一.简介
XML是由万维网联盟(W3C)创建的标记语言,被设计用来传输和存储数据,XML可以自行定义标签,具有自我描述性,其设计宗旨是传输数据,而非显示数据。Python自带XML模块,方便开发者解析XML数据。XML模块中包含了广泛使用的API接口--------SAX和DOM等。另外,lxml解析库同样支持HTML和XML的解析,而且支持XPath解析方式。总的来说,Python解析XML的常用方法有以下几种:
1、DOM解析,xml.dom.*模块。
2、SAX解析,xml.sax.*模块。
3、ET解析,xml.etree.ElementTree模块。
4、lxml解析并结合XPath提取元素。
由于第四种方法是我们在网络爬虫时解析html经常用到的,也是我们较为熟悉的,所以首先尝试用它来解析xml,另外三种方法也将陆续介绍。
二. 使用lxml解析xml文件
1、导入相关标准库
from lxml import etree
2、定义解析器
parser = etree.XMLParser(encoding = "utf-8")
3、使用解析器parser解析XML文件
#传入两个参数,第一个参数是文件名,第二个参数是解析器。 tree = etree.parse(r"douban.xml",parser = parser) #查看解析出的tree的内容 print(etree.tostring(tree,encoding = 'utf-8').decode('utf-8'))
4、结合xpath提取XML文件中的信息
from lxml import etree # 使用lxml解析xml文件 parser = etree.HTMLParser(encoding="utf-8") tree = etree.parse("douban.xml", parser=parser) a = tree.xpath('//loc/text()') print(a)
方法二:直接使用html解析器就能解析xml文件
from lxml import etree with open('douban.xml', 'r',encoding='utf-8') as reader: xmlstr = reader.read() tree = etree.HTML(xmlstr) print(tree.xpath('//loc/text()'))
这种方法容易遇到这样的错误:
ValueError: Unicode strings with encoding declaration are not supported. Please use bytes input or XML fragments without declaration.
原因是lxml 不支持解析带有encoding 声明的字符串,例如 xml中以encoding="UTF-8"开头,需要转换成bytes类型。
我们看看douban.xml文件,真的带有编码声明的:
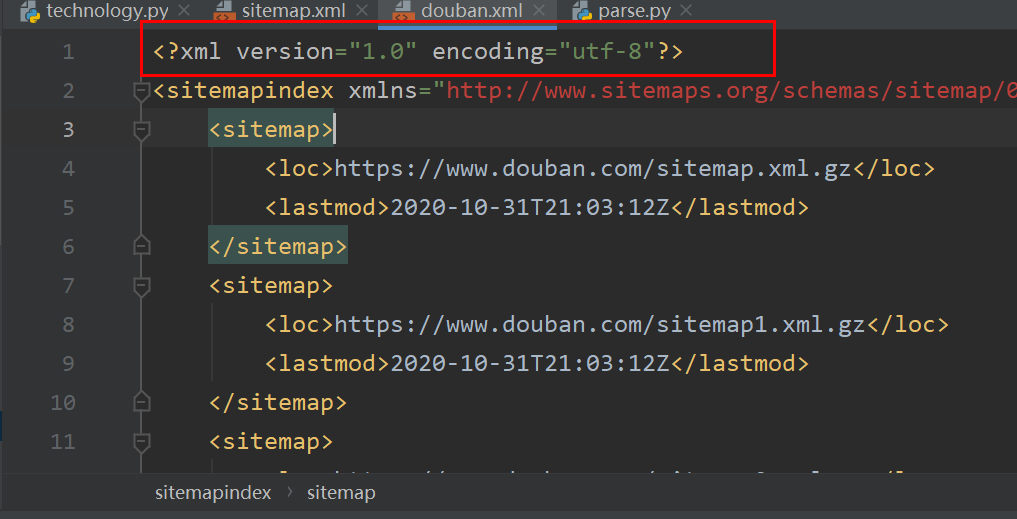
解决方法:
1.把xml文件的首行编码声明去掉就可以了
2.传入构造含数据的不要用字符串,而是二进制内容:
如:
from lxml import etree #以二进制打开文件,传进去bytes类型的数据 with open('douban.xml', 'rb') as reader: xmlstr = reader.read() tree = etree.HTML(xmlstr) print(tree.xpath('//loc/text()'))
三.使用xml.dom.minidom解析xml
import xml.dom.minidom def readXML(path): urls = [] domTree = xml.dom.minidom.parse(path) # 文档根元素 rootNode = domTree.documentElement print(rootNode.nodeName) # 所有loc节点 locs = rootNode.getElementsByTagName("loc") print(locs) for loc in locs: url = loc.childNodes[0].data urls.append(url) return urls path = "./sitemap.xml" readXML(path)