1、避免创建重复的RDD和不必要的内存空间浪费
错误代码:
val rdd1 = sc.textFile("D:\abc\wordcount\input\hello.txt")
rdd1.map(...)
val rdd2 = sc.textFile("D:\abc\wordcount\input\hello.txt")
rdd2.reduce(...)
错误解析:
这种情况下,Spark需要从文件中加载两次hello.txt文件的内容,并创建两个单独的RDD;第二次加载HDFS文件以及创建RDD的性能开销,很明显是白白浪费掉的
正确代码:
val rdd1 = sc.textFile("D:\abc\wordcount\input\hello.txt")
rdd1.map(...)
rdd1.reduce(...)
这种写法很明显比上一种写法要好多了,因为我们对于同一份数据只创建了一个RDD,然后对这一个RDD执行了多次算子操作
2、尽最大可能复用同一个RDD
错误代码:
val rdd1 = sc.textFile("D:\abc\wordcount\input\hello.txt")
Val rdd2 = rdd1.map(...)
//分别对rdd1和rdd2进行了不同的算子操作
rdd1.reduceByKey(...)
rdd2.map(...)
错误解析:
上面这个案例中,其实rdd1和rdd2的区别无非就是数据格式不同而已,rdd2的数据完全就是rdd1的子集而已,却创建了两个rdd,并对两个rdd都执行了一次算子操作。 此时会因为对rdd1执行map算子来创建rdd2,而多执行一次算子操作,进而增加性能开销。
正确代码:
val rdd1 = sc.textFile("D:\abc\wordcount\input\hello.txt")
rdd1.reduceByKey(...)
rdd1.map(tuple._2...)
在进行第二个map操作时,只使用每个数据的tuple._2,也就是rdd1中的value值,即可。第二种方式相较于第一种方式而言,很明显减少了一次rdd2的计算开销
3、对多次使用的RDD进行持久化操作
错误代码:
val rdd1 = sc.textFile("D:\abc\wordcount\input\hello.txt")
rdd1.map(...)
.reduce(...)
.reduceByKey(...)
错误解析:
Spark中对于一个RDD执行多次算子的默认原理是这样的:每次你对一个RDD执行一个算子操作时,都会重新从源头处计算一遍,计算出那个RDD来,然后再对这个RDD执行你的算子操作。这种方式的性能是很差的
正确代码:
val rdd1 = sc.textFile("D:\abc\wordcount\input\hello.txt").cache()
rdd1.map(...)
rdd1.reduce(...)
或者
Val rdd1=sc.textFile("D:\abc\wordcount\input\hello.txt").persist
(StorageLevel.MEMORY_AND_DISK_SER)
rdd1.map(...)
rdd1.reduce(...)
如果要对一个RDD进行持久化,只要对这个RDD调用cache()和persist()即可。
cache()方法表示:使用非序列化的方式将RDD中的数据全部尝试持久化到内存中。此时再对rdd1执行两次算子操作时,只有在第一次执行map算子时,才会将这个rdd1从源头处计算一次。
第二次执行reduce算子时,就会直接从内存中提取数据进行计算,不会重复计算一个rdd。
persist()方法表示:手动选择持久化级别,并使用指定的方式进行持久化。 比如说,StorageLevel.MEMORY_AND_DISK_SER表示,内存充足时优先持久化到内存中,内存不充足时持久化到磁盘文件中。
而且其中的_SER后缀表示,使用序列化的方式来保存RDD数据,此时RDD中的每个partition都会序列化成一个大的字节数组,然后再持久化到内存或磁盘中。
序列化的方式可以减少持久化的数据对内存/磁盘的占用量,进而避免内存被持久化数据占用过多,从而发生频繁GC。(总共有12中方式源码)
4、尽量避免使用shuffle算子
错误代码:
val rdd3 = rdd1.join(rdd2)
错误分析:
Spark作业运行过程中,最消耗性能的地方就是shuffle过程。所以能避免则尽可能避免使用reduceByKey、join、distinct、repartition等会进行shuffle的算子,尽量使用map类的非shuffle算子。这样的话,没有shuffle操作或者仅有较少shuffle操作的Spark作业,可以大大减少性能开销
正确代码:
val rdd2 = rdd2.collect() val rdd2Broadcast = sc.broadcast(rdd2) Broadcast+map的join操作,不会导致shuffle操作。使用Broadcast将一个数据量较小的RDD作为广播变量。以上操作,建议仅仅在rdd2的数据量比较少(比如几百M,或者一两G)的情况下使用 因为每个Executor的内存中,都会驻留一份rdd2的全量数据
5、使用性能较高的算子
groupByKey代码:
val Data1 = lines.flatMap(_.split(" "))
.map((_,1))
.groupByKey().mapValues(_.sum)
reduceByKey代码:
val Data2 = lines.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
使用reduceByKey替代groupByKey,因为reduceByKey会先进行一次局部聚合
再比如使用mapPartitions替代普通map
mapPartitions类的算子,一次函数调用会处理一个partition所有的数据,而不是一次函数调用处理一条,性能相对来说会高一些,使用mapPartitions会出现OOM(内存溢出)的问题,所以使用这类操作时要慎重
6、使用Kryo优化序列化性能
代码:
object YouHua { def main(args: Array[String]): Unit = { val conf = new SparkConf() .setAppName("haha") .setMaster("local[*]") .set("spark.testing.memory", "2147480000") .registerKryoClasses(Array(classOf[Student])) val sc = new SparkContext(conf) } } // spark默认Java的序列化 class Student{}
Kryo序列化机制比Java序列化机制,性能高10倍左右,但是spark默认的是java的序列化,因为这个不需要自己手动注册。而Kryo序列化机制我们只要设置序列化类,再注册要序列化的自定义类型即可,注意有一个类需要注册一次所以说比较费劲
7、解决数据倾斜
如何定位导致数据倾斜的代码:
数据倾斜只会发生在shuffle过程中。这里给大家罗列一些常用的并且可能会触发shuffle操作的算子:distinct、groupByKey、reduceByKey、aggregateByKey、join、cogroup、repartition等。出现数据倾斜时,可能就是你的代码中使用了这些算子中的某一个所导致的
解决办法
(1)加盐
val lines = sc.makeRDD(List("ni ni aa aa aa aa aa aa aa aa aa aa aa aa aa aa aa aa aa aa aa aa aa aa aa aa aa aa"))
lines.flatMap(_.split(" "))
//首先我们拼一个时间也可以拼随机数
.map(x => (System.currentTimeMillis().toString + "-" + x,1))
//按照key聚合一下,这样就会打散,均匀分发各个分区
.reduceByKey(_+_)
//去掉我们拼的前缀
.map(x => (x._1.substring(14),x._2))
//最后在聚合得到我们想要的结果
.reduceByKey(_+_)
.mapPartitionsWithIndex(func1)
(2)自定义分区
val func1 = (index:Int,iter:Iterator[(String,Int)]) => { iter.map(index +":" + _) } lines.flatMap(_.split(" ")) .map(x => (x,1)) //按照自定义的分区随机分发数据 .reduceByKey(new MyPartitioner(),_+_) //在按照HashPartitioner聚合数据 .reduceByKey(new HashPartitioner(4),_+_) .mapPartitionsWithIndex(func1) .foreach(println) class MyPartitioner extends Partitioner{ override def numPartitions: Int = 4 override def getPartition(key: Any): Int = { //这里我们给返回随机数 Random.nextInt(numPartitions) } }
(1)采样倾斜key并分拆join操作
如果出现数据倾斜,是因为其中某一个RDD/Hive表中的少数几个key的数据量过大,而另一个RDD/Hive表中的所有key都分布比较均匀,那么采用这个解决方案是比较合适的
实现思路
举例:一号RDD中多个Key都有数据倾斜、二号RDD相对均衡
- 先从一号RDD中利用sample进行抽样 Val sampledRDD = rdd1.sample(false, 0.1)
- 对样本数据RDD统计出每个key的出现次数,并按出现次数降序排序。对降序排序后的数据,取出top 10或者top 100的数据,也就是key最多的前n个数据。具体取出多少个数据量最多的key,由大家自己决定
- 从一号RDD中分离出来导致数据倾斜的key,形成新的RDD
- 从一号RDD中拆出不导致数据倾斜的普通key,形成独立的RDD
- 先给一号RDD中导致数据倾斜的key加盐(随机数(或者自己想要的前缀))再从二号RDD中,前面获取到的key对应的数据,过滤出来,分拆成单独的rdd,并对rdd中的数据也都加盐,加上前面一号RDD的所有盐。然后将这个一号RDD中分拆出来的独立rdd,与上面二号RDD分拆出来的独立rdd,进行join
举例说明:
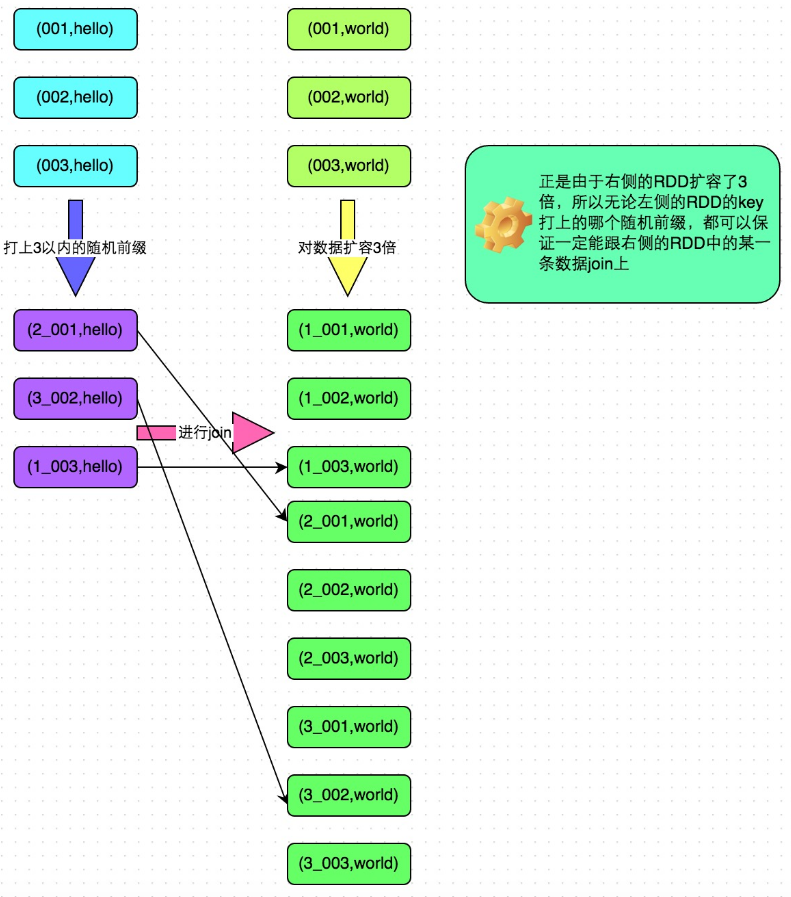
6.将一号RDD中分拆出来的包含不倾斜key的独立rdd,直接与rdd2进行join
7.将倾斜key join后的结果与普通key join后的结果,uinon起来就是最终的结果