCollection("20200624").aggregate([{ $unwind: "$size" }])
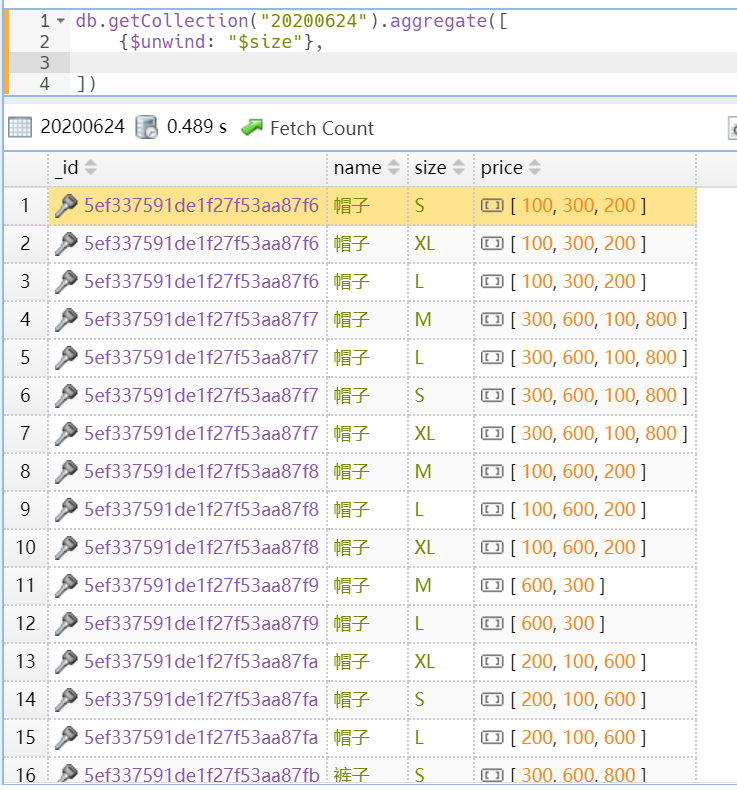
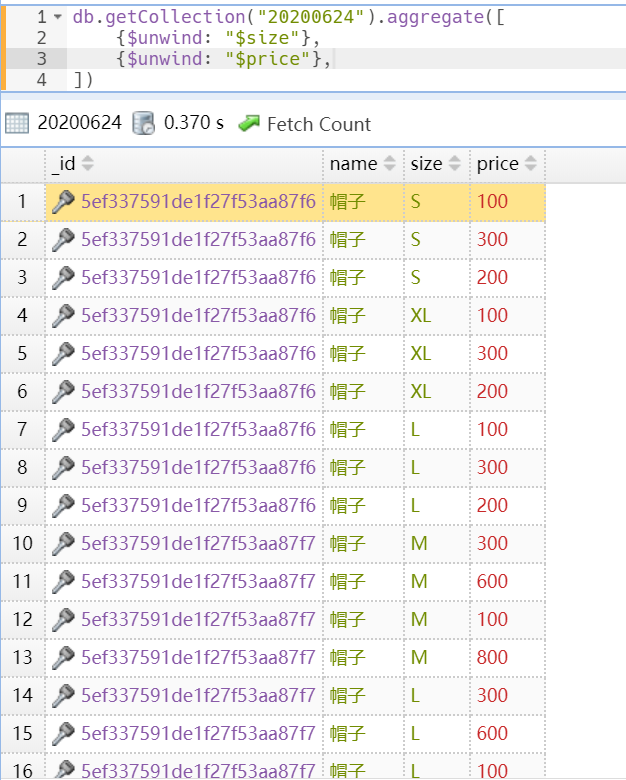
“$unwind”一次只能拆开一个数组, 如果还要把“price”字段拆开,则可以让第一次运行的结果再走一次“$unwind”阶段,
db.getCollection("20200624").aggregate([ {$unwind: "$size"}, {$unwind: "$price"}, ])
摘自:《左手redis,右手mongodb》